Авторы «Платформы-2015» утверждают, что многоядерность — это будущее микропроцессорной индустрии
Переход к построению многоядерных процессоров (MPU) не есть изобретение Intel. Двухъядерные MPU, содержащие по два процессора, выпустили основные разработчики RISC-микропроцессоров — компании HP, IBM и Sun Microsystems. В Intel и AMD достигли наивысших успехов на другом пути роста производительности — за счет тактовой частоты, поэтому, возможно, и «задержались» с многоядерностью. IBM выпустила Power4 с двумя ядрами уже несколько лет назад, ныне производятся уже новые многоядерные процессоры Power5. В прошлом году появились двухъядерные HP PA-8800. Sun давно объявила о переходе в будущем к MPU под кодовым названием Niagara, а UltraSparc IV уже является двухъядерным.
Параллелизм существует и внутри суперскалярных ядер: команды разного типа могут одновременно выполняться в разных функциональных устройствах. Однако задействовать этот тип параллелизма, подняв число команд, одновременно выполняющихся за такт, очень сложно. Даже в Itanium 2 с ориентированной на такой параллелизм VLIW-подобной архитектурой большого прорыва не получилось. А лидером по SPECfp2000 остается RISC-процессор Power5.
Между тем в массивно-параллельных системах и кластерах часто достигается высокий уровень параллелизма, а переход к MPU «облегчает» и удешевляет такое распараллеливание. В MPU удается относительно легко достигнуть увеличения числа транзисторов путем увеличения числа ядер. Относительно легко можно наращивать число транзисторов и за счет роста емкости кэша, но это не всегда дает адекватный рост производительности. А вот увеличивать число функциональных устройств неэффективно в связи со сложностью увеличения внутреннего параллелизма ядер.
Наконец, при маленьких размерах ядер (по сравнению с «большими» MPU) проще наращивать тактовую частоту, не получая при этом больших задержек.
Intel сделала значительный шаг в направлении к MPU-архитектуре, когда ввела поддержку технологии HyperThreading в Pentium 4. Однако достигаемое при работе с двумя нитями ускорение не всегда достаточно существенно, а во многих приложениях с массивными вычислениями может даже дать замедление. Применение многоядерности (в Intel используют термин Chip Multiprocesing, или CMP) может дать более существенное ускорение при распараллеливании. Большинство своих микропроцессоров уже примерно через год Intel будет производить в форме MPU.
В Intel утверждают, что CMP — это будущее микропроцессорной индустрии, что число ядер в MPU может достигать в некоторых случаях сотен. Однако СMP служит не только целям масштабирования производительности, но и минимизации уровня электропитания и тепловыделения.
СMP-архитектура предполагает, что только используемые ядра будут потреблять электроэнергию, а остальные будут «обесточены». Тонкая настройка управления электропитанием будет осуществляться, естественно, динамически.
Во всех плюсах есть свои минусы. Во-первых, чтобы достигнуть реального масштабирования производительности задачи, ее необходимо распараллелить. Это непросто, а большинство разработчиков программного обеспечения сегодня этого делать, по-видимому, не умеют. Во-вторых, существующие алгоритмы могут плохо распараллеливаться на большом числе процессоров. В общем, проблемы разработчиков аппаратуры перекладываются теперь на программистов.
Впрочем, Intel настаивает на «интегрированном интеллекте» своих будущих MPU, в частности в отнесении различных задач различным ядрам. Одним из возможных путей повышения эффективности MPU авторы «Платформы-2015» считают применение встроенного в MPU микроядра, ответственного за разбиение приложения на несколько параллельных нитей, облегчая высокоуровневому программному обеспечению решение сложных задач по управлению аппаратурой.
Где выигрыш от внедрения MPU будет очевидным, так это в многозадачной среде, когда необходимо одновременное выполнение нескольких задач. Intel планирует в своих MPU дополнить универсальные ядра специализированными под различные типы вычислений — для задач графики, распознавания речи, обработки сетевых протоколов.
Чтобы удовлетворить требованиям диверсификации и изменяющихся нагрузок, планируется даже динамическая реконфигурация ядер, межсоединений и кэш-памяти.
Общей тенденцией для микропроцессоров Intel, впрочем, как и ряда других производителей, является интеграция в аппаратуру функций, выполнявшихся ранее программным обеспечением или специализированными микросхемами. Эффективность интеграции в MPU проявляется, в частности, благодаря снижению задержек коммуникаций между специализированными ядрами и ядрами общего назначения. Среди известных примеров такой интеграции в прошлом — операции с плавающей точкой, графическая обработка и обработка сетевых пакетов. Intel перечисляет много потенциальных кандидатов на интеграцию в MPU — рендеринг трехмерных сцен, распознавание речи и др.
Когда речь идет о двухъядерных процессорах ближайшего поколения, задача которых — обеспечения роста производительности, пропорционального росту суммарного числа транзисторов, сразу встает вопрос об узком месте. Таковым для многих приложений, в том числе из области высокопроизводительных вычислений, является доступ в оперативную память. Известным недостатком двухпроцессорных серверов на базе Intel x86/x86-64 и IA-64 является разделение процессорами общей шины, на которой возникают конфликты по доступу в память.
Похоже, что в ближайшем поколении двухъядерных х86-совместимых процессоров ядра будут разделять тракт доступа к памяти, что может отрицательно сказаться на масштабировании производительности.
Некоторые будущие MPU будут включать память на кристалле, которая может достигать гигабайтного диапазона, в ряде случаев заменяя собой оперативную память. Кэш-память MPU от Intel будет реконфигурируемой; части кэша могут динамически распределяться разным ядрами. Кэш может быть в эксклюзивном пользовании ядра, или разделяться группой ядер, или быть общим для всех ядер — в зависимости от потребностей приложений. По замыслу разработчиков, это предотвратит превращение кэш-памяти в узкое место для производительности MPU.
Все виды межсоединений, связывающих процессорные ядра между собой и с памятью различных уровней, должны быть высокоскоростными — также чтобы не стать узким местом. Для этого Intel планирует использовать как усовершенствованные медные межсоединения, так и оптические. Последние, очевидно, быстрее: там скорость передачи сигнала равна скорости света. Интересно, что к 2013 году, когда, по оценкам независимых компаний, будет уже применяться 32-нанометровая технология, ряд компьютерных компаний рассматривают возможность применения другой альтернативы — углеродных нанотрубок.
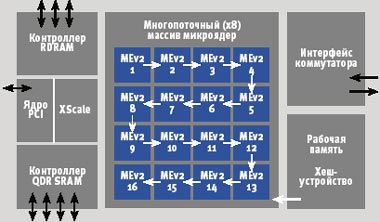
Однако Intel обращает внимание на другую сторону вопроса — на архитектуру межсоединения, которая сможет соединять сотни ядер. Инженеры корпорации активно работают в данной области.
Прообраз "Платформы" - 2015