Не хватает, скажем, человеку рук — он создает себе дубля, безмозглого, безответственного, только и умеющего что паять контакты, или таскать тяжести, или писать под диктовку, но зато уж умеющего это делать хорошо.
Аркадий и Борис Стругацкие
Параллельная программа — частный случай разделения труда
Реализация такого подхода в сфере производства позволила в разы увеличить выпуск продукции. Поэтому неудивительно, что с появлением компьютеров возник вопрос о переносе принципа разделения труда на работу компьютерных программ. Исследования в данной области позволили обнаружить и тот приятный факт, что громоздкие математические вычисления, связанные, например, с операциями над матрицами, можно разбить на независимые подзадачи. Каждую подзадачу можно выполнить отдельно, а затем быстро получить результат решения исходной задачи, скомбинировав результаты решения подзадач. Поскольку подзадачи независимы, их решением могут одновременно заниматься несколько исполнителей. Если в качестве исполнителя выступает компьютер, то такой подход позволяет находить решения для очень сложных в вычислительном плане задач реалистичного моделирования объектов окружающей действительности, криптоанализа, контроля технологических процессов в реальном масштабе времени. Именно по этому принципу работают все суперкомпьютеры, которыми гордятся научные лаборатории и вычислительные центры.
Достигнув предела в увеличении быстродействия процессоров, связанного с принципиальными физическими ограничениями, производители компьютеров стали наращивать в своих изделиях количество вычислительных узлов. И сегодня в корпусе обычной персоналки можно встретить то, что еще недавно называлось суперкомпьютером, — многоядерное вычислительное устрой-ство. Операционные системы уже давно готовы к появлению такой техники. Unix и Linux, OS/2, Mac OS, современные версии Microsoft Windows, способны продемонстрировать увеличение производительности при одновременном выполнении нескольких программ. Например, при просмотре видеофильма может незаметно осуществляться антивирусное сканирование жесткого диска. Но бывают ситуации, когда больших вычислительных ресурсов может потребовать решение только одной задачи. Не беря в расчет проблему моделирования ядерного синтеза или взлома пароля к архиву, вспомним о таких обыденных вещах, как кодирование музыки и видео, компьютерные игры. Программы, реализующие эти задачи, полностью задействуют ресурсы центрального процессора. Однако рост количества процессоров в системе не даст заметного прироста производительности в приведенных примерах, если при разработке программ не применялось специальных методов. Действительно, откуда операционной системе знать детали реализации методов кодирования, чтобы распределить вычисления по процессорам? Разве ей известно, как параллельно рассчитывать сцену игровой ситуации?
Процессы и нити — близнецы-братья
Итак, в нашем распоряжении оказался многопроцессорный компьютер. Мы проанализировали задачу и выделили подзадачи, которые можно решать одновременно. Как в программе оформить решения этих подзадач? Современные операционные системы предлагают два варианта одновременного выполнения кода — в виде процессов и в виде нитей.
Процесс — это работа программы, загруженной в оперативную память и готовой к выполнению. Так, когда мы делаем сразу два дела — просматриваем новости в Интернете и записываем файлы на компакт-диск, одновременно выполняются два процесса — работают интернет-браузер и программа записи на CD. Процесс состоит из кода программы, данных, с которыми производятся операции, и различных ресурсов, например файлов или системных очередей, принадлежащих программе. Каждый процесс выполняется в своем адресном пространстве, т. е. имеет доступ только к своему участку оперативной памяти. С одной стороны, это хорошо, потому что один процесс не может помешать другому (до тех пор, пока они не обратятся к неразделяемому ресурсу, например дисководу, но это — другой разговор) и ошибки в работе одной программы никак не скажутся на работе другой. В то же время, если процессы призваны решать одну общую задачу, возникает вопрос: каким образом они могут обмениваться информацией и вообще взаимодействовать?
Нить — это средство разветвления программы внутри процесса. Процесс может содержать несколько нитей, каждая из которых выполняется независимо от других, сохраняя собственные значения регистров и ведя свой стек. Нитям доступны все глобальные ресурсы выполняемого процесса, например открытые файлы или сегменты памяти. Каждый процесс имеет как минимум одну выполняемую нить — основную. Когда решение задачи подходит к участку, допускающему распараллеливание, процессом порождается необходимое количество дополнительных нитей, которые выполняются одновременно, решают свои подзадачи и возвращают результат основной нити.
Для решения сложных задач мало осуществить параллельное выполнение различных участков кода, надо еще организовать обмен результатами их работы, т. е. наладить взаимодействие между этими участками. Казалось бы, в случае нитей это можно легко реализовать с помощью доступа к оговоренному общему участку оперативной памяти. Однако простота эта обманчива, поскольку операции записи в оперативную память различными нитями могут пересечься самым непредсказуемым образом, так что целостность информации, хранящейся в этой области памяти, будет нарушена (см. врезку «Пример взаимодей-ствия нитей»).
В двух следующих разделах статьи о синхронизации и взаимодействии одновременно выполняющихся участков программы термины «процесс» и «нить» будут использоваться совместно, так как описываемые механизмы в большинстве случаев применимы к обоим понятиям.
Синхронизация…
 Современные операционные системы предлагают широкий набор средств для синхронизации параллельных процессов. Самым простым средством синхронизации одновременно выполняющихся участков кода является ожидание одной нитью завершения выполнения другой нити. Этот же механизм обеспечивает и поддержку выполнения операционной системой асинхронных операций, таких как файловый ввод-вывод или обмен данными по сети. Кроме того, функции ожидания могут использоваться при взаимном оповещении процессов о происходящих событиях (рис. 1).
Современные операционные системы предлагают широкий набор средств для синхронизации параллельных процессов. Самым простым средством синхронизации одновременно выполняющихся участков кода является ожидание одной нитью завершения выполнения другой нити. Этот же механизм обеспечивает и поддержку выполнения операционной системой асинхронных операций, таких как файловый ввод-вывод или обмен данными по сети. Кроме того, функции ожидания могут использоваться при взаимном оповещении процессов о происходящих событиях (рис. 1).
Так, например, при разработке системы банковского операционного дня может быть зарегистрировано событие — поступление средств на банковский счет клиента. Его сигнальным состоянием станет оповещение клиента о переводе денег. Данного события может ожидать нить, осуществляющая исполнение клиентских платежных инструкций.
Если существует вероятность того, что разные участки программы могут одновременно осуществить модификацию какой-нибудь переменной, то необходимо применять защиту этой переменной. Допустим, если одна нить занимается расчетами игровой сцены, а другая — ее перерисовкой, то перерисовка должна выполняться только после выполнения всех необходимых вычислений. Чтобы этого достичь, в операционные системы введен специальный объект — мьютекс (от англ. «mutual execution» — смешанное выполнение).
 Прежде чем начать изменение переменной, нить должна осуществить захват соответствующего этой переменной мьютекса. Если ей это удалось, то мьютекс изменяет свое внутреннее состояние, а нить продолжает выполняться. Если в то время, как с переменной осуществляется работа первой нити, соответствующий мьютекс попытается захватить другая нить, ей будет в этом отказано, и она будет вынуждена дождаться освобождения мьютекса первой нитью (рис. 2). Таким образом гарантируется работа только одного участка кода в конкретный момент времени с конкретной переменной.
Прежде чем начать изменение переменной, нить должна осуществить захват соответствующего этой переменной мьютекса. Если ей это удалось, то мьютекс изменяет свое внутреннее состояние, а нить продолжает выполняться. Если в то время, как с переменной осуществляется работа первой нити, соответствующий мьютекс попытается захватить другая нить, ей будет в этом отказано, и она будет вынуждена дождаться освобождения мьютекса первой нитью (рис. 2). Таким образом гарантируется работа только одного участка кода в конкретный момент времени с конкретной переменной.
При программировании бывают ситуации, когда в одном участке кода необходимо модифицировать несколько глобальных переменных. Если существует вероятность одновременного выполнения этого кода несколькими нитями, необходимо предусмотреть его защиту. Специально для такого случая операционные системы предлагают организовать соответствующий код в критическую секцию.
 Критическая секция может выполняться в каждый момент времени только одной нитью. Другая нить должна узнать, доступна ли критическая секция для выполнения, и в случае отрицательного ответа либо дождаться ее освобождения, либо заняться выполнением другой операции (рис. 3). Критические секции отличаются от мьютексов еще и тем, что одна и та же нить может многократно входить в захваченную ею критическую секцию, тогда как при попытке повторного захвата мьютекса выполнение нити будет остановлено и может возникнуть так называемый тупик.
Критическая секция может выполняться в каждый момент времени только одной нитью. Другая нить должна узнать, доступна ли критическая секция для выполнения, и в случае отрицательного ответа либо дождаться ее освобождения, либо заняться выполнением другой операции (рис. 3). Критические секции отличаются от мьютексов еще и тем, что одна и та же нить может многократно входить в захваченную ею критическую секцию, тогда как при попытке повторного захвата мьютекса выполнение нити будет остановлено и может возникнуть так называемый тупик.
Предположим, что имеется некоторый набор однотипных ресурсов, например несколько окон для вывода информации или пул сетевых принтеров. Для ведения учета распределения таких ресурсов между процессами предназначены семафоры.
 Семафор — это системный объект, который представляет собой счетчик. Перед началом работы с ресурсом из набора нить должна обратиться к ассоциированному с ним семафору. Если значение счетчика семафора больше нуля, то нить допускается к работе с ресурсом, а значение счетчика уменьшается на единицу (рис. 4). Если же со всеми ресурсами из набора уже ведется работа, то нить будет поставлена в очередь. По завершении использования ресурса нить сообщает об этом семафору, значение его счетчика увеличивается и ресурс снова может быть предоставлен в пользование.
Семафор — это системный объект, который представляет собой счетчик. Перед началом работы с ресурсом из набора нить должна обратиться к ассоциированному с ним семафору. Если значение счетчика семафора больше нуля, то нить допускается к работе с ресурсом, а значение счетчика уменьшается на единицу (рис. 4). Если же со всеми ресурсами из набора уже ведется работа, то нить будет поставлена в очередь. По завершении использования ресурса нить сообщает об этом семафору, значение его счетчика увеличивается и ресурс снова может быть предоставлен в пользование.
Иногда возникает необходимость экстренного прерывания процесса ради выполнения каких-нибудь неотложных действий. В некоторых операционных системах для этого служат сигналы. Процесс, которому потребовалось выполнить специальную операцию, отправляет другому сигнал. При написании другого процесса должна быть предусмотрена процедура обработки сигналов: по его получении процесс может приостановиться или завершиться, выполнить предусмотренную специально для этого случая подпрограмму или просто этот сигнал проигнорировать.
… и взаимодействие
 Как сказано выше, для совместного решения общей задачи процессам может понадобиться не только согласовывать свою работу, но и осуществлять обмен информацией, например промежуточными результатами. Для этого можно использовать совместный доступ к оперативной памяти, обмен информацией через файл, передавать данные через однонаправленные каналы или имитировать сетевую работу (рис. 5).
Как сказано выше, для совместного решения общей задачи процессам может понадобиться не только согласовывать свою работу, но и осуществлять обмен информацией, например промежуточными результатами. Для этого можно использовать совместный доступ к оперативной памяти, обмен информацией через файл, передавать данные через однонаправленные каналы или имитировать сетевую работу (рис. 5).
Наиболее быстрый и самый очевидный способ обмена информацией между одновременно выполняющимися участками кода — использование общей области оперативной памяти. Один процесс записывает данные в память, другой их считывает. Однако применяя этот метод, необходимо позаботиться о синхронизации процессов одним из описанных выше способов. Если обмен информацией через разделяемую память между нитями может быть реализован непосредственно, то процессы должны сначала запросить у операционной системы необходимый сегмент памяти и согласовать процедуру его использования.
Следующий метод информационного обмена — посредством каналов. Канал (pipe) — это системный объект, позволяющий передавать информацию, как правило, в одном направлении. Наиболее известные примеры каналов — стандартные потоки ввода и вывода (stdin, stdout). Поток вывода одного процесса может быть направлен в поток ввода другого. После этого информация, которая записывается в выходной поток первого процесса, может быть прочитана вторым процессом. Операционные системы позволяют создавать дополнительные каналы. Для работы с каналами используются функции, по синтаксису аналогичные функциям файловых операций.
Осуществить обмен данными можно и с помощью файлов. Современные операционные системы имеют встроенные механизмы буферизации информации, которая участвует в файловых операциях, поэтому такой способ достаточно эффективен. Однако с точки зрения безопасности такой подход уступает описанным выше, поскольку доступ к файлу, используемому для межпроцессного обмена, может получить неавторизованное приложение. Перед применением этого метода нужно обратиться к руководству по реализации файловых операций в конкретной операционной системе и принять меры по защите данных.
Дуплексный обмен данными между процессами может быть реализован сетевыми средствами операционной системы. С помощью сокетов (socket) два процесса могут установить между собой канал для передачи данных точно так же, как это делают программа-браузер и HTTP-сервер. Формат передаваемых данных при этом может быть абсолютно произвольным, главное, чтобы процессы использовали одинаковые соглашения процедуры обмена, протокол. Более того, ничто не мешает этим процессам выполняться на различных компьютерах.
Суперкомпьютеры — повсюду!
Говоря о параллельном выполнении программ, мы предполагали, что работа ведется на компьютере с несколькими процессорами. Однако это не единственная платформа для выполнения параллельных программ. Рассмотрим простейшую вычислительную сеть, состоящую из десяти обычных однопроцессорных компьютеров, объединенных витой парой по технологии FastEthernet. Знакомая система? Что же представляет собой каждый компьютер? Вообще говоря, он является процессором с доступной ему оперативной и дисковой памятью. Каждый представляет собой отличную площадку для выполнения одного процесса. А если на всех десяти ПК одновременно запустить программы, которые решают подзадачи подбора пароля к архиву? Очевидно, что решение задачи потребует гораздо меньше времени, чем на одной-единственной машине. А когда сеть состоит не из десяти, а из ста компьютеров? А если она подключена к Интернету?
Из этого примера видно, что даже небольшие локальные сети обладают значительной потенциальной вычислительной мощностью. И если использовать эту мощь для компьютерных игр вряд ли удастся, то для работы систем автоматизированного проектирования — вполне. Группа компьютеров, объединенных шиной передачи данных в единую вычислительную систему, называется кластерной системой или кластером. Надо только написать специальную программу и реализовать в ней возможность обмена информацией между одновременно выполняющимися ее экземплярами (процессами) через локальную сеть. Вообще говоря, такая программа может иметь традиционную клиент-серверную архитектуру, т. е. должна быть способна как отправить сообщение своим соседкам, так и прислушиваться к ним. Но чтобы упростить разработку программ для кластерных систем, существуют готовые решения, например MPI и PVM, дающие программисту средства для осуществления как двухточечного, так и коллективного взаимодействия процессов, выполняющихся на узлах кластерной системы, а также способы их синхронизации.
Спецификация MPI (Message Passing Interface — интерфейс передачи сообщений) предлагает модель программирования, в которой программа порождает несколько процессов, взаимодействующих между собой с помощью обращения к подпрограммам передачи и приема сообщений. Ее реализации представляют собой библиотеки подпрограмм, подходящие для использования в программах на языках Си/C++ и Фортран. При запуске MPI-программы создается фиксированное число процессов. Cпецификация MPI создавалась как промышленный стандарт, поэтому ее средства ориентированы на достижение высокой производительности на симметричных многопроцессорных системах и однородных кластерных системах (суперкомпьютерах). Существует свободная реализация MPI — MPICH (MPI CHamelion), версии которой для операционных систем Windows и Linux доступны для загрузки в Интернете по адресу http://www.unix.mcs.anl.gov/mpi/mpich/. Будучи установлена на персональном компьютере, система MPICH позволяет выполнять разработку и отладку программ для дальнейшего использования без каких бы то ни было модификаций на кластерах или суперкомпьютерах.
В отличие от MPI система разработки и выполнения параллельных программ PVM (Parallel Virtual Machine) создавалась в рамках исследовательского проекта с ориентацией на гетерогенные вычислительные комплексы. Она позволяет объединить разнородный набор компьютеров, связанных сетью, в вычислительный ресурс, который называют параллельной вычислительной машиной. Компьютеры могут иметь различную архитектуру и работать под различными операционными системами. Система PVM представляет собой набор библиотек и утилит, предназначенных для разработки и отладки параллельных программ, а также для управления конфигурацией виртуальной вычислительной машины. Реализована поддержка языков программирования Си/C++ и Фортран. Конфигурация вычислительного комплекса может изменяться динамически путем исключения отдельных узлов и добавления новых. Такая универсальность достигнута, в частности, и за счет некоторого уменьшения производительности по сравнению с системой MPI.
Таким образом, как MPI, так и PVM позволяют с весьма небольшими затратами превратить локальную сеть организации в мощное вычислительное устройство, способное эффективно решать сложные задачи.
Очевидно, что параллельные вычислительные системы — это уже сегодняшний день. Операционные системы предоставляют разработчикам необходимый низкоуровневый сервис, а для решения прикладных задач существуют готовые проверенные средства в форме специализированных утилит и библиотек для популярных языков программирования высокого уровня. И чтобы не остаться за бортом в своей профессиональной сфере, программист должен овладевать методами разработки параллельных программ.
ПРОЦЕССЫ. Запуск процессов в Unix и Windows
Интересно, что в операционных системах Microsoft Windows и Unix (Linux) разработчики по-разному подошли к вопросу запуска дочернего процесса. Для программиста, использующего WIN32 API, все выглядит вполне естест-венно. В точке запуска вспомогательного процесса вызывается функция CreateProcess (), одним из ее аргументов указывается путь к EXE-файлу c программой, которую нужно выполнить.
В Unix-подобных операционных системах это делается иначе. В той точке кода, где необходимо создать новый процесс, используется системный вызов fork (). В результате работающая программа «раздваивается», т. е. осуществляется копирование состояния программы на момент исполнения fork () (под состоянием понимаются значения регистров центрального процессора, стек, область данных и список открытых файлов) и на основе этой копии запускается новый процесс, который владеет той же информацией, что и процесс-родитель. Каждый процесс, родительский и порожденный, продолжает выполнять одну и ту же программу с команды, следующей за системным вызовом fork (). Поскольку выполнение двумя процессами одной и той же работы бессмысленно, возникает вопрос: как реализовать в каждом из получившихся процессов решение своей собственной подзадачи? Дело в том, что результатом выполнения функции fork () с точки зрения родительского процесса является идентификатор процесса порожденного, а в порожденный процесс fork () возвращает просто нулевое значение. По этому коду каждый процесс может идентифицировать себя. А дальше — дело техники. Дочернему процессу остается подготовить среду для выполнения новой программы, с помощью системного вызова exec () загрузить ее код и передать ей управление.
ПРОЦЕССЫ. Пример взаимодействия нитей
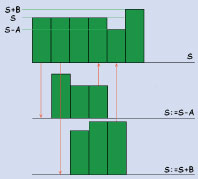 Представим себе биллинговую систему оператора сотовой связи на базе мощного многопроцессорного сервера. Не удивительно, если в такой системе списание средств с лицевого счета клиента за предоставленные услуги будет осуществляться одной нитью программы, а зачисление на счет клиентских платежей — другой. Первую операцию можно записать в виде: S:= S — A, где S — сальдо лицевого счета на момент выполнения операции, A — стоимость совершенных телефонных разговоров. Процессор выполнит такую операцию в три этапа: сначала будет получено исходное значение переменной S, затем оно будет уменьшено на величину A, после чего результат будет записан в ячейку S. Аналогично выполняется вторая операция: S:= S + B, где B — сумма внесенных клиентом средств. Допустим, что через некоторое время после оплаты через кассу банка клиент совершит телефонный звонок. Поскольку зачисление клиентских платежей на лицевой счет по ряду объективных причин происходит с некоторой задержкой, нельзя исключать вероятность того, что обе операции — зачисления и списания — практически одновременно начнут выполняться в биллинговой системе. Предположим, что первой выполняется операция списания и с отставанием на один такт за ней идет операция зачисления (см. рисунок). После выполнения трех тактов операции списания текущий баланс счета станет равным S—A, однако четвертый такт изменит это значение на S+B.
Представим себе биллинговую систему оператора сотовой связи на базе мощного многопроцессорного сервера. Не удивительно, если в такой системе списание средств с лицевого счета клиента за предоставленные услуги будет осуществляться одной нитью программы, а зачисление на счет клиентских платежей — другой. Первую операцию можно записать в виде: S:= S — A, где S — сальдо лицевого счета на момент выполнения операции, A — стоимость совершенных телефонных разговоров. Процессор выполнит такую операцию в три этапа: сначала будет получено исходное значение переменной S, затем оно будет уменьшено на величину A, после чего результат будет записан в ячейку S. Аналогично выполняется вторая операция: S:= S + B, где B — сумма внесенных клиентом средств. Допустим, что через некоторое время после оплаты через кассу банка клиент совершит телефонный звонок. Поскольку зачисление клиентских платежей на лицевой счет по ряду объективных причин происходит с некоторой задержкой, нельзя исключать вероятность того, что обе операции — зачисления и списания — практически одновременно начнут выполняться в биллинговой системе. Предположим, что первой выполняется операция списания и с отставанием на один такт за ней идет операция зачисления (см. рисунок). После выполнения трех тактов операции списания текущий баланс счета станет равным S—A, однако четвертый такт изменит это значение на S+B.
В результате окончательное сальдо лицевого счета будет равно S+B вместо правильного значения S-A+B. В другой ситуации такая коллизия могла бы завершиться и не столь оптимистично для клиента. Поэтому во избежание подобных накладок необходимо предпринимать специальные меры по защите отдельных участков программы от одновременного выполнения.