
Одной из важных составляющих современных операционных систем являются дисковые файловые системы. В общем случае каждая из них разработана с учетом специфики применения. Ярким примером может служить файловая система XFS от Silicon Graphics. Однако, за некоторыми исключениями в виде той же XFS, большинство файловых систем общего назначения стремятся обеспечить не только быстродействие. Немаловажным показателем является устойчивость файловой системы к сбоям. В этом контексте имеется в виду обеспечение согласованности данных в случае непредвиденных сбоев в работе аппаратного обеспечения, например в результате сбоя питания.
Для того чтобы обеспечить подобную устойчивость, разработчики файловых систем обратились к механизмам, применяющимся в современных системах управления базами данных. Основные идеи улучшений были почерпнуты именно из этой области и в той или иной мере применены к существующим файловым системам с учетом того, что файловая система — все-таки не база данных. Справедливости ради стоит заметить, что это не первое удачное заимствование механизмов управления базой данных в файловые системы. К примеру, механизмы, применяемые при построении индексов базы данных, сегодня с успехом применяются и в файловых системах для организации деревьев каталогов и быстрой навигации по ним.
Одним из первых заимствований из области баз данных в область обеспечения отказоустойчивости стали журналы транзакций. Здесь стоит оговориться. То, что называется транзакциями почти во всех современных файловых системах общего назначения, не стоит считать транзакциями в полной мере. Они не соответствуют общим требованиям к транзакциям. Например, их нельзя отменить. Однако, с другой стороны, транзакции файловых систем работают аналогично транзакциям базы данных. Иначе говоря, если происходят какие-то изменения в файловой системе, то сначала они фиксируются в журнале транзакций в синхронном режиме. Если между фиксацией транзакции в журнале и записью в файловую систему произойдет сбой, состояние файловой системы можно будет восстановить по содержимому журнала.
Основными свойствами транзакции являются:
-
атомарность (Atomicity): изменения, производимые в рамках транзакции, являются одним целым. Они либо происходят все, либо не происходит ни одно из них, и данные остаются в том состоянии, в котором были до начала транзакции;
-
непротиворечивость (Consistency): данные по окончании транзакции должны подчиняться правилам, заданным для набора данных, к которым эта транзакция применяется. Например, не может появиться два одинаковых значения для поля, содержимое которого должно быть уникально;
-
изоляция (Isolation): транзакции не должны влиять друг на друга в процессе выполнения;
-
долговечность (Durability): независимо от внешних факторов, выполненная транзакция сохраняется, и ничто не может вернуть систему в состояние до начала транзакции.
Журналирующие файловые системы
Почти все файловые системы современных операционных систем общего назначения, таких как Windows или Linux, имеют журналирующую файловую систему в качестве основной. Их можно условно разделить на две категории:
-
журналирование метаданных — в журнале сохраняется информация о факте произошедших изменений;
-
полное журналирование — журнал содержит не только факт изменений, а еще и данные, с которыми были произведены изменения.
В первом случае журналирование не обеспечивает отказоустойчивости данных. Его основной задачей является обеспечение непротиворечивости метаданных файловой системы, а также повышение скорости проверки структуры файловой системы при старте операционной системы. К примеру, если вы переносите файл из каталога в каталог и происходит сбой, может случиться так, что файловая система будет иметь записи о новом и старом файлах. Мало того, если при этом должно было пройти копирование содержимого исходного файла в новый файл, но оно не произошло, попытка обратиться к новому файлу может привести к неожиданным последствиям. Кроме того, в NTFS журналирование может использоваться для быстрого отслеживания изменений в файлах для тех или иных целей. Такой метод мониторинга изменений используется для работы распределенной файловой системы DFS, репликации политик каталога Active Directory и работы различных приложений резервного копирования. Кроме того, метаданные можно использовать в качестве истории произошедших изменений, например для того, чтобы выявить различные санкционированные и несанкционированные действия с вашими файлами. Как же все-таки выглядят такого вида журналы в разных операционных системах?
В операционной системе Windows начиная с Windows 2000 используется файловая система NTFS версии 5, которая поддерживает журналирование метаданных. В клиентских версиях операционных систем ведение журнала по умолчанию отключено.
Если журнал активен, то каждый раз, когда на томе происходят изменения, файловая система добавляет запись в журнал изменений NTFS. Журнал представляет собой специальный системный файл метаданных$Extend$UsnJrnl. Данные журнала хранятся в потоке $J. Этот файл является разреженным файлом NTFS, поэтому он никогда не переполняется. Он имеется на каждом разделе диска, на котором активен журнал. Каждая запись идентифицируется значением номера последовательных изменений Update Sequence Number (USN) и добавляется в конец журнала. Записи не хранятся вечно. Система удаляет устаревшие записи журнала в случае, если его размер в два раза превышает заданный максимальный размер. Кроме того, NTFS поддерживает значение LastUSN для каждой записи в таблице MFT. Таким образом, даже в том случае, когда записи об изменении файла или папки были удалены из журнала, по наличию этого значения можно судить о том, что файл или папка были изменены. Однако необходимо помнить, что при отключении журналирования файл журнала удаляется вместе со всеми записями. Cистема при этом сбрасывает значение LastUSN каждой записи в MFT в ноль, т. е. операция удаления журнала — сравнительно продолжительная по времени.
Журнал изменений
Рассмотрим вкратце, как устроен этот журнал Windows. Структура записи журнала представлена в листинге 1. Наиболее важными, с точки зрения администратора, полями являются:

-
FileName. Это имя файла или каталога, с которым произошли изменения. К сожалению, это только имя. Путь в этом поле не хранится. Кроме того, в дополнение к этому полю в структуре предусмотрены еще вспомогательные поля FileNameLength и FileNameOffset, которые определяют длину имени и смещение поля с именем относительно начала структуры. Microsoft рекомендует работать с именами файлов в этой структуре, не рассчитывая на то, что имя оканчивается нулем, но используя значения смещения и длины строки. Таким образом обеспечивается совместимость с последующими версиями.
-
FileReferenceNumber. Поле, в котором содержится уникальное значение, идентифицирующее файл. Каждый файл или папка в системе имеют такой идентификатор. Идентификатор раздела и идентификатор файла уникально идентифицируют любой файл на компьютере. По открытым файловым описателям можно узнать, указывают ли они на один и тот же файл. Для этого нужно просто получить эти значения из описателя при помощи функции GetFileInformationByHandle и сравнить соответствующие значения. Если они равны, значит, описатели указывают на один и тот же файл.
-
ParentFileReferenceNumber. В этом поле содержится идентификатор контейнера записи, т. е. если запись описывает файл, то в этом поле будет содержаться идентификатор каталога, в котором он лежит. Это же верно и для папки. Для того чтобы получить полный путь до этого файла, необходимо пройти по дереву идентификаторов до самого корня, которым является идентификатор раздела, и получить имена каждого узла в этом пути.
-
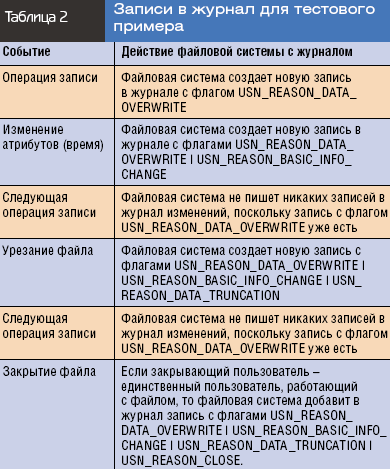
Reason. Здесь хранится флаг, описывающий действие, которое происходит с объектом. Все возможные флаги причин указаны в табл. 1. Необходимо обратить внимание на одну особенность. При изменении файла система не проставляет один и тот же флаг дважды. В случае если выполняется несколько операций записи в файл, система создаст только одну запись в файл журнала с флагом USN_REASON_DATA_OVERWRITE после первой операции. Все последующие операции с этим флагом не отобразятся в журнале. Рассмотрим пример, в котором происходит следующая последовательность операций с файлом:
-
Запись в файл.
-
Установка времени изменения.
-
Запись в файл.
-
Урезание файла.
-
Запись в файл.
-
Закрытие файла.
В этом случае записи журнала будут производиться, как показано в табл. 2.
-
TimeStamp. Штамп времени этой записи в формате UTC.
-
USN. Номер последовательности изменений данной записи журнала. Значение USN является смещением записи относительно начала журнала. Оно постоянно возрастает, а значит, чем новее запись, тем это значение больше.
А как дела в Linux?
Наиболее распространенными файловыми системами в Linux являются reiserfs, ext2, ext3. Первая из этих файловых систем поддерживает журналирование как метаданных, так и данных. Но поддержка журналирования данных основана на особенностях функционирования самой файловой системы и является, так сказать, ее побочным эффектом и фактически не используется. Рассмотрим механизм журналирования в этой файловой системе подробней.
Файловая система reiserfs в качестве единицы манипуляции и хранения использует так называемые блоки фиксированной длины. Журнал в reiserfs — это последовательный набор блоков файловой системы. Каждый раз, когда какие-либо изменения вносятся в файловую систему, открывается своего рода транзакция, содержащая все изменения, атомарность которых необходимо обеспечить. Когда эта транзакция завершается, данные копируются на свое место, и транзакция соответствующим образом помечается. Журнал работает как циклический буфер: когда он достигает конца, данные начинают записываться в начало. Значение размера журнала по умолчанию может быть разным в разных ядрах. Он задается количеством блоков. Размер блока задается при создании файловой системы.
Общая структура журнала имеет вид, представленный на рис. 1. Journal Header — это описатель журнала, в котором содержится информация о последней оконченной (flushed) транзакции, а также о местоположении следующей неоконченной транзакции в журнале. Его структура представлена в табл. 3.


Транзакции, хранящиеся в журнале этой файловой системы, имеют вид, показанный на рис. 2. Все транзакции, попадающие в журнал, имеют заголовок, описывающий транзакцию и ее содержимое — description block, за которым следуют непосредственно блоки, которые и являются изменениями, применяемыми к файловой системе (см. табл. 4).


Наиболее важным полем в этом блоке является поле Real blocks, в котором блокам, следующим за description block, ставятся в соответствие реальные блоки файловой системы, которые и будут изменены по завершении транзакции. Иными словами, в этом поле содержится номер блока, в который попадет соответствующий блок из журнала. Например, представим это поле как массив четырехбайтных значений от К [1] до К [n]. Тогда если К [1]=8840, то в блок реальной файловой системы с номером 8840 попадет блок, идущий первым за description block, в блок с номером К [2] — второй и т. д. Окончание транзакции отмечается при помощи commit block, его описание дано в табл. 5.

Стоит отметить, что если блоки транзакции не умещаются в description block, то не уместившиеся блоки будут перенесены в это же поле в commit block. Таким образом, получается, что размер блока файловой системы влияет на объем сохраняемых данных в журнале транзакций. Чем меньше размер блока, тем меньше данных попадет в транзакцию, поскольку число соответствий ограничено значением 2* (размер блока — 24). Однако для журналирования в этой файловой системе этого более чем достаточно.
В файловой системе reiserfs имеется понятие ключ (key). Это запись, уникально идентифицирующая объект файловой системы: файл, каталог и ссылки на объект. Записи эти также хранятся в блоках специального типа.
Таким образом, механизм журналирования данной файловой системы сравнительно прост. Он сохраняет в журнал измененные блоки, включая блоки, содержащие управляющие структуры файловой системы, так называемые суперблоки, блоки битовых карт занятости и блоки, содержащие ключи. При этом не делается различия между измененными и неизмененными данными. Например, если происходит изменение управляющих структур, хранящих ключ, то сохраняется весь блок, включая как измененные, так и неизмененные ключи. Это верно и в случае внесения изменений в блоки на уровне листьев — самого нижнего уровня, на котором и хранятся собственно данные. Он устроен так, что небольшая часть данных содержится именно в блоке листьев. А если весь файл не помещается в блок, то этот блок содержит ссылки на другие блоки файловой системы. Побочный эффект такого механизма заключается в том, что в файл журнала попадают и небольшие файлы, которые умещаются в блок листьев целиком. Содержимое таких файлов можно восстановить, используя журнал.
Основной целью этого механизма является журналирование метаданных, при помощи которых значительно ускоряется процедура проверки целостности структур и метаданных файловой системы при ее старте, а также их восстановления после аварийного отказа.
Теперь о файловой системе ext3
Перейдем к рассмотрению устройства файловой системы ext3. Она является расширением файловой системы ext2, в которую добавлена возможность журналирования. В зависимости от вариантов монтирования файловой системы, на ней создается скрытый или видимый файл журнала. Кроме того, этот файл можно создавать на отдельном носителе, т. е. не на том, в котором происходят сами изменения. Такой подход призван обеспечить ускорение записи данных на диск за счет того, что время ожидания окончания записи в журнал будет меньше, чем если бы это происходило на одном диске. Сам механизм журналирования вынесен в отдельный логический уровень файловой системы, который занимается управлением и диспетчеризацией транзакций. Формат самого файла журнала сходен с применяемым в ReiserFS, как показано на рис. 3.
В начале журнала расположен заголовок, или суперблок. В нем описаны параметры журнала. Он предваряется структурой стандартного заголовка блока (см. листинг 2). Стандартный заголовок является общим для всех типов блоков, которые могут использоваться в журнале. Сам суперблок ext3 версии 2 представлен в листинге 3. Как мы видим, его структура несколько сложнее, чем в ReiserFS. Это обусловлено более развитыми механизмами журналирования и большей функциональностью.


В журнале присутствует несколько типов блоков:
-
#define JFS_DESCRIPTOR_BLOCK 1
-
#define JFS_COMMIT_BLOCK 2
-
#define JFS_SUPERBLOCK_V1 3
-
#define JFS_SUPERBLOCK_V2 4
-
#define JFS_REVOKE_BLOCK 5
На типах суперблока мы подробно останавливаться не будем. Коснемся только блоков, описывающих транзакции. Первый блок — DESCRIPTOR_BLOCK. Он описывает начало транзакции. Его структура, а также флаги, которые могут быть в нем выставлены, представлена в листинге 4. Говоря просто, при записи в журнал этим блоком открывается транзакция. Номер этой транзакции записывается в соответствующее поле стандартного заголовка. Следом за заголовком идут записи типа journal_block_tag_t из листинга 4. Каждая из этих записей определяет, какому блоку файловой системы соответствует данный блок журнала. Например, первый блок журнала после блока дескрипторов соответствует блоку файловой системы, описанному первой записью дескриптора. Этот механизм описания соответствия блоков журнала с блоками файловой системы схож с механизмом, применяемым в ReiserFS. При записи изменений на диск транзакция закрывается блоком COMMIT_BLOCK. Закрытие означает удачное завершение транзакции и тот факт, что данные будут непротиворечивы. Он содержит только стандартный заголовок, в котором указан номер закрываемой транзакции. В случае сбоя системы данные и метаданные файловой системы могут быть восстановлены в соответствии с блоками закрытой транзакции. Блок файловой системы, включенный в журнал, может быть отменен, чтобы хранящиеся в нем изменения не применялись в процессе восстановления. Для этой цели используется блок отмены (отзыва; см. листинг 5), который содержит порядковый номер и список отменяемых блоков. Во время восстановления все блоки, указанные в блоке отмены, порядковые номера которых меньше порядкового номера блока отмены, восстанавливаться не будут. Механизм отмены используется с целью избежать повторного применения журналированных данных. Например, вы удаляете каталог. Затем создаете некий файл, а файловая система выделят под него те же блоки, что были выделены под каталог. Обе эти транзакции зафиксированы. Происходит сбой. После перезагрузки начинается восстановление данных по журналу. Процедура восстановления начинает повторять транзакции, при этом берет измененные блоки из журнала. В итоге блоки нового файла, если данные не журналировались, могут оказаться затертыми метаданными каталога, т. е. в файловой системе появится удаленный ранее каталог и испортит ваш файл. Для того чтобы избежать такого поведения, во время процедуры фиксации транзакции в журнал записываются блоки отмены для операций удаления метаданных.


Таким образом, можно сказать, что в случае с ext3 мы имеем систему журналирования, сходную по своему принципу с ReiserFS. Тут также журналируется содержимое целых блоков. Однако, в отличие от ReiserFS и NTFS, существуют дополнительные режимы, позволяющие журналировать не только метаданные, но и сами данные файлов. Это может несколько уменьшить производительность, однако значительно повышает устойчивость файловой системы к различного рода сбоям. Кроме того, журналирование данных и знание устройства журнала может помочь вам побороть последствия хакерской атаки.
Подведем итог
Наиболее отказоустойчивой файловой системой, исходя из функциональности журналов, является файловая система ext3 в режиме полного журналирования. ReiserFS и NTFS в этом вопросе уступают. Кроме того, в NTFS процедура восстановления по журналу несколько сложнее логически, нежели в ReiserFS или ext3. Однако тут стоит отметить, что журнал NTFS предоставляет больше возможностей с точки зрения удобства отслеживания изменений в файловой системе в целях безопасности. Об этих возможностях и методах отслеживания речь пойдет в следующей статье.
Андрей Вернигора - администратор баз данных и системный администратор на одном из предприятий компании «Укртранснафта». Имеет сертификат MCP. eosfor@gmail.com