
Движущиеся детали - всегда самая ненадежная часть устройства. Однако правильная реализация избыточности поможет избежать сбоев сервера из-за отказа жестких дисков.
Благодаря техническому прогрессу в области корпоративных сетей, все больше критически важных приложений и данных переносятся на сетевые файловые серверы и серверы баз данных. При таком положении дел надежность работы сетевых приложений ставится во главу угла. Следовательно, информационные системы должны быть спланированы таким образом, чтобы обеспечить пользователям практически бесперебойный доступ к мэйнфреймам, учрежденческим АТС и прочим "принадлежностям", ставшими непременными атрибутами современного офиса.
Копирование критически важных данных (независимо от того, записываются ли они на магнитную ленту, оптический диск или магнитный диск) выполняется многими с неукоснительностью религиозного обряда. Конечно, хорошо, когда можно восстановить данные после отказа сервера, но куда приятнее вовсе избежать отказа. Вот почему администраторы сетей и информационных систем стараются не упустить любую возможность повысить надежность сети.
В общем и целом, твердокристаллическая электроника снискала завидную славу надежной техники с продолжительным сроком службы. Конечно, микросхемы памяти и прочие электронные компоненты время от времени допускают сбои, однако основная опасность отказа компьютерной системы кроется в подверженных износу и поломкам механических частях.
Лучший способ защититься от отказа дисковой системы - это технология RAID (Redundant Array of Independent Disks). Идея RAID состоит в том, чтобы хранить избыточную информацию на разных дисках и тем самым при отказе любого диска из массива обеспечить работоспособность системы.
НА УРОВНЕ
В 1988 году сотрудники Калифорнийского университета Дэвид А. Паттерсон, Гарт Гибсон и Рэнди Х. Кац опубликовали работу под названием "Доводы в пользу избыточных массивов недорогих дисков" ("A Case for Redundant Arrays of Inexpensive Disks"), где впервые было введено сокращенное наименование RAID и описаны пять способов организации дисковых массивов, получивших название уровней RAID.
С тех пор многочисленные производители дисков встали под знамена RAID. Вполне понятное желание избавиться от конкурентов с неизбежностью породило волну заманчивых обещаний. Некоторые производители объявили даже о том, что в их продуктах нашли воплощение "изобретенные" ими (в маркетинговом смысле, конечно) новые уровни RAID. После таких заявлений неудивительно, что в умах как реальных, так и потенциальных пользователей RAID царит сущая неразбериха относительно того, чем же, собственно, они пользуются или собираются пользоваться.
Чтобы внести ясность в вопрос об уровнях RAID и повысить степень образованности пользователей, ряд производителей организовали Комиссию советников по RAID (RAID Advisory Board, RAB). Это солидная организация, насчитывающая на сегодняшний день 50 членов, среди которых университеты, маркетинговые компании, а также поставщики дисков, систем RAID, компьютерных систем и тестового оборудования. Помощь в работе RAB оказывает компания Technology Forums. Ее президент, Джо Молина, является Председателем RAB. Согласно уставу, основные цели RAID Advisory Board состоят в просвещении, стандартизации и сертификации.
Помочь с просвещением и стандартизацией призваны публикуемая RAB 200-страничная книга под названием "The RAIDbook", в которой самым исчерпывающим образом рассмотрена технология и терминология RAID, и ее краткий (30 страниц) вариант, озаглавленный "RAIDprimer". Для сертификации и стандартизации, RAB разработала систему тестов, позволяющих установить, насколько испытуемая система соответствует требованиям RAB. Тесты, кроме того, помогают определить общую производительность; с помощью тестов производители могут проверить свои изделия на соответствие требованиям RAB. Изделиям, соответствующим одному из уровней RAID согласно "The RAIDbook", предоставляется лицензия на помещение логотипа RAID Conformance Logo и текста, разъясняющего, какие уровни RAID поддерживает данный продукт.
ЧТО НАМ СТОИТ МАССИВ ПОСТРОИТЬ
Любой набор дисков можно назвать массивом, однако далеко не любой массив является RAID-массивом. Возьмите пару-тройку дисков, вставьте в подходящий корпус с источником питания, соедините с файловым сервером при помощи адаптера шины SCSI или какого-нибудь другого средства обмена данными - и массив готов.
С помощью шины SCSI, например, можно подключить четыре дисковода к файловому серверу. При этом операционная система видит каждый диск как отдельное логическое устройство. Если сервер работает под MS-DOS, диски массива получают имена D, E, F, G; на сервере NetWare каждый диск рассматривается как отдельный логический том, имеющий свое собственное имя. Диски могут отличаться друг от друга по размеру. Такую компоновку часто называют "Just a Bunch of Disks" (JBOD, Просто Группа Дисков). В некоторых ситуациях она прекрасно работает, однако в большинстве прикладных программ предусмотрена запись данных только в одно место, а распределение данных по нескольким дискам или томам не предполагается.
Кроме того, данная конфигурация не предоставляет избыточности ни по дискам, ни по данным, и в этом смысле она не является отказоустойчивой. (Кстати, совершенно не обязательно соединять диски с машиной при помощи шины SCSI, однако использование SCSI для групп дисков удобно тем, что данный стандарт обеспечивает подключение до восьми устройств к одной шине; SCSI-контроллер - одно из этих устройств, а остальные семь мест предположительно используются для дисков. Вот почему для организации дисковых массивов, как правило, необходима шина SCSI.)
Одна из конфигураций, обеспечивающих преобразование группы дисков в один "виртуальный диск", называется ленточным массивом (striped array, disk striping). С точки зрения операционной системы, запись данных на ленточный массив выглядит как последовательная запись блоков данных на один диск. Однако вместо диска поток данных попадает вначале на контроллер массива, который организует рассылку блоков данных по группе дисков.
Словно человек за занавеской из детской книжки "Волшебник страны Оз", контроллер массива скрывает свои действия от операционной системы и приложений; он отождествляет блоки данных на логическом диске, используемом операционной системой, с физическими блоками дисков массива. В трехдисковом массиве, например, логический блок 1 записывается в физический блок 1 диска 1; логический блок 2 отображается в физический блок 1 диска 2, а логический блок 3 отправляется в блок 1 диска 3. Далее, логический блок 4 записывается в физический блок 2 диска 1, а логический блок 5 отображается в физический блок 2 диска 2 и так далее.
Емкость ленточного массива равна сумме емкостей составляющих его дисков. К примеру, три диска объемом 2 Гбайт дадут один логический диск объемом 6 Гбайт. Поскольку данные на логическом диске распределены по трем физическим дискам, реально повысить производительность системы за счет организации параллельных дисковых операций. В случае трехдискового массива скорость передачи данных при чтении/записи больших файлов последовательного доступа теоретически может почти сравняться с утроенной производительностью одного дискового накопителя.
Недостатком ленточных массивов является низкая степень надежности: отказ одного диска означает полную утрату данных всего массива. Например, если каждый из дисков массива характеризуется средней наработкой на отказ в один миллион часов, то следует ожидать одного отказа каждые миллион часов. Поскольку в данном ленточном массиве используются три диска, то за каждый миллион часов число отказов увеличивается в три раза, что дает один отказ каждые 333333 часа. Вывод прост - частота отказов ленточного массива обратно пропорциональна числу используемых дисков, а стало быть, использование ленточных массивов для критически важных приложений представляется нежелательным.
ОТРАЖЕНИЕ
Степень надежности возрастает, если использовать зеркальные массивы, в которых один из дисков представляет собою "зеркальное отражение" другого диска, именуемого первичным. При записи блока данных контроллер осуществляет запись на оба диска. При отказе первичного диска работа компьютера не прерывается, поскольку весь поток данных направляется на зеркальный диск. Пользователь даже не заметит, что диск отказал, однако администратор сети должен быть начеку, поскольку система уже не обладает необходимой для отказоустойчивой работы избыточностью.
Восстановление зеркальной системы после отказа одного диска означает замену неисправного устройства и повторного выполнения "отражения". При этом контроллер массива копирует содержимое уцелевшего диска на новый. Данная операция выполняется поблочно - от начала диска и до конца.
При использовании специальных контроллеров производительность зеркального массива может быть выше производительности одного диска. В частности, контроллер способен поддерживать раздельный поиск при чтении, когда один блок ищется на первом диске, а другой - на втором.
Из зеркального двухдискового массива (объем каждого диска 2 Гбайт) получается один отказоустойчивый логический том объемом 2 Гбайт. Недостаток очевиден: чтобы получить зеркальный массив объемом 2 Гбайт, надо потратиться на 4 Гбайт дискового пространства.
Пытаясь снизить плату за надежность, ученые из Беркли стали думать, как бы еще организовать дисковый массив. В их работе зеркальные диски были определены как RAID первого уровня.
Объем статьи не позволяет углубиться в описание всех схем RAID, поэтому вкратце опишем лишь наиболее часто используемые уровни RAID и отошлем читателя за более подробной информацией к "The RAIDbook". Для ясности еще одно предостережение - говоря о разных уровнях RAID, мы вынуждены сильно упрощать картину. Реализация RAID может быть чрезвычайно сложна, поэтому стоит обсудить только основную идею технологии, а не детали реализации или все имеющиеся вариации на заданную тему.
УРОВЕНЬ ЗА УРОВНЕМ
Первый уровень RAID предполагает, скажем так, сплошное копирование защищаемых данных, остальные же четыре уровня RAID основаны на работе с одной копией данных (хотя и распределенных по разным дискам) при использовании схем четности. Поэтому уровни RAID выше первого иногда называют также RAID с контролем четности. Использование контроля четности вместо простого копирования данных позволяет, по сравнению с зеркальным отображением, снизить накладные расходы на избыточность.
Третий уровень RAID, или RAID 3, является следующим по сложности уровнем. В нем используется ленточный массив из нескольких дисков, к которому добавлен еще один диск для хранения информации о четности. В качестве примера рассмотрим четырехдисковый RAID 3. В этой конфигурации блоки данных записываются на первые три диска, подобно тому, как это было описано выше. Затем контроллер RAID вычисляет блок четности для записанных трех блоков с использованием логического оператора "исключающее ИЛИ". Указанный блок записывается на четвертый диск (именуемый также диском четности), после чего контроллер RAID переходит к записи трех следующих блоков данных вместе с блоком четности и так далее.
В предложенной схеме защита данных обеспечивается за счет использования блока четности для восстановления утраченных данных в ходе операции чтения при отказе одного из дисков. Пользователи, скорее всего, даже не почувствуют, что произошел отказ, но администратор системы получит аварийный сигнал.
Чтобы восстановить исходное состояние RAID-системы, нужно заменить отказавший диск и подать команду RAID-контроллеру восстановить массив. Получив такую команду, контроллер просматривает все блоки, определяет, каких данных недостает, восстанавливает утраченные фрагменты на основе информации о четности и записывает полученные блоки на новый диск.
Очень важно восстановить массив как можно скорее; хотя система RAID и может сохранить работоспособность при отказе одного диска, на большее она уже не способна - отказ второго диска будет означать полную утрату всех данных.
Накладные расходы на организацию RAID 3 зависят от числа дисков в системе. В случае четырех дисков, один диск используется для хранения информации о четности, в результате непроизводительные накладные расходы составляют 25%.
Для организации RAID 3 необходимо, чтобы все диски вращались синхронно или почти синхронно. Это называется синхронизацией шпинделей. RAID 3 предполагает также синхронный поиск на всей ленте. (Под словом "лента" подразумевается набор соответствующих блоков на всех дисках массива, например все нулевые блоки на четырех дисках.)
В общем и целом, на всех уровнях RAID производительность при чтении увеличивается за счет параллельной работы с несколькими дисками. Что же касается операций записи, то здесь имеется определенное замедление, так как при записи необходимо вычислять и записывать блок четности. Поскольку все диски вращаются синхронно и поиск по ним производится одновременно, работу с RAID 3 удается значительно оптимизировать за счет использования параллельных операций чтения и записи. Это, однако, в первую очередь касается больших файлов последовательного доступа, когда операционная система записывает один блок за другим. Поэтому RAID 3 очень удобен для записи или воспроизведения видеоинформации или сейсмографических данных. При обработке транзакций, где обычно требуется осуществление большого количества операций ввода/вывода, при каждой из которых передается небольшой объем информации из самых разных участков базы данных, преимущества RAID 3 неочевидны.
Схема, в которой удается избежать проблем с параллельным доступом, характерных для RAID 3, - это RAID 5. Пятый уровень RAID предполагает распределение блоков четности по всем дискам массива, так что здесь специальный диск для хранения информации о четности не используется. Объем статьи не позволяет подробно описать алгоритм отображения блоков в RAID 5, однако следует отметить, что в результате производительность при записи увеличивается при произвольном вводе/выводе и уменьшается при записи больших файлов последовательного доступа (в противоположность тому, что мы имели для RAID 3).
Накладные расходы на объем диска при работе по схеме RAID 5 точно такие же, что и для RAID 3 - 25%.
Второй и четвертый уровни RAID используются реже и, по-видимому, менее удобны, чем RAID 3 и RAID 5. Если вас интересуют подробности по данному вопросу, опять-таки загляните в "The RAIDbook".
Хотя идеологи системы RAID описали только пять уровней, многие изготовители на своем, профессиональном, жаргоне называют ленточные диски нулевым уровнем RAID. Строго говоря, это неправильно, поскольку такая конфигурация не обеспечивает избыточности, а следовательно, по сравнению с одиночным диском, и дополнительной отказоустойчивости. Поскольку ленточные диски именуются нулевым уровнем RAID весьма часто (думается, вам уже приходилось видеть рекламные тексты вроде "Отказоустойчивость RAID уровней 0, 1 и 5"), RAB санкционировала применение данного термина, что, на наш взгляд, не вполне оправданно.
РАЗНЫЕ КОМПАНИИ ПОСТУПАЮТ ПО-РАЗНОМУ
Пол Массилья, директор по маркетингу Digital Equipment и редактор последнего издания "The RAIDbook", говорит, что Digital считает необходимым использовать кэш с обратной записью с резервным питанием от гальванических элементов, исключающим связанное с RAID замедление записи. "Мы не предлагаем выбирать между разными уровнями RAID, - поясняет Массилья. - Если клиент сделал выбор, наша система обеспечит ему все необходимое". Он отмечает, что разница в производительности между уровнями RAID маскируется благодаря ускорению работы за счет использования кэш с обратной записью.
Почему необходимо использовать кэш с обратной записью? Потому что кэш чтения способен повысить только производительность при чтении; на операции записи эта технология не влияет. Чтение в системах RAID осуществляется довольно быстро. Ускорение требуется именно для операций записи.
Тем не менее использование кэш с обратной записью может оказаться рискованным, поскольку не каждая операция записи сопровождается немедленным обращением к диску, в то время как операционная система считает, что данные записаны на диск. При сбое в питании находящиеся в кэш-памяти критически важные данные могут быть утрачены. Благодаря гальваническим батареям, используемым в системах Digital, данные в кэше сохраняются в течение 100 часов. После возобновления питания и перехода RAID в интерактивное состояние контроллер в первую очередь запишет данные из кэша на диск, а уж потом сообщит о готовности к дальнейшим операциям чтения и записи.
Некоторые системы RAID производства Digital допускают разные способы конфигурации. Диски можно вставить в корпус, а затем объединить в несколько массивов при помощи интерфейса управления, можно также собрать в двойные или тройные "зеркальные наборы" (массивы RAID первого уровня), а можно организовать из них группу RAID с контролем четности.
Двойной зеркальный набор представляет собой обычное зеркальное отображение дисков, когда один из дисков используется в качестве первичного, а второй служит его зеркальным отражением. В тройном зеркальном наборе два диска являются зеркальным отражением первичного. Как говорит Массилья, некоторые, возможно, сочтут тройной зеркальный набор "системой RAID для параноиков", но тем не менее такие наборы находят потребителей среди совершенно нормальных людей.
В финансовом бизнесе требуется чрезвычайно высокая степень сохранности данных при круглосуточной работе. Отсюда возникает проблема создания резервных копий непрерывно используемых файлов. Пользователи двойных зеркальных наборов могут время от времени отсоединять зеркальный диск от первичного, причем первичный диск продолжает работу и пользователи ничего не замечают. Тем временем отсоединенный зеркальный диск, по существу, становится статическим образом, который легко скопировать на магнитную ленту. По окончании этой операции зеркальный диск можно вновь подсоединить к первичному и продолжить работу в двухдисковом режиме.
Разумеется, все то время, пока зеркальный диск копируется на ленту, а затем приводится в соответствие с содержимым первичного диска, уязвимость системы существенно возрастает, поскольку первичный диск работает без всякой избыточности. Выходом из положения является использование тройного зеркального набора. Например, третий диск можно поставить за несколько часов до планируемого копирования на ленту, затем запустить процедуру отображения и подождать, пока на новый диск будет скопирована вся необходимая информация. По завершении операции отображения один из зеркальных дисков можно будет отсоединить и скопировать на ленту.
"ДИНАМИЧЕСКИЙ" RAID
Компания Hewlett-Packard посчитала, что управлять массивами RAID чересчур сложно и решила упростить этот процесс, предложив новую технологию HP AutoRAID. Во многих имеющихся на данный момент системах RAID администратор должен самостоятельно настраивать дисковые массивы на рабочую нагрузку, подбирая уровень RAID и подгоняя другие параметры системы. AutoRAID же выполняет всю необходимую настройку автоматически; решение о выборе значения того или иного параметра принимается исходя из анализа данных, записываемых на диск и считываемых с диска.
Традиционная архитектура RAID предполагает статическое отображение блоков виртуального диска на физические блоки физических дисков системы RAID. Такая жесткая схема раз и навсегда заданного отображения упрощает задачу контроллера RAID по вычислению физического блока и диска, на котором находится разыскиваемый логический блок данных. Технология HP AutoRAID основана на динамическом отображении, названном компанией структурированным RAID (log structured RAID). В данном процессе используется адресная таблица. Благодаря динамическому отображению, AutoRAID получает значительную гибкость в использовании как дисковых блоков, так и самих дисков, на которые эти блоки записываются.
В основе записи данных по системе AutoRAID могут лежать уровни RAID с первого (зеркальное отражение) по пятый. Контроллер AutoRAID способен преобразовывать данные, записанные на одном уровне RAID, к другому уровню RAID без всяких последствий с точки зрения остальной части системы. Как указано в технической документации на AutoRAID, "...динамический подход к преобразованию данных предполагает использование RAID 1 (обеспечивающего максимальную производительность) для работы с активными данными и RAID 5 (как более экономичного способа) для записи данных, обращение к которым происходит не столь активно".
Чтобы увеличить объем дисковой памяти обычной системы RAID, системный администратор должен выполнить следующие действия - создать резервную копию данных на ленте, вставить дополнительный диск в дисковый шкаф, создать новую дисковую систему, включив в нее новый диск, а затем скопировать данные с ленты на диски. Разумеется, все это возможно проделать, только переведя RAID-систему в автономное состояние.
При использовании AutoRAID процедура наращивания системы RAID куда проще. Администратору достаточно просто вставить дополнительные диски и создать другой виртуальный диск. Все это можно проделать в оперативном режиме.
Как видите, разница между первым и вторым способами велика. Причина же состоит в том, что при использовании статического отображения добавление нового диска означает изменение схемы отображения, влекущего за собой нарушение структуры имеющегося массива данных. Этот процесс можно сравнить с изменением таблицы разделов в однодисковых системах - причем данные из прежних разделов становятся недоступными. В AutoRAID, напротив, новый диск рассматривается как набор блоков, добавляемых к пулу доступной дисковой памяти. При появлении новых блоков AutoRAID распределяет данные равномерно по всей дисковой подсистеме.
Впервые система AutoRAID реализована в изделии HP XLR1200 Advanced Disk Array, которое будет первоначально продаваться как OEM-продукт. Предложив AutoRAID, HP не изобрела "новый уровень" RAID, однако новая технология, безусловно, знаменует собой существенные перемены в RAID. Это событие можно сравнить с переходом от трехскоростной ручной коробки передач на трехскоростную автоматическую.
RAID - НЕ ПАНАЦЕЯ
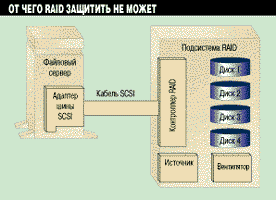
Планируя закупки, всегда следует иметь в виду, что RAID может защитить только от отказов собственно дисков. Как говорит Пол Массилья (Digital), "RAID - это всего лишь первый шаг по направлению к отказоустойчивым системам". Как показано на Рисунке 1, в состав системы RAID входят несколько критически важных модулей; отказ любого из них означает недоступность данных для компьютера. Выход из строя канала SCSI между хостом и системой RAID будет иметь точно такие же последствия. Сам контроллер RAID также является точкой повышенной уязвимости системы.
 (1x1)
(1x1)
Рисунок 1.
Идея RAID состоит в том, чтобы записывать избыточную информацию на разные
диски, тем самым обеспечивая защиту от возможных отказов дисков. Однако
данные, хранящиеся на RAID-системе, могут оказаться недоступны вследствие
отказа одного из отмеченных модулей.
 (1x1)
(1x1)
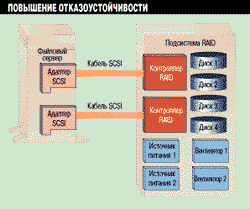
Рисунок 2.
К RAID-системе можно добавить несколько избыточных модулей, уменьшив тем
самым число точек отказа. Например, в указанной конфигурации после отказа
одного из блоков питания подсистема сохранит работоспособность.
На Рисунке 2 изображена система с высокой степенью отказоустойчивости, где продублированы все критически важные компоненты, вроде источников питания или вентиляторов. Эти компоненты системы включены либо параллельно, либо таким образом, что один включается при отказе другого. Кроме того, в системе, изображенной на рисунке, применено дублирование SCSI-адаптеров и кабелей SCSI, идущих от файлового сервера к системе RAID. Такая конфигурация, однако, весьма сложна и может быть использована только в некоторых двухпроцессорных системах, таких, например, как кластеризованные серверы Digital или двухпроцессорные системы NonStop производства компании Tandem.
Кроме того, не следует думать, что использование RAID избавляет от необходимости резервных копий. RAID отнюдь не отменяет регулярного копирования. В частности, система RAID вряд ли защитит данные от пожара в вычислительном центре. Не спасает она и от вирусов, и от ошибок пользователей (если пользователь случайно выдаст команду уничтожить файл, система послушно его сотрет). Бесспорно, большинство операционных систем не записывают немедленно данные на место стертого файла. Но уничтоженный файл в течение некоторого времени еще можно восстановить - важно вовремя обнаружить ошибку. Но что такое "вовремя"? Здесь-то и кроется опасность для корпоративных данных, поскольку границы периода, когда восстановление возможно, строго не определены.
ОБОСТРЕНИЕ ЧУВСТВ
Способствовать повышению отказоустойчивости, не связанной непосредственно с дисками, призвана система SCSI Accessed Fault-Tolerant Enclosures (SAF-TE), спецификация которой была разработана компаниями Conner Storage Systems и Intel. Джоел Рейх, директор по маркетингу Conner Storage Systems, говорит, что многие поставщики RAID успешно справляются с задачей обеспечения отказоустойчивости собственно систем RAID, "...однако до настоящего времени, по-видимому, не существовало общепринятого подхода к работе с дисковыми кабинетами". По мнению Рейха, заполнить этот пробел должна спецификация SAF-TE, появившаяся как расширение системы управления дисковыми массивами StorView производства Conner.
Некоторые производители оснащают дисковые кабинеты датчиками температуры и напряжения питания, а также определенными средствами передачи информации о состоянии кабинета на файловый сервер. Отличие SAF-TE состоит в том, что здесь предлагается использовать для этой цели канал SCSI.
Согласно SAF-TE, внутри дискового кабинета должен быть установлен недорогой восьмиразрядный микроконтроллер, задачей которого является опрос датчиков. В число последних входят температурные датчики, датчики вентиляторов и мониторы состояния блоков питания, сигнальных лампочек на дисках и замков шкафа. Микроконтроллер передает информацию о статусе по шине SCSI программному агенту SAF-TE на файловом сервере. Микроконтроллер SAF-TE получает идентификатор SCSI как устройство на SCSI-шине. Каждые 10-20 секунд агент SAF-TE опрашивает микроконтроллер и фиксирует произошедшие в состоянии шкафа изменения (если таковые имеются).
Разработчики спецификации SAF-TE намеренно отказались от использования нестандартных или редко используемых команд SCSI, которые, возможно, поддерживаются не всеми адаптерами SCSI. Агент SAF-TE может генерировать предупредительные сигналы SCSI и передавать их соответствующей управляющей консоли. SAF-TE работает как с внешними, так и с внутренними дисковыми массивами.
Кроме Conner и Intel, о своем намерении использовать или поддерживать SAF-TE объявили компании Adaptec, Advanced Telecommunications Modules, American Megatrends, AT&T Global Information Systems, BusLogic, Silicon Design Resources, Distributed Processing Technology, Intergraph, Mylex, Siemens Nixdorf, Symbios Logic и Tricord Systems.
ПОКУПАЕМ RAID
Выбор системы RAID определяется целым рядом факторов. Популярность системы очевидна, и, вероятнее всего, с течением времени все больше поставщиков будут предлагать встроенные системы RAID (в действительности, число таких предложений велико уже сейчас). Однако сегодня большую часть продаваемых подсистем RAID по-прежнему составляют внешние системы. Наличие на рынке встроенных систем сильно упрощает покупку RAID, избавляя пользователя от проблем с интеграцией. Внешние же подсистемы обычно обладают более широким набором функций.
Ниже перечислены несколько дополнительных вопросов, на которые необходимо ответить, прежде чем выбрать для себя конкретное изделие.
· Обеспечивается ли гибкий выбор уровня RAID? Или вся система должна работать на одном уровне RAID?
· Обеспечивается ли автоматический выбор уровня RAID в соответствии с рабочей нагрузкой?
· Имеется ли кэш для ускорения операций ввода/вывода? (Это еще один способ избежать замедления операций записи при использовании RAID.)
· Обеспечивается ли "горячая" замена дисков?
· Какие предусмотрены механизмы предупреждения об отказе диска или другого критически важного компонента подсистемы?
· Имеется ли возможность "горячего" резервирования? Сможет ли RAID-контроллер в случае отказа диска автоматически начать заново операцию построения диска или для этого потребуется вмешательство оператора?
ГДЕ МОЖНО УЗНАТЬ ОБ ЭТОМ?
Если вы хотите получить более полные сведения о RAID, рекомендуем прочесть уже упоминавшуюся книгу "The RAIDbook". Она издается Комиссией советников по RAID (RAID Advisory Board, 13 Marie Ln., St. Peter, MN 56082-9423). Цена книги 29,95 долларов. Распространением "The RAIDbook" занимаются также многие производители - члены RAB. Книга "The RAIDprimer" (о ней мы упоминали в самом начале статьи) стоит 4,95 долларов.
С Аланом Франком можно связаться через Internet по адресу: afrank@mfi.com или через CompuServe: 71154,754.