
Поисковые системы — стражи порядка в Internet. Они позволяют ориентироваться в Сети, которая изначально не структурирована. «В Internet невозможно ничего найти», — возмущаются новички, и это действительно так. Порядок в Сеть призваны внести три технологии навигации: поисковые системы, каталоги и рейтинги. Возможно, в скором времени все они объединятся в единую службу навигации в Internet. Этот обзор посвящен развитию российских поисковых систем и возможному их использованию корпоративными пользователями. Мы затронем две области применения поисковых систем — поиск в Internet и организацию поиска по корпоративному Web-узлу.
Поиск в Internet
Существующие службы поиска можно использовать как для поиска нужной информации, так и для привлечения внимания посетителей Internet к своим ресурсам. Оба этих аспекта поисковой технологии мы обсудим чуть позже, а пока рассмотрим, как работают поисковые системы сейчас и в каком направлении они развиваются.
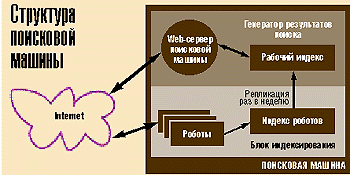
Как ищут?Обычно поисковая система представляет собой комплекс из нескольких компьютеров, каждый из которых выполняет свою часть работы. Например, «Апорт-2000» работает на 12 компьютерах под управлением Windows NT, Яndex — на шести, а Rambler — на трех Unix-серверах.
В поисковой системе должны быть роботы, которые получают страницы из Internet, анализируют их и подготавливают своеобразную выжимку информации, которая называется индексом поисковой системы. В индексе хранится информация, на основе которой поисковая система выдает ответы на запросы пользователей. Роботы, как правило, работают постоянно, накапливая информацию о расположении файлов в Internet, однако для пользователей она становиться доступной только через некоторое время. Полная и единовременная смена индекса необходима для корректной работы механизмов поиска и ранжирования документов. Анализ содержания Internet — процесс непростой, и обеспечить непрерывную обработку его результатов бывает сложно. Обычно используется следующая схема: робот работает непрерывно, а потом в определенный момент полученные результаты становятся доступны пользователю.
Информация в поисковой системе сначала накапливается и индексируется, а затем загружается на машины, которые выдают результаты пользователям. Накопленная роботом информация перегружается в генератор выдачи в определенные моменты времени. Период обновления индекса генератора у трех основных русскоязычных поисковых машин — Яndex, Rambler и «Апорт» — неделя. При этом Яndex и Rambler обновляют общедоступный индекс в выходные, а «Апорт» — в рабочие дни. Поэтому, зарегистрировав свой ресурс в поисковой машине, не следует сразу же искать ссылку на него в результатах поиска — он станет доступным только тогда, когда будет сменен индекс генератора.
В идеале за время, которое проходит от одной смены индекса до другой, поисковая система должна заново просмотреть и проанализировать все накопленные в ней локаторы ресурсов (URL). Но так бывает не всегда, и тогда в результатах выдачи поисковой машины появляются устаревшие или неправильные ссылки. Например, генеральный директор компании «Агама» Евгений Киреев признается, что в прошлом их поисковая машина «индексировала 1% российского Internet в день». Причем в ее базе содержались ссылки примерно на «половину ресурсов русскоязычной части Internet». Получается, что старый «Апорт» анализировал все свои URL примерно за 50 дней, то есть за шесть жизненных циклов поисковой системы. Киреев надеется, что «Апорт-2000» будет работать на порядок быстрее, что позволит обрабатывать всю базу URL за неделю.
Создатели Яndex уверяют, что их поисковая машина справляется с анализом накопленных URL за одну-две недели. Для этого используется механизм динамического изменения периодичности пересмотра URL. То есть если документ не менялся достаточно давно, то и его содержание можно проверять реже. Но как только машина заметила, что документ изменен, она будет анализировать его чаще, чем раньше. Таким образом, Яndex экономит время на анализе мало меняющихся документов.
Есть, конечно, ресурсы, которые обновляются каждый день, например Internet-газеты или ленты новостей информационных агентств. Использовать для поиска по ним существующие поисковые машины нельзя — информация в принципе обновляется быстрее, чем индексируется. Вероятно, поиск по новостным серверам должен выполняться отдельно, поскольку работа с ними сильно отличается от поиска в Internet вообще, и, вероятно, должна быть согласована с авторами ресурсов. Сейчас таких служб нет, но, возможно, они появятся.
В настоящее время все поисковые машины предоставляют и различные дополнительные услуги. Например, все поисковые системы позволяют выполнять так называемый нечеткий поиск, при котором сама машина определяет характерные для документа слова, генерирует запрос, а затем ищет по нему документы с аналогичными характерными словами.
Где деньги?Чтобы соответствовать требованиям быстро меняющейся Сети, поисковые машины должны постоянно развиваться. Однако сейчас услуги по поиску информации в Internet являются бесплатными, хотя на поддержку работы поисковика тратятся определенные средства. Некоторый опыт коммерциализации системы поиска есть у ведущих зарубежных поисковых систем. Например, Yahoo пыталась брать деньги за регистрацию ресурсов в своей базе данных, AltaVista — за размещение пунктов выдачи результатов. Однако успехом эти шаги не увенчались. Вот что говорит о финансировании своего проекта Киреев: «Поддержка поисковой системы — проект инвестиционный, основная цель которого — сделать хорошую технологию, создать популярный ресурс и собрать вокруг него постоянных посетителей. Если выполнится хотя бы одно условие, так или иначе проект окупится».
Сейчас компания «Агама» получила серьезную финансовую поддержку, что позволило выпустить новую версию систем. Есть и другие схемы окупаемости поисковых систем, построенные в основном на рекламе. Например, Яndex является рекламой продуктов компании CompTek — YandexSite, YandexCD и YandexLib.
Кого ищут?В современных условиях уже недостаточно просто опубликовать информацию в Сети, важно сделать так, чтобы ее находили. Поэтому владельцы ресурсов используют поисковые системы для «целенаправленной» выдачи информации именно тем, кто ее ищет. По сравнению с другими способами привлечения пользователей — рейтингами, баннерной рекламой и другими — поисковые системы показывают ссылку на ресурс именно тогда, когда она необходима пользователю. Однако не следует делать из поисковой системы рекламную службу и пытаться попасть на первые страницы выдачи результатов в наиболее популярных запросах. Если запрос, по которому ресурс найден, не соответствует содержанию Web-узла, пользователь быстро это поймет и уйдет навсегда. Поэтому основная задача регистрации какого-либо ресурса в поисковых системах — сделать так, чтобы его находили только те пользователи, которые в нем нуждаются.
 |
Есть одно важное правило работы с поисковыми машинами — использование файла robots.txt, который располагается в корневом каталоге сервера. Этот файл описывает для поискового робота структуру сервера и указывает ему разрешенные и запрещенные для индексирования HTML-документы. Если в тексте встречаются элементы, которые не нужно индексировать, можно использовать теги и . Все российские поисковые системы используют файл robots.txt и указанные выше теги при анализе содержания сервера. Причем если известно имя робота конкретной поисковой системы, то можно установить доступ к документам сервера только для него. Это полезно, если на сервере есть закрытая информация, которая не предназначается для широкой публики.
Следует отметить, что для любой уникальной страницы найдется такой запрос, при котором она будет первой в результатах выдачи поисковой машины. Таким образом, для привлечения внимания к ресурсу достаточно сделать его уникальным. Впрочем, это утверждение справедливо только для классических поисковых систем, которые генерируют результаты выдачи, основываясь лишь на анализе гипертекста. Некоторые же машины при сортировке результатов используют дополнительную информацию о странице, получаемую из других источников. Для них приведенное выше утверждение может оказаться несправедливым.
Как только Web-узел занесен в систему, у его владельцев возникает вопрос — как оказаться на первых двух страницах выдачи результатов? Для этого важно знать, как система вычисляет релевантность документа, то есть ранжирует его при выдаче результатов. У большинства западных поисковых систем и у некоторых российских нет явного описания алгоритма ранжирования. Чаще всего основным параметром является процент слов из запроса, которые присутствуют в документе. Однако ранжирования по количеству слов обычно недостаточно, и поисковые системы часто используют также элементы разметки. Например, «Апорт» с более высоким приоритетом учитывает слова в заголовках. Если слово запроса есть в заголовке документа, то оно засчитывается за десять обычных слов. Аналогичным образом в новом «Апорт-2000» будут учитываться тексты внутри ссылок, выделения более крупным шрифтом или другим цветом. Rambler при ранжировании документов использует восемь уровней важности содержащейся в них информации.
Нужно отметить, что классические поисковые машины работают в основном с HTML-страницами. Но редко кто из владельцев серверов хранит большие объемы информации в HTML, — скорее всего, вся информация содержится в какой-либо базе данных. Базы данных, размещенные в Web, не всегда доступны путем последовательного просмотра, ведь они очень часто используют параметры, которые поисковая система не может самостоятельно генерировать. Поэтому ни одна поисковая система не анализирует странички с параметрами (те, в которых есть знак вопроса). Другой проблемой, по словам Аркадия Воложа, генерального директора компании CompTek, которой принадлежит Яndex, являются серверы, для каждого HTML-документа генерирующие свой уникальный URL. Примером такого Web-сервера является Lotus Domino, при индексировании которого поисковая машина может попросту зациклиться.
При использовании в своем Web-сервере базы данных необходимо учитывать его возможное индексирование какой-либо поисковой машиной. Например, где-нибудь на сервере публиковать его полную структуру, со ссылками на все хранящиеся в базе записи. Вообще же, можно предусмотреть в структуре Web-сервера специальные страницы для поисковых систем, через которые робот быстро и эффективно доберется до всех документов узла.
Владельцы поисковых систем также спорят о том, использовать ли ключевые слова при вычислении релевантности. Тег
был задуман именно для того, чтобы роботы могли получать дополнительную информацию о документе, написанную человеком специально для них. Однако некоторые нечистоплотные владельцы ресурсов стали злоупотреблять этой возможностью для привлечения внимания к своим серверам и помещали в теге наиболее популярные слова, взятые из статистики поисковой системы. В результате многие поисковые системы игнорируют этот тег. На Rambler об этом сказано явно, там имеются пояснения, что поисковая система будет анализировать документ так, как его видит пользователь, а не так, как его хотят показать владельцы ресурса. «Апорт» и Яndex не игнорируют ключевые слова.Не нужно делать сервер, оптимизированный под какую-либо конкретную поисковую систему. Каждая из них анализирует параметры HTML-страниц по своему алгоритму и в результате по-разному оценивает релевантность документа. Есть приемы, которые позволяют сделать сервер более доступным через поисковую систему, но эти методы могут входить в противоречие при использовании для разных поисковых систем. У двух российских поисковых систем — Яndex и Rambler на сервере есть раздел, в котором их авторы приводят рекомендации по правильному составлению документов. Наиболее общие советы можно найти в приведенных врезках.
Киреев рассказал о своем опыте работы с иностранными поисковыми системами: «Мы зарегистрировали свою поисковую систему в AltaVista, меняли страницу и смотрели, как повлияет это на результаты выдачи AltaVista. Результаты были очень загадочными, мы так и не смогли ничего понять, а потом вдруг наш сервер оказался чуть ли не первым по тем запросам, которые нас интересовали. Правда, по времени это совпало с регистрацией нашего сервера в службе RealNames, в которой можно зарегистрировать за деньги свой Web-узел по определенным ключевым словам. Оказалось, многие поисковые системы обмениваются информацией с этой службой и используют полученные данные для сортировки и поиска».
Одно время AltaVista даже явно отличала ресурсы, найденные в свободном поиске, от документов, зарегистрированных в RealNames. Логика у такой работы есть, хотя она и не согласуется с «теоремой поиска», приведенной выше. Если владелец ресурса заплатил определенные деньги за регистрацию своего ресурса, то это серьезный проект, а не персональная страничка. Следовательно, она более качественна и представляет больший интерес для посетителя. В России есть аналогичная служба, но она не стала стандартом и не учитывается в поисковых системах. Впрочем, российские поисковые системы развиваются по другому пути — интегрируются с каталогами ресурсов. Так, «Апорт-2000» будет выдавать результаты, учитывая информацию, найденную в каталоге @Rus-Ау!. Яndex ведет работы по интеграции с каталогом List.ru, правда, они еще далеки от завершения.
Локальный поиск
Важная сфера применения поисковых технологий — локальный поиск по отдельному Web-серверу. Его можно организовать несколькими способами. Например, можно настроить поисковую систему так, чтобы данные о Web-узле хранились в общем индексе поисковика, а машина выдавала ссылки только на этот узел. Так работают, например, Rambler и «Апорт». Это решение достаточно простое и бесплатное, но имеет свои ограничения. Поскольку поиск выполняется на основе индекса поисковой машины, меняющегося раз в неделю, то при такой организации и изменения сервера не сразу будут заметны.
Если сервер меняется достаточно часто, то лучше использовать локальный поиск с помощью специализированной поисковой машины, которая устанавливается на Web-сервер и индексирует только его. Сейчас таких продуктов два: YandexSite компании CompTek и «Следопыт» компании MediaLingua. Все другие разработчики поисковых систем считают невыгодным создание отчуждаемого продукта для локального поиска, поскольку требуются слишком значительные вложения для поддержки и продаж. Например, Евгений Киреев полагает, что рынок для таких продуктов в России недостаточно развит, поскольку крупных русскоязычных Web-серверов мало.
Правда, для организации локального поиска можно купить не законченный продукт, а технологию — только поисковое ядро. Примером такого ведения бизнеса является поисковая служба Inktomi, которая задействуется многими западными серверами. При этом технология продается не любому покупателю, а тому, кто умеет с ней работать. Например, если владелец портала хочет использовать поисковую систему, ему не обязательно разрабатывать ее с нуля. Можно лицензировать какую-либо поисковую технологию и настроить ее под свои нужды. Кроме того, технология — это основа для различных платных служб.
Еще одним способом организации локального поиска являются поисковые агенты. Это программы, устанавливаемые на клиентскую машину и анализирующие информацию с Web-серверов. Они работают медленно, но позволяют более точно настроить механизм поиска и искать даже в тех местах, где поисковая машина не действует, например, в корпоративной сети без выхода в Internet. К сожалению, сейчас технология поисковых агентов еще развивается и может решать только очень узкий круг задач. Например, в Институте программных систем РАН ведется работа по созданию агента на Java для поиска книг в российских электронных магазинах.
Для полнотекстового поиска в базе данных можно использовать комбинированный механизм поиска. Работает он так: поисковая система строит индекс, в котором единицей является не документ, а запись в базе. При получении запроса от пользователя поисковик выдает информацию о том, в какой записи есть соответствующие слова, и дальше передает эту информацию в базу данных. Причем можно использовать как операторы SQL, так и логические операторы полнотекстового поиска. Например, такой механизм применен в @Rus, где реплика «Апорт» ищет информацию по 30 тыс. записей. Впрочем, сейчас большинство баз данных уже включают возможность полнотекстового поиска, к которой остается просто добавить русскую морфологию.
Кто ищет, тот далеко пойдет
Сейчас в мире быстро развивается электронная коммерция, которая также не обойдется без поисковых систем. В частности, поиск необходим для полноценного выбора в Internet-магазинах. Хотя поиск по одному магазину организовать достаточно просто, наиболее интересным представляется поиск товаров в нескольких магазинах для сравнения предлагаемых вариантов. Весьма привлекательной была бы единая система поиска товаров в Internet-магазинах. Подобные системы уже появились на Западе. В качестве примера назовем www. jango.com. Такого рода службы можно разделить на две группы. Те, что относятся к первой, имеют прямой доступ к базам данных магазинов, часто магазины являются даже их партнерами. Во вторую группу входят системы, которые постоянно сканируют страницы Internet-магазинов и создают свою базу данных товаров и цен по ним. Возможно, аналогичные службы скоро начнут создаваться и в России.
Еще одна служба, которая может появиться в скором времени, — система поиска новостей по быстро изменяющимся Web-серверам. Она основывается на несколько иных принципах поиска и, возможно, требует отдельного договора с создателями серверов.
Говоря в целом, разделение поисковых систем на локальные и глобальные становится все более условным. Так, локальные установки новой версии YandexSite, возможно, смогут обмениваться информацией с центральной системой Яndex. А глобальные системы можно будет использовать для локального поиска, например, с помощью технологии поисковых агентов. Internet интегрируется во все более сложную гипертекстовую структуру, где не всегда можно отделить данные, расположенные на одном сервере, от информации на другом. Возможно, Internet уже следует рассматривать как единое информационное гипертекстовое хранилище данных, для которого необходимо разрабатывать общие и универсальные средства доступа и навигации. Одно очевидно: поисковые технологии станут частью этого универсального средства доступа к информации Internet.
| Побочные результаты |
Поисковые системы можно использовать также для оценки размеров русскоязычной части Internet. Зачастую эти данные существенно отличаются от тех, которые можно получить на основе анализа DNS доменов .su и .ru. Например, по оценкам Яndex, их поисковая система нашла около 46 тыс. уникальных серверов, которых примерно в три раза больше, чем адресов в DNS. На этих серверах располагается 10 млн. документов с суммарным объемом текстов свыше 100 Гбайт. Таким образом, получается, что на среднем сервере хранится около 2,2 Мбайт информации, что соответствует одной тысячестраничной книге и чуть больше стандартного объема бесплатного хостинга. Интересно также проследить увеличение среднего размера документов. Так, при анализе базы данных «Апорт» оказалось, что за два года существования поисковой системы средний объем документов расширился. Раньше он был 6 Кбайт, а сейчас уже — 8. Впрочем, из приведенных выше данных следует, что у Яndex средний размер документа еще выше — порядка 10 Кбайт. Возможно, это связано с тем, что среди создателей Web-ресурсов становятся популярными средства быстрой разработки документов, которые, как правило, генерируют более длинные документы, чем можно сделать вручную. Дмитрий Крюков, разработчик Rambler, оценивает средний размер текстов в HTML-документах примерно в 2,5 Кбайт. Возможно, сравниваются разные величины. Так, в первом случае имеется в виду размер файла HTML, который получает поисковая машина, а во втором оценивается именно текст без тегов, лишних пробелов и другой несущественной информации. |
| Как работать с системой Яndex? |
Задавайте уникальные заголовки документов, вкратце описывающие сайт и текущий документ (но не более 20-25 слов). Слова в заголовках имеют большее значение, чем остальные. Давайте каждому документу описание в теге description Не забывайте о ключевых словах, по возможности уникальных для каждой страницы, например, |
Делайте подписи к картинкам в теге alt ![]()
Чем длиннее документ, тем менее заметны в нем слова, заданные в запросе, и, следовательно, ваша страница будет ниже в результатах поиска при прочих равных. Старайтесь разбивать длинные документы на более короткие
Полный текст документа можно
найти на сервере Яndex
| Как сделать, чтобы Rambler находил ваши документы? |
Базовые понятия и ключевые слова для данного сайта следует включать в HTML-теги (в порядке значимости): |