
Один метод IP-коммутации усиливает центр сети, другой - периферию, и оба повышают эффективность сети. Однако решение о применении одного из них требует индивидуального подхода.
Резкое увеличение числа работающих пользователей, рост популярности внутрикорпоративных сетей Intranet, появление новых, более требовательных к пропускной способности приложений привели к тому, что традиционные маршрутизаторы, применяемые в настоящее время в больших распределенных сетях, перестали справляться с возложенной на них нагрузкой. А все более широкое внедрение высокоскоростных технологий (таких как Fast Ethernet, 100VG-AnyLAN, ATM и т. д.) способствует еще большему росту объемов трафика в распределенных сетях, и эта тенденция нарастает.
Маршрутизаторы стали узким местом распределенной сети в силу нескольких причин. Одна из них заключается в том, что маршрутизатор выполняет все задачи по обработке пакетов, предусмотренные на третьем уровне семиуровневой модели OSI. В частности, в отличие от коммутатора, которому для принятия решения о пересылке пакета с одного порта на другой необходимо просмотреть только одно поле поступившего кадра - MAC-адрес получателя (причем это можно сделать до принятия всего кадра целиком), маршрутизатору требуется прежде считать весь пакет и проанализировать к тому же множество полей.
В распределенных сетях со множеством транзитных узлов между отправителем и получателем перечисленные причины приводят к резкому снижению производительности. Это связано с большой потерей времени на поиск данных в таблицах маршрутизации. Естественно, это время значительно больше времени, требуемого для просмотра таблицы MAC-адресов. Сюда же добавляется время, затрачиваемое на выполнение специальных функций, таких как фильтрация пакетов, шифрование и т. д.
Повышения производительности маршрутизаторов можно добиться за счет применения некоторых специальных технических решений - ускорения работы центрального процессора, реализации новых технологий кэширования данных, увеличения объема памяти, отводимой под буферы приема пакетов и т. п.
Увеличение скорости работы центрального процессора считается наиболее общим подходом к повышению производительности маршрутизаторов, однако оно способно удовлетворить лишь сиюминутные потребности определенных сетей. Это связано с тем, что характеристикам процессоров маршрутизаторов не "угнаться" за характеристиками процессоров в конечных станциях. Улучшение характеристик процессоров конечных станций влечет за собой разработку все более мощных приложений, которые, в свою очередь, требуют значительно большей пропускной способности. В этой гонке процессор маршрутизатора будет всегда отставать.
Реализация технологии кэширования заключается в выделении и классификации потоков данных, проходящих через маршрутизатор, при этом под потоком понимается трафик между конкретным отправителем и получателем. Разделение трафика на потоки и последующее кэширование записей из таблицы маршрутизации позволяют ускорить поиск по сравнению с последовательным поиском по всей таблице для каждого пакета в общем трафике. Узкое место технологии кэширования в том, что при большом количестве различных потоков возможно переполнение памяти, отводимой под кэш.
Увеличение объема памяти, выделяемой под буферы приема пакетов, повышает производительность маршрутизатора за счет уменьшения числа ситуаций, в которых IP-пакеты отбрасываются маршрутизатором ввиду его сильной загруженности.
Недостаток данного метода в том, что протокол TCP/IP постоянно пытается повысить эффективность использования сети путем увеличения скорости передачи пакетов конечным станциям. Скорость передачи пакетов увеличивается до тех пор, пока посылаемые пакеты не начнут отбрасываться. Вместе с тем увеличение памяти, отводимой под буферы, приводит к задержкам при обработке пакетов маршрутизатором, так как пакеты вынуждены проводить большее время в очередях, что, в свою очередь, замедляет скорость прохождения пакета через распределенную сеть.
Практика показывает, что, как правило, внедрения этих решений недостаточно для обработки трафика большого объема. Особенно это становится заметным в сети Internet. Как следствие, разработка новой концепции маршрутизации пакетов, при которой задержка пакетов вследствие их обработки была бы минимальной или вообще отсутствовала, стала одной из первоочередных задач. При этом такое решение должно было унаследовать все достоинства, присущие маршрутизаторам (безопасность, ограничение областей широковещания и т. д.) и коммутаторам (невысокую стоимость за порт, скорость обработки и т. п.).
Реализация данной концепции возможна двумя способами: первый - повышение "интеллектуального уровня" центра сети; второй - повышение "интеллектуального уровня" конечных устройств распределенной сети.
В первом случае проходящий трафик классифицируется центральными маршрутизаторами. На основании этой классификации маршрутизаторы принимают решение о маршрутизации последующего трафика, т. е. обрабатывают трафик в соответствии с присвоенным ему идентификатором, а не адресом получателя, содержащимся в каждом пакете. Данный способ реализован в следующих фирменных технологиях: Ipsilon IP Switching, Cisco Tag Switching, Cisco NetFlow Switching.
Во втором случае классификация трафика выполняется не центральными маршрутизаторами, а конечными станциями и серверами. Этот подход реализован в таких технологиях, как 3Com Fast IP, Cascade IP Navigator, Cabletron SecureFast Virtual Network Architecture.
Каждый из подходов использует свои собственные уникальные или стандартные протоколы; ознакомиться с ними более предметно мы предлагаем читателю на примерах решений Fast IP компании 3Com и Tag Switching компании Cisco.
FAST IP УСИЛИВАЕТ ПЕРИФЕРИЮ
Решение фирмы 3Com нацелено на увеличение производительности сетей, построенных на базе ATM. Оно отводит активную роль рабочим станциям и серверам при запросе тех сетевых услуг, которые им необходимы. При этом маршрутизаторы могут быть вообще устранены, а весь трафик - обслуживаться коммутаторами.
В основе данного решения лежат три стандарта: Next Hop Resolution Protocol (NHRP), IEEE 802.1Q/IEEE 802.1p и Ipsilon Flow Management Protocol (IFMP). Основным является протокол NHRP.
В настоящее время комитет IETF еще не завершил работу над протоколом NHRP. Разработка протокола ведется рабочей группой Internetworking Over NBMA (термин "Non-Broadcast Multiple Access Networks" характеризует сети множественного доступа с виртуальными соединениями X.25, frame relay или ATM, называемыми также нешироковещательными сетями множественного доступа), входящей в состав комитета IEFT. Сейчас этот протокол имеет статус экспериментального и определен в документе RFC 1735.
Для поддержки протокола IP в сетях ATM необходим механизм преобразования IP-адреса получателя в соответствующий ATM-адрес. Для примера рассмотрим два маршрутизатора, связанные сетью ATM. При получении одним из маршрутизаторов пакета на интерфейс локальной сети он сначала просматривает таблицу маршрутов для определения интерфейса, через который следует передавать пакет дальше. Если в результате поиска определено, что пакет нужно передавать через интерфейс ATM, то маршрутизатору необходимо узнать ATM-адрес следующего маршрутизатора в пути следования пакета.
Таблица ATM-адресов может, конечно, быть настроена вручную, но это занимает довольно много времени, и, естественно, такой метод неприменим в больших распределенных сетях. Протокол Classical IP over ATM, опубликованный в документе RFC 1577, разрабатывался для автоматического построения таблицы ATM-адресов. Кроме всего прочего, протокол вводит понятие логической IP-подсети (Logical IP Subnet, LIS). Логическая подсеть состоит из группы IP-хостов (таких как станции и маршрутизаторы), подключенных к одной сети ATM и принадлежащих к одной и той же IP-подсети.
Недостаток протокола проистекает от его классических методов работы. Так, протокол не пытается изменить порядок передачи в том случае, если пакет адресован хосту, не находящемуся в подсети отправителя (в этом случае пакет передается маршрутизатору по умолчанию). Эта схема работы не подходит к сетям NBMA, имеющих возможность определения множества логических подсетей. При этом внутри такой сети прямые связи могут поддерживаться между двумя хостами в двух различных LIS.
Преодолеть перечисленные ограничения позволяет протокол NHRP. Протокол NHRP не является протоколом маршрутизации. Однако с его помощью отправитель может определить или адрес получателя в сети NBMA (если получатель непосредственно подключен к этой сети), или адрес маршрутизатора, через который отправитель может связаться с получателем (если получатель не имеет прямой связи с сетью NBMA).
Рисунок 1 иллюстрирует пример работы протокола NHRP. Предположим, что маршрутизатору А необходимо передать данные маршрутизатору В. В отсутствии NHRP маршрутизатору А требовалось передавать данные через промежуточный маршрутизатор Б, который сконфигурирован как связующий для этих двух логических IP-подсетей. Благодаря протоколу NHRP маршрутизатор А получает NBMA-адрес маршрутизатора В, что позволяет им передавать трафик напрямую, в обход промежуточного маршрутизатора Б.
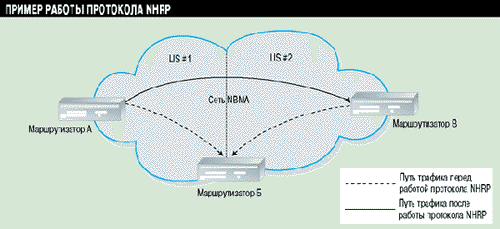
Рисунок 1.
Благодаря протоколу NHRP маршрутизатор А может передавать трафик напрямую
маршрутизатору В в обход маршрутизатору Б.
Таким образом, основным достоинством применения протокола NHRP является существенное повышение производительности в сетях NBMA. Это достигается путем устранения излишних маршрутизаторов на пути следования трафика.
Принципы работы технологии 3Com Fast IP мы рассмотрим на примере локальных коммутируемых сетей (см. Рисунок 2). Предположим, что станции А требуется передать информацию станции Б, находящейся в другой подсети. При этом обе станции принадлежат к общей коммутируемой инфраструктуре. Так как станция Б находится в другой подсети, станция А передает пакеты маршрутизатору по умолчанию. Вначале станция А посылает NHRP-запрос, содержащий ее MAC-адрес, станции Б. Когда маршрутизатор получает этот NHRP-запрос, он направляет его станции Б, которая формирует NHRP-ответ, используя указанный в запросе MAC-адрес станции А. Этот NHRP-ответ передается через коммутируемую инфраструктуру обратно станции А, но маршрутизатор уже не участвует в процессе передачи данных.
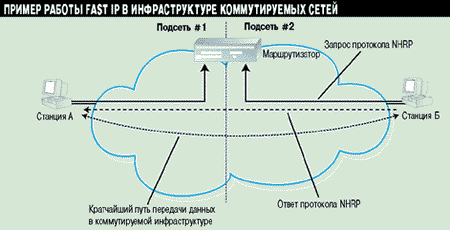
Рисунок 2.
Маршрутизатор участвует только в передаче NHRP-запроса от станции А
к станции Б. NHRP-ответ и все последующие данные передаются через коммутируемую
инфраструктуру.
В больших сетях, состоящих из множества коммутаторов, могут возникнуть ситуации, когда некоторые из них не содержат в своих таблицах MAC-адрес станции А. Эти коммутаторы будут передавать NHRP-ответ через все свои порты. Такая ситуация возникает только однажды, так как затем коммутаторы обновят свои таблицы и добавят в них адрес станции А.
Решение 3Com Fast IP имеет некоторые топологические ограничения. На Рисунке 3 приведен пример сетевой топологии, которая не поддерживается Fast IP.
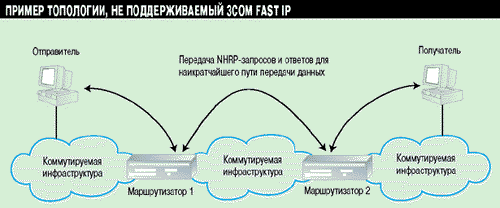
Рисунок 3.
В такой топологии маршрута из конца в конец через коммутируемую структуру
нет.
В этом примере ограничения по поддержке Fast IP связаны с отсутствием коммутируемого пути передачи данных из конца в конец между станциями отправителя и получателя. Ограничения могут быть сняты при условии, что промежуточные маршрутизаторы смогут формировать NHRP-запросы для построения кратчайшего пути передачи данных между ними. Процесс установки кратчайшего пути разбивается на три шага: формирование пути от отправителя к маршрутизатору 1, от маршрутизатора 1 к маршрутизатору 2 и от маршрутизатора 2 к получателю. Необходимо учесть, что в настоящее время не все маршрутизаторы поддерживают генерацию NHRP-запросов.
Защита данных при внедрении решения 3Com Fast IP достигается за счет того, что вначале NHRP-запросы должны пройти через маршрутизатор, находящийся на пути передачи данных. В распределенных сетях, в которых необходимо обеспечить повышенную безопасность, маршрутизатор можно настроить так, чтобы он блокировал NHRP-запросы, адресованные определенной станции. Если маршрутизатор начнет блокировать такие запросы, то построить кратчайший путь передачи не удастся, и трафик будет передаваться через него и через другие маршрутизаторы в пути следования.
Решение 3Com Fast IP представляет собой программное обеспечение, устанавливаемое на конечные системы (рабочие станции и серверы). Основное требование состоит в том, что данное программное обеспечение должно быть установлено на системы и отправителя и получателя.
Иногда доступ к одной из конечных систем для установки программного обеспечения Fast IP невозможен в силу тех или иных причин. В таких ситуациях может быть использован агент-посредник (proxy) Fast IP. Proxy Fast IP представляет собой коммутатор с оригинальным программным обеспечением. В этом случае программное обеспечение Fast IP должно быть загружено только на сервер. Для установления кратчайшего пути между рабочей станцией и сервером, NHRP-запросы будет формировать последний. Агент-посредник берет на себя функцию формирования NHRP-ответа за рабочую станцию, отсылая серверу ее MAC-адрес. Рабочая станция и агент-посредник должны иметь при этом непосредственное соединение. Кратчайший путь будет установлен только в одном направлении - от сервера к рабочей станции. В результате производительность работы повышается, так как основной поток трафика следует в направлении от сервера к рабочей станции.
Решение 3Com Fast IP для практической работы можно получить в пользование следующими путями:
Для упрощения использования программного обеспечения 3Com Fast IP можно применить программные комплексы управления сетями: Microsoft SMS, Symantec Norton Administrator, Novell ManageWise и т. д.
Внедрение решения 3Com Fast IP позволяет в 4-5 раз увеличить производительность сети за счет устранения маршрутизаторов с пути следования трафика (по данным компании 3Com). Еще одним достоинством является возможность реализации данного решения в сетях, построенных на оборудовании различных производителей. Для реализации 3Com Fast IP в глобальных сетях необходимо его взаимодействие с решением компании Cascade IP Navigator.
ЕСЛИ НУЖНО УСИЛИТЬ ЦЕНТР - БЕРИ CISCO TAG SWITCHING
Провайдерам услуг Internet требуются все большая и большая пропускная способность, что продиктовано не только ростом числа пользователей сети Internet, но и внедрением мультимедийных приложений. Данное требование ведет, в свою очередь, к необходимости увеличения производительности центральных маршрутизаторов при обработке обычного и многоадресного трафика.
Фирма Cisco предлагает эффективное решение данной проблемы. Используя гибкость и богатство функциональных возможностей маршрутизации третьего уровня, это решение позволяет реализовать простую технологию передачи данных на основе фирменного алгоритма обмена меток (label swapping). Новая технология направлена на расширение возможностей центральных маршрутизаторов распределенной сети.
Каждый маршрутизатор с поддержкой технологии тег-коммутации (Tag Switching Router, TSR) первоначально формирует внутренний образ сетевой топологии, используя стандартные протоколы маршрутизации (OSPF, BGP или EIGRP). После заполнения таблиц маршрутизации каждый TSR локально генерирует для каждого маршрута так называемую метку (tag). Метка - это короткая, фиксированной длины строка, позволяющая выполнять быстрый и простой просмотр таблицы маршрутизации. При этом время, затрачиваемое на поиск необходимого маршрута, значительно сокращается. Каждая метка может соответствовать одному маршруту или их совокупности. Эти локально генерируемые метки распространяются между соседними TSR с помощью фирменного протокола Tag Distribution Protocol (TDP).
Как только пакет поступает на граничный TSR, ему присваивается своя метка, и затем он передается следующему TSR на данном маршруте (см. Рисунок 4). Метка имеет смысл только в области действия решения Cisco Tag Switching. При выходе пакета из этой области метка изымается.
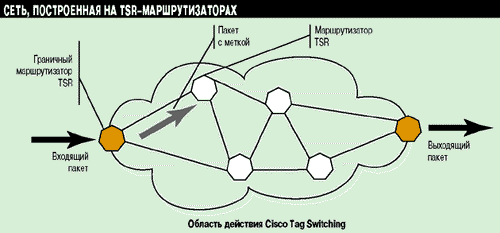
Рисунок 4.
Входящий пакет получает метку на граничном маршрутизаторе. При выходе
пакета из области действия тег-коммутации метка изымается.
Маршрутизаторы, расположенные внутри области действия Tag Switching, принимают решения о маршрутизации основного трафика в зависимости от метки. После получения пакета маршрутизатор корректирует метку и отправляет пакет следующему TSR. Если полученный пакет содержит метку, о которой нет информации, или метка отражает совокупность маршрутов, то данный TSR будет выполнять маршрутизацию традиционным способом. Иными словами, для своей работы каждый TSR требует корректной информации о метках внутри множества связанных TSR.
Метка размещается после заголовка кадров второго уровня, но перед заголовком пакетов третьего уровня, в поле Flow Label заголовка пакетов IPv6 или в поле VCI ячейки ATM. Это позволяет реализовать поддержку решения Cisco Tag Switching практически в любой среде передачи данных.
Алгоритм обмена меток реализуется следующим образом. После поступления пакета с меткой на очередной TSR, он считывает ее и использует как индекс для работы со своей информационной базой меток (Tag Information Database, TIB). Каждой входной метке в TIB соответствует определенная информация, применяемая для маршрутизации всех пакетов с этими метками.
Рисунок 5 иллюстрирует пример работы алгоритма обмена меток. При получении TSR пакета с меткой 100 он, используя набор выходящей информации в TIB, присваивает пакету метку 500 и передает на соответствующий интерфейс.
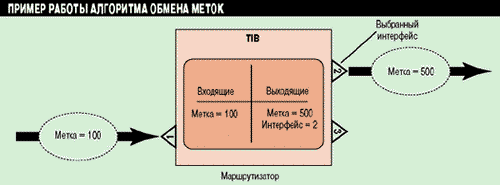
Рисунок 5.
При получении пакета маршрутизатор присваивает пакету новую метку на
основании информации TIB.
Процедура поиска необходимой для принятия решения о маршрутизации информации в базе TIB эффективнее, чем в случае традиционного алгоритма поиска в обычной таблице маршрутизации. Кроме того, данная процедура может быть реализована на аппаратном уровне, с использованием технологии ASIC. Технология обработки меток не зависит от их внутреннего содержания, т. е. метка может соответствовать одному маршруту или совокупности маршрутов в случае обычного трафика, маршруту передачи группового трафика или идентификатору потока данных.
Архитектура IP-маршрутизации сети Internet имеет строгую иерархию. Вся сеть Internet рассматривается как совокупность индивидуальных доменов маршрутизации, называемых автономными системами. Маршрутизация внутри автономной системы выполняется с помощью протоколов маршрутизации, принадлежащих к классу внутренних протоколов маршрутизации (Interior Gateway Protocol, IGP), а между автономными системами - с помощью протоколов, принадлежащих к классу граничных протоколов маршрутизации (Border Gateway Protocol, BGP). Однако все маршрутизаторы внутри индивидуальных доменов, передающие транзитный трафик, должны поддерживать информацию, полученную не только от протоколов класса IGP, но и от протоколов класса BGP.
Решение Cisco Tag Switching позволяет резко уменьшить количество информации о маршрутизации, так как только граничным TSR требуется вся информация, полученная от протоколов маршрутизации класса BGP. С этой целью решение Cisco Tag Switching предусматривает возможность включения в пакет не одной метки, а набора (стека) меток.
При передаче пакета между двумя TSR граничных доменов данный пакет получает первую метку. На Рисунке 6 представлен пример передачи пакета между двумя доменами.
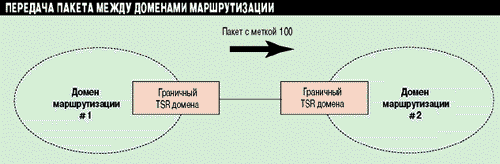
Рисунок 6.
В случае решения Cisco Tag Switching только граничным маршрутизаторам
требуется вся информация от протоколов маршрутизации класса BGP.
Вторая метка формируется при передаче пакета внутри домена маршрутизации входным граничным TSR домена и помещается впереди первой метки. По мере прохождения пакета внутри домена метка преобразуется в соответствии с алгоритмом обмена меток. Данная метка используется для определения корректного маршрута до другого граничного маршрутизатора этого домена. Процесс прохождения пакета внутри домена показан на Рисунке 7.
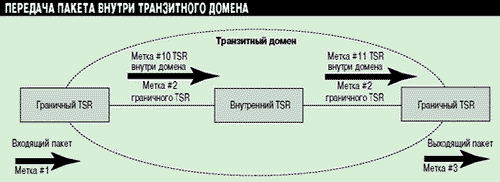
Рисунок 7.
Пакет может содержать не одну метку, а набор (стек) меток.
При маршрутизации группового трафика необходимо построить дерево доставки. Для построения деревьев доставки следует использовать протоколы многоадресной маршрутизации. Каждый TSR для поддержки передачи группового трафика производит формирование отдельных меток в местах "ветвления" дерева доставки, присваивая каждому маршруту свою метку.
Благодаря сходству принципов работы, а именно сходству алгоритмов обмена меток, использующихся в TSR и в коммутаторах ATM, последние могут быть дополнены механизмом Tag Switching. При этом коммутаторы ATM для получения маршрутной информации от TSR должны поддерживать протоколы маршрутизации 3 уровня (EIGRP, OSPF или BGP) и протокол TDP для обмена информацией о метках.
ЗАКЛЮЧЕНИЕ
В Таблице 1 приведены некоторые сравнительные характеристики предлагаемых решений. Несмотря на общность поставленных целей, эти решения довольно сложно сравнивать: необходим обширный анализ конкретной ситуации, при которой применим тот или иной метод. Решающими факторами внедрения того или иного решения могут стать размеры сети, используемое оборудование, финансовая обеспеченность и т. д. Следует отметить, что решения некоторых других фирм-производителей сетевого оборудования также предусматривают поддержку одного из этих методов.
ТАБЛИЦА 1 - СРАВНИТЕЛЬНЫЕ ХАРАКТЕРИСТИКИ IP-КОММУТАЦИИ 3COM FAST IP И CISCO TAG SWITCHING
| 3Com Fast IP | Cisco Tag Switching | |
| Среда применения | Локальные сети | Распределенные сети |
| Метод реализации | Повышение "интеллектуального уровня" конечных устройств | Повышение "интеллектуального уровня" центра сети |
| Метод передачи данных | Коммутация + маршрутизация | Маршрутизация |
| Элементы пути передачи данных | Маршрутизатор по необходимости, коммутатор по возможности | От TSR к TSR |
| Стандарты | Основной - NHRP, дополнительные - IEEE 802.1p/Q и IFMP | В процессе стандартизации |
| Поддержка групповой маршрутизации | IEEE 802.1p/Q, IFMP, DVMRP, MOSPF | DVMRP, PIM |
Максим Владимирович Кульгин - менеджер по проектам компании АйТи. С ним можно связаться по тел.: (812) 185-4988, или через Internet по адресу: m_kulgin@it.spb.ru.