
[Примечание автора: весьма вероятно, что читатели имеют представление главным образом о базовых понятиях проекта для транзакционной базы данных. В этом месяце я хочу сделать акцент на основах проектов для хранилищ данных и сохранении в них данных. В следующих статьях мы рассмотрим такие темы как конкретный проект таблицы размерностей, проект таблиц фактов, проект разбиения таблицы фактов, проект итоговой таблицы и проект медленно меняющихся размерностей. Кроме того, я расскажу о методах индексирования, которые оптимизированы для использования с хранилищами данных и разделенных таблиц, и о том, как формировать технические требования для проекта хранилища данных, которые могут отличаться от требований, предъявляемых при проектировании транзакционной базы данных.]
Хранилище данных - это одна из фундаментальных структур решений бизнес-аналитики (далее BI). Аналогично транзакционной базе данных, хранилищу данных требуется проект схемы. Основная схема для хранилища данных - это схема «звезда». Если для работы BI нужно создать многомерный куб, лучше всего для хранилища данных применять именно эту схему. Далее в статье я объясню, почему схема «звезда» предпочтительнее остальных и почему я использую пример схемы «звезда» для иллюстрации преимуществ этого проекта. Подробнее о BI и хранилищах данных рассказано в статье «Хранилища данных: фундамент BI».
Существует несколько причин использовать схему «звезда», а не традиционный проект нормализованной базы данных. Прежде всего, нужно задействовать схему «звезда», если необходимо создавать и использовать кубы OLAP. Размерности куба - это оси анализа (например, по временному периоду, по линии продуктов, региону).
И, возможно, более значимая причина: схема «звезда» обеспечивает высокое быстродействие, когда реализовывается в виде куба OLAP.
Еще одна причина применения схемы «звезда» для хранилища базы данных заключается в том, что схема «звезда» похожа на наш способ восприятия и использования данных. Никто, кроме разработчиков модели данных, администраторов базы данных и некоторых программистов базы данных и не думает структурировать данные методами, применяемыми в транзакционной базе данных. Схема «звезда», реализованная как куб OLAP, позволяет и разработчикам, и конечным пользователям без труда управлять метаданными. Дополнительно можно модифицировать и развивать схему «звезда», по мере роста потребности в BI на предприятии. В отличие от обычной транзакционной схемы базы данных, не нужно беспокоиться о хранении ключевых атрибутов только в одном месте. И последнее, но не менее важное - схема «звезда» расширяет выбор инструментов для внешнего интерфейса BI, потому что лишь некоторые инструменты подходят для доступа к кубам OLAP.
На Рисунке 1 показан образец схемы «звезда», это модель с примером хранилища данных Adventure Works DW, который поставляется с SQL Server 2005. Особенность схемы - одна таблица с данными Reseller Sales. Данные таблицы - это совокупность ключей и показателей. Ключи связывают каждую строку таблицы данных с ассоциированной строкой в таблице размерностей. Как и в схеме транзакционной базы данных, первичный ключ таблицы размерностей Product становится внешним ключом в таблице данных Reseller_ Sales. Измерения (практически любое поле, кроме ключевого) - это рабочие данные, хорошо упакованные и готовые для анализа.
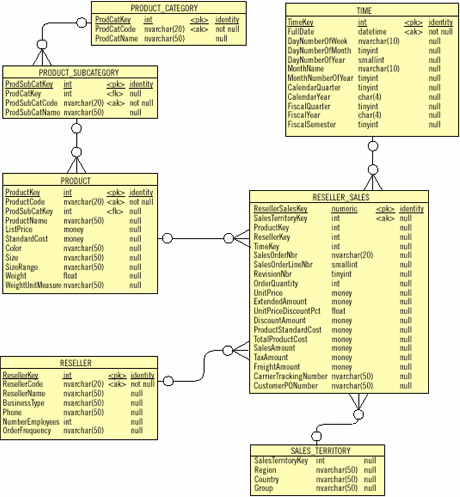
Пример схемы «звезда» на Рисунке 1 подразумевает поддержку принятия решений и программного инструментария BI. Если реализовать эту схему, ее можно заполнить из соизмеримых таблиц и полей в транзакционной версии базы данных AdventureWorks.
Размерности схемы (то есть Time, Product, Reseller и Sales_Territory) могут быть отображены в таблицах или представлениях базы данных AdventureWorks, которая облегчает перенос рабочих данных в хранилище данных, и в конечном счете в куб Reseller_Sales. Каждая размерность - это ось для исследования в кубе, построенная так, чтобы можно было анализировать данные по месяцам, по регионам или типу бизнеса.
Обратите внимание на простую иерархию размерности в этой схеме: из Product_Category в Product_Subcategory далее в Product. Данная структура уменьшает избыточность и превращает схему «звезда» в схему «снежинка», хотя в этом случае неравномерная схема предпочтительнее. Можно добавлять столько размеров, сколько необходимо для схемы «звезда/снежинка». Можно также осуществить более сложную структуру, такую как географическое измерение, которое будет родителем для Reseller и для Sales_Territory. Мы рассмотрим это, когда речь пойдет о модели размерности таблицы.
Проект схемы «звезда», который показан на Рисунке 1, имеет несколько известных характеристик:
- Каждая таблица в «звездной» схеме имеет индивидуальный первичный ключ, который устраняет противоречие между естественными первичными ключами и суррогатными первичными ключами. В хранилище базы данных назначение первичного ключа происходит как суррогатное; если есть натуральный ключ, который нужно сохранить для запросов, он определяется как альтернативный ключ.
- Большинство полей как в таблицах измерений (с метаданными), так и в таблицах с данными, пустые. Только первичные и дополнительные ключи обязательны для заполнения, и лишь первичный ключ уникален. Необходимо иметь в виду, что данные будут загружены в эту структуру хранилища данных из различных источников, в том числе от многократных версий операционных баз данных. Тем не менее, ограничения, которые пользователь обычно применяет для прописывания бизнес-правил в транзакционной базе данных, в хранилище данных должны быть смягчены. Большинство полей должно иметь возможность быть nullable или оставаться незаполненными, потому что для этих полей не будет данных.
- Взаимосвязи на родительской стороне необязательны (то есть zero-to-one к zero-to-many). Если нет никакого контроля ссылочной целостности исходных данных, нужно учитывать «осиротевшие» записи в таблице фактов и на более низких уровнях иерархии размерностей.
- Большинство полей в таблице фактов (например, величины) числовые. Таблица фактов есть цель исследований BI, и аналитикам BI требуются числа и факты.
- Избыточность данных растет по всей схеме. Эта избыточность необходима для хранилища данных, чтобы добиться приемлемого уровня производительности. Количество данных в хранилище данных обычно огромно по сравнению с количеством данных в транзакционной базе данных. При написании запросов на языке T-SQL для работы с хранилищем данных со схемой «звезда» избыточность минимизирует число связей, необходимых для возврата данных, при этом производительность намного лучше, чем если бы тот же самый запрос был выполнен в исходной транзакционной базе данных
Модель схемы для хранилища данных не должна сильно отличаться от модели схемы для обычной транзакционной базы данных. Поскольку хранилище данных - это исторический архив, можно поддерживать некоторое подобие состояния нормализации в проекте схемы для хранилища данных. Кроме того, можно создавать итоговые таблицы или столбцы, и, конечно, желательно к индивидуальным записям из реляционных таблиц хранилища данных добавить временную метку и уникальное значение. Выгода от хранения реляционных или почти реляционных хранилищ данных будет заключаться в том, что хранилище является готовой, доступной базой данных для генерации отчетов, в которой можно использовать для запросов обычный T-SQL. Без необходимости обучения программированию и без специально настроенных инструментов хранилище данных позволяет получить непосредственный эффект от вложенных инвестиций.