
В случае отказа сети передачи данных, какой-либо службы или приложения издержки начинают неуклонно расти, a предприятие не в состоянии продуктивно работать. Чтобы избежать неприятностей, система должна соответствовать определенным требованиям готовности.
 Готовностью ИТ-системы называется время, в течение которого все пользователи в сети могут согласованно обращаться ко всем без исключения имеющимся в ней приложениям и данным. ИТ-системы с высокой готовностью в состоянии реагировать на ошибки без остановки работы, из-за чего и обладают высокой степенью отказоустойчивости. Это достигается путем применения избыточных компонентов, которые при возникновении неисправности поддерживают выполнение всех функций и поэтому минимизируют время отказа. На практике различают два вида системных отказов: запланированные и незапланированные. Действия по наращиванию системы, замене неисправного, но имеющего аналог компонента, обновлению программного обеспечения намечаются заранее, а потому ведут к запланированным простоям. Стихийные бедствия, ошибки конфигурации или дефекты основной платы становятся причиной незапланированных отказов системы. В статье лишь намечаются отдельные шаги и освещаются важные детали, при помощи которых администратор сети сможет повысить время ее безаварийной работы. Первым шагом является целенаправленное организационное и техническое планирование. К тому же очень большое внимание следует уделить осмотру всей системы.
Готовностью ИТ-системы называется время, в течение которого все пользователи в сети могут согласованно обращаться ко всем без исключения имеющимся в ней приложениям и данным. ИТ-системы с высокой готовностью в состоянии реагировать на ошибки без остановки работы, из-за чего и обладают высокой степенью отказоустойчивости. Это достигается путем применения избыточных компонентов, которые при возникновении неисправности поддерживают выполнение всех функций и поэтому минимизируют время отказа. На практике различают два вида системных отказов: запланированные и незапланированные. Действия по наращиванию системы, замене неисправного, но имеющего аналог компонента, обновлению программного обеспечения намечаются заранее, а потому ведут к запланированным простоям. Стихийные бедствия, ошибки конфигурации или дефекты основной платы становятся причиной незапланированных отказов системы. В статье лишь намечаются отдельные шаги и освещаются важные детали, при помощи которых администратор сети сможет повысить время ее безаварийной работы. Первым шагом является целенаправленное организационное и техническое планирование. К тому же очень большое внимание следует уделить осмотру всей системы.
Структурированно описать высокую готовность можно с помощью несколько моделей. Одна из них — обеспечение готовности ИТ-систем за четыре этапа. На первом реализуются только элементарные функции, к примеру сохранность данных. На втором уже вводятся избыточные компоненты аппаратного обеспечения. Осуществляющие контроль активные инструменты управления постоянно выдают информацию о состоянии отдельных компонентов. Кроме того, имеющаяся точная системная документация ускоряет и упрощает администрирование и поиск ошибок. На третьем этапе применяются кластеры и системы массового хранения. Образование логических единиц позволяет частично или полностью ликвидировать одиночные точки отказа. Четвертый, и последний, этап предусматривает дублирование всего центра обработки данных.
ТЕХНИКА В ЗДАНИИ
Отказоустойчивость начинается со зданий и их инфраструктуры. Тщательное планирование инфраструктуры ИТ в соответствии с требованиями отраслевых стандартов и рекомендаций значительно повышает готовность всей системы. Наряду с техническими функциями планировщик обязан принимать во внимание аспекты пожаробезопасности и охраны здания. Проведение организационных мероприятий позволяет четко определить критерии доступа, а также ответственность за серверные и аппаратные. Кроме этого, необходимо разработать план поведения в аварийных ситуациях с описанием последовательности действий персонала, например, при пожаре.
Особую роль играет серверная комната как центральная точка ИТ-системы. Если к отказоустойчивости в ней предъявляются особенно высокие требования, то само собой напрашивается решение о полностью избыточном построении аппаратной. По возможности оба помещения должны быть разделены географически и ни в коем случае не находиться в одном здании.
Даже если серверная комната не выполнена полностью избыточной, ее следует рассматривать как отдельную охраняемую зону с конструктивными мерами предосторожности, позаботившись о наличии запираемых дверей, окон и механизмов контроля доступа.
Более того, специальные сигнальные устройства должны обеспечивать своевременное прибытие охраны или пожарников до того, как оборудование будет полностью уничтожено. Сигнал тревоги подается ими при взломе, пожаре, затоплении или предельном повышении температуры. Работу персонала необходимо организовать так, чтобы сигнал не остался незамеченным. В качестве альтернативы специально назначенному человеку может быть отправлено сообщение по SMS или электронной почте с соответствующим приоритетом о возникших неполадках и проблемах. В зависимости от уровня тревоги это сообщение получают милиция, пожарная охрана или одно из многочисленных охранных предприятий.
ЭЛЕКТРОПИТАНИЕ
Аппаратная должна располагать независимыми электрическими вводами, поскольку энергоснабжение относится к наиболее чувствительным областям инфраструктуры ИТ. В зависимости от желаемой степени готовности в здании и аппаратной могут быть проложены избыточные линии питания. Если прокладка второй линии невозможна из-за отсутствия поблизости второй трансформаторной подстанции, то в этом случае следует установить агрегат аварийного питания. В случае запланированных отключений, например при монтажных работах на электростанции, практикуется аренда мобильного устройства аварийного питания.
Однако, как правило, электропитание не отключается, а происходят колебания напряжения, снижение его до нулевого уровня и — гораздо реже — кратковременные перерывы в электроснабжении. Последствия подобных происшествий, едва ли заметных для пользователя, без соответствующей защиты могут быть разрушительными для ИТ-систем. Система бесперебойного питания помогает предотвратить значительные неприятности. Для определения ее параметров производители предоставляют различные инструменты. При расчетах учитывается оптимальное время работы — как правило, 15 мин — при условии потребления электроэнергии всеми подключенными компонентами. К примеру, Rack Builder от НР предназначен для автоматического расчета таких необходимых величин, как напряжение и ток питания (см. пример расчета в Таблицах 1 и 2).
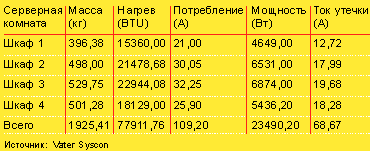
|
| Таблица 2. Пример расчетов при помощи инструмента Rack Buider компании НР характеристик системы бесперебойного питания для конкретного вычислительного центра. |
- защита точки пользования ограничивается точечной защитой одного шкафа;
- централизованная защита предназначается прежде всего для небольших аппаратных;
- зональная защита для более крупных помещений делит всю площадь вычислительного центра на несколько областей.
Возможны также комбинации этих трех методов.
Обычно системы бесперебойного питания обладают аппаратным интерфейсом и программным обеспечением механизмов отключения и управления. При этом различают резервные системы и системы с двойным преобразованием. Первые включаются лишь при колебании или отключении тока при помощи инвертера и берут электропитание на себя. В остальное время работа оборудования поддерживается непосредственно источником питания. Система бесперебойного питания с двойным преобразованием, напротив, постоянно включена и обеспечивает «гладкое» напряжение.
Последние, необходимые для бесперебойной работы компоненты с точки зрения электропитания составляют блоки питания подключенных устройств, как, например, серверов или активного оборудования. В случае высокой степени готовности эти устройства обладают двумя блоками питания для подключения к двум независимым электрическим вводам. Соединение системы бесперебойного питания с серверами и прочими компонентами происходит через распределительные щиты питания (Power Distribution Unit, PDU) (см. Рисунок 1).
ПРОВОДКА
В отказоустойчивости сети проводка играет важную роль. При некачественной проводке высока вероятность некорректной передачи битов из-за отражения, затухания и перекрестных помех. Системы с низкой терпимостью к ошибкам могут отключиться, в то время как системы с высокой терпимостью к ошибкам продолжают функционировать, но уровень выявленных ошибок при этом существенно выше. Построение структурированной проводки должно планироваться и реализовываться на базе стандартов ISO/IEC 11801 и EN50173 и разделяться на области первичной, вторичной и третичной проводок. Первичная проводка между зданиями часто соответствует по своим функциям магистральной линии, при этом топология бывает кольцевой, звездообразной или ячеистой. Отказ работы центрального компонента (единичный отказ) в звездообразной топологии влечет за собой отключение всей первичной области. При кольцевой топологии отказоустойчивость значительно повышается, правда, в местах сопряжения и сращивания может возникать затухание или отражение. Очень высокой отказоустойчивостью обладают ячеистые сетевые структуры, поскольку позволяют создавать множество альтернативных путей.
Вторичная проводка между распределителями на разных этажах реализуется в форме «звезды» или «кольца» по принципу «точка-точка». Это делается для создания распределенной («кольцо») или вырожденной («звезда») магистрали сети. В этом случае можно посоветовать использовать волоконно-оптические линии, а также избыточно проложенные соединения при высоких требованиях к готовности системы.
Третичная проводка, выполненная в форме «звезды», соединяет узловые точки (распределители) на этажах с информационными розетками (для передачи данных).
Чем точнее и актуальнее будет документация, тем меньше вероятность допущения ошибок и быстрее обнаружится потенциальная неисправность.
СЕРВЕР
Серверный парк и непосредственно с ним соединенные компоненты, например библиотеки для резервного копирования или системы хранения данных, являются центром любой ИТ-системы. Наибольший приоритет имеют высокая готовность, избыточность, управляемость и дружественный интерфейс. Значительно уменьшить время отказов серверных компонентов помогут такие свойства хранения, как код коррекции ошибок (Error Correction Code, ECC), оперативный резервный режим памяти (Online Spare Memory Mode, OSMM), зеркальная память с «горячим» подключением (Hot Plug Mirrored Memory, HPMM), а также функциональность «горячей» замены. С помощью кода коррекции ошибок накопитель может выявлять одно- и многобитовые ошибки и исправлять некоторые из них. Сегодня система может не отключаться даже при отказе целой микросхемы. Зеркальная память с «горячим» подключением позволяет обойти все ошибки, выявленные кодом коррекции ошибок. Более того, можно извлечь платы памяти и заменить неисправные компоненты, не прекращая работу сервера. Готовность также заметно повышается, если сервер оснащен массивом RAID с «горячим» подключением, причем RAID в данном случае означает избыточный массив независимых стандартных модулей памяти с двухрядным расположением выводов (Dual In-line Memory Module, DIMM). Более того, практически все ведущие производители серверов применяют жесткие диски, платы расширения, вентиляторы и блоки питания с возможностью «горячей» замены, повышая тем самым готовность во время запланированных и незапланированных отключений. Контроллеры RAID для хранения данных на жестких дисках обеспечивают в соответствии с применяемым уровнем RAID гибко масштабируемую емкость хранения данных с высокой готовностью и устойчивостью к ошибкам.
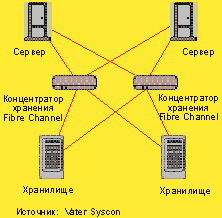
|
| Рисунок 2. Кластер с избыточными компонентами Fibre Channel и системами хранения. |
Наряду с такими привычными для предприятия областями применения, как планирование корпоративных ресурсов (Enterprise Resource Planning, ERP) или управление взаимоотношениями с клиентами (Customer Relationship Management, CRM), кластерные решения играют очень важную роль в приложениях Web. И довольно часто без внимания остается тот факт, что используется только один брандмауэр, когда филиалы соединены с центральным компьютером через виртуальную частную сеть (Virtual Private Network, VPN). Поэтому он становится потенциальной точкой отказа всей системы. Кроме того, и другие применения, не связанные напрямую с деловыми процессами на предприятии, но играющие для него важную роль, например просмотр содержания или защита от вирусов, нуждаются в повышенной отказоустойчивости, которая может быть также реализована на основе кластерной технологии.
СИСТЕМНОЕ УПРАВЛЕНИЕ
Введение проактивного системного управления и проактивного технического обслуживания способствует значительному повышению отказоустойчивости всей инфраструктуры ИТ. Сегодняшние системы аппаратного и программного обеспечения постоянно нуждаются в обновлении, без чего невозможно не только обеспечить требуемую работоспособность и производительность, но и получить поддержку со стороны производителя. Цель проактивного управления состоит в опережающем выявлении и исправлении источников ошибок и пределов производительности. Когда соответствующая система управления контролирует определенные параметры системы через равномерные промежутки времени и постоянно вносит в нее некоторые системные обновления, например заплатки, количество непредвиденных отключений системы уменьшается, и общая готовность повышается.
В случае серверов можно постоянно наблюдать за общим статусом и нагрузкой важнейших компонентов, т. е. процессора, памяти, жестких дисков, вентиляторов и ленточных накопителей. Большую их часть несложно заменить до того, как появившаяся неисправность выведет компонент из строя. Таким образом, время незапланированных отказов уменьшается, а работы по восстановлению планируются на периоды, не являющиеся критическими для работы предприятия.
ПЛАН ДЕЙСТВИЯ В КРИТИЧЕСКОЙ СИТУАЦИИ
При отказоустойчивом построении сети администратор не должен допускать остановки вычислительного центра. Некоторые платформы содержат модели для соответствующих концепций управления. Система от компании Sun, например, разделяет функции работы ИТ-системы на десять областей управления (данные, программное обеспечение, сеть, безопасность, информационно-справочная служба и т. д.) (см. Рисунок 3). Руководитель отдела информационных технологий определяет для них процессы, выполнение которых безусловно необходимо для успешного осуществления предприятием своих функций.
Обязательной частью этой концепции является план действия в критической ситуации. Даже самые полные защитные механизмы не способны защитить от каждой технической проблемы или неосторожных действий, поэтому всегда остается вероятность частичных или полных отказов ИТ-системы. Восстановление работоспособности при определенных обстоятельствах может быть очень сложным процессом и потребовать больших затрат. Заранее продуманные действия обеспечивают, по возможности, наиболее быстрое и полное устранение неполадок. Фундаментом для концепции кризисного плана является тщательный анализ организационного устройства предприятия, его технической оснащенности и состояния ИТ-системы. На основе этих данных можно выявить все без исключения работающие в данный момент приложения, определить приемлемое время потенциального отказа и составить перечень мероприятий, которые должны проводиться во время его устранения. Очень полезное руководство для составления подобного плана представляет собой «Справочник основных приемов защиты ИТ-систем» Федерального ведомства безопасности информационной техники.
Кржиштов Пашке — коммерческий директор компании Vater Syscon. С ним можно связаться по адресу: redaktion@lanline.awi.de.
Ресурсы Internet
«Справочник основных приемов защиты ИТ-систем» Федерального ведомства безопасности информационной техники можно приобрести в издательстве Bundsanzeiger (Кельн) или заказать на сайте http://www.bsi.bund.de/gshb.