
Надежность, высокая доступность, удобство и низкая стоимость эксплуатации всегда были важными характеристиками серверов, обслуживающих критически важные приложения. События последних лет заставили по-новому взглянуть на эти качества корпоративных систем.
Мировая отрасль информационных технологий начинает преодолевать кризис. По прогнозам аналитиков Forrester Research, в текущем году на ИТ будет израсходовано средств на 2,3% больше, чем в предыдущем. Основания для оптимизма дает и статистика продаж. В течение первого квартала отмечался рост мирового рынка серверов. По сравнению с аналогичным периодом прошлого года, их было продано на 10—11% больше — это лучше, чем прогнозировалось, хотя оборот снизился на 3,6%. Таким образом, только за один квартал текущего года мировой парк серверов вырос на 1,22 млн штук.
Предприятия и их информационные инфраструктуры объединяются, эти процессы сопровождаются централизацией управления серверами. В настоящее время около 60% компаний с оборотом более миллиарда долларов имеют централизованные службы ИТ, тогда как в начале прошлого года данный показатель не превышал 20%. Процесс укрупнения компаний, образования холдингов идет и в российской отрасли ИТ, новые структуры вынуждены решать задачи управления большим парком оборудования. По оценкам основных российских производителей серверов, около 50% заказчиков составляют государственные структуры, и 25% приходится на крупных корпоративных клиентов.
Задача контроля над расходами на ИТ не только не теряет своей актуальности, но и становится все более острой. При этом основные предложения поставщиков продолжают превышать возможности бюджетов компаний. Кроме того, по оценкам аналитиков, на каждый доллар, вложенный сегодня в информационные системы, через пять лет придется потратить еще 10 долларов, чтобы оплатить работу обслуживающего персонала. По утверждению IBM, темпы внедрения новых технологий и растущая нехватка квалифицированных администраторов приведут к тому, что через несколько лет некоторые компании просто не смогут управлять своими информационными системами. Производители пытаются разрешить проблему разными способами, но идеологии их подходов во многом совпадают.
Принцип получения от информационных систем большего результата с меньшими затратами находит отражение не только в создании новых операционных систем, в частности Microsoft Windows Server 2003. Большинство ведущих производителей серверов развивают концепции, реализация которых позволила бы упростить управление инфраструктурой ИТ, сделать его более дешевым, обеспечить возможности ее расширения, быстрого развертывания систем и удаленного управления.
Производители вынуждены искать новые подходы и предлагать заказчикам привлекательные концепции виртуализации, открытой, прозрачной или адаптивной вычислительной инфраструктуры, самоуправляемых систем. По существу, сегодняшние подходы — это комбинация решений из четырех основных областей: автоматизация развертывания и функционирования систем, повышение их надежности, усовершенствованные средства управления и администрирования, а также виртуализация с целью более эффективного использования ресурсов.
АДАПТИВНАЯ ИНФРАСТРУКТУРА HP
Различные попытки реализации схем предоставления ресурсов по мере необходимости с оплатой по факту их использования (Computing on Demand, Capacity on Demand и Access on Demand) с 1999 г. предпринимались HP и впоследствии поглощенной ею Compaq для высокопроизводительных серверов и систем хранения. В основном идея сводилась к различным финансовым схемам, чтобы заказчики, у которых есть собственные центры обработки данных, могли платить лишь за реально востребованные ресурсы. Например, вслед за IBM в августе прошлого года было представлено решение Temporary instant Capacity On Demand (TiCOD) для серверов семейства PA-RISC и AlphaServer, суть которого состоит в возможности подключать и оплачивать дополнительные процессорные мощности на требуемое время.
Анонсированная в декабре 2001 г. корпорацией Compaq «адаптивная инфраструктура» была нацелена на повышение рентабельности и эффективности предлагаемых решений. Для этого предполагалось создать инфраструктуру, легко приспосабливаемую к изменениям, чтобы заказчики могли оптимизировать ресурсы в соответствии с требованиями бизнеса. Сегодня и HP, и IBM активно развивают данный подход. Конечная же цель состоит в реализации так называемых «коммунальных вычислений» (Utility Computing), когда ресурсы предоставляются по принципу коммунальных услуг. В ходе эволюции адаптивной инфраструктуры HP собирается перейти от гибких платформ на основе модульных серверов и систем хранения к оптимизации выделения ресурсов и балансированию нагрузки, виртуализации на уровне серверов, сетей и систем хранения данных. (Похожий подход развивает и Sun в стратегии N1.)
В настоящее время, обладая широким спектром продуктов, HP предлагает для снижения совокупной стоимости владения (Total Cost of Ownership, TCO), повышения управляемости и надежности серверов самые различные решения: аппаратные средства удаленного управления, «клонирование» образа системы для быстрого развертывания большого числа серверов, использование логических разделов внутри ОС для предоставления приложению фиксированных ресурсов, динамическую оптимизацию ресурсов, а также методы повышения отказоустойчивости сервера и развитые средства управления. Многие из перечисленных методов уже стали в отрасли стандартными и широко применяются другими производителями.
С точки зрения адаптивной инфраструктуры больший интерес представляет, пожалуй, виртуализация серверов и систем хранения. В применении к серверам она обычно понимается как создание независимых аппаратных или программных разделов (виртуальных машин) — этот подход был заимствован у мэйнфреймов. В числе его преимуществ — более полное использование ресурсов оборудования, управление нагрузкой и защита системы от сбоя в одном экземпляре ОС или приложения. Таким образом, ресурсы сервера удается адаптировать к разнородной нагрузке и меняющимся требованиям. В RISC-платформах HP предусмотрены фиксированные независимые аппаратные разделы. В серверах серии ProLiant можно организовать программные разделы с помощью ПО VMware одноименной компании или HP Workload Management Pack.
Если VMware создает на одном сервере несколько копий ОС, то ProLiant Essentials Workload Management Pack (WMP) способен обеспечивать работу разнородных приложений в рамках одной ОС с разграничением по ресурсам или консолидировать несколько экземпляров одного приложения (например, предоставить по экземпляру SQL Server разным разработчикам). Кроме того, динамическая оптимизация ресурсов предполагает автоматическое включение в работу новых процессоров для повышения производительности при росте нагрузки и добавление оперативной памяти в «горячем» режиме.
Под виртуализацией понимается также интеграция и консолидация других информационных ресурсов, например систем хранения данных, объединяемых в единый пул. Осуществление на практике концепции виртуализированных серверов и систем хранения позволило бы приблизиться к обеспечению для заказчиков возможности использования вычислительной мощности и емкости хранения данных как потребляемого ресурса, предоставление (и последующая оплата) которого происходит, когда в этом возникает необходимость. Такой подход должен стать составной частью развития более полной виртуализированной инфраструктуры. К реализации соответствующего проекта — Utility Data Center (UDC) для автоматизированного управления ресурсами в центрах обработки данных — HP приступила в мае прошлого года. По мнению специалистов HP, позволяя перераспределять посредством ПО серверные, сетевые ресурсы и ресурсы хранения данных в соответствии с потребностями, UDC повысит эффективность использования ресурсов в центрах обработки данных с 35 до 75%.
Хотя принципы адаптивной инфраструктуры в той или иной мере реализованы в широком спектре предлагаемых HP платформ, сегодня они трактуются более прозаично — как максимально гибкое распределение ресурсов с помощью программных средств для их эффективной эксплуатации. Составной частью концепции стали услуги консалтинга НР по анализу ситуации у заказчика, оценке степени гибкости его инфраструктуры и внесению предложений по ее усовершенствованию.
ПРОЕКТ ELIZA И E-BUSINESS ON DEMAND ОТ IBM
Большинство технологий, направленных на обеспечение непрерывного функционирования сервера, заимствовано из мира мэйнфреймов. Не удивительно, что одну из ведущих ролей в подобных разработках играет именно IBM. В представлении IBM создание открытой, виртуализированной и способной к самоуправлению вычислительной инфраструктуры должно позволить предприятиям привести свои информационные ресурсы в соответствие с требованиями бизнеса в условиях растущей сложности систем и удлинения сроков их внедрения.
Если в концепции HP основной акцент делается на адаптацию инфраструктуры, ее гибкость и способность к изменениям, то IBM уделяет значительное внимание автоматизации операций, хотя в отношении «коммунальных вычислений» подходы компаний очень близки. IBM одной из первых стала работать над концепцией «автономных вычислений». Ее «проект eLiza» (от electronic lizard, т. е. электронная ящерица) ориентирован на системы серии eServer и нацелен на снижение стоимости эксплуатации и администрирования информационных систем нового поколения за счет самооптимизации, самоконфигурирования, самовосстановления и самозащиты (см. Рисунок 1). Этот проект, к реализации которого IBM приступила в 2001 г., представляет собой попытку «научить» серверы и мэйнфреймы реагировать на различные ситуации и системные проблемы без вмешательства человека. Сначала функции самоуправления планируется реализовать для аппаратного обеспечения, микропрограммного кода и операционных систем, а затем распространить их на системы хранения данных и ПО промежуточного слоя. Для реализации подобных автономных вычислений предполагается использовать искусственный интеллект, в том числе создать обучающиеся алгоритмы для перераспределения ресурсов в случае возникновения проблем.
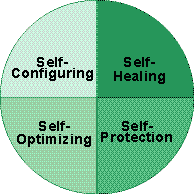 | Рисунок 1. Самооптимизация, самоконфигурирование, самовосстановление и самозащита — четыре составляющих проекта eLiza. Под автоматической конфигурацией (self-configuring) понимается определение новых аппаратных ресурсов и динамическое распределение ресурсов ОС. Автоматическое восстановление (self-healing) позволяет выявить и локализовать неисправности в работе оборудования или встроенного ПО, |
| минимизировав их последствия. Автоматическая оптимизация (self-optimizing) изменяет конфигурацию оборудования для достижения максимальной производительности системы в зависимости от нагрузки на различные аппаратные ресурсы. Самозащита (self-protecting) обеспечивает защиту системы атак, угрожающих целостности данных и приложений. | |
Рассчитанный на несколько лет, проект обойдется IBM в миллиарды долларов. Эта инициатива даже более амбициозна, чем адаптивная инфраструктура HP, и включает в себя самые разнообразные средства — от различной серверной функциональности до самообновляющихся баз данных, ПО управления и средств безопасности, что затрудняет понимание заказчиками сути уже предлагаемых корпорацией решений. Сознавая это, специалисты IBM постарались привести в соответствие с четырьмя областями проекта eLiza уже реализованные, а также планируемые к выпуску в отдельных линейках серверов функциональные возможности, кратко сформулировав все это на сайте компании (см. врезку «Ресурсы Internet»).
На переднем крае работ по проекту eLiza (теперь он стал частью инициативы e-Business on Demand) — мэйнфреймы и серверы zSeries. Полученные результаты IBM распространяет «сверху вниз» на другие свои платформы, включая Intel-серверы: сервер класса мэйнфрейма x440 с процессором Intel Xeon MP и кластер eServer x335 под ОС Linux. В то же время если HP старается внедрить свою адаптивную инфраструктуру в ориентированные на массовый рынок серверы ProLiant, то проект IBM изначально рассчитан на достаточно мощные системы IBM eServer. Впрочем, на платформах IBM аналогичного класса можно найти сходные с Intel-серверами HP средства: например, микросхемы и платы для энергонезависимого удаленного управления, применение которых позволяет сократить расходы на командировки в компаниях с удаленными офисами на 25—50%.
Сегодняшние результаты проекта eLiza можно разделить на несколько основных областей — это оптимизация использования ресурсов, развитые средства управления и повышения отказоустойчивости, а также виртуализация. Как видим, в общих чертах подходы HP и IBM практически совпадают, различаясь в деталях.
Поддержка динамических логических разделов (Dynamic LPAR), относимых IBM к средствам самооптимизации, реализована теперь в основных серверных платформах IBM, благодаря чему один мощный сервер способен выступить в качестве нескольких виртуальных машин с разными операционными средами и разными вычислительными ресурсами, включая процессоры, системную память, устройства ввода/вывода. Администратор может динамически перенастраивать разделы для выделения ресурсов наиболее требовательным приложениям.
В мае IBM представила новые модели UNIX-серверов pSeries на базе процессоров POWER4+: eServer p690, p655 и p670 с количеством процессоров от 4 до 32. В старших моделях этих систем число поддерживаемых независимых логических разделов ОС (LPAR) увеличено до 32, предусматривается динамическое добавление и отключение ресурсов: клиенты могут активизировать и отключать процессоры по мере необходимости, оплатив право их использования в течение требуемого срока. Подобный подход реализован и в недавно выпущенном сервере масштаба предприятия IBM eServer zSeries 990. Кроме наращивания мощности без отключения системы IBM предлагает клиентам воспользоваться вычислительными ресурсами z990 в своих центрах обработки данных, не приобретая саму машину, т. е. речь идет об услугах аутсорсинга.
Кроме того, в серверах pSeries поддерживается динамическое освобождение таких системных ресурсов, как процессоры и кэш-память второго и третьего уровней или слотов PCI-X. В случае сбоя устройства ОС AIX отключает его, автоматически распределяя задачи между соседними ресурсами. Среди других функций «самоконфигурирования» — автоматическое обновление ПО (BIOS и драйверов), тиражирование инсталляций на распределенные системы (Remote Deployment Manager), память Active PCI, утилиты IBM Director Configuration Wizard. Специализированное бесплатное ПО IBM System Networking, Analysis and Performance Pilot, помогает администратору инсталлировать и настраивать сервер в сетевой среде.
Оснащенные встроенным сервисным процессором системы pSeries отслеживают основные параметры работы и автоматически сообщают о предполагаемой неисправности в сервисный центр IBM, а функция сбора данных по первой неисправности (First Failure Data Capture, FFDC) идентифицирует источник сбоя и помогает определить элементы, нуждающиеся в замене.
Методы автоматизации реализуются в решении e-Business Management Services, с помощью которого технические специалисты компании сумеют обнаружить и устранить возникшие проблемы: необходимо заранее определить, как должна работать система, чтобы при снижении производительности одного из устройств требуемые ресурсы были переключены до возникновения отказа. Для выполнения аналогичных задач предназначено самооптимизирующееся ПО службы IBM Enterprise Workload Manager. Эта автоматизированная система позволяет исправлять ошибки прежде, чем они станут критическими. Как и ПО Electronic Service Agent, оно передает через Internet в сервисный центр IBM журнал ошибок. Встречавшиеся ранее неполадки могут быть устранены путем автоматической отправки исправлений пользователю. В противном случае требуется вмешательство специалиста.
В настоящее время IBM завершает разработку ПО для сбора информации с нескольких серверов, с появлением которого компании смогут быстрее диагностировать неисправности на подключенных к сети компьютерах. Оно поможет администратору выяснить, где именно возникает сбой, проследив цепочку событий. Для этого предполагается создать общий формат хранения данных, получаемых с серверов, а позднее включить в сферу контроля и сетевое оборудование (маршрутизаторы и коммутаторы). Собранная информация будет выводиться на консоль, как это делается в ПО управления IBM Tivoli.
По словам Кирилла Корнильева, генерального директора IBM в Восточной Европе/Азии и России, уже сейчас IBM реализовала в рамках инициативы IBM e-Business on Demand (электронный бизнес с предоставлением информационных ресурсов по запросу) такие возможности, как консолидация серверов, плата за реально используемые ресурсы, наращивание ресурсов по запросу, виртуализация корпоративной инфраструктуры (распределенные вычисления и технологии GRID). Компания намерена работать в двух направлениях: с одной стороны, реализуя более широкие возможности аутсорсинга корпоративной инфраструктуры («коммунальные вычисления»), а с другой — развивая концепции использования «ресурсов по запросу» для владельцев собственных центров обработки данных. IBM дополняет эти предложения консалтингом и сервисом.
КОНЦЕПЦИЯ SYSFRAME ОТ FUJITSU SIEMENS
Вслед за гигантами серверного рынка HP и IBM идею снижения стоимости эксплуатации серверов за счет автоматизации различных функций начинают подхватывать и другие производители. Стратегию под названием SysFrame представила на выставке CeBIT?2003 компания Fujitsu Siemens Computers. Она состоит в разработке серверных платформ, в которых стоимость эксплуатации снижается за счет усовершенствованных средств «самоуправления», а эффективность администрирования серверов удается повысить благодаря «автономным вычислениям». SysFrame сравнивается с реакцией живого организма на изменения внутри себя и в окружающей среде, что вызывает прямые ассоциации с проектом eLiza.
В подходе к оптимизации ресурсов и обеспечению бесперебойного доступа к данным идеология SysFrame очень близка к концепциям HP и IBM, особенно если учесть, что рассматривается она как первый шаг на пути к «коммунальным вычислениям». SysFrame включает в себя такие области, как самоконфигурирование, самоизлечение, самооптимизация систем. Этот подход будет охватывать всю инфраструктуру — от мобильных клиентов до серверов приложений. Стратегию SysFrame компания намерена распространить на все свои серверные платформы, включая серверы платформы Intel (PRIMERGY), SPARC-платформы PRIMEPOWER под управлением ОС Solaris, мэйнфреймы BS2000 и системы хранения. Что касается мобильного доступа (ноутбук, PDA, Tablet PC и мобильные телефоны), то под эту идею подводится автоматический выбор вида соединения (GSM, GPRS или WLAN) с самооптимизирующимся (в зависимости от размера экрана клиента) пользовательским интерфейсом на базе технологии openSEAS. Следующим слоем являются самоконфигурирующиеся фермы терминальных серверов (Citrix Terminal Services). В применении к ним концепция транслируется в быстрое развертывание и восстановление после сбоя. Например, согласно Fujitsu Siemens, ферму из более 200 сверхплотных серверов PRIMERGY BX300 можно развернуть менее чем за полчаса.
На серверах PRIMEPOWER система осуществляет постоянный мониторинг использования системных ресурсов. При превышении порогового значения инструмент управления EventAdmin инициирует изменения в конфигурации, например активизирует дополнительные процессоры. Программное обеспечение VM2000, установленное на серверах BS2000, распределяет ресурсы по логическим разделам, позволяя организовать до 15 виртуальных серверов. При этом речь идет о самооптимизации ресурсов и более детализированном их распределении, чем в случае выделения физических разделов, что дает возможность полнее использовать ресурсы.
Важным шагом в направлении SysFrame стала предложенная ранее Fujitsu Siemens самооптимизация инфраструктуры SAP, названная FlexFrame. Технология FlexFrame проверяет, выполняется ли конкретная служба SAP, необходимая пользователю, и достаточно ли ресурсов, чтобы справиться с дополнительной нагрузкой. При нехватке ресурсов автоматически запускается свободный сверхплотный сервер (blade), на него загружается ОС и приложение SAP. По утверждению Fujitsu Siemens, экономия затрат на оборудование и администрирование по сравнению с традиционными конфигурациями SAP достигает 60%. Теперь FlexFrame стала составной частью SysFrame.
В серверах PRIMEPOWER с процессорами SPARC64 применяются программные (на базе ПО Active Resource Management Technology, ARMTech), физические (PPAR) или расширенные разделы (ХPAR). Последние обладают гибкостью программных разделов при уровне безопасности и отказоустойчивости аппаратных. Они реализуются с помощью плат расширения XBS, интегрируемых с системной платой. Программные разделы (партиции) включены в младшие модели PRIMEPOWER, а расширенные — в старшие модели расширенной архитектуры (XA). Согласно Fujitsu Siemens, такая функциональность ведет к дальнейшему повышению окупаемости инвестиций. Solaris 8 поддерживает динамические аппаратные разделы с «горячим» добавлением или удалением системных плат.
В конце мая Fujitsu Siemens представила семь новых моделей серверов PRIMEPOWER с процессорами SPARC64 V собственной разработки и производства, конкурирующих с RISC/UNIX-серверами Sun, IBM и HP. В них реализованы многие средства, заимствованные из технологии мэйнфреймов, — автоматический повтор инструкций (что отличает серверы PRIMEPOWER от систем такого же класса других производителей), автоматическое реконфигурирование системы (выключение отказавших элементов — процессоров, памяти и плат PCI), расширенные средства управления XSCF с аппаратным контролем (предупреждение о сбоях и локализация неисправностей), дублирование памяти и части кэша. По данным Fujitsu Siemens, диагностика и коррекция ошибок кэша вкупе с автоматическим повтором инструкций снижают до 98% вероятность «мягких» ошибок — случайных сбоев в процессорах (с увеличением числа транзисторов в современных процессорах возможность подобных сбоев заметно выросла). Администратор может удаленно получать информацию о конфигурации, отчеты об ошибках, включать питание и перезагружать систему. Центр удаленной поддержки REMCS предоставляет клиентам услуги по круглосуточному мониторингу состояния оборудования, корректируя неисправности по сети или на местах. Данный подход очень близок к тому, что предлагает сегодня компания IBM. Кроме того, подобно IBM, Fujitsu Siemens предусматривает возможности наращивания вычислительной мощности по запросу (подключение клиентом процессоров по мере необходимости), хотя в России эта услуга широко не продвигается, а предоставляется по индивидуальным запросам клиентов.
Функции упреждающего обнаружения и анализа (Prefailure Detection and Analyzing, PDA) позволяют заблаговременно оповестить администратора о скором отказе жестких дисков и вентиляторов и применяются во многих современных моделях оборудования. Этими средствами мониторинга оснащаются серверы PRIMERGY платформы Intel. Состояние компонентов отображается в интерфейсе поставляемого с ними ПО ServerView. Подобно HP с ее концепцией адаптивной инфраструктуры, компания включила в SysFrame и такие испытанные средства повышения надежности серверов, как кластеры различных конфигураций, которые могут собираться из различных модулей в соответствии с требованиями заказчика. Отказоустойчивость достигается также за счет избыточных связей между сервером и системой хранения, зеркалирования данных на две независимые системы хранения. В основе решений Fujitsu Siemens — серверы PRIMEPOWER и PRIMERGY, ПО PRIMECLUSTER, Multipath и Duplex Data Manager.
SUN N1: «ДИНАМИЧЕСКОЕ ПРЕДПРИЯТИЕ»
Осенью прошлого года Скотт Макнили, президент и главный исполнительный директор Sun Microsystems, представил новую стратегию распределения и управления корпоративными ресурсами, которая получила название N1. Согласно ей, серверная система будущего должна представлять собой динамическую совокупность вычислительных ресурсов, систем хранения данных и сетевых компонентов, используемых по мере необходимости. Если «коммунальные вычисления» и «предоставление ресурсов по запросу» предусматривают покупку не востребованной в обычной ситуации избыточной мощности в ожидании пиковых нагрузок, то в основе N1 лежит метод балансирования нагрузки и организации пула ресурсов.
N1 пока не отличается гибкостью и предполагает виртуализацию отдельных моделей серверов Sun и систем хранения. Конечная же цель состоит в поддержке широкого спектра ОС (Solaris, Linux и Windows) и архитектуры Sun (платформ x86-32 и SPARC). Стратегия N1 стала ответом Sun на архитектуры распределенных вычислений IBM и HP, т. е. компания пытается на новом уровне воплотить в реальность свой подход «компьютер — это сеть». На первом этапе N1 предполагает виртуализацию, т. е. создание пула ресурсов в центре обработки данных, на втором — отображение на этот пул ресурсов приложений и сетевых служб, а на третьем — динамическое управление системной политикой, что вызывает ассоциацию с политикой IBM по обеспечению надежности инфраструктуры (policy based orchestration) на основе доступности, безопасности, оптимизации и управления.
В уже анонсированном Sun программном продукте N1 Provisioning Server 3.0 Blades Edition для виртуализации ресурсов используются технология, приобретенная Sun в прошлом году у компании TerraSpring, и собственные разработки Sun. ПО позволяет управлять сверхплотными серверами как одной системой, конфигурировать серверную стойку для инсталляции ОС и настраивать в ней конфигурацию коммутаторов и маршрутизаторов. Наряду со встроенными коммутаторами предусматривается управление внешними коммутаторами, соединяющими серверы на канальном уровне. Кроме отдельных модульных SPARC-серверов SunFire Blade с ОС Solaris 8 можно управлять и стойками с набором таких систем. Само ПО N1 Provisioning Server выполняется на специализированном сервере в сети с управлением по дополнительному каналу. N1 Provisioning Server обеспечивает возможности динамического добавления, масштабирования, реконфигурирования и удаления серверов.
ПО N1 Provisioning Server 3.0 Blades Edition включает в себя N1 Blades Starter Pack и N1 Blades System. Наряду с виртуализацией модульных серверов основное назначение продукта — автоматизация развертывания и настройки конфигурации серверов, межсетевых экранов, средств распределения нагрузки и сетевых ресурсов, чтобы можно было получить единую интегрируемую систему, объединяющую необходимые вычислительные, сетевые ресурсы и системы хранения.
Для мониторинга и управления отдельными элементами в рамках N1 предполагается использовать уже реализованные продукты iChange (тиражирование на серверы «образов» ОС для быстрого развертывания), Sun Management Center (систему управления для обновления ПО и аудита изменений в настройках системы и хранимых в ней данных). Планируется включить в нее и Sun ONE Grid Engine (распределенное ПО для объединения вычислительной мощности компьютерных систем, серверов и рабочих станций).
Кроме того, в феврале Sun анонсировала технологию виртуализации систем хранения N1 Data Services и внедряет ее в информационных центрах некоторых своих заказчиков. Новый пакет услуг N1 services for Blades помогает развертывать платформы нового поколения с помощью продукта N1 Provisioning Server 3.0 Blade Edition.
Как и SysFrame от Fujitsu Siemens, N1 от Sun — сравнительно новая концепция, и, пока не ясно, насколько далеко компании удастся продвинуться в ее реализации.
С НЕБЕС НА ЗЕМЛЮ
Спустя два десятилетия разработчики переходят от исследования технологий самомониторинга и самоизлечения систем к попыткам обоснованного выбора подобных технологий, их проверки и внедрения в реальных решениях. Активные разработки и теоретические изыскания уже принесли некоторые практические результаты, но для достижения заявленных целей придется пройти еще немалый путь.
Подходы IBM, HP и Sun роднит и принцип виртуализации ресурсов, хотя в этом направлении работает и ряд других производителей — разработчики ПО (виртуализация серверов) и устройств хранения. Виртуализация устройств от разных производителей предполагает, что заказчики смогут использовать ресурсы как единый пул. Такой пул должен строиться на основе открытых стандартов и тесно увязываться с бизнес-процессами. Несмотря на попытки создания открытых решений, предлагаемые сегодня схемы виртуализации ограничиваются в основном оборудованием одного поставщика (хотя IBM, начинающая в июле поставки ПО виртуализации Total Storage SAN Volume Controller и SAN Integration Server, намерена уже в этом году добиться поддержки систем хранения других компаний). Необходимо более тесное сотрудничество производителей или развитие новых подходов. Важно отметить также, что задачи создания автономных вычислительных систем нередко сочетаются с задачами GRID-вычислений, поэтому некоторые производители (особенно IBM и Sun) согласованно развивают обе инициативы, которые могут стать важным шагом в решении проблем виртуализации.
Задуманные как достаточно смелые концепции, подходы IBM и HP стали в последнее время более практичными. Пытаясь отказаться от глобальности, компании намерены сделать их понятными конкретному кругу заказчиков и преподносят в виде решений, с помощью которых организации могут приспособиться к меняющимся условиям рынка, экономить людские и технологические ресурсы. Это продиктовано самой логикой развития рынка ИТ. В стратегии SysFrame компания Fujitsu Siemens также сделала попытку перевести задачи, поставленные IBM в проекте eLiza, в практическую плоскость.
Многие представленные выше подходы, особенно касающиеся повышения отказоустойчивости систем, не уникальны для перечисленных компаний. В частности, средства консолидации серверов, мониторинга и сообщения о работе системы (Hardware Configuration and System Health) предлагает компания Dell. Функции System Health позволяют на раннем этапе выявить потенциальные проблемы и устранить их до утраты данных. Между тем в большинстве своем развитые функции «автономных вычислений» и «адаптивной инфраструктуры» характерны пока лишь для достаточно мощных и дорогих систем.
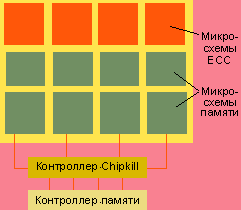
|
| Рисунок 2. Контроллер Chipkill объединяет память в банки по четыре модуля и распределяет каждое слово по всем модулям банка. Выход одной микросхемы из строя ведет к потере одного разряда в каждом слове банка. Данные восстанавливаются с помощью контрольной суммы и алгоритма ECC. Chipkill позволяет применять стандартные модули ECC и поддерживается в наборах микросхем ServerWorks и Intel. |
Сергей Орлов — обозреватель «Журнала сетевых решений/LAN». С ним можно связаться по адресу: sorlov@lanmag.ru.
Ресурсы Internet
Информация об адаптивной инфраструктуре HP представлена по адресу: http://h18004.www1.hp.com/products/servers/ technology/ai/index.html.Сведения о проектах eLiza компании IBM и N1 компании Sun опубликованы по адресам: http://www-1.ibm.com/servers/eserver/introducing/eliza и http://wwws.sun.com/software/solutions/n1.
С описанием концепции SysFrame компании Fujitsu Siemens Computers можно ознакомиться по адресу: http://www.fujitsu-siemens.com/atbusiness/1019897.html.
Предложения Dell Computer по увеличению окупаемости инвестиций находятся по адресу: http://www.dell.com/us/en/esg/topics/ products_roi_main_pedge_000_roi.htm.