
Поможет ли новый набор микросхем покончить с проблемами масштабируемости Windows NT?
Во многих компаниях используются серверы, оснащенные процессорами Intel. Такое решение дает ряд преимуществ: дешевле обходятся аппаратные компоненты, шире выбор поставщиков оборудования, наконец, на рынке представлено больше прикладных программ для деловых применений. С ростом популярности NT Server многие фирмы переносят программы уровня предприятия, такие, как поиск и выборка данных из разных источников, системы планирования ресурсов предприятия (enterprise resource planning — ERP) и терминальные серверы на машины с процессорами Intel, работающие в среде NT Server. Понятно, что этим компаниям требуется более высокая производительность, и они, соответственно, предъявляют к своим компьютерам повышенные требования по части масштабируемости. Между тем, 4-процессорные серверы с возможностями симметричной многопроцессорной обработки (symmetric multuprocessing — SMP) уже не удовлетворяют этим требованиям. В такой ситуации в Intel разработали новую архитектуру для SMP-систем, которая получила название Profusion. Ею реализуется стандартизованный метод использования в компьютерах восьми процессоров Intel. Надо сказать, что существует множество машин, оснащенных четырьмя (и даже более) процессорами, но проблема в том, что они выполнены на базе нестандартных архитектур. Повысить производительность таких приложений для NT, как SAP R/3 или Microsoft SQL Server 7.0 можно только с помощью истинно масштабируемого 8-процессорного SMP-сервера.
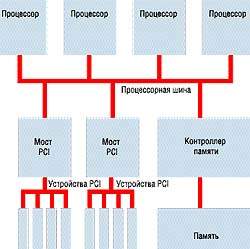 |
| РИСУНОК 1. Традиционная архитектура 4-процессорного SMP-сервера |
Уникальность архитектуры Profusion в том, что она обеспечивает возможность оснащения сервера восемью процессорами Intel. Перед покупкой нового SMP-сервера важно разобраться в особенностях этой архитектуры. Помочь читателям понять, за счет чего достигается масштабируемость архитектуры Profusion, и призвана настоящая статья, в которой рассматривается как сама архитектура в целом, так и все ее компоненты.
Почему предел — четыре
Прежде всего, давайте коротко остановимся на традиционной архитектуре 4-процессорного SMP-сервера на платформе Intel. Мне хотелось бы пояснить, какие обстоятельства осложняют создание SMP-сервера с числом процессоров более четырех.
На Рисунке 1 дано схематичное представление традиционной архитектуры 4-процессорного SMP-сервера с процессорами Intel Pentium Pro или Xeon. Машина укомплектована четырьмя процессорами, одним или более мостами PCI, каждый из которых позволяет использовать до четырех устройств PCI, и одним контроллером памяти, обеспечивающим доступ к памяти. Надежное взаимодействие процессоров, мостов PCI и контроллера памяти достигается с помощью шины процессора (многие называют такую шину системной). Так вот, описанная архитектура вполне допускает использование четырех процессоров, но применение большего их числа связано с серьезными трудностями. Здесь мы имеем дело сразу с несколькими ограничениями, и первое из них определяется самой природой процессов, происходящих в электронных устройствах. Скажем, при тактовой частоте 100 МГц системная шина сервера на базе процессоров Pentium II или Pentium III Xeon в состоянии обеспечить работу не более чем пяти процессоров. При повышении тактовой частоты шины приходится уменьшать ее длину, что, в свою очередь, ограничивает число подключаемых к шине компонентов. Второе ограничение — по пропускной способности. Скорость системной шины традиционного SMP составляет порядка 400 Мбит/с. Этого достаточно для работы четырех процессоров, но если их будет больше, обеспечить необходимую полосу пропускания уже трудно. Наконец, существует ограничение и со стороны логической схемы построения сервера: дело в том, что в традиционных системах SMP для обозначения процессоров применяется двухразрядный код, а он дает возможность идентифицировать на одной шине не более четырех процессоров. Правда, SMP-системы на базе Pentium Pro и более поздних разновидностей Pentium позволяют работать с протоколом конвейерной обработки транзакций (pipelined transaction protocol), который позволяет системной шине начинать обработку новых запросов от других процессоров еще до завершения пересылки данных по запросу первого процессора. Но когда на шину возлагается задача обслуживания дополнительных процессоров, это может привести к увеличению числа запросов, поступающих к этой шине в одно и то же время. А это осложняет контроль согласованности данных, обеспечивающий безошибочную передачу информации по шине.
Вот почему для успешной реализации SMP-системы с числом процессоров Intel более четырех в архитектуру SMP должны быть внесены изменения. Для преодоления рассмотренных нами ограничений исследователи предложили несколько вариантов решений. В частности, предлагается использовать существующие технологии кластеризации, архитектуру неоднородного доступа к памяти (NUMA — non-uniform memory architecture) и увеличить число системных шин. (Вообще-то было предложено еще два решения на базе шин — применение двухпортовых схем памяти и шлейфовое соединение шин — но они были отвергнуты специалистами как недостаточно эффективные с точки зрения масштабируемости системы). Технология кластеризации предусматривает формирование кластеров из двух или более 4-процессорных SMP-серверов. Такое решение хорошо масштабируется и обеспечивает как отказоустойчивость, так и выравнивание нагрузок, однако здесь не обойтись без переработки операционных систем и прикладных программ. Архитектура NUMA, реализуемая в Unix-системах высокого класса, позволяет включать в систему несколько дополнительных 4-процессорных блоков, так называемых «квадов» (скажем, в 32-процессорную систему входят 8 таких блоков). Но в этих случаях тоже приходится переписывать и ОС, и приложения. А вот третий метод — увеличение числа системных шин — не предполагает модификации ни операционных систем, ни прикладных программ. Но как построить новую систему? Казалось бы, решение, что называется, лежит на поверхности: надо организовать шины системы в некую иерархию. Архитектура с иерархией шин, проиллюстрированная на Рисунке 2,
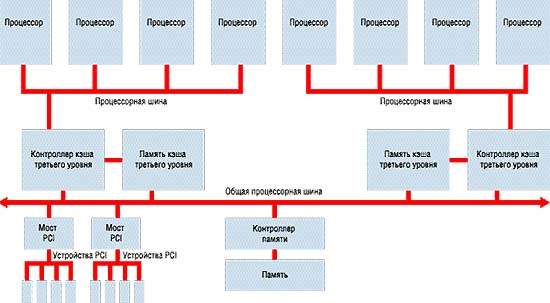 |
| РИСУНОК 2. Архитектура с иерархией шин |
Новый «союз шин»
В 1996 году компания Corollary, производитель решений для многопроцессорной обработки, разработала для 8-процессорных систем на базе процессоров Intel SMP-архитектуру, которая получила название Profusion. (В 1997 году Corollary приобрела корпорация Intel). И хотя новая технология была создана на базе шин, она существенно отличалась от традиционных решений такого рода. Profusion объединяет все подсистемы в матричную сеть, предоставляя каждой из них высокоскоростной и автономный доступ к совместно используемой памяти. Знатоки сетевых архитектур, несомненно, подметят, что точно такое же решение используется в коммутаторах межсоединений, которые обеспечивают коммутацию в высокоскоростных сетях.
Архитектура Profusion представлена на Рисунке 3. Ее центральный элемент — пятипортовый матричный переключатель, который в Intel называют набором микросхем Profusion (Profusion chipset). Собственно, этот матричный переключатель и формирует 8-процессорную SMP-систему, так как именно он объединяет в одно целое две процессорные шины, каждая из которых соединена c четырьмя процессорами, системную шину ввода/вывода и два банка памяти. Для обеспечения согласованности данных в наборе микросхем Profusion предусмотрено два кэша, осуществляющих фильтрацию обращений к памяти на когерентность. Рассмотрим архитектуру Profusion несколько подробнее.
 |
| РИСУНОК 3. Архитектура 4-процессорного SMP-сервера Profusion |
Системные шины, процессоры и мосты. Наряду с двумя процессорными шинами система Profusion включает в себя специализированную шину ввода/вывода, обеспечивающую ввод и вывод данных; эта шина повышает производительность и надежность системы. Специализированная шина ввода/вывода может непосредственно взаимодействовать с памятью, сводя к минимуму дополнительную нагрузку на процессор и число прерываний процессора. Кроме того, шина может изолировать процессоры от подсистем ввода/вывода при некорректном поведении последних; это, в свою очередь, снижает вероятность отказа системы.
Три шины системы Profusion могут работать с тактовой частотой 100 МГц или 133 МГц и обслуживают по пять компонентов системы каждая. Точнее говоря, каждая процессорная шина обслуживает четыре процессора и набор микросхем Profusion. Шина ввода-вывода обслуживает все четыре моста PCI и набор микросхем Profusion.
Этот набор микросхем совместим с двумя типами процессоров: с моделями Pentium II Xeon, имеющими тактовые частоты 400 МГц и 450 МГц, а также с процессорами Pentium III Xeon, имеющими тактовую частоту 500 МГц и выше и вторичный кэш емкостью до 2 Мбайт. Большинство поставщиков высококлассных серверов, скорее всего, будут использовать в своих изделиях процессоры Pentium III Xeon, ибо это дает возможность получать максимальную скорость, какую только можно «выжать» из архитектуры Profusion. Некоторые производители, в частности, Compaq, комплектуют свои 8-процессорные серверы 64-разрядными системными шинами и соответствующими новой спецификации PCI 2.1 64-разрядными шинами PCI с тактовой частотой 66 МГц для мостов PCI. Мосты PCI от этих производителей допускают «горячую замену»; иными словами, устанавливать и заменять устройства PCI можно не перезагружая систему. Допускается подключение до четырех устройств PCI к каждому мосту PCI.
Память. В системе Profusion предусмотрено два банка памяти. Они используют общее адресное пространство, а содержимое банков формируется по принципу чередования адресов по строкам кэша (cache-line interleaved). Это означает, что в одном банке содержатся четные строки кэша (с адресами 0, 2, 4 и т. д.), а в другом — нечетные (с адресами 1, 3, 5 и т. д.). Доступ к банкам памяти осуществляется в соответствии со спецификацией архитектуры UMA, то есть на равных правах. По теории вероятности при случайных обращениях половина из их общего числа должна приходиться на банк с четными адресами, а вторая половина — на банк с нечетными адресами. Таким образом, доступ к памяти осуществляется в два раза быстрее, нежели в конфигурациях с одним банком.
Емкость каждого из банков памяти Profusion (обычно это память типа SDRAM) может достигать 16 Гбайт, то есть емкость памяти сервера Profusion может составлять 32 Гбайт. Сервер Windows 2000 Datacenter Server, который будет обеспечивать адресуемую память емкостью 64 Гбайт, позволит в полной мере использовать преимущества, вытекающие из таких возможностей масштабирования. Однако следует отметить, что выпускаемые ныне модели серверов Profusion обычно не позволяют работать с памятью емкостью 32 Гбайт. Скажем, возможности расширения памяти Compaq ProLiant 8500 пока составляют 8 Гбайт. Поэтому до принятия решения о приобретении 8-процессорного сервера нужно внимательно ознакомиться с его характеристиками.
Фильтр когерентности кэша. В серверах SMP на базе процессоров Intel предусмотрено совместное использование данных процессорами и подсистемами ввода/вывода. При этом существует возможность того, что копии данных, имеющих идентичные адреса памяти и находящиеся в кэшах процессора и в памяти, потеряют согласованность. Это чревато ошибками в функционировании системы. Хорошо спроектированная SMP-система обеспечивает согласованное отображение содержимого памяти или, иначе говоря, когерентность данных. Если данные с идентичным адресом памяти поступают в кэш одного или нескольких процессоров, система должна синхронизировать кэшированные копии с соответствующими данными в памяти. Для обеспечения согласованности информации в процессорах Intel предусмотрено использование специального протокола, позволяющего отслеживать все адреса оперативной памяти, по которым происходило изменение данных. Когда процессорная шина обрабатывает транзакцию памяти, она опрашивает «свои» процессоры, а также процессоры-абоненты удаленных процессорных шинах, содержатся ли в их кэшах данные с идентичным адресом памяти. Если от одного или нескольких процессоров поступает положительный ответ, система синхронизирует кэшированные копии с данными в памяти и использует их новейшую версию. Однако надо иметь в виду, что на проверку адресов оперативной памяти расходуются дополнительные такты процессора. Кроме того, сокращается пропускная способность шины и возрастает интенсивность трафика между процессорными шинами.
Таким образом, операции по «прочесыванию» адресов оперативной памяти на удаленной процессорной шине следует свести к минимуму, и для этой цели в системе Profusion предусмотрено два фильтра когерентности кэша. Обратимся к Рисунку 3: фильтр когерентности кэша, изображенный слева, содержит адреса данных, которые находятся во вторичных кэшах процессоров левой же процессорной шины. Фильтр в правой части рисунка, соответственно, содержит адреса данных, хранимых во вторичных кэшах процессоров-абонентов правой процессорной шины. При совершении транзакции памяти соответствующая локальная процессорная шина должна определить, следует ли осуществлять согласование данных. Но приступая к выполнению этой задачи, она начинает не с анализа адресов удаленной процессорной шины, а с проверки удаленного фильтра когерентности кэша. Разбираться с адресами на своей удаленной «напарницы» локальная шина будет лишь в том случае, если обнаружит, что удаленный фильтр когерентности кэша содержит адрес, совпадающий с адресом данных, которые участвуют в транзакции памяти. В противном случае проверка ограничивается собственными «закромами» данной локальной шины. Некоторые изготовители называют фильтры когерентности кэша ускорителями кэша, поскольку применение этих фильтров позволяет повысить быстродействие.
Набор микросхем Profusion. Это микропроцессорный набор, представляющий собой пятипортовый матричный переключатель, является главным компонентом архитектуры Profusion. Как явствует из Рисунка 3, пять портов набора связаны друг с другом. Эти пять портов составляют два интерфейса процессорной шины, два интерфейса памяти и один интерфейс шины ввода/вывода. Все пять портов — двунаправленные: 10 однонаправленных портов в 64-разрядной статической памяти образуют 5 двунаправленных портов. Таким образом, между процессорными шинами, банками памяти и шиной ввода/вывода существует в общей сложности десять двунаправленных каналов [(5 портов х 4 канала на порт) + 2 направления]. Следовательно, между процессорными шинами, памятью и шиной ввода/вывода операции чтения и записи могут осуществляться параллельно, и это может разительно сократить задержку доступа. Теоретически скорость передачи данных по шине с тактовой частотой 100 МГц (минимальное быстродействие шины сервера Profusion) может достигать уровня 800 Мбит/с. При такой пропускной способности матричный переключатель Profusion может обеспечить максимальную пропускную способность 4 Гбит/с (800 Мбит/с х 5 портов).
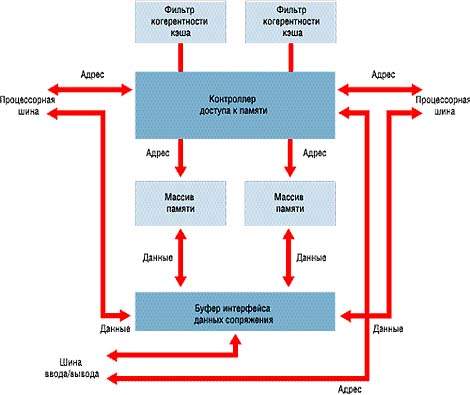 |
| РИСУНОК 4. Детальное строение набора микросхем Profusion |
Как показано на Рисунке 4, набор микросхем Profusion состоит из двух физических разделов, каждый из которых представляет собой специализированную интегральную схему: это контроллер доступа к памяти (memory access controller — MAC) и буфер информационного сопряжения (data interface buffer — DIB). Контроллер MAC осуществляет пересылку между процессорными шинами, шиной ввода/вывода и памятью данных по адресам и управляющей информации, а также управляет работой двух фильтров когерентности кэша. Буфер DIB аккумулирует и пересылает данные между шинами процессоров, шиной ввода/вывода и памятью.
Поясним принцип работы контроллера MAC и буфера DIB на простом примере. Допустим, процессору нужно извлечь данные, хранимые в памяти по адресу 100. По локальной процессорной шине процессор пересылает контроллеру MAC адрес «100» и управляющую информацию для чтения/записи. С помощью контроллера MAC локальная системная шина проверяет фильтр когерентности кэша удаленной процессорной шины. Цель проверки — выяснить, имеется ли копия хранимых по адресу «100» данных в каком-либо кэше процессора, подключенного к удаленной процессорной шине. Если проверка не дает положительных результатов, контроллер MAC направляет данный адрес и управляющую информацию для чтения банку памяти, содержащему четные строки кэша. Если же искомые данные все-таки содержатся в кэше одного из процессоров удаленной процессорной шины, локальная процессорная шина начинает отслеживание всех адресов оперативной памяти удаленной процессорной шины с тем, чтобы система обеспечила согласование копий данных в памяти и в кэше. После этого память возвращает данные в буфер DIB. Буфер выясняет, не занята ли локальная процессорная шина обработкой других запросов. Если в данный момент шина занята, данные остаются в буфере и передаются на локальную процессорную шину после ее высвобождения.
В новый век — с новой архитектурой
Итак, производители серверов могут воспользоваться и набором микросхем, и архитектурой Profusion для создания SMP-серверов нового поколения, которые можно будет оcнастить восемью процессорами Intel. Ведущие производители серверов уже сегодня поставляют 8-процессорные SMP-серверы на базе архитектуры Profusion, и вы уже можете выполнять на этих новых серверах с повышенным быстродействием требующие высокой производительности прикладные программы. Архитектура Profusion в сочетании с такими аппаратными средствами, как сервер Windows 2000 Advanced Server, оснащенный 8 процессорами и памятью емкостью 8 Гбайт, или Datacenter Server (32 процессора и 64 Гбайт памяти) позволит NT-приложениям уровня предприятия уже в 2000 году выйти на новые рубежи производительности и наращиваемости.