Концепция EPIC (Explicitly Parallel Instruction Computing) определяет новый тип архитектуры, способной конкурировать по масштабам влияния с архитектурой RISC. Эта идеология направлена на то, чтобы упростить аппаратное обеспечение и, в то же время, извлечь как можно больше «скрытого параллелизма» на уровне команд, чем это можно сделать при реализации VLIW или суперскалярных стратегий.
За последние два с половиной десятилетия компьютерная отрасль развивалась в соответствии с темпами увеличения производительности микропроцессоров. Отрасль использовала эти достижения, позволяя обходиться без кардинального переписывания программ в «параллельном виде», без смены языков и алгоритмов и, зачастую, даже без перекомпиляции самого кода. По крайней мере до последнего времени параллельная обработка на уровне команд утвердилась как единственный подход, позволяющий добиваться высокой производительности без серьезных изменений программного обеспечения.
Однако компьютеры достигали этой цели главным образом за счет серьезного увеличения сложности аппаратного обеспечения - сложности, которая стала настолько значительной, что превратилась в препятствие, не позволяющее отрасли добиваться еще более высокой производительности. Мы разработали тип архитектуры Explicitly Parallel Instruction Computing (EPIC) именно для того, чтобы обеспечить более высокую степень параллелизма на уровне команд, поддерживая при этом приемлемую сложность аппаратного обеспечения.
Увеличение степени параллелизма
Более высокая производительность достигается как за счет совершенствования полупроводниковой технологии, в частности, увеличения скорости передачи сигналов в самой микросхеме, так и за счет увеличения плотности микросхем. Дальнейшего увеличения скорости выполнения программ можно добиться в первую очередь благодаря реализации определенного вида параллелизма. Параллелизм на уровне команд (instruction-level parallelism, ILP) стал возможен благодаря созданию процессоров и методик компиляции, которые ускоряют работу за счет параллельного выполнения отдельных RISC-операций. Системы на базе ILP используют программы, написанные на традиционных языках высокого уровня для последовательных процессоров, а обнаружение «скрытого параллелизма» автоматически выполняется благодаря применению соответствующей компиляторной технологии и аппаратного обеспечения.
Тот факт, что эти методики (как и увеличение скорости работы самих микросхем) не требуют от прикладных программистов дополнительных усилий, имеет крайне важное значение. Это решение резко отличается от традиционного микропроцессорного параллелизма, который предполагает, что программисты должны переписывать свои приложения. Если говорить о перспективе, становится очевидно, что многопроцессорный тип параллельной обработки останется важной технологией для компьютерной отрасли. Сейчас, тем не менее, параллельная обработка на уровне команд, является единственным надежным подходом, позволяющим добиться увеличения производительности без фундаментальной переработки приложений. Эти два типа параллельной обработки не исключают друг друга; самые эффективные многопроцессорные системы, вероятнее всего, будут создаваться на базе процессоров ILP.
Архитектуры ILP
Компьютерная архитектура - это своего рода соглашение между классом программ, написанных для данной архитектуры, и множеством реализаций процессора для нее. Как правило, это соглашение описывает формат и интерпретацию отдельных команд, но в случае с архитектурами ILP это соглашение может быть расширено: в него включается информация о возможном параллелизме между командами или операциями. Два наиболее важных на сегодняшний день типа ILP-процессоров отличаются именно в этом аспекте.
Суперскалярные процессоры - это реализации ILP-процессора для последовательных архитектур - архитектур, программа для которых не должна передавать и, фактически, не может передавать точную информацию о параллелизме. Поскольку программа не содержит точной информации о наличии ILP, то, задача обнаружения параллелизма должна решаться аппаратурой, которая, следовательно, должна создавать план действий для обнаружения «скрытого параллелизма».
Процессоры VLIW (процессоры, использующие сверхбольшие слова команд) представляют собой пример архитектуры, для которой программа предоставляет точную информацию о параллелизме. Компилятор выявляет параллелизм в программе и сообщает аппаратному обеспечению, какие операции не зависят друг от друга. Эта информация имеет важное значение для аппаратного обеспечения, поскольку в этом случае оно «знает» без дальнейших проверок, какие операции можно начинать выполнять в одном и том же такте.
Тип архитектуры Explicitly Parallel Instruction Computing - это эволюция архитектуры VLIW, которая абсорбировала в себе многие концепции суперскалярной архитектуры, хотя и в форме, адаптированной к EPIC. По сути, EPIC - это «идеология», определяющая, как создавать ILP-процессоры, а также набор характеристик архитектуры, которые поддерживают данную идеологию. В этом смысле EPIC похож на RISC: определяющий класс архитектур, подчиняющихся общим основным принципам. Точно также, как существует множество различных архитектур наборов команд (ISA) для RISC, может существовать и больше одной ISA EPIC. В зависимости от того, какие из характеристик EPIC использует архитектура EPIC ISA, она может быть оптимизирована для различных приложений, например, для систем общего назначение или встроенных устройств.
Первым примером коммерческой EPIC ISA стала архитектура IA-64. Однако в данной статье мы сосредоточимся на более общей концепции EPIC, которую олицетворяет собой архитектура HPL-PD (ранее известная как архитектура Hewlett-Packard Laboratories PlayDoh) [2, 3], поскольку она охватывает большее пространство возможных EPIC ISA. Мы определили HPL-PD в лаборатории Hewlett-Packard Laboratories с тем, чтобы стимулировать исследование архитектуры и компиляторов EPIC. В данной статье мы рассматриваем HPL-PD потому, что ей не свойственны какие-либо уникальные характеристики конкретной ISA и это позволяет поговорить о сути основных принципов EPIC.
Причины создания EPIC
Исследования, связанные с EPIC, в HP Labs велись с начала 1989 года, хотя само название этого типа архитектуры появилось только в 1997 году, когда был образован альянс HP-Intel. В то время суперскалярные процессоры безусловно были самыми популярными средствами достижения параллелизма на уровне команд. Однако, поскольку уже тогда было понятно, что потребуется несколько лет, прежде чем наши исследования окажут влияние на проектирование реальных продуктов, нам показалось крайне важным оценить перспективы на следующие пять - десять лет и понять, какие технологические трудности и возможности проявятся в течение этого периода времени.
И в тот момент мы пришли к двум заключениям: одно из них очевидно, а вот второе, на первый взгляд, кажется спорным. Во-первых, из закона Мура напрямую следовало, что в скором времени станет возможным разместить весь ILP-процессор с высоким уровнем параллелизма целиком на одной микросхеме. Во-вторых, мы были уверены в том, что постоянно наращиваемая сложность суперскалярных процессоров окажет негативное влияние на их тактовую частоту и, в конечном итоге, приведет к тому, что дальнейшее увеличение сложности не будет оправдывать рост производительности микропроцессоров.
Хотя проектировщики оспаривают последнее утверждение даже сегодня, тем не менее мы и по сей день убеждены в том, в чем были убеждены в 1989 году. И эта убежденность заставила нас искать альтернативный тип архитектуры, способный обеспечить высокий уровень ILP и при этом упростить аппаратное обеспечение.
В частности, нам хотелось избежать внеочередного выполнения команд - элегантной, но весьма дорогой методики ILP, которая впервые была применена в System/360 Model 91 корпорации IBM и сейчас используется многими суперскалярными микропроцессорами старшего класса. Тип архитектуры VLIW в том виде, как он реализован в продуктах Multiflow [5] и Cydrome [6,7], решает задачу обеспечения высокого уровня ILP, снижая при этом сложность аппаратного обеспечения. Однако эти машины были предназначены специально для числовых вычислений и не подходят для работы скалярных приложений с интенсивным ветвлением и требующих активного использования указателей. Конкурирующие RISC-процессоры, с другой стороны, имеют относительно невысокую производительность при работе с числовыми приложениями. Было ясно, что новый тип архитектуры должен быть архитектурой общего назначения, то есть архитектурой, способной достигать высокой степени параллелизма на уровне команд как в числовых, так и в скалярных приложениях. Кроме того, существующие архитектуры VLIW не обеспечивали адекватную совместимость объектного кода между процессорами развивающегося семейства, что абсолютно необходимо для процессоров общего назначения.
Код для суперскалярных процессоров содержит последовательность команд, которая порождает корректный результат, если выполняется в установленном порядке. Код указывает последовательный алгоритм и, за исключением того, что он использует конкретный набор команд, не представляет себе точно природу аппаратного обеспечения, на котором он будет работать или точный временной порядок, в котором будут выполняться команды.
В отличие от программ для суперскалярных процессоров, код VLIW предлагает точный план того, как процессор будет выполнять программу, план, который компилятор создает статически во время компиляции. Код точно указывает, когда будет выполнена каждая операция, какие функциональные устройства будут работать и какие регистры будут содержать операнды. Компилятор VLIW создает такой план выполнения (plan of execution - POE), имея полное представление о процессоре VLIW, причем создает этот план так, чтобы добиться требуемой записи выполнения (record of execution, ROE) - последовательности событий, которые действительно происходят во время работы программы.
Компилятор передает POE (через архитектуру набора команд, которая точно описывает параллелизм) аппаратному обеспечению, которое, в свою очередь выполняет указанный план. Этот план позволяет VLIW использовать относительно простое аппаратное обеспечение, способное добиться высокого уровня ILP. В отличие от VLIW суперскалярное аппаратное обеспечение динамически строит POE на основе последовательного кода. Хотя такой подход увеличивает сложность аппаратного обеспечения, в то же время суперскалярный процессор создает POE, используя преимущества тех факторов, которые могут быть определены только во время выполнения.
Основные принципы EPIC
Одна из целей, которые мы ставили перед собой при создании EPIC, состояла в том, чтобы сохранить реализованный в VLIW принцип статического создания POE, но в то же время обогатить его возможностями, аналогичными возможностям суперскалярного процессора, которые позволят новой архитектуре лучше учитывать динамические факторы, традиционно ограничивающие параллелизм, свойственный VLIW. Чтобы добиться этих целей, «идеология» EPIC была построена на следующих основных принципах.
Создание плана выполнения во время компиляции
EPIC возлагает нагрузку по созданию POE на компилятор. Хотя, в общем, архитектура и реализация процессора могут препятствовать компилятору в выполнении этой задачи, процессоры EPIC предоставляют функции, которые помогают компилятору создавать план выполнения. Во время выполнения поведение процессора EPIC, с точки зрения компилятора, должно быть предсказуемым и управляемым. Динамическое внеочередное выполнение команд может «запутать» компилятор так, что он не будет «понимать», как его решения повлияют на реальную ROE, созданную процессором; компилятор должен предвосхитить действия процессора, что еще больше усложняет задачу. В данной ситуации предпочтителен «послушный» процессор, который делает то, что ему указывает программа.
Суть создания POE во время компиляции состоит в переупорядочивании исходного последовательного кода так, чтобы использовать все преимущества параллелизма приложения и максимально эффективно тратить аппаратные ресурсы с тем, чтобы минимизировать время выполнения. Без соответствующей поддержки архитектуры такое переупорядочивание может нарушить корректность программы. Таким образом, поскольку EPIC возлагает создание POE на компилятор, она должна обеспечивать архитектурные возможности, поддерживающие интенсивное переупорядочивание кода во время компиляции.
Использование компилятором вероятностных оценок
Компилятор EPIC сталкивается с серьезной проблемой при создании POE: информация определенного типа, которая существенно влияет на ROE, становится известна только в момент выполнения программы. Например, компилятор не может точно знать, какая из ветвей после оператора перехода будет выполняться и когда запланированный код пройдет базовые блоки в блок-схеме; компилятор не может точно знать, какой из путей графа будет выбран. Кроме того, обычно невозможно создать статический план, который одновременно оптимизирует все пути в программе. Неоднозначность также возникает и в тех случаях, когда компилятор не может решить, будут ли ссылки указывать на одно и то же место в памяти. Если да, то в блок-схеме обращение к ним должно осуществляться последовательно; если нет, то их можно запланировать в произвольном порядке.
При такой неоднозначности часто наиболее вероятен некий конкретный результат. Одним из важнейших принципов EPIC является возможность разрешить компилятору в этой ситуации оперировать вероятностными оценками - компилятор создает и оптимизирует POE для наиболее вероятных случаев. Однако EPIC обеспечивает архитектурную поддержку, (такую как выполнение, спекулятивное по управлению и спекулятивное по данным (control and data speculation), которые мы обсудим позже) с тем, чтобы гарантировать корректность программы, даже если исходные предположения были не верны.
Когда предположение оказывается неверным, при выполнении программы может упасть производительность. Такое снижение производительности иногда видно на плане программы, к примеру, в тех случаях, когда существует высоко оптимизированная программная область, а код исполняется в менее оптимизированной области. Или падение производительности может возникнуть в тактах «остановки» (stall cycle), которые на плане программы не видны; определенные операции, подпадающие под наиболее вероятный и, следовательно, оптимизированный случай, выполняются при максимальной производительности, но приостанавливают процессор для того, чтобы гарантировать корректность, если возникнет менее вероятный, не оптимизированный случай.
Передача аппаратуре плана выполнения
После того, как создан POE, компилятор передает его аппаратному обеспечению. Для этого ISA должна обладать возможностями достаточно богатыми, чтобы сообщить решения компилятора о том, когда инициировать каждую операцию и какие ресурсы использовать, в частности, должен существовать способ указать, какие операции инициируются одновременно. В качестве альтернативного решения компилятор мог бы создавать последовательную программу, которую процессор динамически реорганизует с тем, чтобы получить требуемый ROE. Но в таком случае цель EPIC - освобождение аппаратного обеспечения от динамического планирования, не достигается.
При передаче POE аппаратному обеспечению крайне важно своевременно предоставить необходимую информацию. Иллюстрацией тому может служить операция перехода, которая, в случае ее использования, требует чтобы по адресу перехода команды выбирались с упреждением, заведомо до того, как будет инициирован переход. Вместо того, чтобы решение о том, когда это нужно сделать и каков адрес перехода отдавать на откуп аппаратному обеспечению, такая информация, в соответствии с основными принципами EPIC, передается аппаратному обеспечению точно и своевременно - через код.
Микроархитектура принимает и другие решения, не связанные напрямую с выполнением кода, но которые влияют на время выполнения. Один из таких примеров - управление иерархией кэш и соответствующие решения о том, какие данные нужны для поддержки иерархии и какие данные следует заменить. Такие правила обычно встраиваются в аппаратное обеспечение кэш-памяти. EPIC расширяет принцип, утверждающий, что план выполнения компилятор создает так, чтобы тоже иметь возможность управлять этими механизмами микроархитектуры. Для этого EPIC обеспечивает архитектурные возможности, позволяющие осуществлять программный контроль механизмов, которыми обычно управляет микроархитектура.
Архитектурные возможности поддержки EPIC
EPIC использует компилятор для создания статически запланированного кода, который позволяет процессору извлечь как можно больше «скрытого параллелизма», используя большую ширину «выдачи» команд (wide issue-width) и длинные конвейеры с большой задержкой (deep pipeline-latency), но менее сложное аппаратное обеспечение. EPIC упрощает два ключевых момента, реализуемых во время выполнения. Во-первых, принципы EPIC позволяют во время выполнения отказаться от проверки зависимостей между операциями, которые компилятор уже объявил как независимые. Во-вторых, EPIC позволяет отказаться от сложной логики внеочередного выполнения операций, полагаясь на порядок выдачи команд, определенный компилятором. EPIC совершенствует возможность компилятора статически генерировать хорошие планы выполнения за счет поддержки разного рода перемещений кода во время компиляции, которые были бы некорректными в последовательной архитектуре.
Статическое планирование
Команда MultiOp указывает, что несколько операций должны выдаваться одновременно. (Каждая операция в MultiOp эквивалентна последовательной команде RISC или CISC). Компилятор выявляет операции, выдача которых запланирована одновременно, и объединяет их в MultiOp. При выдаче MultiOp аппаратное обеспечение не должно выполнять проверку зависимостей между составляющими ее операциями. Более того, с кодом EPIC связывается понятие виртуального времени (virtual time). По определению, за один цикл виртуального времени выдается только одна команда MultiOp. Это виртуальное время обеспечивает временные рамки, используемые для определения плана выполнения программы. Виртуальное время отличается от реального времени тогда, когда при выполнении аппаратное обеспечение добавляет «остановки» (stall), которые компилятор не предвидел.
Традиционные последовательные архитектуры определяют выполнение как последовательность атомарных операций; в принципе, каждая операция завершается до начала следующей операции. Такая архитектура не допускает возможность того, что чтение и запись в регистр одной операции будут пересекаться по времени с чтением и записью регистров другой операции.
Благодаря применению MultiOp операции больше не являются атомарными. При выполнении операций одной MultiOp, несколько операций могут считывать свои входные данные до того, как любая другая операция запишет свой результат. Таким образом, неатомарность и задержки операций определяются на уровне архитектуры.
Появление понятия NUAL (nonunit assumed latency) - предполагаемой задержки на несколько тактов - обусловлено, главным образом, стремлением упростить аппаратное обеспечение для таких операций, которые, на самом деле, выполняются за несколько тактов. Если аппаратное обеспечение может быть уверено в том, что операция не попытается использовать результат до того, как его сгенерирует порождающая операция, аппаратному обеспечению не нужны функции внутренней блокировки (interlock) или «остановки».
Если, к тому же, компилятор может быть уверен в том, что операция не будет записывать свой результат до того, как истечет предполагаемая задержка, он может уплотнить план выполнения; компилятор может запланировать операцию-преемник (вне зависимости или в зависимости от результата) раньше на период времени, равный предполагаемой задержке операции. Процессоры VLIW традиционно используют преимущества такого подхода. NUAL служит своего рода гарантией соглашения между компилятором и аппаратным обеспечением о том, что обе стороны будут придерживаться принятых на себя обязательств. Если по каким-либо причинам реальные или истинные задержки процессора отличаются от предполагаемых, аппаратное обеспечение должно гарантировать корректную семантику программы, используя для этого механизмы, описанные в техническом отчете [4]. Мы назвали операцию с предполагаемой на архитектурном уровне задержкой в один такт операцией unit-assumed-latency (UAL). Операция UAL также не является атомарной.
MultiOp и NUAL - вот две важнейшие особенности передачи плана выполнения, созданного компилятором, аппаратному обеспечению. Они позволяют процессорам EPIC, которые либо не поддерживают внутреннюю блокировку, либо поддерживают , но с упорядочиванием, эффективно выполнять программы с значительным уровнем ILP.
Решение задачи переходов
Многие приложения предусматривают большое число переходов. Задержка перехода (branch latency), измеряемая числом тактов процессора, растет по мере увеличения тактовой частоты, в силу чего и возникают серьезная нехватка производительности. Операции перехода имеют аппаратную задержку, которая исчисляется с момента начала выполнения перехода до того момента, как начинает выполняться команда по адресу перехода. Во время этой задержки осуществляется несколько действий. Аппаратное обеспечение вычисляет условие перехода, формирует адреса перехода, выбирает команды либо обходя переход, либо выбирая нужный путь, а затем декодирует и выдает следующую команду. Хотя традиционные ISA указывают переход как единую операцию, предпринимаемые действия, на самом деле, выполняются в разное время, которое и определяет задержку перехода.
Невозможность параллельного выполнения приемлемого числа операций с ветвями значительно снижает производительность. Особенно это неприятно для процессоров с «широкими командами», которые могут потратить множество слотов выдачи для каждого такта задержки перехода. EPIC допускает создание статических планов выполнения с целью добиться максимально перекрывающейся обработки перехода и осуществления других вычислений, предоставляя архитектурные возможности, которые поддерживают следующие три функции.
- Выделение операций, составляющих переходы, которые указывают, когда выполняется каждое действие перехода.
- Поддержка исключения переходов.
- Улучшенная поддержка статического перемещения операций через несколько переходов.
Разделенные переходы. Переходы в EPIC разделяются на три компонента:
- подготовка-к-переходу, которая вычисляет адрес перехода;
- сравнение, которое определяет условие перехода;
- реальный переход, который указывает, когда передается управление.
Компилятор может планировать операции подготовки-к-переходу и сравнения задолго до момента реального перехода, чтобы своевременно предоставить информацию аппаратному обеспечению перехода. При выполнении подготовки-к-переходу аппаратное обеспечение может осуществлять предварительную спекулятивную загрузку команд по адресу перехода. После выполнения операции сравнения, аппаратное обеспечение может определить, будет ли выбран данный переход, отказаться от необязательной предварительной спекулятивной загрузки команд, а также запустить неспекулятивную предварительную загрузку. Эти механизмы допускают перекрывающуюся обработку компонентов перехода, в то же время полагаясь только на статическое перемещение компонентов перехода.
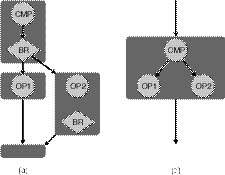 |
| Рис. 1. Использование предикатного выполнения для реализации if-conversion. (a) В этой конструкции if-then-else фоном указан базовый блок. Черные стрелки представляют поток управления, а пунктирные стрелки определяют зависимость данных. (b) if-conversion удаляет ветвь и порождает только один базовый блок, содержащий операции, контролируемые соответствующими предикатами. |
Предикатное выполнение (predicated execution). EPIC сокращает отрицательное влияние переходов на производительность за счет удаления переходов, используя предикатное выполнение благодаря применению методики компиляции, известной как if-conversion. При предикатном выполнении операции выполняются условно, в зависимости от параметра, имеющего булево значение - предиката, связанного с базовым блоком, содержащим операцию. Операции сравнения вычисляют предикаты, которые получают значение «истина», если программа достигнет соответствующих базовых блоков в блок-схеме, и имеют значение «ложь» в противном случае. Семантика операции, контролируемой предикатом p такова, что операция выполняется как обычно, если p - «истина», но если p - «ложь», процессор отменяет операцию.
Простой пример if-conversion показан на рисунке 1. На рисунке 1a приведена блок-схема для конструкции if-then-else, а на рисунке 1b - полученный в результате применения if-conversion код. Одна операция сравнения в EPIC вычисляет дополняющие друг друга предикаты, каждый из которых контролирует операции в одной из ветвей, определяемых условным оператором.
Преобразованный с помощью if-conversion код не содержит переходов и легко планируется в параллель с другим кодом, часто выявляя намного «больше» параллелизма на уровне команд. Преобразование if-conversion особенно эффективно, когда ветви не имеют значительных отклонений в ту или другую сторону и условные операторы содержат немного операций.
Спекулятивное управление (control speculation). Операции перехода серьезно препятствуют изменению порядка операций, который необходим для эффективного планирования выполнения программ. Помимо предикатного выполнения EPIC предоставляет еще одну возможность, позволяющую переносить операции через переходы - выполнение, спекулятивное по управлению. Рассмотрим фрагмент программы, представленный на рисунке 2a, который содержит два базовых блока. Выполнение, спекулятивное по управлению, показано на рисунке 2b; OP1 переносится из второго базового блока в первый, чтобы сократить соответствующую «глубину» программного графа. Операция получает метку OP1*, которая показывает, что необходим код спекулятивно выполняемой операции.
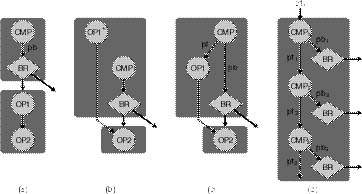 |
| Рис. 2. Пример перемещения кода вверх через один или несколько переходов. (a) Исходный код содержит два последовательных базовых блока фон. OP1 переносится выше перехода с помощью либо (b) выполнения, спекулятивного по управлению, либо (c) применения предикатов. (d) Использование полностью разрешенных предикатов порождает код без управляющих зависимостей между переходами, а также между переходами и другими операциями. Отсутствие этих управляющих зависимостей порождает область кода с многими переходами, которая допускает очень большую свободу планирования выполнения. |
При том, что статическое спекулятивное выполнение позволяет добиться более высокой степени ILP, оно требует аппаратной поддержки при обработке исключений. Если операция сразу сообщает о спекулятивном исключении, исключение может оказаться ложным. Такое возможно, если OP1* сообщает об исключении, а последующая ветвь при этом выбирается. Исключение ложное потому, что о нем было сообщено, несмотря на то, что OP1 в исходной программе на рисунке 2a даже не была бы выполнена.
EPIC позволяет избежать ложных исключений за счет применения кодов спекулятивно выполняемых операций и помеченных тегами операндов. Когда спекулятивно выполняемая операция (такая, как OP1* на рисунке 2b) вызывает исключение, она не сообщает об исключении сразу. Вместо этого операция генерирует операнд, который помечается тегом как ошибочный. Она сообщает об исключении позже, когда ошибочный операнд использует неспекулятивно выполняемая операция. Если ветвь была пропущена, OP2 корректно сообщает об исключении, сгенерированным операцией OP1*. Если ветвь была выбрана, ошибочный операнд игнорируется и об исключении не сообщается.
Предикатное перемещение кода. Процессор EPIC не поддерживает спекулятивное выполнение таких операций, как переход и сохранение в памяти, поскольку это вызывает краевые эффекты, которые нелегко ликвидировать. Вместо этого EPIC использует предикатное выполнение, которое допускает неспекулятивное перемещение операций через переходы. На рисунке 2c показано перемещение через переход операции OP1. Однако, в этом примере, OP1 остается неспекулятивной, потому что она контролируется предикатом, соответствующим отрицанию условия выхода из ветви (pf = не pb). Как и в исходной программе, OP1 выполняется только в том случае, если переход не выбран.
EPIC допускает неспекулятивное перемещение кода через несколько переходов. Компилятор может каскадировать операции сравнения, которые вычисляют предикаты через несколько переходов, как показано на рисунке 2d. Каждое сравнение оценивает имеющееся условие (на рисунке не показано) и вычисляет предикаты для перехода (pbi) и для базового блока, достигаемого, когда переход пропускается (pfi). Предикат перехода (pbi) содержит значение «истина», когда предикат предыдущего базового блока (pf i-1) содержит значение «истина» и когда условие выхода из перехода не выполнено. Мы называем предикаты, которые вычисляются над многоблочной областью, полностью разрешенными предикатами (fully resolved predicate - FRP).
Когда предикаты для последующих ветвей в линейной последовательности вычисляются как FRP, они взаимно исключают друг друга - самое большее может быть истинным только один предикат и выбран только один переход. Операции перехода и другие неспекулятивные операции теперь легко переупорядочить; они свободно перемещаются в слоты задержки (delay slots) предыдущих ветвей или через предыдущие переходы. Если переходы, в конечном итоге, запланированы так, что они выполняются одновременно, взаимное исключение гарантирует корректное поведение. Когда компилятор предлагает неспекулятивные операции, используя FRP, он заменяет зависимости между переходами на соответствующие зависимости между операндами предикатов. Для оптимизации плана выполнения планировщик поддерживает как спекулятивное, так и неспекулятивное перемещение операций.
Использование FRP позволяет заменить зависимости между последовательностями переходов на зависимости между последовательностями сравнений; каждая операция сравнения объединяется с дополнительным булевым выражением. Глубина зависимости выражений FRP может быть сокращена за счет других возможностей EPIC (аппаратных операций сравнения AND и OR [4]) с тем, чтобы ускорить оценку содержащих несколько термов конъюнкций и дизъюнкций, которые возникают в выражениях FRP.
Задача адресации памяти
Доступ к памяти также может негативно повлиять на производительность. Поскольку длительность такта процессора уменьшается быстрее, чем время доступа к памяти, то время доступа к памяти (измеряемое в тактах процессора) растет. Это увеличивает длину критически важных путей в планах программы. Кэш данных может помочь сократить снижение производительности за счет увеличения задержки оперативной памяти. Однако аппаратно управляемый кэш иногда способен снизить производительность настолько, что она становится меньше производительности системы без кэша.
EPIC обеспечивает архитектурные механизмы, которые позволяют компиляторам точно контролировать перемещение данных в иерархии кэш. Эти механизмы могут выборочно перекрывать аппаратные правила, задаваемые по умолчанию. Для данной статьи мы предполагаем следующую видимую для архитектуры структуру кэша данных. На первом уровне, ближе всего к процессору, располагаются традиционная кэш-память первого уровня и кэш предварительной выборки данных (или потоковый кэш). На следующем уровне размещается традиционный кэш второго уровня.
Спецификаторы кэша. В отличие от других операций, на длительность загрузки могут влиять несколько различных задержек, в зависимости от уровня кэш-памяти, в которой размещаются указываемые данные. Для загрузки NUAL компилятор должен сообщить аппаратному обеспечению конкретную задержку, которая предполагается для каждой операции загрузки. С этой целью, EPIC предоставляет операции загрузки со спецификатором кэша-источника, который компилятор использует для информирования аппаратного обеспечения о том, где именно в иерархии кэш можно предположительно найти указываемые данные и, косвенно, сообщает предполагаемую задержку. Чтобы сгенерировать высококачественный план выполнения, компилятор должен проделать большую работу по прогнозированию того, какая задержка будет у каждой операции загрузки (а затем сообщить это аппаратному обеспечению, используя спецификатор кэша-источника), чтобы для каждой операции загрузки предсказать уровень кэш-памяти, где, вероятнее всего, можно найти указываемые данные.
Операции загрузки и сохранения EPIC также предоставляют спецификатор кэша-адресата, который компилятор использует для того чтобы показать, в кэш-память какого уровня операции загрузки или сохранения должны перенести (на уровень вверх или на уровень вниз) указываемые данные для того, чтобы те были использованы последующими операциями, предусматривающими работу с памятью. Спецификатор кэша-адресата сокращает число неудачных обращений к кэшу первого и второго уровней за счет управления содержимым этих кэшей. Компилятор может извлечь данные с неэффективной «временной локализацией» из кэша первого или второго уровней и может удалить данные из кэша того уровня, где они последний раз использовались.
Кэш предварительной выборки данных позволяет перенести данные с небольшой временной локализацией в кэш с низкой задержкой, не меняя содержимое кэш первого уровня. Программа может предварительно извлечь данные, используя несвязывающую загрузку, которая указывает кэш предварительной выборки как кэш-адресат. Несвязывающая загрузка не записывает данные ни в один регистр; ее цель - перенести данные внутри иерархии кэш-памяти. Перенос данных в кэш предварительной выборки вместо кэша первого уровня позволяет программе предварительно загружать большие потоки данных и загружать их быстро, без перемещения содержимого кэша первого уровня. Операции несвязывающей загрузки могут также использовать кэш первого или второго уровня как свой кэш-адресат, позволяя выполнять предварительную загрузку в другие кэши.
Выполнение, спекулятивное по данным (data speculation). Еще одно препятствие на пути создания хорошего POE возникает из-за маловероятных зависимостей между ссылками в память. Часто компилятор не может статически определить, что ссылки указывают на различные адреса в памяти и должен опираться на более безопасное предположение о том, что они указывают на один и то же адрес, даже если на самом деле это в общем не так. Выполнение, спекулятивное по данным, позволяет компилятору генерировать планы выполнения программ, которые предполагают, что операции сохранения и последующей загрузки используют разные адреса в памяти, даже если вероятность этого события небольшая.
Выполнение, спекулятивное по данным, разделяет традиционную загрузку на две операции: команду спекулятивной загрузки данных (data-speculative load) и команду загрузки данных с проверкой (data-verifying load). Компилятор перемещает команду спекулятивной загрузки данных выше команды сохранения, которая потенциально записывает данные по тому же адресу, чтобы загрузка началась вовремя, в соответствии с планом выполнения. Компилятор планирует последующую команду загрузки данных с проверкой после команды сохранения, которая потенциально записывает данные по тому же адресу, и использует аппаратное обеспечение для проверки, насколько вероятно возникновение ситуации, в которой операции загрузки и сохранения используют один и тот же адрес. Если подобной ситуации не возникает, это значит, что команда спекулятивной загрузки данных загрузила корректное значение и команде загрузки данных с проверкой делать нечего, поэтому выполнение осуществляется с максимальной эффективностью. Когда же операции загрузки и сохранения обращаются по одному и тому же адресу, команда загрузки данных с проверкой повторно выполняет загрузку и приостанавливает процессор, чтобы гарантировать своевременное получение корректных данных для их последующего использования в соответствии с планом программы. Кроме того, EPIC также поддерживает более активное спекулятивное перемещение кода, когда компилятор переносит не только операции спекулятивной загрузки данных, но, вдобавок, и операции, которые используют их результат, выше операций сохранения, которые потенциально могут использовать тот же адрес в памяти [4].
В короткой статье невозможно полностью проиллюстрировать все функции EPIC и то, как они используются. Заинтересованный читатель найдет более полное описание в нашем техническом отчете [4]. Среди других тем в нем также обсуждаются стратегии обеспечения совместимости объектного кода на различных процессорах семейства EPIC. При этом следует учитывать два фактора. Во-первых, операционные задержки, предполагаемые компилятором при генерации кода для одного процессора, могут не совпадать с аналогичными характеристиками для другого и, во-вторых, предполагаемый и реальный параллелизм (в терминах числа функциональных устройств) могут различаться. Все методики, используемые суперскалярными процессорами, применимы и к этой архитектуре; однако, EPIC позволяет создавать относительно недорогие программные решения этой проблемы, предоставляя компилятору возможность играть более важную роль в обеспечении совместимости.
Заключение
За последние десять лет сравнение достоинств VLIW и суперскалярных архитектур было основной темой в дискуссиях специалистов по вопросам ILP. Сторонники той и другой концепции сводят это обсуждение к противопоставлению простоты и ограниченных возможностей VLIW сложности и динамическим возможностям суперскалярных систем. Такое противопоставление в корне неверно. Совершенно ясно, что оба подхода имеют свои достоинства и говорить об их альтернативности не уместно. Очевидно, что создание плана выполнения во время компиляции существенно для обеспечения высокой степени распараллеливания на уровне команд, даже для суперскалярного процессора. Также ясно и то, что во время компиляции существует неоднозначность, которую можно разрешить только во время выполнения, и для решения этой задачи процессор требует наличия динамических механизмов. Сторонники EPIC согласны с обеими этими позициями. Различие только в том, что EPIC предоставляет эти механизмы на уровне архитектуры так, что компилятор может управлять такими динамическими механизмами, применяя их выборочно там, где это возможно. Столь широкие функции управления дают компилятору возможность использовать правила управления этими механизмами более оптимально, чем это позволяют аппаратные возможности.
Основные принципы EPIC, наряду с возможностями архитектуры, которые их поддерживают, обеспечивают средства определения ILP-архитектур и процессоров, позволяющих добиться более высокой степени ILP при меньшей сложности аппаратуры в самых разных прикладных областях. IA-64 - пример того, как принципы EPIC могут применяться к вычислительными системам общего назначения - области, где совместимость объектного кода имеет критически важное значение. Однако мы уверены в том, что EPIC будет играть столь же важную роль и на рынке высокопроизводительных встроенных систем. В этой области более жесткие требования к соотношению цена/производительность и при этом более низкие требования к совместимости на уровне объектных модулей, что заставляет использовать более настраиваемые архитектуры.
Исходя из этой уверенности, HP Labs четыре года назад начала реализацию исследовательского проекта PICO (Program In, Chip Out). В рамках этого проекта разработан прототип, который, наряду с другими возможностями, способен на основе встроенных приложений, написанных на стандартном языке Си, автоматически проектировать архитектуру и микроархитектуру процессора EPIC, адаптированного к конкретному приложению на языке Си [8].
Коммерческая версия такой технологии EPIC для встроенных систем - дело будущего. В то же время, EPIC дает новые надежды на то, на что мы все рассчитываем - на устойчивый рост производительности микропроцессоров общего назначения на наших приложениях без кардинального переписывания этих приложений.
Благодарности
Так много людей принимали участие в создании EPIC и PA-WW, и делали это столь различными способами, что мы вынуждены ограничиться благодарностью только в адрес тех, кто существенно повлиял на один аспект всего предприятия в целом: разработку и определение типа архитектуры EPIC. Среди этих людей Билл Ворли, Раджив Гупта, Винод Катхайл, Алан Карп и Рик Эмерсон. Активная поддержка Джошем Фишером принципов и набора возможностей EPIC существенно сказалась на проектировании PA-WW. Нельзя не отметить Дика Лемпмана, принимавшего активное участие во всех проектах HP Labs, и который еще в 1998 году оказался настолько предусмотрительным, что приобрел права на интеллектуальную собственность Cydrome (в то время, когда VLIW почти всеми считалась ошибочной концепцией) и начал реализацию проекта FAST. Впоследствии, как менеджер проекта SWS, Дик отвечал за эволюцию научных идей в работе над определением PA-WW.
Об авторах
Майкл С. Шланскер - сотрудник Hewlett-Packard Laboratories. К кругу его научных интересов относятся компьютерная архитектура, компиляторы и проектирование встроенных систем. С ним можно связаться по адресу schlansk@hpl.hp.com.
Б. Рамакришна Рау - старший технический специалист лаборатории Hewlett-Packard Laboratories. Он занимается компьютерной архитектурой, компиляторами и автоматизацией проектирования компьютерных систем. С ним можно связаться по адресу rau@hpl.hp.com.
Что такое EPIC ISA?
К архитектуре EPIC можно отнести множество самых разных ISA. Помимо включения или исключения той или иной характеристики архитектуры, которую мы обсуждаем, проектировщики процессоров должны принимать традиционные решения по таким вопросам, как набор кодов операций, диапазон поддерживаемых типов данных и количество используемых регистров. Тем не менее, определенная идеология объединяет все такие ISA. Любая архитектура, относящаяся к классу EPIC должна реализовывать общую идеологию EPIC, которая определяется тремя основными принципами:
- компилятор должен играть ключевую роль в создании плана выполнения (plan of execution- POE), а архитектура должна обеспечивать поддержку необходимых для этого компонентов;
- архитектура должна обеспечивать функции, которые помогают компилятору в использовании статических ILP;
- архитектура должна обеспечивать механизм для передачи плана выполнения компилятора аппаратному обеспечению.
В подробном техническом отчете [4] можно найти более детальное описание EPIC и ее характеристик, в том числе стратегии EPIC, касающейся совместимости объектного кода.
История создания архитектуры EPIC
Хотя EPIC была создана группой инженеров лаборатории Hewlett-Packard Laboratories, эта архитектура базируется на VLIW и разработках, подготовленных за последние 25 лет, еще до появления VLIW. В частности, EPIC основана на архитектурных идеях, впервые реализованных компаниями Cydrome и Multiflow. У Multiflow были позаимствованы такие концепции, как аппаратная поддержка спекулятивного по управлению выполнения команд загрузки, способность одновременно выдавать несколько операций перехода, наделенных приоритетами, а также формат команд VariOp.
От Cydrome архитектура EPIC унаследовала следующие концепции:
- предикатное выполнение, которое с тех пор было реализовано также в процессорах TriMedia компании Philips, VelociTI компании Texas Instruments и RISC-процессорах компании ARM;
- поддержка технологии, получившей название программной конвейеризации циклов в виде вращаемых регистров и специальных переходов, завершающих цикл;
- приостановка задержки (latency stalling) и регистр задержки памяти;
- возможность выполнять несколько независимых переходов одновременно;
- аппаратная поддержка выполнения, спекулятивного по управлению, в том числе концепции кодов спекулятивно выполняемых операций, бита тега спекулятивной ошибки в каждом регистре, а также отложенной обработки исключений (идеи, которые были независимо разработаны Кемалем Эбсиоглу и его коллегами в IBM Research и впоследствии в рамках проекта Impact университета штата Иллинойс);
- вспомогательный формат команд MultiTemplate.
Более ранним и оказавшим большое влияние на развитие этой концепции был проект Stretch компании IBM, который согласно Хербу Шорру, ввел многие понятия суперскалярной архитектуры, в том числе код операции «подготовки-к-переходу», буферы адресов переходов и предсказание перехода наряду с предварительной спекулятивной загрузкой команд.
Проекты FAST и SWS
В начале 1989 года в HP Labs приступили к реализации исследовательского проекта FAST (Fine-Grained Architecture and Software Technologies). Его цель состояла в развитии архитектуры VLIW, которая до этого была ориентирована преимущественно на числовые вычисления, в архитектуру общего назначения. Именно эту архитектуру после образования альянса HP-Intel Alliance стали называть EPIC.
Кроме того, в лаборатории HP Labs была запланирована на год программа SWS (Super Workstation), в рамках которой предполагалось определить преемника архитектуры PA-RISC. Билл Ворли стал главным проектировщиком этой новой архитектуры, которую сотрудники HPL назвали PA-WW (Precision Architecture-Wide Word).
Цели этих двух проектов дополняли друг друга. Обе команды вскоре начали совместно создавать тип архитектуры EPIC, а также работать над спецификациями PA-WW.
Каждый проект также предусматривал и другие направления деятельности. К примеру, в рамках проекта FAST готовился компилятор EPIC. А программа SWS рассматривала вопросы, имеющие критически важное значение для PA-WW, такие как архитектура устройства выполнения операций с плавающей запятой, создание пакетов и поддержка ОС.
Проекты оказали существенное влияние друг на друга. В SWS были использованы архитектурные решения и открытия, сделанными в рамках FAST. Критически важные вопросы, которые решала программа SWS, определили направления исследований в FAST, а обсуждения, проводимые группой SWS, обогатили работу группы FAST. В рамках этого сотрудничества и было выработано большинство характеристик, определяющих современную архитектуру EPIC.
Новшества EPIC
Группа, создававшая EPIC, усовершенствовала предикатную архитектуру системы Cydra 5 компании Cydrome, включив в ее состав аппаратно реализованные операции сравнения OR и AND с установкой предикатов, а также возможность использования двухзначных сравнений. Мы также расширили поддержку переходов в EPIC для реализации программной конвейеризации и вращения регистров для обработки циклов WHILE, а также расширили и оптимизировали архитектурную поддержку спекулятивного по управлению выполнения команд, разработанную для будущего продукта компании Cydrome - Cydra 10, который, однако, так никогда и не был выпущен. Мы также разработали концепцию выполнения, спекулятивного по данным и ее архитектурную поддержку. И опять-таки, позже выяснилось, что эта идея независимо была разработана в рамках проекта Impact, а также Эбсиоглу и его коллегами в IBM Research.
Мы расширили возможность обхода кэша данных при обращении к данным с низкой временной локализацией, предложенную компанией Convex в C2 и Intel в i860, для работы с многоуровневой иерархией кэш-памяти. Дополнительные архитектурные новшества, связанные с иерархией кэш-памяти для хранения данных, включали в себя спецификаторы кэша-источника (или задержки) и кэша-адресата. Мы расширили концепцию подготовки к переходу до трехкомпонентной архитектуры несвязанных переходов, определяемой понятием предикатов. И, наконец, мы разработали методику обеспечения совместимости объектных кодов.
В начале 1994 года для того чтобы стимулировать и упростить создание компилятора для процессоров EPIC, в рамках проекта FAST была опубликована спецификация архитектуры HPL-PD, которая определила общее пространство архитектур типа EPIC. С другой стороны, к концу 1993 года в рамках проекта SWS была создана спецификация архитектуры PA-WW. Этот документ определил конкретную EPIC ISA, которую группа SWS предложила группе компьютерных продуктов компании HP в качестве преемника архитектуры PA-RISC. Эта ISA содержала целый ряд других новшеств, которые выходят за рамки данной статьи.
В 1993 году HP начала программу проектирования, разработки и производства микропроцессоров PA-WW. Короткое время спустя HP и Intel начали вести переговоры о совместном определении архитектуры, которая могла бы стать преемником и архитектуры IA-32 компании Intel, и архитектуры PA-RISC компании HP. После того, как в июне 1994 года была начата совместная деятельность, HP прекратила работу над PA-WW. Вместо этого обе компании начали готовить ISA для IA-64, используя в качестве отправной точки PA-WW. Со своей стороны, IA-64 решает вопросы, возникающие в связи с тем, что новая архитектура должна стать преемником архитектуры IA-32, а также содержит другие решения, описанные в документе IA-64 Application Developer?s Architecture Guide.
Литература
[1] IA-64 Application Developer?s Architecture Guide, Intel Corp., 1999.
[2] M. Schlansker et al., Achieving High Levels of Instruction Level Parallelism with Reduced Hardware Com-plexity, HPL Tech. Report HPL-96-120, Hewlett-Packard Laboratories, Feb. 1997.
[3] V. Kathail, M. Schlansker, and B.R. Rau, HPL-PD Architecture Specification: Version 1.1. Tech. Report HPL-93-80 (R.1), Hewlett-Packard Laboratories, Feb. 2000; впервые опубликован как HPL PlayDoh Architecture Specification: Version 1.0, Feb. 1994.
[4] M.S. Schlansker and B.R. Rau, EPIC: An Architecture for Instruction-Level Parallel Processors, HPL Tech. Report HPL-1999-111, Hewlett-Packard Laboratories, Jan. 2000.
[5] R.P. Colwell et al., A VLIW Architecture for a Trace Scheduling Compiler, IEEE Trans. Computers, Aug. 1988, pp. 967-979.
[6] B.R. Rau et al., The Cydra 5 Departmental Supercomputer: Design Philosophies, Decisions, and Trade-Offs, Computer, Jan. 1989, pp. 12-35.
[7] G.R. Beck, D.W.L. Yen, and T.L. Anderson, The Cydra 5 Mini-Supercomputer: Architecture and Implementa-tion, J. Supercomputing 7, May 1993, pp. 143-180.
[8] S. Aditya, B.R. Rau, and V. Kathail, Automatic Architectural Synthesis of VLIW and EPIC Processors, Proc. 12th Int?l Symp. System Synthesis, IEEE CS Press, Los Alamitos, Calif., 1999, pp. 107-113.
