 Только в модельном ряду настольных процессоров Intel флагманский титул «самый-самый», как эстафетная палочка, переходил от Pentium Extreme Edition 955 к Pentium Extreme Edition 965, от Intel Core 2 Extreme X6800 (Conroe) к Intel Core 2 Extreme Quad-Core QX6700 (Kentsfield). А если учесть еще и мобильные новинки, то в бурном потоке технической информации могут запутаться даже маркетологи Intel, не говоря уже о простых пользователях.
Только в модельном ряду настольных процессоров Intel флагманский титул «самый-самый», как эстафетная палочка, переходил от Pentium Extreme Edition 955 к Pentium Extreme Edition 965, от Intel Core 2 Extreme X6800 (Conroe) к Intel Core 2 Extreme Quad-Core QX6700 (Kentsfield). А если учесть еще и мобильные новинки, то в бурном потоке технической информации могут запутаться даже маркетологи Intel, не говоря уже о простых пользователях.
И тем не менее последним событием нашего времени смогут проникнуться даже блондинки — в мире появился первый четырехъядерный процессор Intel Core 2 Extreme QX6700. Значит, и Интернет станет быстрее, и в офисных программах работать будет легче, да и пасьянс «Косынка» прибавит динамичности. Как обычно?
Увы, в этот раз не все ладно с инновацией Intel. Ведь ядра процессора Kentsfield, по заявлениям конкурентов, «не совсем честные» и толку от их квартета на одной фронтальной шине может не быть вообще. И действительно, нельзя игнорировать возможные проблемы «бутылочного горлышка» при передаче данных между ядрами и ОЗУ, поскольку соответствующие транзакции могут создать серьезную нагрузку на общую шину FSB (Front-Side Bus — фронтальная шина). А в итоге — никакого роста производительности.
Но давайте не будем торопиться с выводами и детально изучим сам ЦП Kentsfield и вероятные сложности его внедрения на хорошо знакомой шине.
Intel Core 2 Extreme QX6700
Превзойдя смелые прогнозы оптимистов, в конце 2006 г. компания Intel представила сообществу новейший процессор для компьютерных энтузиастов — Intel Core 2 Extreme QX6700, состоящий из четырех ядер.
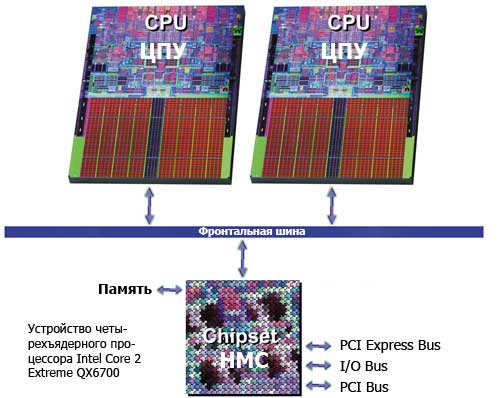
Однако стоит внимательно посмотреть на характеристики и блок-схему кристалла Kentsfield, как становится понятно: ЦП с индексом QX6700 объединяет в одном корпусе две двухъядерные приставки Intel Core 2 Duo E6700, которые располагаются на старой знакомой — фронтальной шине Intel (1066-МГц FSB). Но прежде чем перейти к списку предсказуемых минусов подобного решения, давайте взглянем на проблему N-ядерности с точки зрения производства.

Многоядерность в одном процессорном корпусе можно организовать тремя основными способами. Во-первых, вспомните технологию изготовления двухъядерных процессоров Pentium Extreme Edition 840 (800-я серия), когда из подложки «выпиливались» два кристалла, расположенные рядом. Вторым методом производства можно назвать процесс создания ЦП Pentium Extreme Edition 955 (900-я серия), когда в один корпус ЦПУ подбирались два различных кристалла, наиболее подходящие друг другу по частоте. И третьим способом построения многоядерности можно считать специальное проектирование процессора с заданным количеством ядер на одном монолитном кристалле (например, так создается продуктовая серия Intel Core 2 Duo и процессорная линейка AMD Athlon 64 X2).
Нетрудно догадаться, что третий путь реализации N-ядерности будет наиболее продуктивным, но при этом самым дорогим и сложным. Так что вполне понятно, почему инженеры компании Intel в производстве четырехъядерных ЦП Intel Quad-Core применили комбинацию второго и третьего способов. А именно, на соответствующих фабриках Intel тщательно подбирают два монолитных кристалла Intel Core 2 Duo из двух ядер и соединяют их в одном корпусе, чтобы сделать процессор Intel Core 2 Quad.
Кстати, такое технологическое упрощение дает возможность опережать главного конкурента AMD в плане достижений и позволяет быстро насытить рынок. Ведь, по данным независимых ИТ-аналитиков, за первые девять месяцев серийного производства компания Intel сможет выпустить около миллиона четырехъядерных ЦП, в то время как компания AMD — не более 50 тыс. альтернативных процессоров.
Но стоит ли радоваться быстрому появлению в магазинах четырехъядерных систем Intel? На самом деле два монокристалла Intel в одном корпусе ЦП представляют собой по сути простейшую двухпроцессорную систему (со всеми ее недостатками), где на общей шине располагаются два разных процессора Intel Core 2 Duo. И именно эта аналогия позволяет специалистам AMD называть две пары ядер Intel Conroe в одном ЦП Kentsfield «нечестными четырьмя ядрами».
Но, с другой стороны, два двухъядерных кристалла Conroe соединяются внутри процессорного корпуса Kentsfield той самой общей шиной FSB, которая затем соединяет ЦП QX6700 и НМС, а значит, по большому счету процессор Kentsfield является четырехъядерным устройством.
Здесь просто надо ответить на вопрос, а хватит ли пропускной способности общей фронтальной шины для двух пар ядер Intel Conroe, которые будут не только обращаться к ОЗУ через НМС по единственной шине, но и общаться по ней между собой. И чтобы «закрыть тему», надо понять, как работает процессорная шина и какому уровню трафика она может соответствовать.
Основные принципы работы FSB
Без сомнений, выпуск четырехъядерного процессора Intel Kentsfield — это большое достижение в отрасли. Однако многие специалисты сомневаются в пропускном потенциале фронтальной шины, ведущей свою историю с момента появления микроархитектуры P6 (включающей в себя семейства ЦП Pentium Pro, Pentium II, Pentium III), забывая при этом, что FSB изначально является многоагентной шиной.
Напомним: в классической архитектуре Intel есть главный агент — центральный процессор ЦП, который соединяется с узловым агентом — северным мостом — по фронтальной шине. Последнюю также можно называть внешней или процессорной. Когда речь идет о многоядерной (многопроцессорной) системе, то вычислительные ядра, одновременно присутствующие на внешней шине FSB, представляются симметричными агентами. Однако в любом случае факультативно приоритет на фронтальной шине FSB имеет северный мост — агент набора микросхем системной логики, который можно также именовать центральным агентом или агентом, умеющим откладывать транзакции.
Кроме того, в классической архитектуре стоит говорить о «двух с половиной» типах агентов, ведь наряду с симметричным и центральным агентами существует еще и так называемый «снупинг-агент» (от слова snooping — подглядывание, вынюхивание), чью роль исполняет процессор с задачей наблюдения за работой других агентов.
Конечно, шинная топология компьютерной платформы предусматривает и другие важные резиденты, например южный мост, который отвечает за операции ввода-вывода, и оперативную память, но общение с такого рода компонентами происходит уже не по шине FSB. А нас в первую очередь интересуют особенности передачи данных между процессором и северным мостом.
Итак, любая передача данных на процессорной шине является транзакцией, состоящей из нескольких фаз. Первая ступень — это фаза арбитража (Arbitration), вторая — фаза запроса (Request), третья — фаза снупинга (Snoop). Четвертая стадия — это фаза ответа (Response), которая несет в себе информацию о том, не было ли ошибки (Error) и будет ли передача данных, что может выливаться в появление пятого этапа — фазы передачи данных (Data transfer).
Как можно догадаться, последней ступени в транзакции может и не быть (если данные не должны передаваться), но фазы арбитража, запроса, снупинга и ответа присутствуют обязательно. К тому же стоит заметить, что все этапы транзакций выполняются на шине конвейерным методом, что крайне важно в случае процессора Kentsfield, когда на фронтальной шине располагаются сразу четыре симметричных агента и один центральный (четыре ядра и НМС).
Чтобы лучше понять роль конвейеризации фаз, давайте включим воображение и сначала представим ситуацию, когда к общей шине обращается один агент. Допустим, ядру 0 (агент №0) кристалла Kentsfield потребовался доступ к шине FSB. Тогда в первый такт на шине появится информация о запросе, т.е. о том, что агент №0 хочет получить какие-либо данные. После этого нулевой агент расположит на шине сам запрос, который будет содержать информацию, объясняющую, что же точно ему нужно. Следующей в транзакции пойдет фаза «вынюхивания» реакции агента, после чего возникнет ответ и, возможно, осуществится непосредственная передача данных.
Теперь представим ситуацию двух обращений к фронтальной шине от ядер 0 и 1. Разумеется, сначала на шине появится запрос от агента, который первым к ней обратится (по принципу «кто раньше встал, того и тапки»); пусть это будет агент №0. Но как только в транзакции от нулевого агента пройдет фаза арбитража, к шине получит доступ агент №1. Причем обычно между фазами арбитража и запроса в одной транзакции проходит лишь два такта (первый такт нужен для расположения заявки на шине, второй — для ее прохождения до пункта назначения). И это означает для нашего эпизода, что на процессорной шине FSB, отставая на пару тактов, появится запрос от второго агента и ответные действия для него.
Подобная конвейеризация фаз позволяет работать на процессорной шине сразу нескольким агентам, ведь при выполнении любых транзакций шина FSB практически не блокируется и остается доступна. Правда, стоит взять на заметку, что в один момент времени на шине могут конвейеризироваться не более 12 транзакций, которые отслеживаются в специальной очереди IOQ (In-Order Queue — упорядоченная очередь) на шине. Глубина буфера IOQ характеризуется возможностями ЦП (например, популярные процессоры микроархитектуры P6 позволяли немедля отрабатывать лишь восемь транзакций). Если очередь IOQ оказывается заполненной, то агенты не могут ставить в нее новые транзакции и отслеживать их. В такой ситуации на шине активируется сигнал BNR (Block Next Request — блокировка следующего запроса) и все новые запросы приостанавливаются до момента освобождения записи в буфере IOQ.
Кроме того, безотлагательно на шине может обрабатываться не более одной фазы арбитража от разных транзакций. Однако разные агенты одновременно могут располагать всевозможные запросы и пересылать нужные данные.
Здесь уместно добавить следующее: если запросы в череде транзакций у разных агентов шины FSB связаны между собой (например, агент №0 расположил на шине запрос к агенту №1, на который тот должен ответить), то соответствующие запросы в очередях двух агентов пойдут параллельно. Но если запросы в очередях разных агентов не связаны между собой, то они будут выполняться в соответствии со своими местами в буферных очередях.
Кстати, поскольку шина FSB является общей, то для ее корректного функционирования потребуется еще и распределение приоритетов по агентам, за которое собственно и отвечает фаза арбитража. Так, центральный агент (северный мост) в случае необходимости, очевидно, должен иметь больший приоритет по отношению к симметричным агентам (четыре ядра Kentsfield), распределяющими между собой приоритеты по времени обращения к процессорной шине. И если в череде транзакций от симметричных агентов появится специальный запрос от северного моста системной логики, то это обращение в шине может обладать внеочередным правом на исполнение.
Основные характеристики работы FSB
В эффективной работе процессорной шины важна не только конвейеризация транзакций, но и скорость передачи данных, которая зависит от частоты функционирования FSB, и объем передаваемых за такт данных.
К слову сказать, последние пять лет у процессорной шины росли только частотные характеристики и в настоящий момент достигли планки в 266 МГц. А вот ширина фронтальной шины FSB находится неизменно на отметке в 64 бит (т.е. 8 байт) в силу особенностей процессорной архитектуры. Легко подсчитать, что в работе компьютерной системы на базе четырехъядерного ЦП Intel Core 2 Extreme QX6700 по фронтальной шине с частотой 266 МГц может передаваться 2128 байт в секунду — довольно скромный показатель в эпоху многоядерности. Но не все здесь так печально.
Во-первых, фаза запросов в транзакциях на шине исполняется на удвоенной частоте, и если физическая частота FSB составляет 266,7 МГц, то ее эффективная частота FSB для ступеней запросов соответствует 533 МГц (т.е. пропускная способность вырастает до 4256 байт в секунду). А во-вторых, самая ресурсоемкая фаза — передача данных — осуществляется на учетверенной скорости по так называемой технологии четырехнасосной шины (Quad Pump Bus), что соответствует 1066- МГц FSB. Таким образом, сами данные передаются по процессорной шине со скоростью 8512 байт в секунду. Но не стоит забывать, что при трансляции не исключены «пузыри», поскольку нужные данные могут чередоваться в памяти, а значит, к передаче они будут готовы не сразу.
Ближайшие перспективы развития
Поскольку передовые инновации проходят апробацию в серверном сегменте, а потом «спускаются» в настольные компьютеры, то можно без труда предсказать скорое появление новых процессоров и соответствующих системных плат с FSB 1333 МГц (физическая частота 333 МГц) и даже с FSB 1600 МГц (физическая частота 400 МГц). Этот путь — увеличение пропускной способности фронтальной шины — даст инженерам некоторое время на новые эксперименты с N-ядерностью, но FSB 1600 МГц, судя по всему, — это частотный предел общей шины, а значит, нужно думать о революционных модификациях.
Конечно, на поверхности лежит идея об исследовании возможности повышения пропускной способности шины за такт. Но опыты соответствующих специалистов по увеличению количества параллельных линий для фронтальной шины привели к значительному усложнению разводки и заметному снижению физической частоты FSB, ведь даже на 64-бит шине появляются нешуточные проблемы согласования сигналов. Так что скорее всего этот путь пока бесперспективен и в ближайшее время индустрия по нему не пойдет.
Разумеется, можно вспомнить о решении инженеров компании AMD, которые в свои четырехъядерные процессоры AMD Quad-Core встроили особые контроллеры ОЗУ и пустили большую часть информационного трафика мимо НМС по двум специальным шинам (в случае двухканальной памяти DDR2). Но такой подход имеет свои недостатки (например, НМС работает с ОЗУ через ЦП), хотя в общем случае пропускная способность внутри архитектуры AMD выглядит шире.
Однако основные сомнения относительно ширины общей шины Intel для четырехъядерных процессоров Kentsfield связаны с изолированностью двух ядерных пар между собой, поскольку во многих ситуациях обмен данными идет через ОЗУ с использованием специального контроллера в северном мосту. И здесь есть место для гипотетической оптимизации с помощью одного технического решения.
Допустим, ядру 0 потребовались какие-либо данные. Если их не оказывается в общем с ядром 1 кэше L2 объемом 4 Мбайт, запрос посылается через системную шину во второй кэш L2, который принадлежит ядрам 2 и 3. Далее, если и в этом кэше нет нужной строки, запрос данных отправляется через НМС в системную память. Согласитесь, подобный алгоритм взаимодействия ядер порождает некоторые задержки в исполнении команд и создает лишний трафик на общей шине. Так вот, если внедрить в северный мост специальный буфер-ускоритель, аккумулирующий в себе содержание всех кэшей, то в некоторых случаях можно будет ускорить доступ к тем данным, которых не окажется во втором кэше L2.
Кстати, с чем-то похожим можно столкнуться в технологии буферизации кэшей в наборах серверных микросхем Intel с двойной независимой шиной, где особый буфер Snoop Filter ускоряет общение между ядрами по разным шинам. Но перспектива появления двойных шин и аккумулирующих буферов в настольных системах кажется весьма далекой. Гораздо проще увеличивать объем кэшей второго уровня, и очень скоро мы увидим N-ядерные процессоры с общим кэшем 6 Мбайт и более, что в определенных ситуациях снизит нагрузку для внешней шины.
Что показали тесты
Изучив принципы построения и функционирования процессорной шины, можно утверждать, что две пары ядер Intel Core 2 Duo E6700 в корпусе QX6700 могут быть производительней одной пары. Вот только наглядная демонстрация превосходства четырех ядер на общей шине доступна не во всех приложениях для пользователя.
Как видно по результатам игровых тестов Call of Duty 2 build 5060, Serious Sam 2 2.064b), Call of Juarez 1.0, от перехода к четырехъядерной поддержке игровых процессов нет никакого толку. Более того, в популярной игре Quake 4 1.3 наблюдается регресс результативности при попытке ОС самостоятельно распараллелить вычислительные задачи. Однако в играх Battlefield 2, Prey, The Chronicles of Riddick: EFBB, где N-ядерная оптимизация предусмотрена, наблюдается явный рост производительности, достигающий 10%.
Глядя на итоги специальных испытаний архивирования/разархивирования, шифрования/раскодирования, растровой декомпрессии, аудиоперекодирования и воспроизведения видео из тестового пакета PCMark05 1.2, можно констатировать равенство в плане производительности между процессорами Intel Core 2 Duo E6700 и Intel Core 2 Extreme QX6700. Однако если пытаться выполнить поставленные задачи параллельно, то очевиден позитивный эффект применения четырехъядерного ЦП, который выражается оценкой 8480 баллов (PCMark CPU) против 6742 баллов у двухъядерного устройства. Разумеется, нельзя забывать, что характер тестов PCMark носит синтетический оттенок, но аналогичная ситуация сложилась и с результатами выполнения специального сценария, написанного на языке C# и создающего несколько независимых вычислительных потоков на основе реальных приложений.
Из табл. 2 видно, что однопоточное выполнение отдельных сценариев работы игры Serious Sam 2 и архиватора WinRAR не дает ощутимых преимуществ четырех ядер над двумя. Но как только тестовый алгоритм запускает на переднем плане игровой процесс, а на заднем — процесс архивирования, то четырехъядерный процессор постепенно уходит в отрыв в соответствии с ростом количества вычислительных потоков в системе. И в некоторых комбинациях из потоков и приложений с применением XQ6700 мы видим примерно 10%-ный выигрыш в кадрах в секунду (в игре SS2) и одновременно 17%-ный выигрыш в секундах (в архивировании WinRAR).
Но важно заметить, что как только общее количество вычислительных потоков превышает четыре, заканчивается прирост производительности четырехъядерного процессора относительно двухъядерного. Это, конечно, может говорить о жестком ограничении пропускной способности процессорной шины, но вероятнее всего свидетельствует об ограничении вычислительной способности четырех ядер на общей FSB.
В любом случае очевидно: дальнейший рост производительности компьютеров на базе процессоров Intel будет построен на повышении пропускной способности процессорной шины и на увеличении количества ядер в системе. И мы уверены, что уже в этом году независимые эксперты смогут протестировать настольную платформу с более производительной шиной FSB и с б?ольшим количеством ядер в системе (хотя бы «логических»). А стоит ли называть ядра Intel «сомнительными» или «нечестными», каждый должен решать для себя сам.
Редакция журнала «Мир ПК» благодарит компанию Philips (www.philips.ru) за предоставленный для проведения тестирования монитор Philips Brilliance 202P7.
Полный вариант статьи см. на «Мир ПК-диске».
Таблица 1. Технические характеристики многоядерных процессоров Intel
Как мы тестировали
Тестирование проводилось под управлением английской версии операционной системы Windows XP Professional SP2 (build 2600 + официальные обновления и «заплатки»). Для работы с графическими подсистемами использовался видеодрайвер ForceWare 93.71.
В качестве измерительного инструментария применялся сценарный тест SmartFPS.com 1.5 (www.smartfps.com) для автоматизированного определения производительности в игровых приложениях Call of Duty 2, Battlefield 2, Serious Sam 2, Call of Juarez, Quake 4, Prey и The Chronicles of Riddick: EFBB. Кроме того, в испытаниях многопоточности ЦП использовался автономный модуль SmartFPS.com CPU 1.5, умеющий создавать параллельные вычислительные потоки на основе реальных приложений Serious Sam 2 и WinRAR 3.60.
Все запуски тестовых сценариев выполнялись с использованием монитора Philips Brilliance 202P7 в графических разрешениях 640×480, 800×600 и 1024×768 точек с глубиной цвета 32 бита и в режиме отключенных полноэкранного сглаживания и анизотропной фильтрации.
Аппаратная конфигурация тестового стенда в корпусе Compucase LX-7X31BS была следующей: процессоры Intel Core 2 Duo E6700 и Intel Core 2 Extreme QX6700, системная плата Intel D975XBX, видеоплата NVIDIA GeForce 7800GT, двухканальное ОЗУ на базе модулей Samsung PC2-6400 (2×512 Мбайт, DDR2, 800 МГц, 5-4-4-18), жесткий диск WD Caviar SE16 WD5000KS (SATA 2, 7200 об/мин, 500 Гбайт), оптический DVD-привод TEAC DV-516, блок питания Thermaltake Pure Power-680APD. Энергопотребление системного блока (без монитора) контролировалось сертифицированным прибором учета электроэнергии «Меркурий 200.02» (классы точности 1 и 2).
Технологии Intel
Intel Viiv — технология доступа к компьютерным развлечениям с помощью дистанционного управления. Система на основе технологии Intel Viiv представляет собой мощный мультимедийный компьютер, который можно подключить к телевизору. Можно также объединить в сеть другие устройства с поддержкой технологии Intel Viiv и обеспечить возможность развлечений в других комнатах цифрового дома.
Intel vPro — набор особенностей корпоративных ПК, в который входят интегрированные средства управления, повышенная безопасность, эффективное энергопотребление и высокая производительность.
Intel VT — технология, позволяющая использовать одну аппаратную платформу как несколько виртуальных систем. Для предприятий технология Intel VT обеспечивает удобство управления, сокращение времени простоя и повышение продуктивности работы сотрудников за счет выделения изолированных разделов для вычислительных операций.
Intel HT — технология Hyper-Threading позволяет операционной системе рассматривать и использовать один физический процессор как два логических. Технология HT поддерживает многозадачность, обеспечивая одновременное выполнение двух приложений без замедления работы системы.
Enhanced Intel Speed Step — усовершенствованная технология Intel Speed Step, благодаря которой ПК работает тише и нагревается меньше (в зависимости от реализации системы и модели использования).
Intel EM64T — технология Intel Extended Memory 64 Technology аналогична ноу-хау AMD64 и позволяет процессору обращаться к большему объему виртуальной и физической памяти. Для реализации технологии EM64T, впрочем как и технологии Intel VT, необходима вычислительная система на базе процессора, набора микросхем, BIOS, ОС, драйверов и приложений, поддерживающих эти технологии.
Execute Disable Bit — технология, которая обеспечивает расширенную антивирусную защиту при использовании с поддерживающей ее операционной системой, предотвращая заражение системы определенными типами вирусов. Для реализации функции Execute Disable Bit требуется ПК с процессором и операционной системой, поддерживающими эту функцию.