
Планы Microsoft в отношении кластеризации серверов довольно хорошо известны. А в каком направлении движется Novell?
HOMO HOMINI LUPUS EST
А мы уйдем на север...
ИЗ ПЕРВЫХ РУК
Что у Novell в рукаве
Тема кластеризации серверов на базе Intel получила освещение относительно недавно. Тем не менее разработка Microsoft Wolfрack (с недавнего времени Microsoft Cluster Server) и планы компании по построению распределенных отказоустойчивых систем у всех на слуху. В то же время аналогичные разработки Novell и перспективы компании по развитию этого направления несколько незаслуженно оставались в тени. Мы попытаемся восстановить равновесие и попристальней рассмотреть стратегию Novell.
ПРОИСХОЖДЕНИЕ ВИДОВ
Первые шаги по направлению к отказоустойчивам системам были сделаны Novell достаточно давно. С 1992 года операционные системы компании дополнительно могут поддерживать технологию SFT III, что расшифровывается как System Fault Tolerance level 3, т. е. отказоустойчивость систем 3-го уровня (вторым уровнем была зеркализация дисков в сервере).
SFT III позволяет осуществлять полную зеркализацию серверов: два одинаковых по конфигурации сервера (один основной, второй резервный), связанные между собой через специальные платы, поддерживают в реальном времени идентичное состояние дисков и оперативной памяти; причем в сети пара машин видна как один сервер. В случае выхода из строя основного сервера резервный немедленно вступает в действие, при этом, с точки зрения пользователя, ничего не меняется. SFT III, правда, накладывает достаточно много ограничений, требуя, как уже говорилось, идентичной конфигурации машин, а также использования только сертифицированных под SFT III модулей NLM, что ограничивает функциональные возможности системы. Свое решение Novell разумно не называла кластерными, используя термин "постоянная доступность" (high availability) или "отказоустойчивость" (fault tolerance).
Альтернативным решением, появившимся примерно в одно время с SFT III, является Vinca Standby Server. Как видно из названия, основное отличие этой системы от SFT III в том, что резервная машина не является "горячим зеркалом" основной и, прежде чем вступить в действие, перезагружается.
Сегодня же, имея технологии, объединенные под кодовым названием Wolf Mountain, компания выработала поэтапную стратегию разработки и продвижения масштабируемых, высоконадежных кластерных решений на платформе IntranetWare/NetWare. Три этапа, запланированных на период до 2000 года, носят условные названия Moab, Park City и Escalante.
Первый, рассчитанный на конец этого - начало следующего года, проходит под лозунгом расширения функциональности и базируется в основном на текущих решениях Novell. Он призван повысить доступность ресурсов, объединенных службой каталогов NDS. Согласно стратегии Moab все ресурсы системы тиражируются, гарантируя доступ отовсюду в любое время. Работа серверов (читай ОС) должна стать более устойчивой и производительной, а администраторы должны получить возможность централизованно управлять ресурсами и динамически менять конфигурацию серверов.
Второй этап, Park City (1998-1999), ставит своей целью появление в системе компонентов, обеспечивающих постоянную доступность и кластеризацию данных. Данные будут храниться на виртуальном томе, распределенном по нескольким серверам. Запросы на данные динамически распределяются между серверами, обеспечивая равномерную загрузку системы. На рабочих местах, в свою очередь, появятся более интеллектуальные клиенты NetWare, умеющие искать доступные на данный момент "зеркала" ресурсов прозрачным для пользователя образом.
Этап распределенных ресурсов Escalante (1999-2000) должен обеспечить пользователям взаимодействие с единой системой, точнее, с единым образом системы (single-system image, SSI), полностью спрятав ее (возможно, гетерогенную) внутреннюю сущность. Клиент сможет запрашивать конкретные сервисы и ресурсы и получать их "вовремя и без потерь", не задумываясь о том, где конкретно в сети их искать. Перейдем к детальному рассмотрению всех трех этапов.
 (1x1)
(1x1)
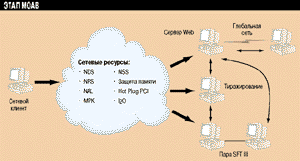
Рисунок 1.
Почти то же самое, к чему мы привыкли, но лучше.
В НОЧЬ С СЕГОДНЯ НА ЗАВТРА: MOAB
Чего же следует ждать от Novell в ближайшее время? Список служб и технологий, которые Novell вот-вот выпустит на рынок (или уже предлагает), включает в себя службу тиражирования данных (Novell Replication Services, NRS), продукт для подключения сети к Internet под названием Border Manager, усовершенствованный Novell Application Launcher (NAL), поддержку стандарта Hot Plug PCI, новое многопроцессорное ядро (MPK) с улучшенным распределением процессов, поддержку стандарта I2O, защиту памяти, виртуальную память, первую фазу гибкой зеркализации и службу управления хранением данных Novell Storage Services (NSS).
Служба тиражирования файлов NRS позволяет создавать зеркальные копии файлов IntranetWare, а также каталогов, приложений и страниц Web как в рамках локальной сети, так и по глобальным линиям, синхронизируя состояние всех тиражированных данных. Наличие дополнительных копий данных и приложений повышает надежность работы системы, а (статическое) распределение запросов пользователей снижает общую нагрузку на систему за счет предоставления пользователю ближайшей копии ресурса. Тиражирование планируется сделать кросс-платформенным.
Недавно поступивший в продажу Border Manager значительно расширяет возможности подключения корпоративных сетей к Internet при помощи IntranetWare, добавляя к последней следующие компоненты: функции шлюза/брандмауэра (благодаря NDS защита сети становится намного надежней), средства организации виртуальных частных сетей, использующих Internet в качестве глобальной магистрали, и proxy-кэширование (в том числе и каскадное), ускоряющее работу пользователей с Internet или же удаленными ресурсами Intranet.
Application Launcher предоставляет возможность через NDS централизованно администрировать сетевые или настольные приложения, а также в случае отказа сервера запускать приложение на другой машине. В дальнейшем NAL будет интегрирован с NRS.
Поддержка аппаратных решений Hot Plug PCI и I2O повысит надежность и производительность работы серверных систем. В его конечном виде Hot Plug PCI позволит заменять, удалять или устанавливать устройства PCI без выключения и перезагрузки сервера. Прямое взаимодействие устройств ввода-вывода по стандарту I2O разгрузит центральный процессор.
Новое ядро MPK улучшит работу IntranetWare как в однопроцессорных, так и многопроцессорных системах. MPK повысит вертикальную масштабируемость сетевых серверов, а также позволит администраторам задавать приоритеты различным процессам на серверах.
Модель памяти Memory Protection делит используемую IntranetWare оперативную память на системную и защищенные области. В системной области будет работать сама ОС и драйверы, в защищенных - выполняться NLM или виртуальные машины Java (один NLM в одной области). В случае сбоя в отдельном NLM процесс будет выгружен, без риска зависания всей системы. Весьма полезное усовершенствование, поскольку обычно администратор NetWare семь раз отмеряет, прежде чем "навесить" на сервер еще один NLM.
Появление виртуальной памяти повысит устойчивость и масштабируемость IntranetWare при поддержке большого количества процессов, в первую очередь при работе с виртуальными машинами Java.
Первая фаза гибкой зеркализации позволит одному диску иметь несколько разделов IntranetWare, т. е. он сможет содержать до четырех зеркальных копий других дисков. Подобное усовершенствование снимает требование по использованию при зеркализации двух идентичных дисков и дает возможность манипуляций с дисками без выключения и перезапуска системы.
Служба NSS ускоряет монтирование и восстановление томов любого размера, отменяет линейную зависимость требуемых размеров оперативной памяти от дискового пространства и поддерживает хранение неограниченного количества файлов и каталогов, а также хранение очень больших, до сотен терабайт, объектов.
Как видно, на стадии Moab в первую очередь ликвидируются архитектурные недостатки IntranetWare/NetWare, сказывавшиеся на масштабируемости и устойчивости этой операционной системы, а также добавляются значительные усовершенствования, что делает операционную систему готовой к следующему важному этапу развития.
ДЕНЬ ЗАВТРАШНИЙ: PARK CITY
На этом этапе ресурсы хранения данных будут отделены от привязки к конкретному серверу, в результате данные станут храниться в соответствии с сетевой моделью. Емкость ресурсов можно будет расширять не прерывая работу сети, логически данные будут храниться в сети в целом и иметь несколько точек доступа. Тиражирование данных будет привязано к службе хранения данных. В этом случае нагрузка при обращении ко всем ресурсам сети с различных точек доступа распределяется равномерно, за этим следят интеллектуальные клиенты.
Вторая фаза - гибкая зеркализация - расширит функциональность Moab и позволит организовывать зеркализацию, без удвоения дискового пространства. Доля избыточного дискового пространства будет сокращаться по мере добавления к зеркальной группе дополнительной емкости. Такое усовершенствование снизит накладные расходы на зеркализацию и упростит процесс администрирования дисковых систем.
Хорошее дополнение к гибкой зеркализации - усовершенствованные средства организации иерархического хранения данных (HSM). Миграция редко требуемых данных на более дешевые носители (магнитооптические библиотеки) еще сильнее сократит расходы на дорогие жесткие диски, а также повысит защищенность хранимых на них данных.
Поддержка избыточных дисковых адаптеров (Dual Path Volume) поможет серверу подсоединяться к дисковым массивам RAID по нескольким каналам, обеспечивая бесперебойное соединение с ними.
Развитие этой концепции - Cluster Volume - позволит подключать дисковые подсистемы одновременно к нескольким серверам как напрямую, так и по сети. Задать избыточные пути доступа к подсистеме можно будет при помощи NDS. Наличие избыточных путей обеспечит бесперебойный доступ к дискам, а также равномерное распределение общей нагрузки на сетевые ресурсы.
Сервис распределенного хранения данных NSS-D даст возможность использовать новые функции файловой системы и организовывать исходя из практических и экономических соображений самые различные схемы тиражирования данных, в частности при работе с логическими томами. Интеллектуальное взаимодействие службы тиражирования с HSM позволит избежать создания "зеркал" редко используемых ресурсов на жестких дисках. С помощью NSS-D можно будет перенаправлять запросы пользователей или подключать их при входе в сеть к ближайшему доступному ресурсу (или его зеркалу). Прозрачность работы с сетью будет обеспечиваться интеллектуальным клиентом.
На этапе Park City в действие вступит протокол взаимодействия серверов в кластере (InterConnect Protocol), получивший кодовое название Wolf Mountain, который осуществляет связь между серверами, совместное использование ими ресурсов и равномерное распределение нагрузки. Этот протокол отслеживает "признаки жизни серверов" и обеспечивает прозрачную передачу управления в случае отказа системы. Распределение запросов от пользователей (User Load Balancing) позволит выравнивать нагрузку на сетевые ресурсы как на уровне нескольких серверов, так и на уровне устройств одного сервера.
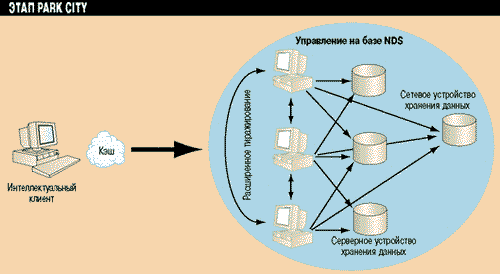
Рисунок 2.
Сто дорог - одна твоя. Та, которая короче.
Исходя из вышеперечисленного Park City можно назвать этапом локальной кластеризации. Следующим шагом, как легко догадаться, является перенос новых принципов на корпоративные сети.
СВЕТЛОЕ БУДУЩЕЕ: ESCALANTE
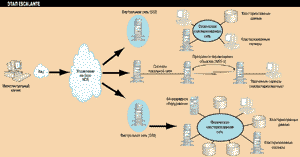
По мнению Novell, этот этап должен сделать кластеры (в их традиционном понимании) обычным явлением на всех стандартных аппаратных платформах. Серверы, данные и приложения должны образовать одну "виртуальную сеть". Термин этот, естественно, имеет в данном случае несколько иное, чем принятое у производителей сетевого оборудования, толкование, но это, скажем так, взгляд под другим ракурсом. Все ресурсы должны представать перед пользователем как составляющие одного объекта, администрируемого как единый образ системы (SSI). Escalаnte будет включать в себя следующие компоненты.
Виртуальная служба хранения данных NSS-V, дальнейшее развитие NSS и NSS-D предоставит высокопроизводительное хранилище объектов, ориентированное прежде всего на приложения Java. NSS-V сможет поддерживать практически неограниченное количество объектов, хранение и доступ к которым осуществляются унифицированными методами, вне зависимости от их природы. Система имен и ограничения доступа будут едины для объектов, хранимых на рабочей станции, сервере, кластере серверов или на архивных носителях. Планируемый в HSM переход на уровень отдельных блоков оптимизирует работу с очень большими файлами и базами данных с точки зрения как стоимости хранения, так и распределения нагрузки. Операции с объектами будут осуществляться посредством NDS, по оптимальным путям доступа через сеть. Привязка данных к конкретному серверу окончательно исчезнет, а сами серверы полностью "спрячутся" от пользователей.
Распределение нагрузки на приложения (Application Load Balancing) позволит процессам приложений мигрировать с сервера на сервер в кластере. Высокоемкие сетевые приложения смогут утилизировать кластеризованные вычислительные ресурсы во всей сети, что максимизирует масштабируемость сети и позволяет постепенно наращивать ее мощность.
Novell делает ставку на 64-разрядные вычисления и уже сегодня проводит разработки, чтобы к моменту массового перехода на 64-разрядное оборудование представить готовые решения. Хочется верить, что ко времени выхода Escalante обещанный процессор Merced будет уже выпущен.
Главная цель Escalante - SSI, логически продолжает идею, заложенную Novell в NDS. NDS представляет ресурсы сети в виде единого дерева объектов. Следующим шагом станет перенос этого видения на всю сеть "от и до". Согласно планам Novell, технология SSI, как и NDS, должна быть реализована на различных платформах и применяться не только в рамках кластерных решений компании.
Вершиной же кластерных решений будет создание глобальных кластеров (Wide Area Clustering, WAC). Кластеры будут организовываться не только в рамках локальной сети здания (или одной территориальной сети), но и распространятся на корпоративные сети, включая удаленные офисы. Этот пункт компания пока не раскрывает, поскольку реализация подобного решения сильно зависит как от развития телекоммуникаций, так и от технологий производителей сетевого оборудования.
 (1х1)
(1х1)
Рисунок 3.
Объединяется все и вся, но все эти детали клиенту уже не видны.
ЗАКЛЮЧЕНИЕ
Думается, читатели обратили внимание на весьма сжатые сроки реализации каждого из этапов. Вся эта глобальная стратегия рассчитана всего лишь на три года. Конечно, сроки всех стратегических планов имеют обыкновение сдвигаться, но "начальная ставка" все-таки показательна. Основания для подобного оптимизма у Novell есть. Компоненты всех трех этапов, как правило, являются логическим продолжением имеющихся у компании технологий; многие заявленные продукты и службы уже существуют в действующих (пусть пока и некоммерческих) вариантах, и в первую очередь это Wolf Mountain. Хотя появление кластерных решений заявлено только со второго этапа, Novell уже в этом году успешно демонстрирует кластеры на своих конференциях BrainShare, а наличие готового (или почти готового), возможно, самого сложного, компонента трехэтапной стратегии внушает надежду на то, что заявленные сроки будут выдержаны. В следующем году ждите кластерных войн!
С Александром Авдуевским можно связаться по адресу: shura@osp.ru.
HOMO HOMINI LUPUS EST
А мы уйдем на север...
Как известно, разработка Wolf Mountain протекала не совсем гладко. Хотя, наверно, это слишком осторожное высказывание, поскольку уход из компании группы ведущих разработчиков проекта - событие весьма и весьма скандальное. Не будем вдаваться в подробности до сих не завершившихся судебных тяжб между Novell и образованной "ренегатами" компанией Timpanogas Research Group, поскольку интерес в другом: что беглецы захватили с собой и как они собираются этим распорядиться.
TRG, естественно, не собирается создавать точь-в-точь то же самое, что продолжает, уже без их помощи, разрабатывать Novell. Титульная страница сервера Web компании с изображением волка, воющего на Луну, это просто шпилька в адрес бывших работодателей, и слов с корнем "wolf" TRG в своих материалах не использует. Отрезав для себя путь на рынок IntranetWare, TRG естественным образом обратилась к Windows NT. Наличие у Microsoft собственных кластерных технологий, а также готовых решений у производителей серверов заставляет TRG разрабатывать больше, чем просто кластеры, а именно распределенное многосерверное/многопроцессорное решение, ориентированное на 64-битный процессор Merced. Технологии, объединенные торговой маркой Replevin, в принципе будут переносимы и на другие платформы, а о планах TRG можно сказать, что в целом они хотят добиться такой же функциональности, что и Novell, только для NT. Пытаться предсказать будущее TRG и Replevin сейчас бессмысленно. Пока можно сделать только один вывод: наличие под боком таких зубастых парней однозначно интенсифицирует разработки, проводимые Novell.
ИЗ ПЕРВЫХ РУК
Что у Novell в рукаве
Novell впервые продемонстрировала Wolf Mountain весной, но тогда было лишь известно, что 12 серверов объединены в кластер. А что такое Wolf Mountain "на ощупь"? Незадолго до начала BrainShare Russia мы связались с московским офисом Novell, где шла подготовка к демонстрации WM, и поинтересовались, что именно специалисты компании устанавливают на серверы.