
Кто сказал, что меньше - лучше? Когда речь идет об объединении серверов, цифры говорят сами за себя.
СЕКРЕТНОЕ ОРУЖИЕ КЛАСТЕРНЫХ ТЕХНОЛОГИЙ
Переход к коммутации
ДВУСТУПЕНЧАТЫЕ ДРАЙВЕРЫ УСТРОЙСТВ ОБЛЕГЧАЮТ ВВОД/ВЫВОД
Разделение ради объединения
Все чаще и чаще их замечают за пределами естественных мест обитания. Некоторые из них живут более скученно, чем другие, в некоем симбиозе. И хотя они встречаются в среде Unix уже в течение двух десятилетий, за их разновидностью, впервые замеченной в Редмонде, штат Вайоминг, охотятся толпы отраслевых экспертов. Особей этого загадочного вида называют серверными кластерами, и, вполне возможно, вскоре они поселятся в сети рядом с вами.
ТЬМА - ЗНАЧИТ МНОГО
Сначала в кластеры объединяли мэйнфреймы, затем мини-компьютеры, а теперь серверы на базе операционной системы Unix и процессоров Intel. Компания Tandem была среди первых, кто занялся кластеризацией: она начала выпускать серверы NonStop Himalaya еще двадцать лет назад. За это время Digital Equipment изобрела кластеризацию систем VAX под ОС VMS. IBM была также в числе первопроходцев со своим кластерным оборудованием для систем AIX и мэйнфреймов.
Термин "кластеризация" имеет много различных определений. В этой статье под кластеризацией мы будем подразумевать технологию, с помощью которой два или более серверов (узлов) функционируют как один, так что клиентские приложения и пользователи воспринимают их как единую систему. Если основной сервер выходит из строя, подмена его запасным сервером гарантирует, что пользователи и приложения по-прежнему будут обслуживаться без перерыва. Не будучи исключительно резервом, запасной сервер является активным, выполняя свои задачи, пока он не понадобится основному серверу.
Понимание концепции кластеризации невозможно без понимания архитектуры, с помощью которой серверы могут быть связаны для обеспечения более высокого уровня функциональности в таких областях, как отказоустойчивость, постоянная доступность и масштабируемость.
В архитектурах с разделяемой памятью все системы используют одну и ту же основную память. Весь трафик между устройствами должен проходить через разделяемую память. Кроме того, такие системы имеют одну копию операционной системы и подсистемы ввода/вывода. К этой категории принадлежат системы с симметричной многопроцессорной обработкой.
В модели с разделяемыми дисками каждый узел в кластере имеет свою собственную память, но все узлы совместно используют дисковую подсистему. Такие узлы обычно связаны высокоскоростным соединением для передачи регулярных контрольных сообщений, по отсутствию которых они определяют сбой и подменяют вышедший из строя сервер. Узлы в таком кластере обращаются к дисковой подсистеме по системной шине.
В модели без разделяемых ресурсов серверы не имеют никаких общих ресурсов, а у каждого процессора в кластере своя собственная память и своя собственная копия сетевой ОС. Трафик идет по выделенной высокоскоростной шине. При этом только одна система может обращаться к данному ресурсу в конкретный момент времени, хотя, если сервер, являющийся собственником ресурса, выходит из строя, другой сервер может взять управление им на себя.
Несмотря на то что каждая из этих архитектур имеет свои достоинства, настоящая кластеризация существует только в средах с разделяемыми дисками и без разделения ресурсов (см. Рисунок 1).
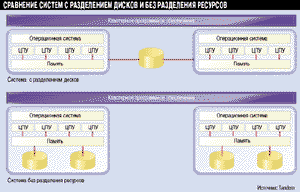 (1x1)
(1x1)
Рисунок 1.
В кластерах с разделяемыми дисками все узлы совместно используют общие
накопители, а в кластерах без общих ресурсов у каждого узла свои собственные
накопители, в результате конкуренция за них меньше.
Тенденция к кластеризации обусловлена целым рядом причин. Одна из них в том, что старое правило 80/20, утверждающее, что 80% сетевого трафика является локальным и лишь 20% передается по магистрали, больше не действует. С увеличением объемов трафика, передаваемого все дальше и дальше от места его возникновения, серверные фермы, или группы кластеризованных серверов, подключенных к высокоскоростным магистралям, становятся все более искусными в обслуживании этих изменившихся схем трафика.
Другой фактор роста популярности кластеризации - Internet с ее высокими требованиями к пропускной способности и производительности. Это привело к потребности в более мощных аппаратных и программных решениях. К тому же, по мере того как серверы Web и другие мультимедийные продукты становятся функционально разнообразнее и сложнее, серверы должны работать еще быстрее.
Кроме того, число приложений, для которых одиночный сервер может оказаться чересчур медленным, растет. "Кластеризация становится все важнее не только для высококритичных приложений, где высокий уровень отказоустойчивости просто необходим, но также для масштабных бизнес-приложений, поддерживающих крупные популяции пользователей, - говорит Брайан Ричардсон, директор по программе открытых вычислений и серверных стратегий в Meta Group. - С ростом размера системы тенденция к кластеризации проявляется все сильнее".
В самом деле отрасли, в которых компании имеют крупные системы, первыми внедряют кластерные технологии; финансовый, телекоммуникационный и здравоохранительный секторы рынка являются главными кандидатами на кластеризацию. Однако по мере того, как организации все в большей степени полагаются на электронные данные, пользовательская база должна значительно расшириться.
Сетевые администраторы более, чем когда-либо прежде, обращают внимание на стоимость эксплуатации. Многие научились выполнять довольно сложный анализ таких факторов, как простои. Потенциально астрономические потери от простоя систем привели к уменьшению допуска на простои.
Во всяком случае, согласно данным Dataquest, будущее постоянно доступных серверных систем выглядит весьма лучезарно (см. Таблицу 1). Несмотря на то что цифры в Таблице 1 относятся к широкому спектру реализаций (от избыточных компонентов сверх стандартных источников питания и вентиляторов до полных постоянно доступных систем), они являются своебразным барометром состояния кластерной технологии.
ТАБЛИЦА 1 - ПРОЦЕНТ СИСТЕМ ВЫСОКОЙ ГОТОВНОСТИ В СЕВЕРНОЙ АМЕРИКЕ
| 1995 | 1996 | 1997 | 1998 | 1999 | 2000 | |
| Суперкомпьютеры | 40 | 44 | 48 | 52 | 56 | 60 |
| Мэйнфреймы | 35 | 39 | 43 | 47 | 51 | 55 |
| Системы среднего класса | 30 | 35 | 40 | 45 | 50 | 55 |
| Рабочие станции | 15 | 19 | 23 | 27 | 31 | 35 |
| ПК | 5 | 8 | 12 | 15 | 20 | 25 |
ПЛОТНОСТЬ НАСЕЛЕНИЯ
Два Священных Грааля кластеризации серверов - доступность и масштабируемость. В постоянно доступных системах при выходе одного сервера в кластере из строя другой берет на себя выполнение его функций. Кластеризация - это нечто большее, чем, например, зеркальный подход в StandbyServer компании Vinca, при котором резервная система не работает до тех пор, пока ей не потребуется прийти на смену аварийному основному серверу. В настоящее время многие системы зеркального типа поддерживают только два сервера, хотя поставщики отказоустойчивых решений заявляют, что в будущих версиях они собираются сделать их масштабируемыми.
При кластеризации резервные серверы продолжают работать и выполнять обычные повседневные функции помимо подмены аварийных серверов. Кроме того, кластеризация защищает как от аппаратных, так и программных сбоев. "Значение этого фактора возрастает по мере того, как программные проблемы вызывают все большее число сбоев, а оборудование становится все более надежным", - говорит Марти Миллер, менеджер линии продуктов в NetFrame. Продукт этой компании - Cluster Data - призван сократить время простоев, обусловленных сбоем операционной системы.
Достоинства масштабируемости кластера состоят в том, что такие компоненты, как ЦПУ и диски, можно добавлять по необходимости для наращивания мощности сервера. Кластеризация серверов позволяет избежать имеющей место при симметричных многопроцессорных вычислениях конкуренции за память.
Масштабируемая кластерная среда с эффективным промежуточным обеспечением и распределением нагрузки рассматривается в качестве ближайшей перспективы в мире распределенных вычислений. Ответ на вопрос о том, в какой мере кластер масштабируем, зависит от ряда факторов. В идеальной масштабируемой системе добавление процессора или новой дисковой подсистемы ведет к пропорциональному росту производительности каждого инсталлированного компонента. По причинам, которые мы обсудим позже, уравнение масштабируемости имеет нелинейный характер.
Тем не менее Митч Шультц, директор по маркетингу серверных платформ в группе корпоративных серверов компании Intel, утверждает, что возможности масштабируемости выглядят весьма многообещающе. По мнению Шультца, пределы для масштабируемости систем на базе стандартных высокопроизводительных вычислительных элементов с высокоскоростными межсоединениями если и есть, то достигнуты они будут нескоро. "Нет никакого смысла рассматривать несовместимое решение при любом уровне масштабируемости, когда вы можете купить стандартные переносимые компоненты, - говорит он. - Наличие таких компонентов является ключом к кластеризации серверов".
Технологию кластеризации серверов довольно часто сравнивают с технологией SMP на базе архитектуры с разделяемой памятью. Некоторые полагают, что данная технология лучше отвечает задачам масштабирования в настоящий момент.
"Кластеризация - пока еще недостаточно зрелая технология, - говорит Джо Баркан, директор по исследованиям в Gartner Group. - Если целью является масштабируемость, то сначала лучше попробовать масштабировать систему с помощью SMP. К следующему году NT должна стать гораздо более надежной по части постоянно доступных приложений и сервисов. В отношении масштабируемости картина отличается радикальным образом, причем изменится она не так скоро. Даже если говорить о масштабируемости Unix, сегодня в первую очередь я бы все же порекомендовал именно крупные системы SMP".
Как и у любой другой технологии, у кластеризации серверов свои недостатки, и один из них в том, что ввиду относительной новизны рынка все продукты опираются на закрытые нестандартные технологии, а кластерных приложений совсем немного. Однако по мере созревания рынка кластеризации эта ситуация должна разрешиться сама собой, поскольку вследствие стандартизации и сокращения цикла разработки продуктов потенциал этого рынка будет привлекать все новых и новых поставщиков.
Кроме того, своего разрешения требуют и некоторые вопросы управления кластером. Вот что говорит по этому поводу Стив Трамак, менеджер по продуктам в отделе персональных компьютеров Digital Equipment, отвечающий за кластеризацию Windows NT: "Когда организация решает создать кластер, она ожидает, что он будет управляемым - не только в смысле определения групп взаимозаменяемых серверов и специфичных для кластера событий, но также, например, в смысле оповещения в случае сбоя". А значит, управление на базе SNMP просто необходимо.
Еще одно препятствие на пути кластеризации - управление одновременным доступом к файлам. Эта проблема может быть разрешена с помощью распределенного блокиратора (Distributed Lock Manager, DLM) для координации доступа различных приложений к файлам. Сервис DLM выполняет свою задачу посредством отслеживания ссылок на ресурсы в кластере. Если две или более системы пытаются получить доступ к одному и тому же ресурсу одновременно, DLM разрешает конфликт между ними.
Но это далеко не все. В области разработки серии кластерных комплектов, включающих необходимые аппаратные компоненты для кластера серверов, Digital выделила некоторые проблемы, на которые необходимо обратить особое внимание. "Во время разработки и тестирования, - отмечает Трамак, - у нас возникли сложности с конфигурацией, с правильной настройкой шины SCSI и с развертыванием". С решением этих вопросов кластерные комплекты станут неотъемлемой частью стратегии развертывания Digital.
Боб Блатц, менеджер по маркетингу в Digital, отвечающий за поддержку продуктов Microsoft, обращает внимание на другой важный фактор для распространения кластерных технологий. "Наверно, важнейшая проблема, о которой мне постоянно приходится слышать, - реализация приложений в кластерной среде. Пока еще не накоплено достаточно опыта работы с такими приложениями, в частности, в среде NT. Но со временем, по мере того как пользователи ознакомятся и приобретут опыт в кластерных технологиях, фаза реализации будет проходить гораздо проще и быстрее", - считает Блатц.
НОВОЕ ПЛЕМЯ
Многие поставщики имеют свои собственные реализации кластерной технологии. Хотя различные предложения рассматриваются более подробно в статье Аниты Карве "Кластеры всех мастей, объединяйтесь!", мы все-таки уделим несколько строк общей картине рынка кластерных продуктов.
Наиболее известный кластерный продукт - Wolfpack for Windows NT компании Microsoft с его комплектом программ и API для кластеризации серверов Windows NT. Microsoft планирует представить Wolfpack в два этапа. Первый этап должен был завершиться летом этого года; он состоит в реализации кластеризации двух серверов с возможностями подмены одного сервера другим. Второй этап, реализовать который Microsoft намеревается в 1998 году, должен воплотить в жизнь распределение нагрузки и кластеризацию до 16 узлов.
Такие поставщики, как Compaq, Digital Equipment, Hewlett-Packard, IBM, Tandem и NCR, разрабатывают совместимые с Wolfpack кластерные продукты самостоятельно. Amdahl, Siemens, Fujitsu и Stratus собираются взяться за свои планы разработки уже в этом году. При такой поддержке Wolfpack наверняка станет стандартом де факто.
Несмотря на то что на первом этапе Wolfpack будет обеспечивать кластеризацию только двух серверов, по глубокому убеждению Баркана из Gartner Group, Microsoft уже смотрит вперед, отчасти по практическим соображениям: "Мы обратили внимание на то, что Microsoft начинает позиционировать Wolfpack как решение старшего класса, - говорит он. - Они не готовы поддерживать сотни тысяч крошечных кластеров Wolfpack по всему миру".
Wolfpack имеет уже значительное влияние на рынок постоянно доступных серверов, в том числе и в области цен. "До недавнего времени, если вам нужна была постоянная доступность вашего кластера, то надо было тратить огромные деньги, - замечает Баркан. - По нашим оценкам, в случае кластеров Unix заказчик тратит в среднем около 50 000 долларов за профессиональные услуги по запуску, эксплуатации и тестированию системы. NT снижает стоимость кластера, по крайней мере потенциально, до приемлемого уровня. И это сделала Microsoft со своим Wolfpack".
Как же на это реагируют другие игроки на рынке кластеризации? Digital Clusters for Windows NT появились на сцене в 1996 году, и, кроме того, Digital представила свои Unix TruCluster Solutions. Последний продукт позволяет осуществлять кластеризацию как серверов AlphaServer самой компании, так и других серверов разных размеров.
Другая заметная фигура в истории кластеризации, Tandem, внесла свою лепту в виде серверов NonStop Himalaya на базе массовых параллельных систем. Некоторые части технологии Wolfpack компании Microsoft базируются на коде, который Tandem использовала в своих системах Himalaya.
ServerNet компании Tandem представляет собой шестинаправленный коммутатор данных на базе интегральных схем ASIC: эта коммутирующая структура обеспечивает масштабируемую кластерную архитектуру. По словам Джима Генри, директора по разработкам для бизнеса в отделении ServerNet компании Tandem, продукт предназначен для системных сетей, т. е. сетей, обеспечивающих доступ к ресурсам в кластерных системах. (Дополнительную информацию о решениях на базе коммутаторов см. во врезке "Переход к коммутации".)
Тим Кифавр, менеджер по кластерным продуктам в подразделении систем для Windows NT компании Tandem, говорит, что, когда начнутся поставки Wolfpack, Tandem будет предлагать активную/активную динамическую библиотеку SQL Server 6.5. (В данном контексте "активная/активная" означает систему, в которой оба узла в кластере могут выполнять транзакции SQL Server одновременно.)
Технология кластеризации компании Sun Microsystems под названием Full Moon станет отличным дополнением к таким продуктам Sun Clusters, как Solstice HA и Ultra Enterprise PDB (Parallel Database). Этот подход предполагается реализовать в четыре этапа. Первый этап, начало которому положено весной 1997 года, состоял во включении кластерных API, функций восстановления после аварий и усовершенствованного доступа в Internet посредством Solstice HA 1.3.
Технология NetWare SFT (System Fault Tolerance) компании Novell появилась достаточно давно. С помощью SFT пользователи могут зеркально копировать содержимое основного системного диска на запасной. Относительно новая версия SFT III позволяет дуплексировать целые серверы, обеспечивая подмену без перерыва в работе. По заявлениям компании, она собирается добавить новые возможности в SFT III в этом году.
"Мы не называем SFT III технологией кластеризации, хотя, по моему мнению, у нас есть на это все основания, - говорит Майкл Брайант, директор по маркетингу Wolf Mountain, инициативы Novell в области кластеризации. - Novell не собирается придавать новый смысл кластеризации. Мы придерживаемся классического определения и переносим его на серверы на базе ПК". Во время написания статьи Novell еще не объявила о дате выхода Wolf Mountain.
Подходя к кластеризации с разных сторон, IBM представила в прошлом году свое решение Cluster Internet PowerSolution for AIX. Весьма любопытно, что компания объявила также о
планах переноса своей технологии кластеризации Phoenix на платформу Windows NT. Ожидаемый продукт IBM под названием HACMP (High-Availability Cluster Multiprocessing) Geo должен позволить создавать постоянно готовые кластеры из удаленных мест.
NetServer представляет базовую кластерную платформу Hewlett-Packard. Компания может извлечь значительную выгоду из своих усилий по интеграции Wolfpack с системой управления OpenView.
Среди других компаний, которые имеют (или разрабатывают в настоящее время) решения по кластеризации, - NCR, Compaq, SCO, Data General и Stratus.
Чтобы кластер работал как надо, он должен иметь промежуточное программное обеспечение для разрешения многочисленных требований и нюансов кластерной технологии. Помимо прочего, несколько копий промежуточного программного обеспечения должны взаимодействовать друг с другом и представлять единый образ системы для приложений на различных платформах, а также осуществлять распределение нагрузки.
В приложениях баз данных, например, каждый экземпляр приложения в кластере осуществляет мониторинг всех других экземпляров этого приложения. Операции типа запросов выполняются таким образом, что нагрузка распределяется равномерно между всеми серверами, а операции с общими устройствами координируются в целях поддержания целостности базы данных.
Примерами кластерного промежуточного программного обеспечения могут служить Parallel Server компании Oracle и ServerWare компании Tandem. Microsoft объявила, что она собирает-ся предложить кластерную версию SQL Server и других приложений BackOffice; независимые поставщики также намереваются предложить кластерные приложения.
РАСЧИЩАЯ ПУТЬ
Кластеризация сервера предполагает использование достаточно сложного набора команд, плюс к тому системные сообщения должны доставляться без задержки. Наверное, никто не захочет столкнуться с таким явлением, как заторы виртуального трафика, при которых системный компонент, например ЦПУ, не имеет необходимой для поддержки всех выполняемых операций ввода/вывода емкости.
Без надлежащей инфраструктуры перегрузка может иметь место и на уровне дискового массива и системной памяти. Если вы планируете реализовать кластеризацию, то прежде всего следует обеспечить достаточный объем системной памяти и дисков. Объем зависит от ряда факторов, таких как типы приложений, с которыми вы работаете. Например, для крупных баз данных производительность может быть улучшена за счет использования двух наборов дисков: одного - для протоколирования транзакций, а другого - для данных.
Кэширование дисков также представляется немаловажным фактором. Для приложений, которым важна скорость, наличие кэша с задержкой записи весьма желательно, даже несмотря на его меньшую, чем у кэша, с немедленной записью надежность.
В системах SMP шина внутренней памяти и шина дисковой подсистемы (как правило, это устройства SCSI) используются совместно всеми ЦПУ. При кластеризации разделение данных осуществляется либо с помощью общих дисков (таких как двухпортовые устройства SCSI), либо с помощью высокоскоростного межсоединения.
Несмотря на то что сейчас многие серверы поставляются с нескольким шинами PCI и могут иметь где-то от пяти до семи слотов PCI, далеко не все реализации одинаковы. Например, в некоторых серверах одна шина PCI подключена как мост к другой, а в некоторых - две или три шины равноправны.
Использование нескольких хост-адаптеров SCSI часто способствует значительному повышению производительности. Быстрые диски также способны помочь ускорить работу сервера, однако здесь, с точки зрения цена/производительность, отдача весьма невелика. Кроме того, обычный интерфейс SCSI может поддерживать только определенное число дисков. Современные интерфейсы, такие как SCSI-3, Ultra SCSI и Fibre Channel, имеют более высокую пропускную способность, чем SCSI-2.
Ввиду важности ЦПУ для кластерных технологий, мы несколько более подробно остановимся на этой проблеме. Суровая правда жизни состоит в том, что вне зависимости от того, сколько процессоров вы вставите в сервер, масштабируемость системы будет не соответствовать ожидаемой, если переполнение данными будет препятствовать их нормальной работе. Весьма эффективный способ блокировать работу ЦПУ состоит в постоянной его бомбардировке посредством многочисленных асинхронных прерываний для обслуживания операций ввода/вывода.
На примере серверов Web прекрасно видно, какую нагрузку современные приложения возлагают на ЦПУ. Хотя простое обслуживание страниц Web не сопряжено само по себе с интенсивными операциями ввода/вывода, другие функции, такие как шифрование и дешифрование, могут потребовать всех ресурсов ЦПУ.
Архитектура интеллектуального ввода/вывода (Intelligent I/O) призвана разрешить проблему истощения вычислительной мощности ЦПУ. В модели I2O драйверы разделены на две группы: одна - для обслуживания операционной системы, а другая - для обслуживания аппаратных устройств. I2O освобождает ЦПУ, память и системную шину от большей части операций по обслуживанию ввода/вывода и возлагает их на саму подсистему ввода/вывода. Целый ряд компаний объединили свои усилия по стандартизации архитектуры I2O. (Дополнительную информацию см. во врезке "Разделение ради объединения", а также на узле www.I2O.org.)
Компания Wind River Systems разработала операционную систему реального времени IxWorks на базе модели с раздельными драйверами. ОС, являющаяся частью среды разработки I2O под названием Tornado, предполагает написание только одного драйвера для каждого аппаратного устройства, при этом один и тот же драйвер пригоден для всех сетевых ОС.
Особого внимания заслуживают усилия по стандартизации архитектуры виртуального интерфейса Virtual Interface Architecture. Участниками данной инициативы являются Compaq, HP, Intel, Microsoft, Novell, Santa Cruz Operation и Tandem. Целью этой инициативы является определение стандартов на аппаратные и программные интерфейсы для кластеров. Данные интерфейсы разрабатываются для упрощения процесса синхронизации, поддержки коммуникаций с разделяемыми массивами дисков и коммуникаций между серверами. Спецификация будет независима от среды передачи, процессоров и сетевой операционной системы.
"Архитектура VI описывает, как этот [аппаратный и программный] коммуникационный канал будет работать, - говорит Марк Вуд, менеджер по продуктам в команде Windows NT Server компании Microsoft. - Как только все согласятся на бумаге, как она должна работать, любой поставщик сможет проектировать совместимое аппаратное и программное обеспечение".
Генри из Tandem также полагает, что архитектура VI будет немало способствовать развитию кластеризации. Эта инициатива громогласно призывает: "Давайте облегчим программистам разработку программного обеспечения для кластеров", - говорит Генри.
Однако далеко не все относятся с тем же энтузиазмом к архитектуре VI. "Мы ничего хорошего от нее не ждем, - заявляет Ричардсон из Meta Group. - Microsoft просто собирается придать статус стандарта своим, ею же выбранным для среды NT, API, а другие поставщики систем будут вынуждены подстраиваться под них или идти на риск выпуска нестандартных расширений".
ВЫЖИВАНИЕ НАИБОЛЕЕ ПРИСПОСОБЛЕННЫХ
Нет недостатка в прогнозах и предсказаниях относительно будущего кластеризации серверов. Неудивительно, что большая часть из них касается вопросов производительности и цены.
"Дайте срок, и кластеризация станет базовой составляющей операционной системы, - полагает Баркан из Gartner Group. - Через пять лет любая операционная система на рынке будет иметь базовые кластерные сервисы".
Баркан высказал и мнение о цене кластерных решений: "Со временем с помощью кластеризации стоимость обеспечения постоянной доступности опустится до уровня потребительских цен, а это означает, что постоянно доступный кластер можно будет создать меньше чем за 50 000 долларов".
Некоторые организации уже в ближайшем будущем смогут заменить или дополнить свои системы на базе мэйнфреймов кластерами серверов. Но это отнюдь не означает конец мэйнфреймов. Учитывая разнообразие групп пользователей и выполняемых ими задач, и мэйнфреймы, и кластеры серверов будут мирно сосуществовать друг с другом.
Однако Баркан предостерегает от поспешных действий: "Главное - не следует торопиться. Кластеризация постепенно становится фактом нашей жизни, но параметры масштабируемости, по сути, неизвестны и непроверены".
Ричардсон из Meta Group согласен с этим мнением. "Мы приветствуем кластеры как средство повышения доступности приложений, - говорит он. - Но, думается, как решение проблемы масштабируемости приложений кластеры чересчур сложны и неэффективны".
Несмотря на эти предостережения, потенциальные выгоды в масштабируемости от кластеризации серверов довольно сильно подогревают интерес поставщиков к этой технологии. И сегодняшнее умонастроение "больше - лучше" должно в конце концов возобладать в умах многих сетевых администраторов, не желающих выглядеть белой вороной.
Элизабет Кларк - старший редактор Network Magazine. С ней можно связаться по адресу: eclark@mfi.com.
СЕКРЕТНОЕ ОРУЖИЕ КЛАСТЕРНЫХ ТЕХНОЛОГИЙ
Переход к коммутации
Мы все слышали о том, что коммутаторы позволили освободить многие сети от заторов, но немногие знают о роли технологии коммутации в кластеризации серверов.
Одной из разработок в этой области - ServerNet компании Tandem. Продукт имеет коммутирующую структуру на базе интегральных схем ASIC: она-то и позволяет создавать масштабируемую архитектуру кластерной среды. "Интегральная схема ASIC не только является многонаправленным коммутатором, но и содержит всю логику маршрутизации, логику проверки ошибок, логику сообщений об ошибках и логику обеспечения правильной последовательности пакетов", - говорит Джим Генри, директор по разработкам для бизнеса в подразделении ServerNet компании Tandem. По мнению Джима, несколько коммутаторов ServerNet могут составлять каскад, в результате чего заказчик получит очень крупную коммутирующую сеть или структуру, к которой он может подключить и серверы Windows NT, и массивы RAID.
Однако это далеко не единственная технология коммутации для кластеризации серверов. Например, SilkWorm компании Brocade Communications Systems представляет собой гигабитный коммутатор Fibre Channel с числом портов от 2 до 16 со встроенным программным обеспечением для создания структуры Fibre Channel (архитектуры межсоединения узлов в кластере). Система эта создавалась для ликвидации узких мест в каналах к дисковым подсистемам серверов. SilkWorm имеет сервис для идентификации подключенных к структуре узлов, причем он распространяет информацию об их местоположении и характеристиках другим коммутаторам в структуре.
Постоянно доступная система PowerSwitch/NT компании Apcon базируется на SCSI Switch. До 16 серверов может быть объединено в одну группу и подключено к общему дисковому массиву и другой периферии. При обнаружении сбоя сервера другой сервер автоматически подключается через SCSI Switch к внутренним дисководам и периферии вышедшего из строя сервера.
ДВУСТУПЕНЧАТЫЕ ДРАЙВЕРЫ УСТРОЙСТВ ОБЛЕГЧАЮТ ВВОД/ВЫВОД
Разделение ради объединения
А вы устаете в конце рабочего дня? Так что же пенять на многострадальные процессоры в кластере серверов! Эти трудолюбивые устройства бомбардируют прерываниями для выполнения операций ввода/вывода практически беспрестанно. При добавлении все новых и новых функциональных возможностей эта нагрузка на процессоры вряд ли уменьшится в обозримом будущем.
"Требования к вводу/выводу многократно возросли, в частности, в связи с появлением Internet, - объясняет Паулин Шульман, менеджер по продуктам в Wind River Systems. Эта компания разработала операционную систему на базе архитектуры интеллектуального ввода/вывода (Intelligent I/O, I2O) с раздельными драйверами. - Но возможности ввода/вывода значительно отстают от этих требований".
Если Intelligent I/O Special Interest Group претворит в жизнь свои усилия, то разрыв между требованиями и возможностями будет ликвидирован уже в ближайшем будущем. Данная организация предложила недавно спецификацию на базе архитектуры I2O. В принятой модели с разделением драйверов ЦПУ память и системная шина освобождены от выполнения некоторых функций.
Формально группа приняла версию 1.5 спецификации в марте 1997 года. Эта версия поддерживает одноранговую технологию, с помощью которой устройства ввода/вывода могут общаться друг с другом непосредственно без участия ЦПУ и независимо от сетевой операционной системы.
По словам Шульман, основная причина повышения производительности состоит в том, что многие операции переводятся на уровень системы ввода/вывода. Несмотря на то что в настоящее время основное внимание уделяется одноранговой технологии, в будущем группа собирается заняться и кластерными технологиями.
Microsoft объявила о своих планах включения I2O в Windows NT 5.0, а Novell также заявила о намерении реализовать эту технологию в своих продуктах.
В настоящее время о совместимости своих продуктов с I2O заявляют такие компании, как Xpoint Technologies, разработавшая решение на базе I2O для ускорения обмена данными между дисковой и локально-сетевой подсистемами, а также NetFrame, чей постоянно доступный сервер ClusterSystem 9000 (NF9000) на базе Pentium Pro совместим с Windows NT и IntranetWare. Кроме того, в этот список может быть включена и компания American Megatrends, создатель предназначенных для кластеров комплектов RAID на материнской плате для производителей серверов.