
Как это сделано в Microsoft SQL Server 2000 Analysis Services.
- Что же это собой представляет? - опасливо спросил Бейли.
- Это тессеракт. Его восемь кубов образуют стороны гиперкуба в четырех измерениях.
- А по-моему, это больше похоже на кошкину колыбельку - знаешь игру с веревочкой, надетой на пальцы...
Р. Хайнлайн,
"Дом, который построил Тил"
Кошкина колыбелька
Не секрет, что, несмотря на развитие тенденций, обуславливающих внедрение аналитических систем в российском бизнесе, многие IT-менеджеры до сих пор не имеют четкого представления о возможностях и назначении технологии OLAP (on-line analytical processing). Очень часто под бизнес-анализом понимают всего лишь статистическую обработку данных в табличных редакторах, и именно здесь, по-видимому, следует искать причины восприятия аналитических приложений как «игры с веревочкой» и сомнений относительно их масштабируемости до уровня предприятия. Действительно, если говорить о стандартной двухуровневой клиент-серверной модели, то возложение функций анализа на клиента вынуждает нас мириться с потерей корпоративной целостности данных и небольшими объемами анализируемой информации. Перенос же этих функций на реляционный сервер баз данных, во-первых, требует от аналитика профессиональных знаний в области IT, а во-вторых, как правило, нежелателен из-за весьма скудного набора возможностей вычислительного анализа в классическом SQL. Появление серверных продуктов OLAP позволило перекинуть мостик между этими двумя крайностями. OLAP-сервер обеспечивает целостное управление огромными объемами данных, мощную аналитику, быстрое время отклика и привычную для аналитика парадигму представления информации. Таким образом удается объединить преимущества обоих подходов, что делает OLAP-сервер центральным звеном в системе анализа данных на предприятии. В то же время OLAP, как и любой технологии, присущи свои особенности, которые лучше изучить заранее, до этапа практической реализации. В настоящей статье затрагиваются некоторые проблемы, возникающие при развертывании аналитических систем на предприятии, и намечаются способы их решения при помощи MS Analysis Services. Я намеренно опускаю подробности реализации разбираемых подходов, так как нет смысла дублировать содержание документации (Books Online) и MSDN. К тому же для практических целей важно не просто иметь представление о том, как задействовать ту или иную функцию, а понимать, для решения каких задач ее лучше всего использовать и каких результатов она позволяет достичь.
Краткий курс истории MS Analysis Services
Период с 1994 по 1997 гг. характеризовался значительным ростом рынка OLAP-средств, в первую очередь, за счет участия лидирующих производителей серверов баз данных. В октябре 1994 г. компания Sybase приобретает технологию bitwise-индексирования Expressway, впоследствии нашедшую отражение в SybaseIQ; в июне 1995 г. Oracle покупает OLAP-сервер Express у Information Resources Inc. (IRI); в октябре компания Informix (ныне сама купленная IBM в части бизнеса БД) приобретает Stanford Technology Group (STG) вместе с ее продуктом MetaCu-be; в январе 1997 г. IBM заключает с Arbor соглашение о лицензировании Essbase для своего DB2 OLAP-сервера. На рынке баз данных Microsoft в то время уступала своим могущественным конкурентам, так что известие о приобретении этой компанией разработок в области поддержки принятия решения фирмы Panorama Software Systems 29 октября 1996 г. (см.[1]) прошло практически незамеченным. Рынок OLAP казался уже установившимся и поделенным, что подтверждало и слияние двух крупнейших его участников Arbor Software и Hyperion Solutions в мае 1998 г. И вот в декабре того же года Microsoft выпускает седьмую версию сервера баз данных SQL Server, в состав которой впервые за долгую историю продукта вошли службы аналитической обработки OLAP Services (кодовое название Plato). Это было для всех неожиданностью. Появление нового опасного соперника, естественно, не могло вызвать прилива вдохновения у завзятых игроков. Еще за месяц до выхода SQL Server 7.0 Л. Эллисон (СЕО Oracle) объявил, что готов выплатить миллион долларов тому, кто докажет, что производительность продукта Microsoft на аналитических запросах превышает хотя бы на 1% производительность Oracle 8i. Забегая вперед, скажу, что в марте следующего года SQL Server 7.0 (а точнее, OLAP Services) продемонстрировал среднее время выполнения пресловутого Que-ry 5 серии 1.3.1 тестов TPC-D в 1,075 с (в случае Oracle этот результат равнялся 0,7 с, подробности тестирования отражены в [2]). Как выяснилось, конкуренты беспокоились не напрасно: Microsoft стремительно ворвалась в «плотно населенную» область OLAP-решений, заняв по итогам 1999 г. сразу пятое место - очень неплохой показатель для дебюта. К началу 2000 г. стало окончательно ясно, что это не сиюминутный успех, что на рынке OLAP Microsoft обосновалась надолго, и аналитики, в частности Gartner Group [3], оценили серьезность намерений компании, прогнозируя дальнейший рост доли OLAP Services for SQL Server (см. Рисунок 1). Как выяснилось, они не ошиблись. Недавние результаты исследования OLAP Report, приведенные в [4] (см. Рисунок 2), показывают, что в 2000 г. Microsoft поднялась уже на третье место.
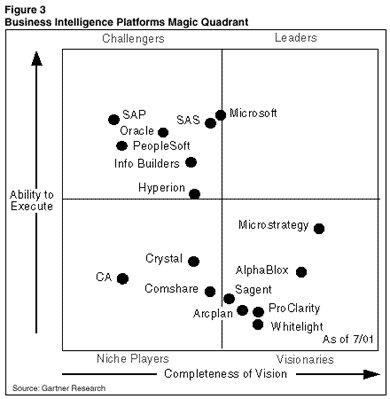
|
| Рисунок 1. «Магический квадрант» платформ бизнес-анализа. |
Выход в августе 2000 г. MS SQL Server 2000, аналитические службы которого были значительно усовершенствованы (кстати, теперь их официальное название - SQL Server 2000 Analysis Ser-vices), позволяет говорить о дальнейшем укреплении позиций Microsoft. В феврале 2001 г. был реализован один из крупнейших проектов в сфере хранилищ данных и многомерного анализа - Т3 (TeraCube) - см. [5]. В разработке проекта совместно с Microsoft приняли участие компании: Unisys, предоставившая 32-процессорный сервер e-@ction Enterprise Server ES7000; ЕМС, предоставившая подсистему хранения Symmetrix 3830 Enterprise Storage Sys-tem, и Knosys, предоставившая клиентские средства анализа ProClarity. В результате были построены хранилище объемом в 1,2 Тбайт и многомерный куб на его основе. В куб было погружено около 7,7 млрд записей (скорость загрузки составила чуть больше 40 тыс. записей в секунду). Тест производительности включал 1350 различных запросов от 50 пользователей, время отклика при этом составило 0,08 с при «холодном» кэше и 0,02 с при «разогретом». Полученные результаты позволяют дать примерную оценку возможностей использования Analysis Services в качестве центра аналитической обработки на крупном предприятии, а подробный обзор этих возможностей как раз и является предметом данной статьи.
Еще более краткое введение в OLAP
Я позволю себе очень беглый экскурс в основную терминологию OLAP для того, чтобы читатели, мало знакомые с предметом, имели представление о том, что это такое. Технологиям OLAP и хранилищ данных посвящено достаточное количество литературы (см., например, [6], [7]), поэтому я упомяну лишь те понятия, которые понадобятся нам в дальнейшем. Подобно математическому анализу, OLAP оперирует функциями в многомерном пространстве. Например, изучается динамика объемов продаж в зависимости от времени, расположения торговых центров, категории продуктов и т. д. Координатные оси называются измерениями, значения функции - мерой или фактом. Это можно себе представить в виде n-мерного куба, по одному ребру которого отложены, допустим, дни, по второму - города, по третьему - наименования продуктов и т. д., а в ячейках на пересечении - цифры продаж за конкретный день, по данному городу, для того или иного продукта и т. д. Подобная форма представления очень удобна для задач отчетности, так как сечение куба плоскостью параллельно одной из двухмерных граней немедленно дает нам фактически готовый отчет по динамике продаж, допустим, выбранного продукта в зависимости от времени и географии. Затем можно подать эту картину на вход алгоритма поиска закономерностей или, в простейшем случае, построить график и очень быстро определить региональные предпочтения потребителей, характерны ли сезонные колебания и т. д. Если взять срез по клиентам и продуктам, можно отыскать группы сопутствующих товаров и другие зависимости, обычно неочевидные в традиционной нормализованной форме представления.
Дело в том, что традиционная структура реляционной базы данных, отвечающая многочисленным правилам нормализации, оптимизирована для задач учета, а не анализа. Учет и накопление данных (так называемые on-line transactional processing, OLTP-приложения) характеризуются короткими обновляющими транзакциями, «задевающими» относительно небольшое число таблиц. Напротив, аналитические запросы - это запросы, в основном, на чтение, причем в нем участвуют практически все таблицы. Понятно, что в процессе чтения некоторые из OLTP-транзакций будут вынуждены ждать, чтобы заблокировать нужные данные на обновление. Отсюда следует, что приложениям OLTP и OLAP очень трудно ужиться в одной базе как в силу разницы в форме логического представления информации, так и в силу природы запросов. Поэтому для анализа данных необходимо отдельное хранилище (data warehouse). Как правило, оно имеет существенно больший объем, нежели транзакционная база данных. Например, для регистрации продаж и оперативных задач вполне достаточно держать в OLTP-базе только данные за текущий год, тогда как комплексный анализ требует наличия информации и за прошлый год, и за позапрошлый, и вообще за всю историю существования корпорации. Кроме того, хранилище может вмещать данные из нескольких транзакционных систем, одна из которых, например, отслеживает продажи, другая ведет складской учет, третья - кадры и т. д. По соображениям согласованности, обновления информации в хранилище напрямую не допускаются (исключения возможны, но о них позже), ибо источником новых данных являются транзакционные системы, следовательно, хранилище может пополняться данными из операционных источников и затем использоваться только для чтения (здесь тоже возможны исключения, но и о них позже). В SQL Server для очистки, унификации и погружения данных в хранилище предназначены службы преобразования данных (Data Trans-formation Services, DTS).
Проектирование структуры агрегатов
Обычно аналитика не интересуют детальные данные, которые изначально содержатся в операционных источниках и оттуда попадают в хранилище. Скажем, если наше транзакционное приложение ведет учет продаж с точностью до секунд, то едва ли такая степень детализации реально потребуется для задач анализа. Конечно, можно на этапе погружения с помощью тех же DTS «переагрегировать» секунды в дни и класть в хранилище цифры дневных продаж, но что если аналитика заинтересуют недели, месяцы и т. д.? Поэтому измерение обычно представляет собой не плоскую одноуровневую структуру, а иерархию. Например, на самом нижнем (детальном, или «листовом») уровне хранятся адреса торговых центров. Уровнем выше расположены города, так что «детьми» каждого города являются расположенные в нем торговые центры. Города, в свою очередь, объединяются в регионы и т. д. В зависимости от задачи, на одном измерении может определяться несколько иерархий, например, если для отдела кадров требуются цифры в разрезе «год - неделя - день», для отдела продаж - «год - квартал - месяц - день» и т. д. Факты, соответствующие узлам дерева иерархии (например, продажи всех категорий продуктов за 1998 г. по России, продажи серверных продуктов за все время по всему миру и т. д.), называются агрегатами. Существенный выигрыш в производительности аналитических запросов, который дают OLAP-серверы, определяется не только оптимизированной схемой представления и/или форматом хранения данных, но и тем, что агрегаты не пересчитываются заново при каждом новом запросе, а хранятся уже посчитанными вместе с детальными данными. Как правило, расчет агрегатов происходит на этапе погружения данных. Таким образом, в аббревиатуре OLAP сокрыт некоторый обман - по крайней мере, часть обработки происходит в off-line (конечно, если только речь не идет об OLAP реального времени).
К сожалению, здесь вступает в силу закон сохранения пространства/времени, и, выигрывая во времени обработки запросов, мы вынуждены поступиться местом на диске. Дело в том, что, как легко показать (проделайте это для квадрата и куба, далее - по индукции), количество агрегатов увеличивается в степени n-1, где n - число измерений. Это, естественно, не лучшим образом сказывается на размере базы. Данную проблему в теории хранилищ обозначают как «взрывной рост данных». Итак, краевые условия понятны: либо считать все агрегаты и смотреть, как катастрофически уменьшается свободное место в дисковом массиве, либо не считать ничего, и тогда OLAP, как таковой, принесет нам мало радости. В MS Analysis Services предусмотрены эффективные методы борьбы с взрывным ростом. На стадии построения куба администратор задает размер дискового пространства, которым он готов пожертвовать под агрегаты, или процентный выигрыш в производительности, который он желает получить. После чего эвристический алгоритм мастера Design Storage определяет минимальный набор агрегатов, обеспечивающих наибольшую производительность при заданных ограничениях. Если не вдаваться в подробности реализации, то суть алгоритма очень проста: он выбирает те агрегаты, от которых за минимальное число операций производятся остальные. Однако, какой бы изощренной эвристика ни была, она остается только эвристикой. Поэтому в ходе работы с кубом Analysis Services протоколируют информацию о поступающих запросах: имя куба, имя пользователя, время начала выполнения, длительность, какие потребовались агрегаты и т. д. По умолчанию, сохраняется статистика по одному из 10 запросов (этот параметр можно менять в настройках сервера). После того как куб проработал некоторое время на практических задачах и в журнале накопилась достаточная статистика обращений, администратор может перестроить структуру агрегатов при помощи мастера Usage-Based Optimization, и тот адаптирует ее под реальную рабочую нагрузку.
Более тонкую настройку агрегатов можно выполнить для каждого измерения в отдельности средствами Decision Support Objects (DSO). Интерфейсы DSO играют в Analysis Services примерно ту же роль, что и SQL-DMO в реляционном SQL Server - они определяют объектную модель многомерного сервера и позволяют автоматизировать выполнение задач администрирования с помощью любого программного инструмента, поддерживающего работу с СОМ-объектами. В свойстве AggregationUsage указывается, должны ли быть посчитаны агрегаты только самого верхнего уровня, либо только для самого детального, либо для того и другого вместе. Выбор dimAggUsage
Standard означает, что для данного измерения необходимые агрегаты определяют вышеупомянутые алгоритмы. Наконец, dimAggUsageCustom позволяет установить, будет ли агрегироваться каждый отдельный уровень данного измерения (свойство Enab-leAggregations объекта «Уровень»).
Выбор архитектуры хранения
Существует два наиболее распространенных подхода к хранению аналитической информации. Можно промоделировать куб средствами старой доброй реляционной базы данных, в которой таблицы измерений (соответствуют реперу куба) связаны с центральной таблицей фактов («начинкой» куба) отношениями «один ко многим». Из-за внешнего сходства такая псевдомногомерная схема получила название звездной. Если измерение состоит не из одной, а из нескольких связанных таблиц, она превращается в «снежинку», хотя суть дела от этого не меняется, и «снежинку» можно привести к «звездочке» путем соответствующей денормализации таблиц измерений. Агрегаты также хранятся внутри реляционной базы данных. Под них создаются специальные таблицы или индексированные (материализованные) представления. Этот подход получил название реляционного OLAP - ROLAP. В нем, как мы видим, OLAP-сервер, по сути, хранит только метаданные куба и преобразует аналитические запросы в стандартный SQL-запрос к реляционной БД. Второй способ идет дальше. Он предполагает наличие у OLAP-сервера собственного, отличного от реляционного, механизма хранения, изначально ориентированного на навигацию по многомерным структурам и иерархиям. С его помощью над реляционным хранилищем строится куб, в который переносятся детальные данные, и в нем же рассчитываются и хранятся агрегаты. Такой подход получил название MOLAP (многомерный OLAP).
Каждый способ имеет свои сильные и слабые стороны. Чтобы отчетливо их себе представлять, рассмотрим, что происходит, когда аналитический запрос отправляется на MS Analysis Services. Сначала проверяется возможность выполнения этого запроса исходя из той информации, которая накоплена в клиентском кэше MS PivotTable Service. Если ее недостаточно, клиентская часть обращается за недостающими данными к серверу. Тот, в свою очередь, ищет их в собственном кэше. Если их там также не оказывается, сервер пытается удовлетворить запрос исходя из заранее посчитанных и хранящихся вместе с кубом агрегатов. Если этого сделать нельзя, он определяет, какие еще агрегаты нужно досчитать, и вычисляет их. Наконец, в случае, если запросу требуются детальные данные, сервер осуществляет погружение в детали. Таким образом, архитектура MOLAP обеспечивает:
- наибольшую автономность, так как вся необходимая для запроса информация по определению содержится внутри многомерной структуры, т. е. она является самодостаточной;
- производительность, так как, в отличие от реляционной, эта структура хранения создавалась специально для аналитических запросов и была под них соответствующим образом оптимизирована.
В случае ROLAP производительность в целом будет, очевидно, хуже, поскольку и за деталями, и за агрегатами OLAP-сервер вынужден обращаться к операционному источнику, что требует дополнительных накладных расходов на слой OLE DB (и сетевое взаимодействие, если аналитический и реляционный серверы расположены на разных машинах). В то же время ROLAP более экономичен, так как, оставаясь в рамках привычных реляционных технологий хранения, он позволяет предприятию в значительной мере обойтись средствами, вложенными во внедрение этих технологий и обучение специалистов. Кроме того, не будем забывать о том, что MOLAP, по сути, хранит копию детальных данных - неизбежная плата за его самодостаточность. Несмотря на то что в этой архитектуре предусмотрены эффективные средства сжатия данных (сравните, например, исходный объем хранилища и размер куба на его основе в случае TeraCube), перенос деталей в многомерный формат, так или иначе, предполагает дополнительное расходование дискового пространства. В известном смысле компромиссом между этими двумя подходами является гибридный OLAP (HOLAP), когда детальные данные остаются в реляционной базе данных, а агрегаты хранятся в многомерном кубе, размер которого в этом случае составит только часть от «чистого» MOLAP. По производительности данная архитектура также занимает промежуточное положение, поскольку обращение к реляционной информации здесь происходит только в том случае, когда запросу требуются детальные данные, что для подавляющего большинства аналитических запросов скорее исключение, чем правило.
Возникает вопрос: какой из перечисленных факторов (построение структуры агрегатов, выбор архитектуры хранения) оказывает наиболее существенное влияние на рост производительности? Иными словами, что выгоднее: куб ROLAP с 80% от общего числа агрегатов или MOLAP с 20%? К сожалению, однозначно ответить на такой вопрос очень сложно, так как это зависит от специфики конкретного приложения, типового набора запросов и других факторов. В связи с этим довольно любопытным представляется исследование, проведенное сотрудниками Unisys при решении практической задачи из области банковской аналитики. С его результатами можно ознакомиться в статье [8].
Выбор способа хранения возможен не только для кубов, но и для измерений. В предыдущей версии поддерживались только MOLAP-измерения, которые хранятся в многомерной структуре на OLAP-сервере, создаваемой в момент обработки измерения. Все MOLAP-измерения для всех баз данных подгружаются в память при старте сервера. Это обеспечивает наибольшую производительность, но накладывает ограничения на размер MOLAP-измерений, так как максимальная память, адресуемая msmdsrv в стандартной версии SQL Server, составляет 2 Гбайт. Примерно оценить размер памяти, необходимой для загрузки измерений, можно с помощью команды dir *.dim /s, причем необходимо учесть, что для их обработки сервер привлекает дополнительную память. В случае Windows NT 4.0 после обработки больших MOLAP-измерений нелишним может оказаться перезапуск службы, что позволит избавиться от фрагментированности памяти. Можно также уменьшить величину параметра Process Buffer Size в установках сервера (не ниже 4 Мбайт). В SQL Server 2000 Enterprise Edition, который «умеет» адресовать 4 Гбайт на Windows 2000 Server, 8 Гбайт на Windows 2000 Advanced Server и 64 Гбайт на Windows 2000 DataCenter, эти ограничения в значительной мере ослаблены. Тем не менее даже в таком случае хранить в MOLAP-измерении свыше 5-10 млн членов непрактично. Для работы с измерениями, чей размер превышает эти пределы, в SQL Server 2000 Enterprise Edition была введена поддержка реляционного формата хранения измерений. Тип хранения задается в свойствах измерения (Storage Mode). Как и в случае с кубами, ROLAP-измерения содержатся в таблицах реляционного хранилища. Для однозначной идентификации членов ROLAP-измерения свойство Member Keys Unique должно иметь значение True. Кроме того, всякое ROLAP-измерение по определению является изменяющимся (changing) - о чем подробнее рассказано дальше. ROLAP-измерения возможны только в кубах, чей формат хранения также ROLAP. Нельзя использовать ROLAP-измерения с MOLAP- или HOLAP-кубами.
Разделы куба
Существует два подхода к повышению производительности с точки зрения распределенности и параллельной обработки. Первый касается исключительно реляционной стороны вопроса и не имеет прямого отношения к Analysis Services. Например, единую таблицу фактов можно распределить по нескольким серверам, применяя технологии той СУБД, которая используется в качестве операционного источника. Так, в роли таблицы фактов куба может выступать распределенное секционированное представление (distributed partitioned view), объединяющее фрагментированные по тому или иному признаку таблицы, хранящиеся на разных машинах SQL Server. Если операционным источником является Oracle, можно рассмотреть вариант использования Parallel Server и т. д. Поскольку этот вопрос не имеет прямого отношения к Analysis Services, подробно рассматривать его мы здесь не будем.
Второй подход предполагает разбиение собственно многомерного куба при помощи разделов. Разделы (partitions) можно представить себе в виде непересекающихся областей единого куба. В Analysis Services каждый куб состоит хотя бы из одного раздела, по умолчанию совпадающего с самим кубом. Максимальное число разделов теоретически неограниченно. При определении нового раздела наиболее существенными свойствами являются фильтр и срез. Фильтр эквивалентен условию WHERE в операторе SQL над таблицей фактов и таблицами измерений реляционного хранилища, который описывает относящиеся к этому разделу данные. Срез можно уподобить ограничению CHECK в реляционной терминологии. Он помогает оптимизатору Analysis Services определить, в каком разделе или разделах находятся данные, необходимые для выполнения многомерного запроса, чтобы правильно разбить его на подзапросы к соответствующим разделам. Все разделы наследуют структуру родительского объекта, т. е. они обязаны иметь тот же набор измерений и мер, что и куб, который они составляют. В то же время каждый раздел может иметь собственную таблицу фактов, набор агрегатов и формат хранения. Если таблицы фактов для разных разделов пересекаются, т. е. частично содержат общие данные, пересечения необходимо исключить, правильно выбрав фильтры для каждого из разделов, поскольку появление повторяющейся информации в разделах приведет к заведомо неправильному вычислению агрегатов и дублированию результатов. Один раздел можно добавлять (merge) к другому при условии, что они принадлежат одному и тому же кубу. Перед слиянием добавляемый раздел необходимо привести к формату хранения целевого раздела, а, кроме того, он должен иметь ту же структуру агрегатов (для чего используется Copy Design Structure), что и целевой раздел. Условие фильтрации результирующего раздела получается как дизъюнкция фильтров объединяемых разделов. Если разделы имеют разные таблицы фактов, то автоматического слияния таблиц при объединении разделов не происходит. В качестве таблицы фактов результирующего раздела будет выбрана таблица целевого раздела. Слияние таблиц в операционном источнике должно выполняться администратором само-стоятельно.
Использование разделов позволяет существенно повысить гибкость масштабирования аналитического решения за счет оптимального сочетания производительности и затрат на хранение. Обычно куб разделяют по географическому или временному признаку. Например, куб может состоять из трех разделов, один из которых соответствует текущему году, второй - прошлому, и третий - всей остальной истории предприятия. Допустим, аналитические запросы чаще всего затрагивают информацию текущего года, реже - прошлого, и совсем редко - историческую информацию. Тогда, учитывая плюсы и минусы каждой из архитектур, разобранные выше, следует хранить первый раздел как MOLAP, второй - как HOLAP и третий - как ROLAP. По прошествии года второй раздел преобразовывается в ROLAP и добавляется в архив, первый раздел преобразуется в HOLAP, а под новый год создается новый MOLAP-раздел.
Для распределения куба по нескольким SQL Server используются удаленные (remote) разделы. Данные удаленного раздела физически хранятся на сервере, отличном от того, на котором определен родительский куб, содержащий метаданные этого раздела. OLAP-сервер, на котором хранится определение удаленного раздела, будем называть точкой входа, так как именно ему адресованы аналитические запросы пользователей. Под ресурсным будем понимать OLAP-сервер, содержащий данные удаленного раздела. Если раздел имеет формат MOLAP, данные будут включать детальные данные и агрегаты, если HOLAP - только агрегаты. Точка входа сама может никаких данных не хранить, она играет роль диспетчера. Поступивший на нее запрос разбивается на части, которые перенаправляются к соответствующим ресурсным серверам. Точка входа «знает», где находятся нужные данные, поскольку она владеет метаданными о срезах разделов. Каждый из ресурсных серверов обрабатывает свою часть запроса и отсылает результаты точке входа, где они объединяются и возвращаются клиенту. Процессинг куба происходит и в параллельном режиме. Администрирование удаленного раздела допускается только с точки входа, при этом необходимо иметь в виду, что данные удаленного раздела при создании резервной копии базы данных не архивируются. Слияние удаленных разделов возможно только с другими удаленными разделами данного куба, хранящимися на том же ресурсном сервере. В роли ресурсного сервера может выступать Analysis Services 2000, но не OLAP Services в составе SQL Server 7.0.
В отличие от удаленных разделов прилинкованные кубы (linked cubes) в меньшей степени нацелены на решение задач масштабируемости, поскольку в этом случае как данные, так и определения хранятся на удаленном сервере, а точка входа выступает, по сути, только в роли ссылки. Поэтому прилинкованные кубы могут рассматриваться в качестве средства упрощения доступа, т. е. приближения многомерных данных к потребителю без необходимости создания их копии (что приводит к уменьшению затрат на хранение), а также защиты данных с точки зрения сокрытия их местонахождения. Доступ к прилинкованному кубу происходит прозрачно для пользователя, как если бы куб находился на точке входа. Поскольку в SQL Server 2000 возможен доступ к кубу по HTTP, ресурсный сервер может располагаться за брандмауэром или proxy-сервером. При этом сам ресурс не обязательно должен находиться под управлением MS Analysis Services. Достаточно, чтобы с ним можно было установить соединение при помощи любого многомерного OLE DB-провайдера. Создание прилинкованных кубов поддерживается только в SQL Server 2000 Enterprise Edition.
Алексей Шуленин - системный инженер отдела бизнес-приложений российского представительства Microsoft. Имеет сертификаты MCSE, MCDBA, MSS, MCSD. С ним можно связаться по адресу: rusdev@microsoft.com.
Ссылки и библиография
- Microsoft Announces Acquisition Of Panorama Online Analytical Processing (OLAP) Technology. http://www.microsoft.com/ PressPass/ press/ 1996/ Oct96/ pan2pr.asp
- Microsoft Demonstrates Performance and Value Advantages of SQL Server 7.0 Enterprise Edition for Terabyte-Scale Business Problems. http://www.micro-soft.com/ PressPass/ press/ 1999/ Mar99/SQLEntpr.asp
- Gartner's Intranets & Electronic Workplace Research Note COM-10-0657, 2 March 2000. http://www.gartner.com/ webletter/ microsoft/ article3/ article3.html
- OLAP Report. Market Share Analysis. http://www.olapreport.com/Market.htm
- Enterprise-Scale Business Intelligence. http://www.microsoft.com/ sql/ techinfo/ BI/ terabytecube.asp
- Barquin R.C., Edelstein H.A. Planning and Designing the Data Warehouse. Prentice Hall, 1996, ISBN: 0132557460
- Thomsen E. OLAP Solutions: Building Multidimensional Information Systems. Wiley, 1997, ISBN: 0471149314
- Tewari S. Optimizing Cube Performance with OLAP Services. SQL Server Magazine, September 2000 http://www.sqlmag.com/ Articles/ Index.cfm?ArticleID=9140.