
На смену PCI должны прийти новые архитектуры локальной шины.
В одном из первых номеров LAN на русском языке уже публиковалась статья о шине PCI в разделе «Первые уроки». В том далеком теперь 1995 году это межсоединение периферийных компонентов (Peripheral Component Interconnect, PCI) было еще достаточной молодой технологией (первая версия PCI была принята в 1992, а вторая — в 1993 г.). Тем не менее шина PCI оказалась как нельзя кстати, так как шины EISA и тем более ISA перестали справляться с операциями ввода/вывода ввиду возросшей скорости процессоров и пропускной способности сетей.
Однако с тех пор и скорость процессоров, и пропускная способность сетей возросли многократно, и, несмотря на увеличение тактовой частоты и ширины шины, в свою очередь PCI перестает справляться с возложенными на нее обязанностями, особенно в мощных серверных системах старшего класса. Вместе с тем рост уровня требований к локальной шине привел к тому, что ранее терпимые или несущественные недостатки PCI перестали быть таковыми. Прежде чем переходить к недостаткам, хотя точнее говорить о несоответствии современным требованиям, я хотел бы напомнить основные особенности шины PCI.
КРАТКИЙ ОБЗОР PCI
Как уже говорилось, до появления PCI наибольшее распространение в ПК имели шина ISA и ее усовершенствованная разновидность — EISA. При взаимодействии устройства с процессором (хостом) запросу на обслуживание приходилось проходить через расширительный мост, шину памяти, кэш шины и локальную шину процессора. Все это вело к значительным задержкам при обработке запроса и вводе/выводе. В соответствии же со спецификацией PCI, каждое устройство имеет доступ напрямую к локальной шине процессора и шине системной памяти через связующий их мост. Такое решение имеет по крайней мере два преимущества. Во-первых, оно позволяет выполнять по шине несколько операций одновременно, например процессор может забирать из кэша моста данные, в то время как устройство обращается к системной памяти. Во-вторых, оно обеспечивает независимость локальной шины от процессора, так, например, PCI стала использоваться в компьютерах на базе процессоров Alpha.
 |
| Ввод/вывод следующего поколения. Благодаря сочетанию коммутируемой структуры с канальной архитектурой Next Generation I/O обеспечивает более эффективный метод соединения хостов с периферийными устройствами. |
Данные и адресная информация передаются по одному и тому же пути, поэтому передача данных требует как минимум двух циклов шины: одного — для передачи адреса, другого — для доставки самих данных. Однако благодаря поддержке пакетной передачи в режиме владения шиной отправитель может вслед за адресной информацией послать все данные сразу. Об объеме передаваемых данных отправитель и получатель договариваются в начале передачи. Пакетную передачу не может прервать никакое другое устройство, поскольку оно не находится в режиме владения шиной.
Стандартная шина PCI способна поддерживать не более 10 нагрузок или 3-4 слота. Данное ограничение преодолевается за счет включения в ПК нескольких шин PCI. Это достигается с помощью мостов двумя способами: при одном — шина PCI подключается к другой шине PCI, при втором — шина PCI подключается непосредственно к системной шине. Однако обычно сервер на базе ПК имеет не более одного-двух десятков слотов PCI.
PCI поддерживает автоматическую конфигурацию, т. е. автоматическое назначение адресов; проверку четности для данных и адресов; прямой доступ к памяти; Plug-and-Play и т. д.
ОГРАНИЧЕНИЯ PCI
С повышением тактовой частоты процессоров до 500—600 МГц и в ближайшей перспективе — до более 1 ГГц при ширине шины «процессор-память» в 64 бит, с одной стороны, и в связи с возрастанием пропускной способности локальной сети до 1 Гбит/с и появлением высокоскоростных периферийных устройств на базе Ultra3 SCSI и Fibre Channel — с другой, пропускной способности имеющихся реализаций PCI оказывается недостаточно. Так, теоретический предел для 64-разрядной шины PCI на 66 МГц, наиболее производительной из возможных стандартных реализаций, составляет 533 Мбайт/с, к тому же наибольшее распространение имеют шины на 33 МГц, для которых максимум пропускной способности составляет 266 Мбайт/с.
PCI представляет собой шину с разделяемой архитектурой с распределением памяти, иными словами, память совместно используется хостом и устройствами. Разделяемый подход имеет очевидные недостатки, например какое-либо одно периферийное устройство может монополизировать шину, так что другие устройства не будут иметь к ней доступа. Кроме того, шина с распределением памяти затрудняет выявление и изолирование источника сбоя. Хотя это и случается нечасто, драйверы устройств могут повредить соседние области памяти и привести к сбою системы.
Для замены отказавшего устройства или установки нового компьютер придется выключить, так как замена в горячем режиме не поддерживается. Это приводит к незапланированным простоям, чреватым значительными потерями в случае высококритичных систем. Правда, для таких систем компания Compaq предложила спецификацию PCI Hot Plug (иногда порядок слов в термине обратный — Hot Plug PCI). Однако помимо чисто технических ухищрений для полноценной поддержки горячей замены она требует соответствующей модернизации операционной системы, программного обеспечения и драйверов устройств. К тому же, несмотря на стандартизацию, спецификация не получила широкого распространения.
Кроме того, ввиду разделяемой архитектуры протяженность шины весьма ограничена и в случае высоких частот не превышает 90 см и менее. Это предъявляет весьма жесткие требования к компоновке сервера. К тому же, ввиду все большей распределенности вычислений, в частности появления сетей хранения (Storage Area Network, SAN), последнее ограничение оказывается все более неприемлемым.
PCI-X
Осенью 1998 года Compaq, Hewlett-Packard и IBM предложили расширить имеющуюся спецификацию PCI. Получившая название PCI-X, эта спецификация опирается на существующую технологию PCI, но за счет ряда усовершенствований протокола она позволяет значительно увеличить производительность шины: при частоте 133 МГц и ширине 64 бит ее максимальная пропускная способность составляет свыше 1 Гбайт, а именно 1066 Мбайт/с.
Помимо количественных характеристик два главных отличия PCI-X от PCI состоят в использовании межрегистрового протокола (register-to-register protocol) и атрибутивной фазы (attribute phase).
В случае традиционной шины PCI декодирование полученного сигнала на принимающей стороне происходит на протяжении того же цикла, что и отправка. Это налагает очень жесткие требования на время декодирования — в случае шины PCI с частотой 66 МГц оно составляет всего 3 нс. В соответствии же с новым межрегистровым протоколом декодирование производится за отдельный цикл. Такое решение, с одной стороны, упрощает реализацию шины с более высокой тактовой частотой, так как ослабляет ограничения на время декодирования, а с другой — лишь незначительно увеличивает общее число циклов для одной транзакции (так, если в случае PCI операция записи выполняется обычно за девять циклов, то в случае PCI-X она будет завершена за десять циклов).
Кроме того, спецификация PCI-Х вводит новую фазу транзакции — атрибутивную фазу. Передаваемое во время этой фазы поле длиной 36 бит сообщает более подробную информацию о транзакции, чем это предусмотрено прежней спецификацией PCI. В частности, это поле содержит данные об объеме транзакции, порядке транзакций, инициаторе транзакции и др.
Разработавшие спецификациюPCI-X компании представили ее для стандартизации в отвечающую за разработку стандартов для PCI организацию PCI Special Interest Group (PCI SIG). Первые поддерживающие PCI-X системы должны появиться уже в этом году. Однако, как предрекают многие, ей уготована недолгая жизнь — максимум два-три года. Это связано как с присущими ей (как и другим шинам PCI) ограничениями, так и с появлением двух принципиально новых архитектур локальных шин — Future I/O и Next Generation I/O.
FUTURE I/O
Та же троица, что предложила PCI-X, т. е. Compaq, HP и IBM, выдвинула и концепцию призванной прийти на смену PCI архитектуры локальной шины под названием Future I/O. Официально об этой инициативе компании объявили 13 января 1999 г.
В отличие от разделяемой архитектуры шины PCI, когда шина используется совместно всеми подключенными устройствами, Future I/O опирается на коммутируемую структуру или матрицу с прямыми соединениями между устройствами. Как и в любой коммутируемой среде, подключение очередного устройства никак не сказывается на доступной любому из них пропускной способности, а, наоборот, ведет к увеличению совокупной пропускной способности, так как каждое из них имеет свое отдельное соединение.
Первоначально пропускная способность соединений Future I/O будет составлять 1 Гбайт/с в каждом направлении. Как планируется, Future I/O будет применяться для межсоединения процессоров в кластере, подсистем и процессоров в сетях хранения, а также для подключения высокоскоростной периферии и сетей на базе Fibre Channel, Ultra3 SCSI и Gigabit Ethernet.
Ввиду ориентации Future I/O на различные приложения ее разработчики предусмотрели три модели подключения. Первая рассчитана на соединения протяженностью менее 10 м между интегральными микросхемами специального назначения, платами и шасси. Для физического соединения в этой модели используется параллельный кабель.
Вторая модель поддерживает расстояния от 10 до 300 м и служит для организации соединений между серверами в центрах обработки данных. Этой моделью будут использоваться оптические или последовательные медные кабели с дополнительной логикой. Третья модель предназначена для расстояний свыше 300 м. Это достигается за счет применения дополнительной буферизации и логики.
При модернизации коммутатора подходящие к нему каналы можно будет модернизировать по очереди. Так, если коммутатор сможет поддерживать соединения на 2 Гбайт/с в каждом направлении, то часть подключенных устройств можно будет перевести на новые соединения, а часть — оставить на прежних.
Кроме того, благодаря тому, что каждое прямое соединение поддерживает фактически только одно устройство, коммутируемое межсоединение имеет следующие преимущества:
- ? уменьшение электрической нагрузки;
- ? повышение тактовой частоты;
- ? увеличение протяженности соединений;
- ? упрощение изоляции ошибок и сбоев и др.
СЛЕДУЮЩЕЕ ПОКОЛЕНИЕ
Со своей стороны Intel вместе с ее партнерами Dell Computer, Hitachi, NEC, Siemens и Sun Microsystems предложила иную архитектуру шины под названием Next Generation I/O. Как и Future I/O, NGIO базируется на коммутируемой, а не на разделяемой архитектуре.
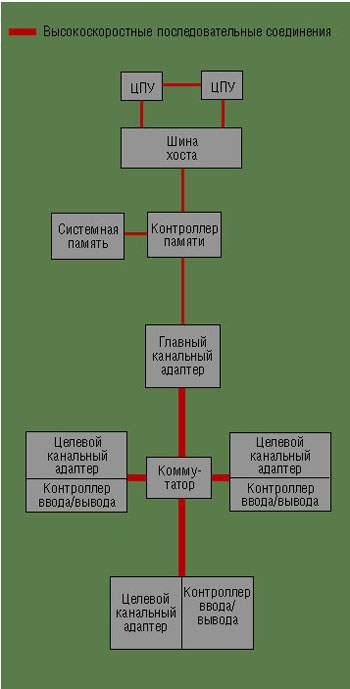
Помимо коммутируемой структуры другим новшеством в NGIO является использование канальной архитектуры — более эффективного механизма ввода/вывода для обработки запросов от периферии. Ранее такого рода архитектура применялась только в мэйнфреймах. Общая архитектура NGIO представлена на Рисунке.
Канальная архитектура NGIO включает главный канальный адаптер (Host Channel Adapter, HCA) и интерфейс с контроллером памяти хоста. Адаптер содержит механизмы прямого доступа к памяти и имеет тесную связь с контроллером памяти хоста. Кроме того, архитектура NGIO также включает целевые канальные адаптеры (Target Channel Adapter, TCA), через которые контроллеры ввода/вывода подключаются к коммутатору. Контроллеры ввода/вывода могут быть адаптерами для SCSI, Fibre Channel и Gigabit Ethernet. Конечно, центральное место в архитектуре занимает сам коммутатор.
HCA и TCA могут подключаться либо к другому канальному адаптеру, либо к коммутатору. В архитектуре NGIO коммутаторы позволяют хостам и устройствам взаимодействовать со множеством других хостов и устройств. Коммутаторы передают информацию между каналами, но сами остаются прозрачны для конечных станций.
Как в I2O, ЦПУ и операционная система освобождаются от необходимости принимать непосредственное участие в передачи данных. Вместо этого контроллеры ввода/вывода наделяются интеллектуальными функциями, с помощью которых они могут осуществлять контроль за тем, как происходит обмен данными по сети между серверами и другими устройствами. Кроме того, каждому из них выделяется свое собственное адресное пространство, при этом контроллер обращается к памяти не непосредственно, а с помощью сообщений.
Каждый канал в системе NGIO передает запросы и ответы в пакетной форме. Эти пакеты состоят из множества ячеек, что несколько напоминает формат ATM. Пакеты передаются со скоростью до 2,5 Гбит/с, при этом канал может иметь протяженность до 17 м. Физический уровень NGIO во многом аналогичен соответствующему уровню Fibre Channel.
Реализация NGIO может привести к изменению самого вида и компоновки серверных устройств. ЦПУ и память могут быть физически разделены с подсистемой ввода/вывода и находиться в разных корпусах в стойке. Это позволит ослабить или вообще снять присущие современным серверам, ввиду недостаточности физического пространства, ограничения на число слотов, ЦПУ, периферийных плат и контроллеров памяти.
Те же преимущества, о которых говорилось в разделе Future I/O как о характерных для коммутируемой архитектуры, остаются справедливы и для NGIO.
СИСТЕМНЫЙ ВВОД/ВЫВОД
Наличие двух схожих по своим возможностям стандартов обычно всегда ведет к проигрышу пользователей, так как им, как правило, приходится поддерживать оба, к тому же разделение рынка препятствует скорейшему снижению цен. Однако в случае коммутируемой архитектуры локальной шины двум противостоящим группам удалось все же договориться о разработке общего стандарта, о чем они и заявили в совместном коммюнике от 31 августа 1999 года.
Новая инициатива пока не имеет своего имени и называется просто «системный ввод/вывод» — system I/O. Как утверждается в заявлении, общая архитектура должна будет заимствовать все лучшее от своих предшественников и предназначается для широкого спектра оборудования — от систем начального уровня до корпоративных центров обработки данных, от традиционного ввода/вывода до кластерных систем. Новая спецификация должна повысить производительность, надежность и доступность соединений между серверами и периферией. Как ожидается, спецификация 1.0 должна появиться уже в конце этого года, а первые ее реализации — в 2001 году.
Дмитрий Ганьжа — ответственный редактор LAN. С ним можно связаться по адресу: diga@lanmag.ru.Ресурсы Internet
Обзор основных возможностей и особенностей шины PCI можно найти в ознакомительной статье «Обзор шины PCI» на http://www.adaptec.com/technology/whitepapers.pcibus.html, а также в статье «Новая шина: кто больше» на http://www.osp.ru/lan/1995/05/15.htm.
Описание технологии PCI Hot Plug приводится на сервере Compaq на странице http://www.compaq.com/support/techpubs/whitepapers/ecg0800698.html, а также на http://mac.croc.ru/products/compaq/ac_pci_hotplug.htm.
Введение в технологию PCI-X имеется на сервере Compaq по адресу: http://www.compaq.com/support/techpubs/whitepapers/ECG0700299.html.
Краткое описание технологии Future I/O приводится на узле ее разработчиков по адресу: http://www.futureio.org/samp/whitepaper.htm.
Ознакомительная статья о Next Generation I/O помещена на http://www.ngioforum.org/events/02991357.html.