
Микропроцессоры архитектуры x86 и компьютерные системы на их базе продолжают вытеснять с рынка всех конкурентов. Став 64-разрядными, эти процессоры лишили альтернативы из лагеря RISC (и пост-RISC) главного козыря. Новыми лидерами по многим техническим параметрам стали представленные нынешним летом процессоры Intel с микроархитектурой Core.

Учитывая относительную дешевизну всей аппаратной инфраструктуры компьютерных систем на платформе х86, нетрудно предположить дальнейшее увеличение доли х86 на рынке. Ничего не мешает строить самые мощные многопроцессорные серверы и даже суперкомпьютеры на 64-разрядном расширении IA-32 (EM64T или x86-64). По производительности на «целочисленных» задачах х86 давно впереди, и лишь на плавающей точкой лидирует IBM Power5+.
В настоящее время ограничением остается адресуемая физическая память. 36 разрядов адреса в новейших серверных процессорах Intel Woodcrest отвечает емкости оперативной памяти 64 Гбайт. В Intel Xeon MP и AMD Opteron эти адреса 40-разрядные; это позволяет обращаться к 1 Тбайт памяти, что, однако, для сверхбольших сcNUMA-серверов уже недостаточно. Для виртуальной адресации Woodcrest и Opteron используют 48 разрядов.
Представленные летом 2006 года х86-процессоры Intel с новой микроархитектурой Сore впервые за последние годы резко опередили процессоры AMD по производительности, обладая при этом более низкоим энергопотреблением.
Микроархитектура Core
Микроархитектура Pentium 4 NetBurst и ее последняя модификация в процессорах Prescott/Nocona были суперконвейерными, нацеленными на максимальные тактовые частоты. Корпорация Intel выпускала уже и двухъядерные процессоры, однако их микроархитектура не была специально оптимизирована для достижения высокой производительности при низком энергопотреблении. Для многоядерных процессоров с более низкими частотами ее понадобилось существенно переделывать, и была создана новая микроархитектура, Core. В ней число стадий основного, целочисленного конвейера было уменьшено более чем вдвое — до 14. Интересно, что почти столько же стадий имеет IBM Power4 — 15, в AMD Opteron — 12 стадий [1, 2]. Самый короткий конвейер в Sun UltraSPARC T1 (шесть стадий), но отдельные его ядра не нацелены на максимум производительности, а тактовая частота не превышает 1,2 ГГц [3].
Конечно, много важных компонентов микроархитектуры остались в Core неизменными. Можно сказать, что базовые особенности были заложены еще в суперскалярном процессоре Pentium Pro, когда появилась перекодировка CISC-команд x86 во внутренние RISC-подобные микрооперации, внеочередное (Out of Order, OoO) спекулятивное выполнение микроопераций из буфера переупорядочения (ReOrder Buffer, ROB) и др.
Однако в распоряжении разработчиков Core были сразу две разные микроархитектуры — кроме «высокочастотной линии» NetBurst-Prescott-Pentium D (двухъядерный процессор для ПК) и Dempsey (двухъядерный серверный процессор Xeon DP), имелись еще израильские разработки Pentium M — Core Duo (бывшее кодовое название Yonah) для мобильных ПК, в которых частоты и тепловыделение ниже. И микроархитектура Core взяла лучшие черты от обеих линий.
Основные усовершенствoвания микроархитектуры Core ее разработчики условно объединили в пять групп [5, 6]. Рассмотрим их.
1. Wide Dynamic Execution. Эти усовершенствования направлены на рост показателя IPC (количество выполняемых за такт команд). В микроархитектуре предшественников Core из RISC-команд за такт декодировалось до четырех микрокоманд в блок переименования и распределения регистров и в ROB поступало до трех микрокоманд, и завершалось до трех микроопераций за такт; таким образом, максимум IPC был равен трем. (В Yonah этот показатель равнялся шести: две микрооперации за счет двух простых декодеров плюс четыре микрооперации за счет выборки запасенной последовательности микроопераций из постоянной памяти декодера сложных x86-команд.) В Core может декодироваться до семи микроопераций за такт, в том числе три простыми декодерами. Далее на всем пути обработки микроопераций вплоть до их формального завершения (фиксация результатов) за такт проходят до четырех микроопераций (а из накопителя команд на выполнение в исполнительные устройства за такт направляется до шести микроопераций). Таким образом, максимум IPC равен четырем.
В процессорах Opteron декодируются и выдаются на выполнение до трех микроопераций за такт. Для сравнения, Power 5 выдает на выполнение до восьми команд и завершает выполнение до пяти команд за такт. Для высокого показатели IPC важны также емкости ROB и станции резервации, которые увеличены по сравнению с Yonah. В Pentium 4 нет накопителя команд, вместо него используются очереди планировщика (всего 46 строк) к разным портам устройств выполнения [4].
Остальные усовершенствования данной группы относятся к фронтальной части Core. Одно из них — модернизация ESP (Extended Stack Pointer) Tracker. Раньше этот блок задействовал АЛУ, а теперь во фронтальной части Core появились собственные сумматоры. Благодаря этому не только разгружается АЛУ, но и становится ненужным прохождение по конвейеру соответствующих микроопераций.
Два последних усовершенствования этой группы — объединение микроопераций и макроопераций (так в Intel называют CISC-команды). Объединение микроопераций в Pentium M. Объединяться вместе могут микрооперации, возникшие при декодировании одной CISC-команды. Исследования показали, что общее уменьшение числа выполняемых OoO-логикой микроопераций при этом может превышать 10%. Хотя основным предназначением объединения микроопераций считается уменьшение энергозатрат процессора, общее уменьшение числа микроопераций способствует и росту производительности.
Типичный пример такого объединения в Pentium M — объединение пар микроопераций, порождаемых декодерами из команд загрузки регистров (L) и записи в память ST [7]. К примеру, ST декодируется в две микрооперации — запись адреса и запись данных. Первая рассчитывает адрес памяти, куда будет производиться запись, и выполняется в устройстве генерации (записи) адреса. Вторая записывает данные в буфер записи, из которого они помещаются в оперативную память при фиксации результатов. Микрооперации пары могут выполняться одновременно в разных исполнительных устройствах, имеющих собственные порты диспетчеризации, но они рассматриваются как одна вплоть до выдачи этих микроопераций на выполнение. По завершении обеих микроопераций они снова рассматриваются как одна объединенная. В Core число микроопераций, которые могут объединяться, было расширено [5].
Объединяться могут и некоторые типовые пары CISC-команд (например, сравнение с последующим условным переходом). Поскольку вместо двух команд формируется одна микрооперация, общий объем работы процессора уменьшается, а производительность соответственно растет. Мало того, АЛУ исполнительной части процессора доработаны так, что объединенные микрооперации могут выполняться всего за один такт [5-6, 8].
Команды х86 извлекаются из 8-канального наборно-ассоциативного кэша команд первого уровня емкостью 32 Кбайт. При этом ширина тракта доступа к буферу выборки и предварительного декодирования в Core составляет не меньше 160 бит (это позволяет выбирать не менее пяти команд за такт), что существенно выше, чем в Yonah (128 бит). Емкость этого буфера составляет предположительно не менее десяти команд. Все команды мультимедийного расширения SSE обрабатываются простыми декодерами, генерирующими для этих команд всего одну микрооперацию [4]. Двухпортовый кэш данных первого уровня имеет такую же емкость (т.е. вдвое больше, чем в NetBurst) и число наборов, как и кэш команд. Число строк в буфере TLB также сильно возросло (табл. 1), что ускоряет работу приложений с большими рабочими множествами страниц памяти.
Предсказание переходов в Сore уходит своими корнями в линию Pentium M. Оно основывается на традиционных для Pentium 4 буфере «целей» перехода BTB, калькуляторе адресов перехода BAC и стеке адресов возврата RAS [9, 10]. Кроме этих средств в Core имеется еще два предсказателя.
Первый, детектор циклов, служит для правильного предсказания выхода из цикла. Обычное предсказание переходов на основе предыстории будет предсказывать очередное выполнение цикла. Чтобы предсказать выход из цикла, специальные счетчики отслеживают число итераций цикла до его завершения и используют эти данные в будущем для предсказания, когда из этого цикла следует выйти* [7].
Второй, предсказатель косвенных переходов, относится к переходам, адрес которых не кодируется в команде непосредственно, а задается содержимым регистра; такие переходы предсказывать сложнее. Этот предсказатель содержит таблицу, в которую заносятся вероятные адреса косвенных переходов. Когда фронтальная часть процессора обнаруживает косвенный переход и предсказывает, что он произойдет, он запрашивает эту таблицу, выбирая из нее соответствующий целевой адрес перехода [7].
Кроме того, в Core добавлена очередь, в которой записываются адреса произошедших переходов, что позволяет упразднить большинство однотактных «пузырей» (отсутствие работы) в конвейере, которые обычно возникали в предыдущих поколениях микроархитектуры в случае, если переход реально происходил [4].
2. Advanced Smart Cache. Усовершенствования этой группы затронули прежде всего кэш второго уровня, который является общим для обоих процессорных ядер. Такой подход уже доказал свою эффективность, например, в двухъядерных процессорах IBM Power. Применение общего кэша позволяет динамически распределять его емкость между ядрами. При этом исчезает необходимость дублировать общие для обоих ядер данные, как это происходит при использовании каждым ядром собственного кэша второго уровня.
Кроме того, в некоторых случаях имеет место существенное увеличение производительности по сравнению с раздельными кэшами ядер. Так, если ядро обращается к данным, которые находятся в кэше второго уровня другого ядра, то задействуется контроллер памяти (северный мост), что резко увеличивает задержки. В случае общего кэша второго уровня оказавшиеся в нем данные доступны для кэша первого уровня напрямую.
Кэши первого и второго уровня в Сore (как и в Yonah) используют обратную запись при длине строки кэша в 64 байт. Интересно, что кэш данных первого уровня в NetBurst использовал сквозную запись с той же длиной строки, но длина строки в кэше второго уровня была в два раза выше. Пропускная способность кэша первого уровня по сравнению с Yonah возросла вдвое [6].
В [11] на примере подпрограмм vpr и galgel (из SPECcpu2000) показано, что преимущества применения общего кэша второго уровня в Core для процессоров Conroe (набор микросхем i975) по сравнению с Presler с точки зрения пропускной способности памяти и эффективности использования FSB являются очень существенными.
3. Smart Memory Access. Эта группа нововведений Core связана с усовершенствованием доступа в память и направлена на увеличение пропускной способности памяти и уменьшение задержек. Основными здесь являются средства упразднения «неоднозначностей» оперативной памяти [5-6, 8].
Современные суперскалярные процессоры с OoO-выполнением команд могут одновременно выполнять несколько команд L/ST. Очень часто данные желательно загрузить заранее, чтобы скрыть потенциально большие задержки по доступу в память хочется перенести выполнение соответствующих команд L пораньше, возможно, до выполнения команд ST, как в данном фрагменте команд:
(1) ST в X
(2) команды АЛУ
(3) SТ в ?
(4) ST в Y
(5) L из X
Очевидно, выполнение команды (5) можно перенести до команды (4) (конечно, если поля оперативной памяти, задаваемые адресами Х и Y, не перекрываются), но нельзя — до команды (1). Однако на момент планирования выполнения адрес памяти в команде (4) еще не известен, что помечено знаком вопроса.
Упразднение неоднозначностей оперативной памяти — это процесс определения, не совпадает ли адрес в ST с адресом последующей команды L. В Pentium Pro для решения этой проблемы команды ST декодировались в две микрооперации, одна из которых рассчитывала адрес, а вторая производила собственно запись в память. Для обеспечения возможности OoO-обработки команд L и ST еще со времен этого процессора в Intel используют буфер MOB. Если возникает совпадение адресов, как в командах (1) и (5), L вперед не переносится, а если совпадения нет, как в командах (4) и (5), такой перенос возможен. Переносы одной команды ST вперед другой не осуществляются.
Однако остаются случаи, когда адрес памяти к моменту выполнения L еще не определен, и тогда в Pentium Pro перенос L не выполняется. Исследования показывают, что для процессора, похожего на Alpha EV6, даже с 512 выполняемыми на лету командами*, в 97% случаев команды L не зависят от предыдущих команд ST [4]. Поэтому желательно задействовать этот потенциал увеличения производительности и выполнять подобные cпекулятивные переносы, но затем проверять, не был ли совершен некорректный перенос. Ранее подобное спекулятивное OoO-выполнение было реализовано, например, в IBM Power4/Power5 [1], а в проекте Alpha EV8 планировалось спекулятивное OoO-выполнение команд ST.
Если перенос L осуществлен некорректно, приходится выполнять часть команд заново, перезагружая конвейер. Чтобы уменьшить вероятность подобных ситуаций, в Core реализовано динамическое предсказание на основе предыстории. Проверка корректности переноса осуществляется на стадии завершения микроопераций.
В [4] приведены некоторые грубые оценки возможного улучшения производительности. По содержащимся там данным, точность предсказания в Core превышает 90%, что выглядит малоинформативным с учетом уже приведенной оценки об отсутствии взаимозависимости в 97%. Чтобы оценить сравнительную эффективность OoO-выполнения команд работы с памятью в Core и в Power4/Power5.
Еще один компонент из данной группы усовершенствований — это устройства упреждающей загрузки (prefetcher). Таких устройств имеется по два в кэше данных первого уровня каждого ядра, по одному — в кэшах команд первого уровня. Эти устройства могут одновременно обрабатывать несколько шаблонов, указывающих, откуда и каким образом (например, с фиксированным шагом по адресам) осуществляется загрузка данных. Еще есть два общих для ядер устройств упреждающей загрузки в кэше второго уровня, которые динамически разделяются ядрами и также могут отслеживать несколько шаблонов на ядро [6]. Выделение этих устройств ядрам осуществляется по модифицированной схеме кольцевой очереди (round-robin) с учетом активности доступа ядер в оперативную память; арбитраж FSB также обеспечивает при этом «справедливое» распределение ядрам полосы пропускания [4]. Результат всех этих действий — уменьшение задержек при работе с памятью.
4. Advanced Digital Media Boost. Эта группа усовершенствований формально относится к улучшенной цифровой обработке мультимедийной информации, но на самом деле ее значение шире; она охватывает также работу с плавающей точкой как таковой. Дело в том, что «классическая» работа с плавающей точкой, предполагающая применение традиционных команд х87, в последнее время вытесняется за счет применения возможностей работы с плавающей точкой в рамках мультимедийного расширения команд (SSE/SSE2/SSE3). Они допускают обработку векторов (длиной два или четыре элемента) из чисел с плавающей точкой одинарной или двойной точности, причем в последнем случае речь идет об использовании «обычных» 64-разрядных чисел, а не собственного 80-разрядного представления Intel.
Хотя, конечно, MMX (векторные целочисленные операции) и команды всех SSE-расширений в целом ориентированы на обработку медийной информации (речи, изображения, видео и пр.), они с успехом применяются для решения финансовых задач, в криптографии, в научно-технических расчетах и т.д.
Мы рассмотрим данные усовершенствования в Core в общем контексте работы исполнительных устройств. Всего таких устройств в Core девять, из них три целочисленных, в том числе одно для сложных команд (по функциям похоже на аналогичный блок в Pentium Pro), и два простых для простых операций наподобие сложения, одно из которых разделяет общий порт с устройством обработки переходов. Совместная работа с этим портом двух последних устройств позволяет им выполнять объединенные макрооперации типа «сравнить и перейти». Целочисленное устройство на порту 1 умеет выполнять 128-разрядные операции сдвига и вращения (циклический сдвиг).
Впервые процессоры Intel получили возможность выполнять целочисленные операции за один такт, а пропускная способность Core составляет три целочисленные операции за такт. Для сравнения, в PowerPC 970 время выполнения целочисленных операций составляет два такта [7]. Эти особенности позволили Woodcrest стать абсолютным лидером по целочисленной производительности.
Что касается плавающей точкой, то в Core имеется три 128-разрдных SSE-устройства и два 128-разрядных устройства с плавающей точкой (для сложения и умножения/деления). Последние могут работать как со скалярами, так и с векторами длиной два или четыре элемента в зависимости от точности. Устройства с плавающей точкой и SSE-устройства разделяют общую аппаратуру там, где это представляется естественным. Команды FPmovе могут выполняться одновременно на всех трех портах. Теперь за такт можно одновременно выполнить 128-разрядное сложение, 128-разрядное умножение (с плавающей точкой), 128-разрядную загрузку, 128-разрядную запись и еще скажем объединенную макрокоманду «сравнить и перейти» [4, 6]. Это почти полное тело небольшого цикла!
Слабым местом NetBurst была, в свое время, неполная конвейеризация умножения с плавающей запятой, когда один результат появлялся только на каждом втором такте [9]. SSE-операции над 128-разрядными величинами в Pentium 4 также были не полностью конвейеризированы, а в Yonah SSE работают с 64-разрядными трактами, что также дает один результат за два такта.
В Core все сделано полностью конвейеризированным, и ядро может выдавать по два 64-разрядных результата с плавающей точкой за такт на каждом устройстве, т.е. всего четыре результата за такт [6]. Это вдвое выше, чем в Opteron (такую же пропускную способность имеют Power4 и Power5), и AMD вплоть до появления будущих процессоров K8L, очевидно, будет сильно отставать.
Необходимо упомянуть новое расширение системы мультимедийных команд, которое, вероятно, получит название SSE4. Эти расширения достаточно узко специализированы, и, по-видимому, не очень существенно влияют на производительность; возможно, в будущих 45-нанометровых процессорах Penryn команды SSE4 будут еще усовершенствованы и окажутся эффективнее.
5. Intelligent Power Capacity. Последняя группа усовершенствований Core связана с интеллектуальными возможностями управления электропитанием [6]. Значение TDP (Thermal Design Power) для Woodcrest/3 ГГц составляет всего 80 Вт (этому, очевидно, способствует использование новой технологии 65 нм), в то время как двухъядерные Opteron имеют свыше 100 Вт. Ясно одно: по характеристикам тепловыделения Intel также сильно опережает AMD, пока не перешедшую на технологию 65 нм.
Отметим также отказ разработчиков Core от технологии HyperThreading, доступной в Xeon/Pentium 4. С одной стороны, выигрыш в производительности от HT во многих случаях невелик, хотя есть и приложения, выигрывающие от HT существенно. С другой стороны, известны важные приложения, от этого проигрывающие, например Microsoft SQL Server [12].
Наборы микросхем
Для Сore создано три набора микросхем — 5000X для рабочих станций, 5000V и 5000P для серверов (бывшие кодовые названия Greencreek и Blackford соответственно).
В их северном мосте MCH реализовано управление четырьмя каналами (в 5000P — двумя каналами) оперативной памяти нового типа — Fully Buffered DIMM (FB DIMM). Главное предназначение данного типа памяти — рост пропускной способности, что необходимо для увеличения пропускной способности памяти в расчете на одно ядро. В Сore разработчики не пошли на интеграцию контроллера оперативной памяти в процессорной микросхеме, как это сделано в Power5 и Opteron. Вместо этого они увеличили пропускную способность FSB до 10,6 Гбайт/с (этому отвечает частота FSB 1333 МГц) и синхронно — пиковую пропускную способность памяти. При этом каждый двухъядерный процессор имеет свой FSB-порт на северном мосте. Ранее в двухпроцессорных серверах все четыре ядра Xeon DP работали с одной шиной. Пропускная способность памяти в расчете на одно ядро и была слабым местом Dempsey/Paxville, предыдущего поколения двухъядерных серверных процессоров Intel [13].
Наборы микросхем серии 5000 очень близки друг к другу. Отличия состоят главным образом в поддержке PCI-Express в МСН (слоты x16 для 5000X, и x8 — для 5000V/P). MCH 5000X содержит буфер — фильтр наблюдения (snoop), позволяющий ускорить процедуру поддержания когерентности кэша.
Процессоры и производительность
В настоящий момент поставляются процессоры Woodcrest с частотами 2,33, 2,66 и 3,0 ГГц (последние официально называются Xeon 5160); будут поставляться также процессоры с более низкими частотами — до 1,6 ГГц.
Проведенный выше сравнительный анализ микроархитектуры Core свидетельствует, что процессоры Woodcrest опережают двухъядерные Opteron по производительности, имея при этом более низкое энергопотребление. Процессоры Woodcrest имеют наивысшую в мире целочисленную производительность, уступая на плавающей точкой лишь Power5+ (табл. 2). Эти результаты подтверждаются и рекордными показателями пропускной способности Woodcrest на целочисленных задачах (SPECint_rate2000), и данными конкретных приложений. Например, по данным пресс-релиза Intel, Woodcrest/3,0 ГГц опережает Opteron 275/2,2 ГГц на задачах гидродинамики (CFD, программа Fluent) и моделирования столкновений (LS-DYNA) [14]. Из других приложений упомянем на задачи вычислительной химии: для известных программ NAND, Amber и VASP на четырех ядрах Woodcrest/2,66 ГГц оказался на 10-20% быстрее, чем двухъядерный Opteron/2,4 ГГц.
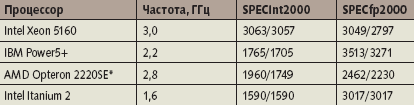 |
| Таблица 2. Оценка пиковой и базовой производительности серверных процессоров на тестах SPECcpu2000. * Одноядерный Opteron/3 ГГц имеет показатели 2119/2942 и 2365/2122 для SPECint2000 и SPECfp2000 соответственно. Источник: www.specbench.org. |
Остановимся на некоторых данных подробнее. В конференциях Usenet обсуждался вопрос, не уменьшается ли сильно производительность Woodcrest при использовании 64-разрядного, а не 32-разрядного режима. Такое уменьшение для целочисленной производительности естественно, поскольку в 64-разрядном режиме увеличивается нагрузка на кэш из-за увеличения длины указателей, и соответственно возрастает нагрузка на TLB (приложения с плавающей точкой обычно всегда «64-разрядны», они более предсказуемо — «последовательно» работают с оперативной памятью, к тому же они выигрывают от большего числа доступных регистров). Для оценки разницы можно посмотреть на SPECint2000. Рекордные показатели Woodcrest — 3063 — относятся к 32-разрядному режиму; в 64-разрядном режиме, согласно ION Computers, достигается 2888 единиц.
Неожиданные данные, обсуждавшиеся в августе на телеконференции по высокопроизводительным кластерам, были получены рядом независимых исследователей (M. Hahn, J. Landeman, J. Holmes). На стандартных тестах пропускной способности памяти (STREAM) для FSB с частотой 667 MГц и всех основных компиляторов (Intel, Portland, Pathscale) не удалось достигнуть ожидаемо высоких значений пропускной способности при параллельном выполнении нитей (детальнее о тестах STREAM и наших результатах для многоядерных Opteron см. [13]).
Например, на четырех нитях в четырехъядерных серверах пропускная способность составила около 4,8 Гбайт/с на циклах copy, scale и 5,2 Гбайт/с на add, triad. Для сравнения, в Opteron 275 (на сегодня они у AMD не самые быстрые) с оперативной памятью PC3200 (пиковая пропускная способность соответственно 12,8 Гбайт/с) при этом достигается 5,7-5,8 и 6,4 Гбайт/с соответственно. В других исследованиях (J. Landeman, Scalable Informatics) Opteron 275 дал 10,0-8,9 Гбайт/с и около 9,2 Гбайт/с соответственно, но Woodcrest — только 6,6-7,0 и 6,3-7,1 Гбайт/с. Последние результаты были получены с набором микросхем Blackford; более совершенная версия северного моста 5000X может дать существенное улучшение, но, по имеющимся данным, показатели Opteron все равно выше. Возможно, причина этих проблем лежит не в Woodcrest, а в контроллере оперативной памяти в MCH.
Однако важна не только пропускная способность, но и задержки оперативной памяти (особенно — для задач экономического характера, например, при работе с большими базами данных). Априори Opteron может иметь здесь преимущества — во-первых, из-за встроенного контроллера памяти, а во-вторых, из-за используемой Intel технологии FB DIMM, в которой буфер памяти Advanced Memory Buffer добавляет свою задержку.
В [15] приводятся результаты измерений задержек памяти Xeon 5160. Эти данные (табл. 3) подтверждают более высокие величины задержек в микроархитектуре Сore.
 |
| Таблица 3. Задержки по результатам тестов lmbench. * Использованные типы памяти: FB-DIMM Registered DDR2-533 СAS4 для Xeon; DDR-400 (3-3-3-6) для Opteron. Измерения проведены в среде Linux 2.6.15. |
В [15] приведены также результаты измерений производительности на ряде приложений. По большому счету, Opteron оказался быстрее, чем Woodcrest, только на тестах генерации RSA-ключей для OpenSSA: Xeon 5160 показал при этом производительность, близкую к Opteron/2,4 ГГц, и оба этих процессора сильно обошли по производительности (при равном числе ядер) Sun UltraSPARC T1 в серверах T2000. Впрочем, их микроархитектура NetBurst на этих тестах вела себя еще хуже.
На тестах Apache/PHP/MySQL процессор Xeon 5160 оказался на 75% быстрее, чем Opteron 275. На тестах Java/Webserving процессор T1/1,2 ГГц оказался на 20% быстрее, чем Xeon, а Opteron, даже с экстраполяцией до частоты 3 ГГц, уступает Xeon 5160. Отметим, что максимальная частота Opteron (2,8 ГГц для двухъядерных процессоров, 3 ГГц для одноядерных) практически достигла частоты Woodcrest, так что становится актуальной экстраполяция к 3 ГГц, которая показывает сравнительную эффективность микроархитектуры при одинаковой частоте. Что же касается самих рассматриваемых Java-тестов, то это как раз те приложения, на которые нацелен процессор T1 [3], имеющий чуть более низкое энергопотребление, чем Xeon 5160 (72 Вт против 80 у Intel), так что T1 здесь лучший и по производительности в расчете на 1 Вт.
При полной загрузке процессоров сходные конфигурации серверов с двумя процессорами (четырьмя ядрами) и оперативной памятью емкостью 4 Гбайт показали энергопотребление 245 Вт в сервере c Xeon 5160, 239 Вт — в сервере с Opteron 275 и 188 Вт — в cервере T2000 с восемью ядрами и 8 Гбайт памяти.
На тестах СУБД MySQL процессор Xeon 5160 превзошел Opteron/2,2 ГГц, который близок по производительности к T1/1 ГГц. На тестах MySQL и PostgreSQL Xeon 5160 опережает Opteron, даже если результаты последнего экстраполировать до частоты 3 ГГц. В целом Xeon 5160 обычно оказывается первым не только по производительности, но и по производительности на 1 Вт [15].
На тестах обработки транзакций TPC-C двухпроцессорный сервер с Xeon 5160 достиг производительности 169360 единиц. Для сравнения, на четырех ядрах сервер на базе Itanium 2/Montecito быстрее сервера на базе Woodcrest всего на 18%, хотя с Itanium 2 использовалась вдвое большая емкость памяти.
Учитывая приведенные данные по производительности, можно предположить, что серверы «стандартной» х86-архитектуры продолжат захватывать все большую долю рынка.
Выводы
Переход к многоядерным процессорам с ростом числа ядер в микросхеме является основным путем развития микропроцессоров, но при этом необходимо решать проблемы распараллеливания.
Процессоры, использующие микроархитектуру Core (в настоящее время — Xeon серии 5100), стали мировыми лидерами как по производительности (за исключением задач с плавающей точкой, где Power5+ может быть быстрее), так и по производительности в расчете на 1 Вт.
Относительно более слабым местом современных серверов на базе Xeon 5100 сегодня являются задержки и пропускная способность оперативной памяти, однако последний недостаток может быть исправлен в будущем.
Литература
- Михаил Кузьминский, Power4: надежда мира RISC. «Открытые системы», 2003, № 6.
- Михаил Кузьминский, 64-разрядные микропроцессоры AMD. «Открытые системы», 2002, № 4.
- Михаил Кузьминский, Асимметричный ответ «Ниагары». «Открытые системы», 2006, № 3.
- D. Kanter, Intel’s Next Generation Microarchitecture Unveiled. March 9, 2006, www.realworldtech.com/page.cfm?ArticleID=KWT0602006035626.
- Ofri Wechsler, Inside Intel Core Microarchitecture: Setting New Standards for Energy-Efficient Performance. Technology@Intel, March 2006.
- B. Valentine, Inside the Intel Core Microarchitecture. IDF, March 2006.
- J.H. Stokes, Into the Core: Intel’s next-generation microarchitecture. April 5th, 2006, arstechnica.com/articles/paedia/cpu/core.ars/1.
- S.L. Smith, B. Valentine, Intel Core Microarchitecture. IDF, March 2006.
- Михаил Кузьминский, Дорога к высоким частотам. «Открытые системы», 2001, № 2.
- M. Milenkovich, A. Milenkovich, J. Kulick, Demystifying Intel Branch Prediction. Proc. of the Workshop on Duplicating, Deconstructing, and Debunking, Anchorage, Alaska, May 2002.
- B. Inkley, S. Tetrick, Intel Multi-Core Architecture and Implementation. IDF, March 2006.
- R. Goodwins, ZDNet UK, Nov. 18, 2005.
- Михаил Кузьминский, Многоядерные процессоры AMD. «Открытые системы», 2005, № 10.
- Competitive comparison. Dual-core Intel Xeon processor-based platforms vs. AMD Opteron. Intel Corp., 2006.
- J. De Gelas, www.anandtech.com/IT/showdoc.aspx?i=2772&p=4.
Михаил Кузьминский — сотрудник Центра компьютерного обеспечения ИОХ РАН (Москва).
Работа поддержана РФФИ, проект 04-07-90220.
* Если число итераций в цикле не меняется, все прекрасно, но если оно изменяется, что бывает довольно часто ситуацией, то примерно в половине случаев предсказание будет неверным. В то же время обычное предсказание, что выполнение цикла продолжится, имеет большую вероятность. Поэтому возможно, реальный механизм предсказания перехода в циклах более сложен.
* Это гораздо больше, чем в любом современном процессоре. В Power4 их может быть до 200; в Core одновременно может выполняться 96 микроопераций.
Таблица 1.
