
При передаче аудио- и видеоинформации в распределенных сетях ее потребителями, как правило, являются несколько абонентов. Возникающую проблему доставки группового трафика в сети успешно решают протоколы многоадресной маршрутизации.
Кроме перечисленных в предыдущей статье алгоритмов (таких как RPB, TRPB и RPM, см. статью "От одного - ко многим" в предыдущем номере), формирующих деревья доставки для каждой пары (отправитель, группа-получатель), существует алгоритм Core-Based Trees (CBT), который конструирует одно дерево доставки, используемое всеми членами одной группы. При этом многоадресный трафик для каждой существующей группы посылается и принимается через одно и то же дерево доставки, независимо от отправителя.
Дерево, сформированное с помощью алгоритма CBT, может включать в себя один или несколько маршрутизаторов, которые, по сути, и формируют это дерево. Рисунок 1 иллюстрирует пример сформированного алгоритмом CBT дерева доставки и передачу многоадресного трафика через него.
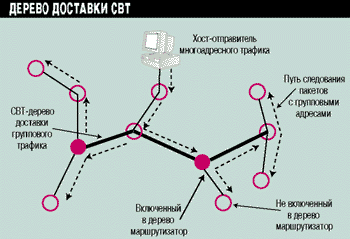
Рисунок 1.
Пример формирования CBT-дерева.
Каждый хост, который намеревается получать трафик, адресованный группе, должен послать присоединяющее сообщение (join) о своем намерении присоединится к CBT-дереву данной группы.
Предполагаемому члену группы необходимо знать только адрес одного работающего маршрутизатора дерева CBT. На этот адрес посылается присоединяющее сообщение с использованием обычной адресации. По пути следования данное сообщение обрабатывается всеми промежуточными маршрутизаторами, которые при этом отождествляют свои интерфейсы, получившие сообщение, как принадлежащие к дереву доставки данной группы. Эти промежуточные маршрутизаторы продолжают передачу сообщения, помечая свои интерфейсы, пока присоединяющее сообщение не достигнет включенного в дерево маршрутизатора.
Алгоритм CBT имеет ряд преимуществ перед алгоритмом RPM. Он более эффективно использует ресурсы маршрутизаторов, так как маршрутизатору требуется управлять информацией только для каждой группы в распределенной сети, а не для каждой пары (отправитель, группа-получатель). Кроме того, алгоритм CBT рациональнее использует пропускную способность сети, поскольку не требуется периодической передачи пакетов с групповыми адресами на все маршрутизаторы в распределенной сети.
Однако принципы, заложенные в основу работы алгоритма CBT, могут привести к сосредоточению трафика около включенных маршрутизаторов с образованием узких мест, поскольку трафик всех источников проходит по одному и тому же набору линий связи при подходе к дереву CBT. Кроме того, единственное разделяемое всеми членами группы дерево CBT может привести к увеличению задержки при передаче пакетов, что критично для некоторых мультимедийных приложений.
СКВОЗНОЙ ТУННЕЛЬ
Для более широкого внедрения приложений и услуг групповой адресации в 1992 году была создана специальная информационная магистраль в рамках сети Internet - Multicast Backbone (MBONE). Эта магистраль появилась в результате первых экспериментов комитета IETF, в которых аудио- и видеоинформация передавалась с применением средств групповой адресации в сети Internet.
Цель создания MBONE состояла в построении тестовой магистрали, поддерживающей передачу пакетов с групповыми адресами для последующей разработки, тестирования и внедрения приложений, поддерживающих групповую адресацию. В апреле 1996 года MBONE насчитывала более 2800 подсетей. Очевидно, что с появлением новых приложений и услуг, поддерживающих групповую адресацию, количество подсетей, работающих в MBONE, возрастет.
Магистраль MBONE состоит из областей, связанных многоадресными маршрутизаторами, соединенных между собой посредством так называемого механизма туннелирования (см. Рисунок 2). Создание виртуальных туннелей позволяет передавать многоадресный трафик через ту часть сети Internet, которая не поддерживает групповую адресацию. Туннелирование происходит посредством инкапсуляции по схеме IP, и таким образом пакеты с групповыми адресами воспринимаются как обычные IP-пакеты. В настоящее время в качестве протоколов многоадресной маршрутизации в MBONE используется протокол DVMRP.
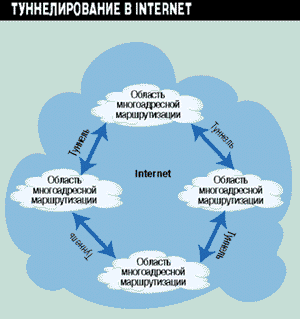
Рисунок 2.
Магистраль MBONE.
УДАРИМ ВЕКТОРОМ ПО БЕЗДОРОЖЬЮ!
Протокол DVMRP предназначен для передачи группового трафика через распределенную сеть и использует в основе своей работы алгоритм длины вектора. Протокол конструирует дерево доставки, используя вариации алгоритма RPB.
Первая версия протокола DVMRP регламентирована документом RFC 1075. Протокол сочетает методы работы протокола RIP и алгоритма TRPB. Основное отличие между протоколами RIP и DVMRP состоит в том, что первый ориентирован на определение следующего транзитного узла на пути (hop) к получателю, а второй - на определение предыдущего транзитного узла на пути к отправителю. Необходимо учесть, что ведущие поставщики маршрутизаторов в своих последних изделиях расширяют возможности протокола DVMRP, вводя поддержку алгоритма RPM.
Напомним, что в соответствии с алгоритмом RPM, первый пакет с групповым адресом для любой пары (отправитель, группа-получатель) передается через всю распределенную сеть. Этот пакет поступает ко всем маршрутизаторам в сети, которые высылают усекающие сообщения в случае, если в подключенных к ним подсетях нет членов группы-получателя. В результате происходит усечение дерева доставки от источника. После некоторого промежутка времени усеченные части дерева игнорируются, и следующий пакет для этой пары вновь передается через всю распределенную сеть, порождая новые усекающие сообщения.
Протокол DVMRP реализует механизм быстрого восстановления усеченных частей дерева доставки. Если маршрутизатор, ранее отвечавший усекающими сообщениями для пары (отправитель, группа-получатель), обнаружил вновь появившихся членов группы-получателя в подключенных подсетях, он посылает восстанавливающее сообщение (graft). Это позволяет восстановить отключенную часть дерева доставки, не выжидая промежуток времени, необходимый для отмены предыдущего усекающего сообщения.
При существовании более чем одного маршрутизатора, поддерживающего протокол DVMRP в подсети, из их числа выбирается один доминантный маршрутизатор (Dominant Router, DR), отвечающий за периодическую рассылку сообщений HMQ протокола IGMP. После инициализации каждый такой маршрутизатор назначает самого себя в качестве доминантного в этой подсети и является им до тех пор, пока не получит от соседнего маршрутизатора сообщение HMQ с меньшим IP-адресом. Выбор доминантного маршрутизатора помогает снизить число дублируемых сообщений, рассылаемых в подсети.
Поскольку протокол DVMRP был разработан для маршрутизации многоадресного трафика, маршрутизаторам в распределенной сети может потребоваться поддержка двух процессов - доставки обычных пакетов и доставки многоадресного трафика.
Расширение магистрали MBONE повышает нагрузку на ее маршрутизаторы. Текущую реализацию протокола DVMRP часто называют "плоской". Это связано с тем, что каждый маршрутизатор в магистрали должен поддерживать детальную информацию обо всех возможных маршрутах в каждую подсеть MBONE. Так как число подсетей в магистрали постоянно увеличивается, то размеры служебных таблиц маршрутизаторов также растут. В какой-то момент маршрутизаторы могут перестать справляться с нагрузкой.
Для преодоления этой проблемы разрабатывается иерархическая версия протокола DVMRP. При иерархической маршрутизации магистраль MBONE будет разделена на несколько индивидуальных регионов (доменов) маршрутизации. Каждый регион работает со своим протоколом многоадресной маршрутизации, в то время как другие протоколы используются для осуществления маршрутизации данных между регионами. Иерархическая структура снижает загруженность ресурсов маршрутизаторов, поскольку каждый маршрутизатор должен поддерживать служебную информацию о маршрутизации пакетов только внутри своего региона, и ему нет необходимости знать о детальной структуре других регионов. Протокол, поддерживающий обмен данными между регионами, управляет только их сетевым взаимодействием, не касаясь внутренней топологии этих регионов.
Каждый регион имеет свой уникальный идентификатор (Region-ID). Маршрутизаторы внутри регионов могут поддерживать любой из существующих групповых протоколов маршрутизации пакетов - DVMRP, MOSPF или PIM. Эти протоколы относятся к протоколам первого уровня (Level 1, L1). Каждый регион должен иметь по крайней мере один пограничный маршрутизатор, отвечающий за связь между регионами. Такие маршрутизаторы поддерживают протокол DVMRP, но уже как протокол второго уровня (Level 2, L2) (см. Рисунок 3). Они обмениваются между собой информацией на уровне идентификаторов регионов, а не уровне адресов подсетей внутри регионов. Таким образом, протокол DVMRP может формировать дерево доставки для пары (регион, группа-получатель), а не для обычной пары (отправитель, группа-получатель).
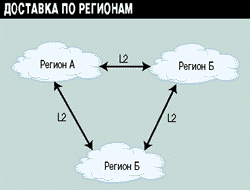
Рисунок 3.
Иерархическая структура протокола DVMRP.
Протокол DVMRP - самый распространенный из всех протоколов многоадресной маршрутизации. Он несложен при внедрении, так как основывается на простом и известном алгоритме RIP. Еще одним преимуществом применения протокола DVMRP является небольшая степень загрузки маршрутизатора при обработке запросов DVMRP. С другой стороны, именно тот факт, что основой протокола DVMRP является протокол RIP, ограничивает его применение в больших распределенных сетях.
Рассматривая будущее магистрали MBONE, некоторые эксперты прогнозируют переход от протокола DVMRP к другим протоколам многоадресной маршрутизации и при этом рассматривают как возможных кандидатов протоколы MOSPF и PIM.
Несмотря на достаточный потенциал протокола DVMRP, все активнее формируется потребность в более быстродействующем и масштабируемом подходе к многоадресной маршрутизации.
Для многих распределенных сетей наиболее оптимально использование протокола MOSPF, являющегося расширением известного протокола OSPF. Протокол OSPF разрабатывался для преодоления ограничений RIP IP, связанных с большим временем обновления таблиц маршрутизации после изменений в сетевой топологии и непригодности его для крупных распределенных сетей. Протокол MOSPF, основываясь на положительном потенциале протокола OSPF, предлагает существенные по сравнению с DVMRP усовершенствования.
Описание протокола MOSPF можно найти в документе RFC 1584. Протокол MOSPF позволяет маршрутизаторам использовать свои базы данных состояния канала (Link State Database) для построения деревьев доставки и для последующей маршрутизации многоадресного трафика.
Протокол MOSPF использует возможности протокола IGMP при определении наличия активных членов групп в подключенных подсетях. Для этого ведется специальная база данных, которая управляет списком членов группы, подключенных напрямую к маршрутизатору. Задачу рассылки сообщений HMQ протокола IGMP выполняет назначенный маршрутизатор (Designated Router, DR). Кроме того, ответственность за прослушивание сообщений IGMP HMR несут только назначенный и резервный маршрутизаторы (Backup Designated Router, BDR). BDR автоматически заменяет DR в случае его выхода из строя.
Как только назначенный маршрутизатор получил информацию о появлении нового члена группы в подключенных к нему подсетях, он генерирует специальное групповое сообщение Group-Membership LSA (Link State Advertisement), которое доставляется всем маршрутизаторам внутри данной области OSPF. После получения этого сообщения маршрутизатор добавляет информацию о новом члене группы в свою базу данных состояния канала (см. Рисунок 4).
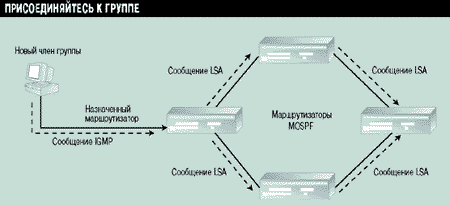
Рисунок 4.
Пример распространения многоадресных сообщений LSA.
Алгоритм состояния канала, заложенный в основу протокола MOSPF, позволяет маршрутизаторам быстро адаптироваться к изменениям в сетевой топологии и к изменениям членства в группах. В отличие от DVMRP протокол MOSPF может использовать при построении деревьев доставки от источника более гибкую метрику маршрута. Эта метрика отличается от применяемого в протоколе RIP IP простого количества транзитных узлов (hop count). Напомним при этом, что в протоколе OSPF в качестве метрики маршрута выступает суммарная стоимость интерфейсов маршрутизаторов.
Вышесказанное относилось к обработке группового трафика протоколом MOSPF внутри одной области OSPF. Дополнительно в документе RFC 1584 описываются методы передачи многоадресного трафика между областями, доменами и автономными системами (Autonomous System, AS).
В распределенной сети протоколы MOSPF и OSPF можно комбинировать, организуя таким образом постепенное внедрение поддержки протокола MOSPF в сеть. Необходимо учитывать, что при построении деревьев доставки протокол MOSPF ориентируется только на маршрутизаторы, поддерживающие этот протокол; маршрутизаторы, поддерживающие только протокол OSPF, он игнорирует, и соответственно многоадресный трафик может передаваться не по оптимальному маршруту.
Протокол MOSPF лучше всего применять в распределенных сетях, содержащих относительно небольшое количество активных в одно и то же время пар (отправитель, группа-получатель). Если в сети работают много активных пар и линии связи неустойчивы при работе, то производительность протокола начинает постепенно снижаться.
Протокол PIM был разработан комитетом IETF. Как видно из названия, PIM является полностью независимым от используемых протоколов маршрутизации пакетов с обычными адресами. При этом для создания таблицы маршрутизации и адаптации к изменениям в сетевой топологии требуется применение одного из протоколов маршрутизации, относящегося или к классу Interior Gateway Protocols (IGP) (таких как RIP, NSLP, OSPF и т. д.), или EGP.
Протокол PIM поддерживает два режима работы - PIM Dense Mode (PIM-DM) и PIM Sparse Mode (PIM-SM). Режим PIM-DM применяется в следующих случаях:
PIM-DM подобен протоколу DVMRP: для построения своих деревьев доставки оба этих протокола используют алгоритм RPM. Однако между ними существуют и различия, главное из которых заключается в том, что PIM-DM полагается на наличие одного из протоколов маршрутизации класса IGP (EGP), оставаясь полностью независимым от механизма его работы. Протокол DVMRP, наоборот, для вычисления требуемой маршрутной информации интегрирует в себя протокол маршрутизации RIP. В свою очередь протокол MOSPF использует информацию, содержащуюся в базе данных состояния канала протокола OSPF, и, кроме того, MOSPF может применяться только совместно с протоколом OSPF.
В отличие от протокола DVMRP, который вычисляет набор порожденных интерфейсов для каждой пары (отправитель, группа-получатель), PIM-DS просто передает многоадресный трафик на все исходящие интерфейсы маршрутизаторов до тех пор, пока не получит усекающее сообщение (см. Рисунок 5).
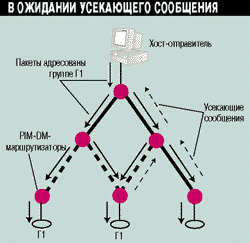
Рисунок 5.
Пример работы протокола PIM-DS.
Протокол PIM-DM, как и DVMRP, поддерживает восстанавливающие сообщения, которые позволяют реконструировать усеченное дерево доставки сразу, не дожидаясь какого-то времени.
Режим работы протокола PIM - PIM-SM - применяется в следующих случаях:
Режим PIM-SM был разработан для взаимодействия разбросанных в распределенной сети членов групп. В таких средах применение алгоритма RPM приведет к неэффективному использованию пропускной способности сети. Для осуществления эффективной маршрутизации многоадресного трафика режимом PIM-SM вводится концепция точки встречи (Rendezvous Point, RP). Роль такой точки играет один или несколько маршрутизаторов. Этот подход аналогичен подходу, применяемому в алгоритме CBT. Когда отправитель посылает данные, он вначале посылает их к маршрутизатору. И если получатель желает получать данные, он должен зарегистрироваться на этом маршрутизаторе. После того как групповой трафик был передан по схеме: отправитель --> маршрутизатор точки встречи --> получатель, промежуточные маршрутизаторы на пути следования автоматически оптимизируют маршрут для устранения лишних транзитных узлов.
МЕЖДУ ТЕМ УРОВНЕМ НИЖЕ...
Рассмотренные протоколы доставки многоадресного трафика работают на сетевом уровне. Если "опуститься" на один уровень ниже, т. е. на канальный уровень, то при доставке кадров с групповыми адресами могут возникнуть проблемы. Дело в том, что подавляющее большинство локальных вычислительных сетей строится с использованием коммутаторов, которые после выполнения процедуры трансляции группового IP-адреса в групповой Ethernet-адрес воспринимают кадры с групповыми адресами как широковещательные и, соответственно, передают их на все свои порты, вызывая ненужный трафик в сети. Такая схема обработки коммутаторами многоадресного трафика на канальном уровне сводит на нет все преимущества групповой адресации.
Во избежание подобных проблем, фирма Cisco ввела в свои маршрутизаторы и коммутаторы поддержку собственного протокола Cisco Group Multicast Protocol (CGMP). Протокол CGMP позволяет коммутаторам использовать информацию, полученную маршрутизаторами с помощью протокола IGMP, в результате многоадресный трафик на канальном уровне передается только на те порты, к которым подключены члены группы-получателя.
Рисунок 6 иллюстрирует работу протокола CGMP. Предположим, что существует хост-отправитель групповых IP-пакетов на одном конце распределенной сети, член группы-получателя - на другом конце. Между маршрутизаторами в распределенной сети пакеты передаются с помощью протоколов многоадресной маршрутизации. Для того чтобы хост - член группы-получателя на другом конце распределенной сети - получал этот многоадресный трафик, он посылает сообщение протокола IGMP локальному маршрутизатору - (1). Маршрутизатор сохраняет в памяти MAC-адрес хоста, пославшего сообщение, а затем посылает сообщение протокола CGMP коммутатору - (2). Коммутатор использует полученное сообщение для динамического добавления полей в свою таблицу коммутации (Forwarding Table), определяющую порты с подключенными к ним членами группы-получателя. После этого коммутатор будет передавать многоадресный трафик на канальном уровне только на те порты, к которым подключены члены группы-получателя - (3).
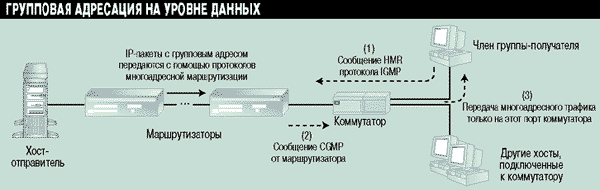
Рисунок 6.
Пример работы протокола CGMP.
МАЛЕНЬКОЕ ОБОБЩЕНИЕ
В Таблице приведены краткие сравнительные характеристики рассмотренных протоколов многоадресной маршрутизации.
ТАБЛИЦА - СРАВНЕНИЕ ПРОТОКОЛОВ МНОГОАДРЕСНОЙ МАРШРУТИЗАЦИИ
| Протокол многоадресной маршрутизации | Необходимый для работы протокол класса IGP (EGP) | Используемый алгоритм построения деревьев доставки | Оптимальные условия применения |
| DVMRP | RIP | TRPB (RPM) | Распределенные сети малого размера |
| MOSPF | OSPF | RPM | Небольшое количество активных пар и стабильные линии связи |
| PIM-DM | Любой | RPM | Небольшое количество отправителей при большом количестве получателей |
| PIM-SM | Любой | Аналогичен CBT | Несколько получателей в группах |
ЗАКЛЮЧЕНИЕ
Наибольший объем многоадресного трафика передается с помощью протокола DVMRP. Ожидается, что этот протокол будет продолжать расширять свою функциональность и использоваться для интеграции членов групп в различных регионах. Но из-за заложенных в его основу ограничений он не применим как базовый протокол многоадресной маршрутизации в распределенных сетях большого размера.
Для организаций, которые уже используют в своих сетях протокол OSPF, наиболее вероятным протоколом многоадресной маршрутизации будет MOSPF. Этот протокол показывает высокую производительность и масштабируемость, присущую протоколу OSPF.
Протокол PIM является соперником MOSPF в больших распределенных сетях. Однако он довольно сложен в применении и, кроме того, находится пока на стадии доработки.
Очень важным моментом является то, что все протоколы многоадресной передачи данных сетевого уровня могут эффективно работать в сетях ATM. При этом протоколы многоадресной передачи данных могут применяться в сетях ATM без изменений. Конечное ATM-оборудование, отвечающее стандарту LANE (LAN Emulation), прозрачно поддерживает протоколы многоадресной передачи сетевого уровня.
Таким образом, если стоит задача передачи аудио- и видеоинформации в распределенных сетях большого размера, то наилучшим вариантом выбора протокола многоадресной маршрутизации может быть протокол MOSPF, а в будущем и PIM.
Максим Владимирович Кульгин - менеджер по проектам научно-технического центра компании "АйТи". С ним можно связаться по адресу: m_kulgin@it.spb.ru.