Пару лет назад наш журнал уже писал о противостоянии Pentium III и Athlon на процессорном фронте [1]. Тогда статья вышла примерно через год после появления нового кристалла фирмы AMD, коренным образом изменившего расстановку сил на рынке ЦП. Потребовалось время, чтобы не торопясь осознать произошедшие изменения и провести всестороннее тестирование конкурирующих технологий. Сейчас мы рассмотрим новых противников, Pentium 4 и Athlon XP, однако сразу оговоримся, что данная статья ориентирована прежде всего на узких специалистов.
Разумеется, каждого человека в первую очередь интересует, какой процессор будет оптимальным именно для его ПК. Естественно, ответ на этот вопрос зависит от того, какие задачи решает данный пользователь и какие приложения он при этом использует. Беда лишь в том, что количество разработанных приложений уже превышает количество программистов на планете и, вероятно, приближается к численности населения всего земного шара. Понятно, что охватить в обзоре сколько-нибудь весомую часть всего ПО невозможно, а тестирование на примере нескольких наиболее распространенных приложений весьма однобоко. Более того, оказывается, что в традиционных сферах использования компьютера (офис и игры) мощность процессора не является определяющей: для офисных приложений это попросту не нужно, а для игр гораздо важнее характеристики графического ускорителя. Но зачастую процессор наивысшей производительности бывает востребован профессионалами, работающими с достаточно специфическими приложениями, не попадающими, как правило, в список тестовых программ для обзоров, и, значит, метод аналогии здесь оказывается неприменимым. Поэтому было бы гораздо целесообразнее дать перечень характеристик, помогающих осмысленно выбрать процессор для работы с оригинальным приложением. При этом, конечно, подразумевается, что пользователь представляет себе характер действий, выполняемых процессором в его приложении.
В данной статье мы исследуем системы, претендующие на наивысшую производительность. Как уже было сказано, центральный процессор не полностью и не всегда определяет мощность вычислительной системы в целом. Кроме него немалый, а иногда и решающий вклад вносят ОЗУ, видеосистема и жесткий диск, однако в большинстве случаев взаимодействуют ЦП и ОЗУ — именно эта комбинация представляет собой основу работы любого компьютера.
По сути дела единственное, для чего предназначен и что умеет делать процессор, — это изменение содержимого ячеек памяти. Но скорость работы ОЗУ сегодня такова, что современный процессор на чтение одного байта из него тратит 200—500 тактов, тогда как сам способен выполнить до 2—3 команд за такт. Естественно, мириться с таким положением дел нельзя, поэтому был найден выход: использование кэша — небольшого буфера высокоскоростной памяти между процессором и основным ОЗУ1. Впервые кэш-память была применена совместно с процессором 80386, сейчас она, как правило, насчитывает два уровня, а в ближайшем будущем ожидается переход на трехуровневую организацию. Таким образом, с одной стороны, среди всего многообразия приложений можно выделить те, чья скорость работы определяется исключительно (или в основном) производительностью подсистемы процессор—память. При этом большинство нестандартных приложений, аналоги которых трудно найти в обзорах, относятся именно к такому классу. С другой стороны, с точки зрения взаимодействия с памятью все приложения можно условно разделить на три группы:
- Имеющие взаимодействие с памятью, сведенное к минимуму, и производительность, в основном определяемую скоростью ядра. Применяются для расчета сложных математических выражений, итерационных вычислений и т. д.
- Требующие для работы достаточно небольшого объема памяти, не превосходящего размера кэш-памяти. Таких задач не так уж мало: это работа с текстом в сотни страниц, работа с 3D-миром, насчитывающим десятки тысяч полигонов (если с текстурами работает ускоритель), обработка полноцветного видео с разрешением до 400x300 точек, моделирование нейронных сетей, содержащих до сотни тысяч связей, расчет потоков жидкости и газа с десятками тысяч узлов, прогнозирование поведения сложных систем, состоящих из сотен объектов, и т. п.
- Предназначенные для несложной обработки больших объемов данных. Это рендеринг фотоизображений, обработка крупной растровой графики, различные научные и экономические расчеты.
Опираясь на такую классификацию, мы и проведем наше исследование.
Были протестированы три системы: одна — на процессоре AMD Athlon XP с памятью DDR2, а две другие — на процессорах Intel Pentium 4 с ОЗУ типа DDR и RDR (Rambus). Все три системы имели по 512 Мбайт памяти и были укомплектованы видеоадаптерами на кристалле nVidia GeForce4 Ti 4600, а также звуковыми платами Creative SB Audigy. Кроме того, часть тестов «вне конкурса» проходила машина с морально устаревшим (по мнению Intel) процессором Pentium III, который тем не менее, еще способен оказывать лидерам достойное сопротивление. Его скорое списание фирмой Intel связано в основном с маркетинговой политикой — Pentium III, сохраняя паритет производительности с Athlon, несколько уступает Athlon XP и не обладает чертами, пригодными для успешного проведения рекламных акций, тогда как у Pentium 4 они есть: высокая тактовая частота (при низкой производительности, как вы увидите ниже) и набор дополнительных инструкций (SSE2).
В таблице приведена конфигурация испытанных машин. Каждой из них присвоен короткий идентификатор для обозначения ее на графиках и диаграммах.
Чтобы избавиться от неопределенности, обусловленной различием характеристик жестких дисков, мы ограничились анализом лишь тех тестов, где жесткий диск не используется. Иными словами, проигнорировали процесс загрузки, предполагая, что объема ОЗУ достаточно для размещения всех необходимых данных. Перед проведением тестов была измерена реальная частота процессоров. Как и ожидалось, у всех образцов она оказалась слегка выше паспортной: у системы P4-DDR — на 1%, у остальных — на 0,2%.
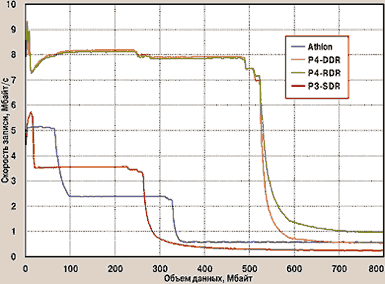
|
| Рис. 1. Зависимость скорости обмена от объема данных (запись) |
При последовательном доступе к памяти (рис. 1) скорость обмена существенно зависит от объема данных. На графике проиллюстрирована эта зависимость для рассматриваемых процессоров на примере операции записи (rep stosd). Вне конкуренции здесь, конечно, Pentium 4. Он продемонстрировал не только максимальную скорость, но и сохранял ее для всего объема кэш-памяти второго уровня. Браво! Именно эта способность и позволяет процессору неплохо справляться с большинством приложений, несмотря на очень медленное (как покажет дальнейший анализ) ядро. На втором месте — Pentium III. Этот процессор обогнал Athlon при работе с кэш-памятью обоих уровней, невзирая на в полтора раза более низкую тактовую частоту. Правда, и у Athlon есть свой конек: во-первых, наличие огромного объема кэш-памяти первого уровня, а во-вторых, такая организация двухуровневого кэша, при которой объем кэш-памяти первого уровня добавляется к объему кэш-памяти второго, а не поглощается им (хотя, конечно, если расплачиваться за такое «добавление» приходится низкой скоростью доступа, то в данном случае конструкторы AMD явно просчитались).
Что касается больших объемов записываемых данных, то здесь зависимости от типа процессора не наблюдается: все определяется типом памяти. На первое место вышла система с Rambus RAM (RDR), на второе — с DDR (независимо от типа процессора) и на третье — с обычной SDRAM, которую в последнее время стало принято именовать SDR RAM.
Инструкции SIMD3 появились задолго до реализации набора ММХ. Еще в кристаллах 8086/88 присутствовали команды обработки строк: чтения, записи и пересылки. Одной из них, а именно записью строки, мы и воспользовались для построения графиков на рис. 1. Запись обычно требуется при инициализации или уничтожении данных. Например, всякий раз, когда мы в графическом редакторе вызываем команду «Файл?Создать», происходит очистка буфера рисунка. Кроме того, в ООП она обычно используется при создании объектов и т. п. Самая распространенная из инструкций обработки строк, естественно, пересылка. Она применяется при любом перемещении данных: от копирования их из буфера в видеопамять и до вызова процедуры с передачей ему массива или строки в качестве параметра. Наиболее редкая инструкция — чтение строки. Действительно, при этом сохранить данные просто негде — не позволяет размер регистра. Зачем, спросите вы, читать, если из этого нельзя извлечь какой-либо пользы? Но для нас эта инструкция также интересна. Во-первых, интерес чисто академический, а во-вторых, полученные данные имеют и вполне практическое значение. Дело в том, что современные процессоры общаются с ОЗУ по одной шине (FSB), а с видеопамятью — по другой (AGP), поэтому при переносе изображения в видеопамять (или загрузке текстур) шина процессор/память ведет себя точно так же, как и при чтении.
С момента проявления 386-х кристаллов и по сей день процессоры архитектуры x86 остаются 32-разрядными, а внешняя шина у них, начиная с Pentium, уже 64-разрядная. Если вместо РОН4 использовать регистры ММХ [3], то разрядности регистров и внешней шины совпадут, и можно ожидать некоторого прироста производительности. Кроме того, если данные не будут выровнены на границу, кратную размеру элемента данных, появятся дополнительные задержки. С учетом этого и получены скоростные характеристики доступа к памяти для всех возможных режимов (диаграмма 1). При измерениях объем данных составлял 4 Мбайт, что существенно превосходит размер кэш-памяти.
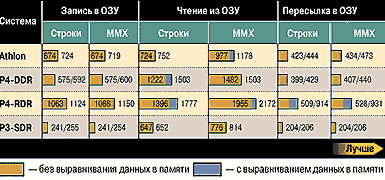
|
| Диаграмма 1 |
Правда, говоря обо «всех возможных режимах», я немного слукавил. В Pentium III появился дополнительный набор инструкций, названный SSE (Streaming SIMD Extension), с помощью которого можно как работать с 128-разрядными данными, так и управлять функционированием кэш-памяти [4]. Набор SSE поддерживается и процессором Athlon XP, так что сравнение будет корректным. Используя инструкции SSE, можно существенно повысить скорость перемещения данных [5], что подтверждают результаты, полученные при копировании 16-Мбайт массива (диаграмма 2).
|
| Диаграмма 2 |
У современной динамической памяти очень много времени занимает установка стартового адреса (до пяти тактов), а дальнейший обмен выполняется сравнительно быстро: по 8 байт за такт — для SDRAM и по 16 байт — для DDR. Значит, когда мы увеличиваем длину читаемого/перемещаемого фрагмента, то повышаем производительность. При копировании достаточно часто происходит переключение из режима чтения в режим записи и обратно, а при каждом перемещении — инициализация нового адреса. Командами управления кэш-памятью мы увеличиваем длину фрагментов, что и приводит к росту производительности.
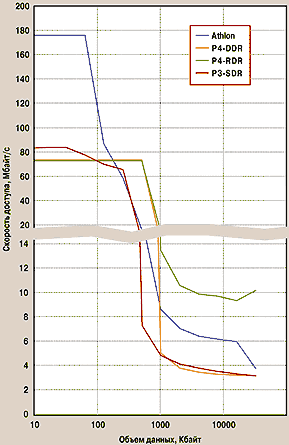
|
| Рис. 2. Скорость произвольного доступа (запись) |
Естественно, мы далеки от мысли, что каждому из наших читателей нужны разъяснения по программированию на ассемблере, но без них результаты следующего теста могут просто шокировать. Итак, на рис. 2 и 3 показана скорость обмена при произвольном доступе к памяти. Обратите внимание, скорость доступа дана не в Мбайт/с, а в Кбайт/с. Чрезвычайно низкая скорость доступа связана, во-первых, с уже упоминавшимся большим временем на установку адреса, а во-вторых, со стремлением разработчиков ЦП повысить скорость последовательного обмена за счет увеличения длины пакета, из-за чего при запросе одного байта реально в кэш-память переносится несколько десятков (не менее 32) байт. В этом тесте очень достойно выглядит Pentium III, что, скорее всего, связано с меньшей длиной пакета.
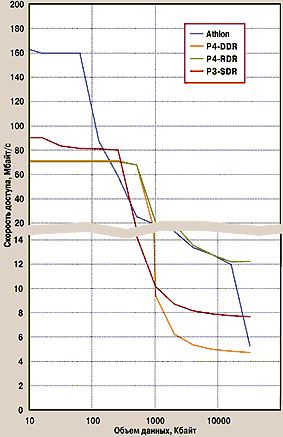
|
| Рис. 3. Скорость произвольного доступа (чтение) |
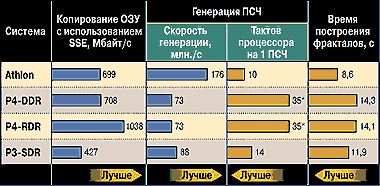
Программная реализация доступа к памяти по произвольным адресам требует применения датчика псевдослучайных чисел (ДПСЧ). Генерация очередного ПСЧ вызывает определенные затраты ресурсов ЦП (при данном измерении хранить заранее подготовленный набор ПСЧ в памяти нельзя), так что часть графика, попадающая в область кэш-памяти, характеризует скоростные свойства именно ЦП, в частности, насколько быстро тот способен сгенерировать очередное ПСЧ (диаграмма 2). На примере этого измерения отчетливо видно то, что выше было названо «слабым ядром» Pentium 4. Процессор Athlon, работающий на частоте 1,8 ГГц, опередил Pentium 4 почти в 2,5 раза. «Четверку» обошел даже «устаревший» Pentium III, имеющий в два с лишним раза более низкую частоту.
Измерив скорость произвольного и последовательного доступа к ОЗУ (и кэш-памяти), мы перешли к тестам процессорного ядра, и здесь Pentium 4 ждала очередная крупная неудача. Давайте рассмотрим еще несколько задач, в которых влияние памяти сведено к минимуму. Как уже отмечалось, к ним относятся сложные математические и итерационные вычисления. Последние хорошо иллюстрировать построением фракталов. В диаграмме 2 приведено суммарное время построения восьми различных фракталов (за вычетом времени, необходимого для вывода их на экран), в том числе Жюлиа и Мандельбротта. Как видим, результат схож с предыдущим: первое место — у Athlon, второе — у Pentium III, а на почетном третьем — Pentium 4.

|
| Диаграмма 3 |
Перейдем к вычислениям с плавающей точкой. Классической контрольной задачей здесь является тест Ветстоуна. В диаграмме 3 приведены результаты, отражающие производительность, показанную в этом тесте 16- и 32-разрядными компиляторами Фортрана (в классической постановке), а также 16- и 32-разрядными компиляторами Паскаля (в переписанном на Паскаль виде). Последнее представляет интерес, поскольку степень оптимизации компиляторов Паскаля, как правило, ниже, чем Фортрана, так как традиционно не привязана к конкретному типу процессора. И тут во всех тестах лидер прежний — Athlon. В 16-разрядных приложениях второе место безоговорочно занимает Pentium III, а в 32-разрядных от него все же немного оторвался Pentium 4. При расчете оптических коэффициентов, где используются интенсивные тригонометрические вычисления (в этом отношении тест походит на современные 3D-игры), Pentium 4 снова оказался в аутсайдерах (справедливости ради заметим, что в данной программе не используется его уникальное расширение SSE2, но явно низкая производительность основного процессорного ядра не вызывает сомнений).
Теперь от программ, измеряющих отдельно производительность памяти и отдельно — процессора, перейдем к тестам, где так или иначе проявляется взаимодействие процессор — память. Как мы уже успели установить, наиболее ярко проявляет себя оперативная память при произвольном доступе5. Зачастую его хорошо имитирует реальная работа с таблицами или базами данных, но в нашем тестировании мы выбрали программу для нахождения простых чисел методом «Решето Эратосфена». Зависимость времени работы алгоритма от диапазона, в котором происходит поиск простых чисел, приведена на рис. 4. В отличие от остальных графиков, здесь более высокой производительности соответствует более низкая кривая. Ничего удивительного этот тест не принес: пока действие разворачивается в процессорном кэше, вне конкуренции остается Pentium 4. Если система к тому же оснащена быстрой памятью RDR, он сохраняет лидерство и даже увеличивает отрыв. При использовании памяти DDR процессор AMD довольно быстро обгоняет своего конкурента. А Pentium III, хотя и оказался в аутсайдерах (с тактовой частотой не поспоришь), однако с ростом объема данных его отставание уменьшается.
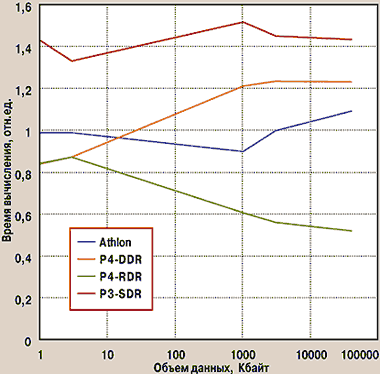
|
| Рис. 4. Время нахождения простых чисел методом «Решето Эратосфена» |
Приведем еще два теста с программами для научных расчетов: решение систем линейных и дифференциальных уравнений. В обоих случаях обрабатываются большие массивы чисел с плавающей точкой, но поскольку зависимость одних чисел от других различна, не совпадают и показанные процессорами результаты. Решение системы линейных уравнений — классическая контрольная задача (Dongarra benchmark), пожалуй, не менее известная, чем тест Ветстоуна. Производительность суперкомпьютеров по сей день измеряется в FLOP?ах, правда, сейчас уже с приставкой «тера». Так что читатель без труда может сравнить приведенные в статье данные с характеристиками машин, которые ему вряд ли когда-нибудь удастся увидеть воочию6. Заметим, что в классической постановке этот тест решал 100 уравнений со 100 неизвестными, что составляет 80 Кбайт данных. Сегодня как объем данных, так и время выполнения программы не могут не вызвать улыбки, поэтому был реализован вариант теста с набором массивов различных размеров — от 3 Кбайт до 50 Мбайт (рис. 5).
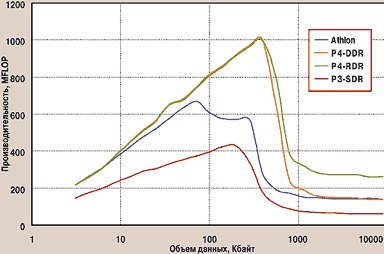
|
| Рис. 5. Производительность вычислений с плавающей точкой |
Тест Донгарра специфичен тем, что значение каждого элемента массива существенно зависит от остальных и весь процесс вычислений состоит в многократном переборе всего объема данных. Соответственно, сначала с увеличением объема массивов производительность растет за счет сокращения доли накладных расходов на организацию циклов и вызов процедур, а затем резко падает по исчерпании объема кэш-памяти. У Athlon по причине двухуровневого кэша наблюдается двугорбая кривая. В целом же производительность во всем рассматриваемом диапазоне определяется скоростными характеристиками памяти: сначала — кэш, затем — оперативной. В частности, производительность двух разных процессоров на массивах большого объема при использовании памяти одного вида не различается.
Для другого теста — решения системы дифференциальных уравнений — характерно то, что данные гораздо меньше зависят друг от друга: возмущения в среде распространяются со скоростью звука, поэтому на каждый элемент массива непосредственно влияют только его ближайшие соседи7. Это позволяет при проведении расчетов эффективно использовать кэш-память, поэтому влияние типа памяти проявляется более мягко, и граница, после которой сказывается преобладающее влияние памяти, отодвигается до нескольких мегабайт. Кроме того, из-за более сложных вычислений (например, уравнения состояния вещества) смещается баланс между мощностью ЦП и пропускной способностью ОЗУ, что при сравнительно небольших массивах вывело вперед процессор AMD. Но при больших объемах более быстрый тип памяти все равно побеждает. Производительность на рис. 6 дана по отношению быстродействию системы на основе процессора Pentium-100 с памятью FPM.
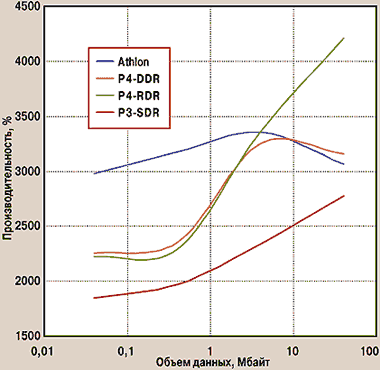
|
| Рис. 6. Решение системы дифференциальных уравнений |
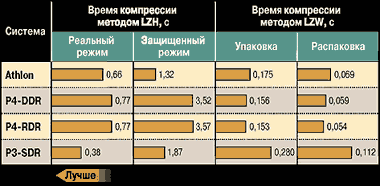
Так или иначе, нам часто приходится сталкиваться с компрессией данных. Принято различать два вида сжатия без потерь: сжатие-архивация, применяемое для уменьшения места, занимаемое отдельными файлами, и сжатие «на лету», при котором выполняется компрессия абсолютно всех данных (например, при установке DriveSpace или аналогичных драйверов), записываемых на диск или передаваемых по каналам связи. В первом случае важнее плотность сжатия, во втором — скорость работы алгоритма компрессии. Именно представителей этих двух алгоритмов — плотный LZH и быстрый LZW — мы и рассмотрим (диаграмма 4). При архивации данные помещаются в кэш-память (22 Кбайт) и преобладает внутрипроцессорная работа, а при сжатии «на лету» процессор вынужден обрабатывать данные, явно превосходящие по размеру кэш (5,7 Мбайт).
|
| Диаграмма 4 |
В тесте с LZH безусловным лидером оказался Pentium III; несмотря на двукратное превосходство «четверки» по тактовой частоте, она во столько же раз отстала по производительности. Итого: разница более чем вчетверо. При переходе в защищенный режим лидером стал Athlon, а двукратное отставание P4 от P3 сохранилось. Athlon же обходит своего конкурента почти втрое.
При использовании алгоритма LZW впереди Pentium 4, как обладающий более быстрой кэш-памятью, а «тройка» оказалась далеко позади. При этом степень отставания процессора AMD от лидера скорее соответствует его заявленному рейтингу, чем действительной тактовой частоте.
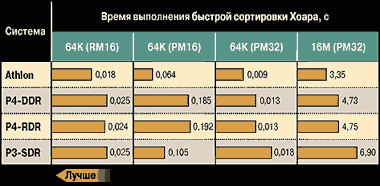
Не менее часто используемая операция, хотя и не такая заметная для пользователя, — сортировка данных. В качестве примера на диаграмме 5 приведено время сортировки 64-Кбайт массива программами, работающими в реальном (RM16), 16- и 32-разрядном защищенных (PM16 и PM32) режимах, а также время сортировки 16-Мбайт массива 32-разрядной программой.
|
| Диаграмма 5 |
Безусловным лидером во всех этих задачах стал AMD Athlon XP. Сортировка — процедура рекурсивная. В процессе рекурсии объем обрабатываемых данных быстро сокращается и становится меньше размера кэша первого уровня, в то же время алгоритм изобилует условными переходами и вызовами процедур, т. е. логикой исполнения, с которой Athlon справляется гораздо лучше.

|
| Диаграмма 6 |
Следующий тест — нахождение кратчайшего пути в неориентированном графе при помощи алгоритма Дейкстры (диаграмма 6). Алгоритм характеризуется интенсивным ветвлением и работой с памятью (в приведенном примере — около 270 Кбайт), он используется при стратегическом планировании, в том числе и в компьютерных играх (нахождение пути в лабиринте). Именно в применении к последним и написана программа, заполняющая карту проходимости размером 256x256 с учетом рельефа местности. Процедура написана на ассемблере и в значительной степени оптимизирована по скорости выполнения.
В лидеры вышел Pentium 4, что, видимо, обусловлено его более быстрой работой с кэш-памятью. Но и Athlon практически не отстал от конкурента, а если сделать поправку на его P-рейтинг (даже не на тактовую частоту), то этот результат можно было бы считать победой. Проиграл битву Pentium III, но с учетом его тактовой частоты и такой результат выглядит вполне достойно.
В заключение приведем результаты, позволяющие оценить производительность блока ММХ (диаграмма 6). Первая задача — микширование звука. Измерялось среднее время микширования одной минуты 8 монофонических каналов при различных частотах дискретизации и разрядности исходных образцов (8 и 16 бит, 22 и 44 кГц) с различным расположением по стереобазе в один стереофонический (16 бит, 44 кГц). Вторая задача — преобразование цвета из 32- в 16-разрядное представление для экранного буфера 800x600 точек. Наилучший результат здесь продемонстрировал Pentium 4. За ним следовал Athlon, и хотя отставание было не слишком существенное, оно все-таки больше, чем разница между тактовой частотой первого и заявленным P-рейтингом второго. Завершает список Pentium III, но для своей тактовой частоты он показывает хороший результат. Таким образом, Intel, разработавшая набор команд ММХ, остается лидером и в его аппаратной реализации.
Гораздо хуже для изделия AMD обстоят дела с перекодировкой цвета. С одной стороны, значительный объем данных (2 Мбайт на входе и 1 Мбайт на выходе) при малом времени преобразования наводит на мысль, что определяющее влияние здесь должна иметь скорость работы памяти. Для двух конфигураций Pentium 4 такое влияние отчетливо просматривается. Но с другой стороны, при надлежащей организации блока ММХ обе системы на DDR должны показывать близкую производительность. Этого, однако, не наблюдается, что еще раз подтверждает низкую производительность блока ММХ у процессора AMD. Заметим, что ММХ — не что иное, как средство быстрой обработки больших объемов данных. Между тем мы видели, что даже при применении таких традиционных средств, как блок вычислений с плавающей точкой, производительность зачастую ограничивается памятью, а новый процессор Intel гораздо быстрее работает с собственным кэшем. Поэтому вполне вероятно, что низкая производительность блока ММХ связана не со схемотехникой самого блока, а с различной скоростью кэша. Не вдаваясь в подробности, можно лишь констатировать относительно низкую производительность процессора AMD на приложениях, использующих инструкции SIMD. К сожалению, из-за особенностей видеоплаты провести последний тест на ПК с Pentium III не удалось.
Подведем итоги. Процессор AMD Athlon XP обладает самым быстрым на сегодняшний день ядром, но скорость работы с собственной кэш-памятью оставляет желать лучшего. Кристалл Pentium III по своим характеристикам очень похож на Athlon, но из-за более низкой тактовой частоты проигрывает ему в производительности. Остается лишь пожалеть, что это не сказывается на цене изделия Intel, которая для старших моделей по-прежнему остается довольно высокой. Процессор Pentium 4 обладает очень быстрой встроенной кэш-памятью, но крайне медленным ядром. Настолько медленным, что снижение его производительности по сравнению с быстродействием Pentium III впору объяснять не только одним лишь увеличением длины конвейера, повлекшим уменьшение числа выполняемых за такт инструкций. Можно даже предположить, что ядро Pentium 4 содержит до сих пор не обнаруженную и не исправленную ошибку в одном из блоков, обеспечивающих оптимизацию исполнения инструкций (например, в блоке предсказания ветвлений). В отличие от арифметического блока, ошибка здесь не приводит к неверным результатам вычислений, а лишь снижает быстродействие ЦП, что делает ее локализацию крайне затруднительной.
Результат таков: у Pentium 4 в 2—3 раза более медленное ядро, чем у Athlon XP, и примерно во столько же раз более быстрый кэш. Таким образом, складывается интересная картина, когда на одних приложениях эти процессоры показывают примерно равную производительность, а на некоторых других очень большое преимущество оказывается то у изделия Intel, то у AMD. И дело здесь не в ошибках или необъективности тестеров и не в качестве программ, а в свойствах самих процессоров.
На протяжении довольно длительного времени процессоры разных производителей можно было условно разделить на два типа: «быстрые» (Intel) и «дешевые» (все остальные). С выпуском AMD Athlon положение на рынке существенно изменилось: вступили в борьбу два практически одинаковых процессора, каждый из которых имел как «быструю», так и «дешевую» модификации. Теперь же, с появлением Pentium 4, мы получили уникальную ситуацию с двумя совершенно разными процессорами, о сравнении скоростей которых уже нельзя говорить однозначно — разница в их производительности при работе с конкретными приложениями может достигать нескольких раз, причем отклоняться в любую сторону.
Все это делает чрезвычайно актуальным вопрос: какой же процессор выбрать? Вместе с тем стало очевидно, что оперативная память безнадежно отстает от ЦП по тактовой частоте, поэтому совсем нередки случаи, когда мощный процессор задействует лишь 10—20% своих возможностей, а большую часть времени ожидает данных от ОЗУ. Таким образом, помимо вопроса выбора ЦП неизбежно возникает и другой: можно ли ждать от более мощного процессора хоть какого-то прироста производительности, или же ресурс пропускной способности шины уже исчерпан и следует ограничиться младшей моделью ЦП, выделив средства на покупку более быстрой памяти?
Для работы с приложениями, в которых основная нагрузка ложится на процессорное ядро (итерационные вычисления, включая фракталы, вычисления по сложным математическим формулам, в том числе тригонометрические, и т. п.) наиболее подходит Athlon. Он же оказывается более предпочтительным и в программах со сложной разветвленной структурой либо короткими циклами. Там же, где нужно многократно производить несложную (на уровне арифметических действий) обработку небольшого (умещающегося в кэш-памяти) объема данных, лучшим окажется Pentium 4.
Если же размер обрабатываемых данных велик (существенно больше объема кэш-памяти), а обработка не слишком сложна, то выбор типа процессора отходит на второй план, а определяющей становится скорость работы памяти. В таком случае, возможно, лучше отдать предпочтение памяти RDR RAM в сочетании с какой-нибудь младшей моделью процессора Intel. Не исключено, что очень хороших результатов можно добиться от связки Pentium III + i820 + RDR RAM. Это особенно справедливо при доступе к случайно расположенным в памяти элементам данных, имеющим небольшую длину (длина одного элемента — не более сотни байт), например при поиске в базе данных, целиком умещающейся в ОЗУ. Если же ЦП должен получать данные сравнительно крупными порциями (элемент данных — от нескольких сот байт), то, пожалуй, наилучшим будет сочетание RDR RAM PC1066 с младшей моделью Pentium 4, работающей на 533-МГц шине (это кристалл с частотой 2,26 ГГц).
Когда объем обрабатываемых данных невелик и не превышает объема кэш-памяти первого уровня Pentium III (16 Кбайт), то наиболее эффективным может оказаться использование именно этого процессора, сочетающего довольно быстрое ядро с быстрой кэш-памятью. Данный кристалл также будет предпочтительнее для выполнения программ в реальном (или виртуальном) режиме (программы DOS).
Кроме того, в некоторых случаях важно наличие дополнительного набора инструкций, поддерживаемых тем или иным процессором. У Pentium 4 это SSE2, а у Athlon XP — 3DNow! 2. К сожалению, их применение в программах, написанных на языках высокого уровня, затруднено, выгоду здесь можно извлечь либо от программ, созданных на ассемблере, либо от драйверов, обеспечивающих выполнение более-менее стандартных функций, например компрессию видеопотока или обработку трехмерной графики.
Редакция благодарит фирмы Eximer, ISM Computers и «Ф-Центр» за предоставленное оборудование.
Литература
- Андрианов С.А. Перманентная битва титанов. //Мир ПК №9/2000.
- Андрианов С.А. Мегагерцы в бутылочном горлышке. http://www. osp.ru/pcworld/2002/09/057.htm
- Бердышев Евгений. Технология ММХ. М.: Диалог-МИФИ, 1998.
- Гук Михаил, Юров Виктор. Процессоры Pentium III, Athlon и другие. - СПб.: Питер, 2000.
- Касперски Крис. Секреты копирования памяти. //Программист №3/02.
- Мейнелли Том. Какая память нужна Pentium 4. //Мир ПК №12/01.
1 Подробнее об оперативной памяти и ее взаимодействии с ЦП см. [2].
2 Вариант SDR здесь не рассматривается как неинтересный.
3 Single Instruction — Multiple Data, т. е. одной инструкцией выполняются действия над набором данных.
4 Регистров общего назначения, для строковых команд это EAX.
5 Хотя английская аббревиатура RAM и расшифровывается как «память с произвольным доступом», как раз в этом качестве современная динамическая память ведет себя хуже всего.
6 Самым мощным на сегодняшний день является суперкомпьютер Earth Simulator корпорации NEC, находящийся в Японии и достигающий пиковой производительности 36 TFLOP.
7 Примерно такой же зависимостью характеризуется и большинство алгоритмов обработки изображения.