
Hовое ядро Linux версии 2.6 обладает совершенно новым планировщиком процессов, что значительно повышает производительность и гарантирует надежную работу.
Появление нового ядра было предрешено 22 ноября 2001 г. Линус Торвальдс прекратил все работы над версией 2.4.15 и начал заниматься экспериментальным ядром 2.5.0. Последовавший за тем стремительный процесс разработки завершился выходом нового, заметно улучшенного ядра. В этой статье перечислены все наиболее интересные и важные его свойства, а также их влияние на производительность и надежность операционной системы.
ИСТОРИЯ ЯДРА ВЕРСИИ 2.5
В номере версии ядер Linux цифра после точки показывает, является ли эта версия стабильной или относится к разряду разрабатываемых. Нечетными номерами (в том числе текущим 2.5) всегда обозначаются разрабатываемые версии. Когда ядро «созревает», номер версии повышается до четного числа. Так, например, разрабатываемая версия 2.3 превратилась в стабильную 2.4.
Поначалу разработка ядра продвигалась очень быстро, в него были добавлены многие новые свойства и улучшения. Если Линус вместе с остальными разработчиками были довольны нововведениями, за этим следовало так называемое «замораживание функций» с последующим замедлением разработки. Последняя фиксация дополнений произошла 31 октября 2002 г.
С этого момента новые свойства Линус не принимает, улучшать можно только уже существующие. Как только имеющиеся функции становятся полноценными и почти стабильными, происходит «замораживание кода». Во время такой «заморозки» допускаются лишь работы по устранению ошибок. После завершения разработки Линус Торвальдс объявляет новое ядро стабильным.
На этот раз стабильное ядро будет иметь номер версии 2.6.0. Хотя об официальной дате выпуска всегда говорилось только, «когда все будет готово», выход можно ожидать в III или IV квартале 2003 г. В марте 2001 г. и июне 2002 г. проводились конференции разработчиков нового ядра операционной системы. Главной целью версии 2.5 являлась адаптация устаревшей системы блочного уровня — части ядра, ответственной за блочные устройства, — к требованиям XXI столетия. Другие разработчики придавали большое значение масштабируемости, малому времени реакции и виртуальным устройствам хранения.
Команда разработчиков решила все поставленные задачи, а некоторые даже перевыполнила. Важнейшими улучшениями по сравнению с предыдущей версией являются:
- усовершенствованный планировщик О(1);
- ядро с приоритетным прерыванием;
- уменьшение времени ожидания;
- обновленный уровень блочных устройств;
- улучшенная подсистема виртуальной памяти;
- улучшенная поддержка потоков;
- новый звуковой уровень.
Чтобы узнать, кто занимался разработкой каждой из этих функций, мы рекомендуем взглянуть на список рассылки по ядру Linux.
ПЛАНИРОВЩИК ПРОЦЕССОВ
Программа управления процессами (более известная как планировщик) — часть ядра, отвечающая за распределение времени центрального процессора между отдельными задачами. Планировщик решает, какой процесс и в какое время будет выполняться. Несмотря на кажущуюся легкость, это довольно непростое дело. К примеру, надо решить, какой процесс из длинной очереди должен считаться всегда активным. Если запущено множество процессов, то поиск наиболее важных из них может затянуться. Если несколько процессов должно выполняться одновременно, то ситуация становится еще сложнее. Поэтому улучшение планировщика имело большое значение для разработчиков. Им необходимо было решить три задачи:
- планировщик должен обеспечивать полное планирование О(1). Это означает, что каждый его алгоритм обязан завершать свою работу за четко определенное время, независимо от количества выполняющихся процессов;
- планировщик должен обладать идеальной симметричной многопроцессорной масштабируемостью (Symmetrical Multiprocessing, SMP). В идеале каждому процессору требуется собственное блокирование и собственный список исполняемых процессов, из которого планировщик мог бы выбирать задания (очередь выполнения);
- кроме того, афинность SMP требовалось улучшить. При этом имели место попытки сгруппировать все задачи на определенном процессоре и оставить их там работать. После чего они могут быть переданы другому процессору лишь с целью предотвратить или ликвидировать неравномерности в очередях.
Новый планировщик удовлетворяет всем поставленным требованиям. Первой целью было обеспечение полного планирования О(1), где О(1) означает алгоритм, выполняющийся за жестко фиксированное время. Причем количество запущенных процессов не влияет на продолжительность выполнения задач каждой частью планировщика.
Примером может служить алгоритм, решающий, какая задача должна выполняться следующей, — он должен ставить на первое место задачи с самым высоким приоритетом, которые возможно выполнить за оставшийся отрезок времени.
В прежнем планировщике алгоритм выглядел приблизительно следующим образом:
for (все запущенные в системе процессы) {
выяснить приоритет процесса
if (это процесс с наибольшим приоритетом)x
{
запомнить процесс
}
}
Выполнить запомненный процессПолучается, что очередь проверяется n раз для n процессов. Продолжительность выполнения такого алгоритма О(1) растет линейно вместе с количеством процессов. Новый же планировщик, наоборот, постоянен. Не важно, решаются в данный момент сразу пять или 5000 задач. Время на выбор и выполнение нового процесса неизменно.
В упрощенном виде это выглядит следующим образом.
Выбрать максимальный уровень приоритета, который имеют процессы. Выбрать на этом уровне первый процесс. Запустить его.
Получается, что новый планировщик может выбрать новую задачу, не проверяя все работающие процессы.
Второй целью являлось достижение симметричной многопроцессорной масштабируемости. Это также означает, что производительность планировщика на отдельно взятом процессоре остается неизменной — неважно, сколько еще процессоров используется параллельно. До сих пор производительность планировщика понижалась из-за проблем с блокировкой. Накладные расходы по обеспечению согласованности планировщика и всех его структур данных были слишком высокими, и чаще всего причиной этому была очередь на выполнение. Чтобы обеспечить возможность использования очереди только одним процессором, применяются механизмы блокировки. Однако в таком случае планировщик может выполняться только одним процессором.
Для решения указанной проблемы новый планировщик делит глобальную очередь на несколько более мелких очередей (планировщик с несколькими очередями), определенным образом назначаемых процессорам.
Каждая очередь предполагает отдельный выбор из всех выполняемых задач системы. Когда планировщик выполняется конкретным процессором, последний выбирает задания только из собственной очереди. Поэтому механизмы блокировки больше не представляют помехи, и производительность при повышении числа процессоров не снижается. На Рисунке 1 сравниваются два процессора с глобальной очередью и та же система с разделенными очередями. Слева показана очередь системы версии 2.4, справа — версии 2.5/2.6.
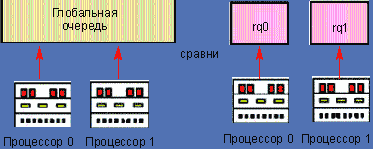
|
| Рисунок 1. Слева — очередь ядра 2.4, справа — новая версия 2.5/2.6. |
Третья цель заключалась в улучшении афинности SMP. Прежний планировщик обладал нежелательным свойством перемещения процессов между процессорами во время их выполнения. В среде разработчиков это явление называется «эффект пинг-понга». В Таблице 1 приведен соответствующий пример.

|
| Таблица 1. Пример «эффекта пинг-понга». |
Новый планировщик решает описанную проблему благодаря новым очередям. Каждый процессор обладает собственным списком задач, поэтому все они остаются на одном и том же процессоре. Этот — улучшенный — вариант представлен в Таблице 2. Конечно же все равно может сложиться ситуация, когда для лучшей балансировки системы процессы необходимо поменять местами. В таком случае собственный механизм балансировки нагрузки перемещает процессы между очередями. Но поскольку подобные ситуации складываются относительно редко, афинность SMP сохраняется.

|
| Таблица 2. Новый планировщик сохраняет афинность процессоров. |
Новое ядро обладает гораздо большим количеством новых свойств, чем может в себя вместить понятие «планировщик». В Таблице 3 показаны результаты тестирования нового планировщика.

|
| Таблица 3. Тестирование сервера поддержки чата: обмен сообщениями между процессами. Результаты в сообщениях/с. |
ВЫТЕСНЯЮЩЕЕ ЯДРО
Так называемое освобождение ядра призвано уменьшить время ожидания. Тем самым увеличивается скорость реакции. Это становится возможным, начиная с версии 2.5.4. Прежде код выполнялся связным образом. Вытесняющее же ядро может заметно сократить время реакции системы за счет того, что даже находящиеся в режиме ядра процессы могут быть прерваны процессами с более высоким приоритетом.
Без вытесняющего ядра процессу с более высоким приоритетом, к примеру текстовому редактору или проигрывателю MP3, приходилось ждать ввода текста пользователем или заполнения аудиобуфера, отчего в большинстве случаев страдала интерактивная производительность. В худшем случае этот процесс как специальный процесс реального времени мог заблокировать всю систему.
Поскольку кооперирующая многозадачность влечет за собой заметные преимущества, почему же не использовать подобное вытесняющее ядро с самого начала? Как видим, разработка подобного ядра требует очень и очень много работы.
Если в любой момент времени задачи в ядре могут планироваться по-новому, то ядро должно обеспечить защиту от одновременного обращения к одним и тем же данным. К счастью, эти задачи схожи с проблемами симметричной многопроцессорной обработки. Механизмы защиты в SMP могут легко быть адаптированы для защиты вытесняющего ядра. Так, ядро просто применяет взаимную блокировку SMP в качестве приоритетной маркировки. Если программа содержит запрет, прерывание не разрешено. В любом другом случае работающая задача может быть прервана.
Вытесняющее ядро сокращает также время ожидания планировщика. Снижение длительности блокировки, соответствующей сроку, за который отключается освобождение ядра, было достигнуто при помощи оптимизации алгоритмов ядра. Тем самым стало возможным сокращение времени ожидания до величины менее 500 нс.
НОВЫЙ БЛОЧНЫЙ УРОВЕНЬ
Блочный уровень — большая часть ядра, отвечающая за управление блочными устройствами. Традиционные системы UNIX поддерживают два типа аппаратного обеспечения: символьные и блочные устройства. Первые, например клавиатура или последовательный порт, обрабатывают поток данных «поштучно». Блочные же устройства обрабатывают данные группами фиксированного объема (в размере одного блока). При этом они не только посылают и получают потоки данных, но могут также переходить от одного блока к другому и выполнять поиск определенных блоков.
Типичными блочными устройствами являются жесткие диски, дисководы DVD и CD, а также ленточные накопители. Обращение с подобными устройствами — отнюдь не тривиальная задача. Жесткие диски, к примеру, — очень сложное оборудование, операционная система должна предоставлять им доступ к любому блоку для считывания и записи. Поскольку запросы на поиск могут быть довольно продолжительными, от операционной системы требуется достаточно «сообразительности», чтобы это время минимизировать. Поэтому, начиная с ядра версии 2.5 в Linux, разработчики приступили к полной перестройке блочного уровня. Самыми интересными задачами являлись нахождение гибкой и всеобъемлющей структуры для обеспечения блочных запросов ввода/вывода, отключения промежуточных буферов (bounce buffer) и организации поддержки доступа при вводе/выводе непосредственно к верхним областям памяти, а также подготовка глобальной блокировки запросов на ввод/вывод и нового планировщика ввода/вывода.
До версии 2.5 для нужд ввода/вывода блочный уровень использовал структуру буферного заголовка. Этот метод оказался малоэффективным по многим причинам, однако главная заключалась в том, что блочный уровень во многих случаях должен был разделить свои структуры данных на более мелкие части лишь для последующей повторной реконструкции.
Ядро версии 2.5 использует для предоставления доступа к устройствам ввода/вывода новую упрощенную структуру. Она подходит как для буферизированного, так и для небуферизированного доступа, работает в верхних областях памяти и может быть легко разделена и снова соединена. На блочном уровне реализована именно эта новая структура, что приводит к более простому и чистому коду.
Еще одной проблемой стало удаление промежуточных буферов (Bounce Buffer), необходимых для доступа при вводе/выводе к верхним областям памяти. В ядре версии 2.4 операция ввода/вывода блочного устройства вынуждена лишний раз делать остановку в верхней области памяти. Она является частью области кратковременного хранения, для которой ядро должно обеспечить особую поддержку. На машинах х86 — это область памяти за пределами 1 Гбайт.
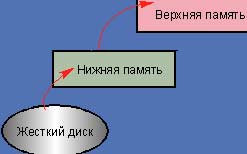
|
| Рисунок 2. Промежуточный буфер ядра версии 2.4. |
Теперь ядро версии 2.5 поддерживает непосредственное перемещение данных в верхнюю область памяти, при которой промежуточные буферы больше не применяются. Это действительно только для устройств, допускающих подобную адресацию.
Еще одно узкое место, ликвидацией которого занялись разработчики, — глобальное блокирование запросов на ввод/вывод. Каждое блочное устройство связано с очередью ожидания запросов ввода/вывода. Перманентно, когда добавляются драйверы или какой-либо запрос удаляется, ядро обновляет эти очереди. Блокирование запросов на ввод/вывод позволяет избежать одновременного доступа, например изменения блока, когда он заперт. В старом ядре все очереди ожидания запросов защищены одним глобальным механизмом блокировки. Глобальное блокирование предотвращает одновременный доступ к любой очереди и препятствует доступу к каждой отдельно взятой.
Начиная с версии 2.5 глобальная блокировка заменяется детальным механизмом запирания (см. Рисунок 3). С его помощью ядро может изменять несколько очередей ожидания сразу.
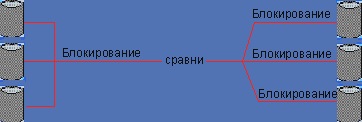
|
| Рисунок 3. Среди новинок в ядре версии 2.5 — «одна блокировка на очередь запросов». |
Новый планировщик ввода/вывода устраняет неэффективность блочного уровня. Он отвечает за объединение блоков данных и доставку их до физических устройств. Поскольку операции поиска достаточно ресурсоемки, планировщик всегда пытается работать только со связными запросами, попутно сортируя приходящие запросы по секторам и тем самым повышая производительность доступа к жестким дискам. Это вело к небольшому недостатку: запросы к следующим друг за другом секторам при доступе к несмежному сектору могли привести к повторным обращениям. Новый планировщик ввода/вывода предотвращает это путем установки временных границ для запросов ввода/вывода. Если планировщик ввода/вывода не получал своевременного ответа на запрос, то он продолжал его ждать и не начинал объединять смежные сектора. В случае доступа для записи все происходит немного по-другому: он имеет более высокий, по сравнению с доступом для чтения, приоритет. После введения всех изменений время ожидания заметно снижено.
УЛУЧШЕННАЯ ПОДСИСТЕМА ВИРТУАЛЬНОЙ ПАМЯТИ
Система виртуальной памяти — это часть ядра, управляющая виртуальным адресным пространством каждого процесса. Она производит запись страниц в область подкачки, когда свободной памяти оказывается слишком мало (так называемая стратегия вытеснения страниц), и снова их считывает (стратегия возврата страниц — возвращение данных, хранящихся в области подкачки). Хорошая скорость виртуальной памяти в большинстве случаев также означает, что прочие программные части работают с относительно низкой производительностью. Создание простой и хорошо сбалансированной виртуальной памяти при старом ядре было практически невозможно. Поэтому разработчики ввели три крупных изменения:
- обратное отображение (reverse mapping, rmap) виртуальной памяти;
- заново написанные простые и небольшие алгоритмы;
- тесная интеграция со слоем VFS.
Всякая виртуальная память обладает двумя различными адресами: физическим (адрес реальных страниц в физической памяти RAM) и виртуальным (логический адрес, используемый приложениями). Архитектуры с блоком управления памятью (Memory Management Unit, MMU) позволяют осуществлять удобный поиск физического адреса по виртуальному. Это необходимо, поскольку программы постоянно пользуются виртуальными адресами, а аппаратное обеспечение должно переводить их в физические.
ФИЗИЧЕСКИЕ И ВИРТУАЛЬНЫЕ АДРЕСА
Обращение процесса все же гораздо сложнее. Для перевода физического адреса в виртуальный ядру в поисках желаемого приходится проверять все записи на странице, что занимает достаточно много времени. Обратное отображение виртуальной памяти предоставляет карту, в которой уже перечислены все эти адреса (см. Рисунок 4). Кроме того, многие алгоритмы виртуальной памяти написаны заново и упрощены, благодаря чему новая виртуальная память стала гораздо быстрее. Дополнительно была улучшена интеграция между виртуальной памятью и VFS.
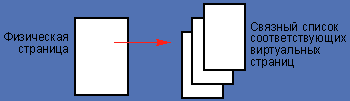
|
| Рисунок 4. При обратном отображении физическая страница отображается на одну или несколько виртуальных. |
Прочие пункты можно отметить лишь вскользь, наиболее важные из них следующие:
- упрощение перезаписи и предварительного считывания файлов и страниц памяти, а также управления буфером;
- поток ядра в dflush был заменен на пул потоков ядра pdflush. Новые потоки позволяют более эффективно использовать жесткий диск, а код ядра теперь гарантирует одновременное насыщение до 60 дисков.
ПОДДЕРЖКА ПОТОКОВ
Поддержка потоков в Linux всегда выглядит несколько громоздкой, как оно и есть на самом деле. Потоковая модель далеко не идеально вписывается в типичную модель процессов UNIX, и поэтому потокам в ядре Linux не слишком комфортно.
Пользовательская библиотека pthread (называемая LinuxThread) хоть и является составной частью glibc, но почти не получает помощи от ядра. Тесное сотрудничество хакеров glibc и ядра привело к ряду значительных улучшений. Результатом стала усовершенствованная поддержка потоков со стороны ядра и новая библиотека pthread под названием Native Posix Threading Library (NPTL), заменившая старую LinuxThread.
NPTL — модель потоковой обработки 1:1. Для каждого пользовательского потока существует поток ядра. Ниже перечислены некоторые изменения:
- поддержка локальных хранилищ для потоков;
- системный вызов О(1) exit();
- расширенный распределитель PID;
- системный вызов clone();
- поддержка дампа кода с учетом потоков;
- потоковая обработка сигнала;
- новый механизм блокировки.

|
| Таблица 4. Создание десяти потоков и удаление одного, пяти или десяти параллельных потоков (время в мкс). |
НОВЫЙ ЗВУКОВОЙ УРОВЕНЬ
В версии 2.5.5. ALSA произошло давно ожидаемое включение звуковой архитектуры Linux (Advanced Linus Sound Architecture, ALSA), она представляет несомненное улучшение по сравнению с предыдущим звуковым уровнем, открытой звуковой системой (Open Sound System, OSS). Наиболее важным отличием стал более мощный API. Драйверы ALSA и относящиеся к ним пользовательские библиотеки (alsa-lib) позволяют использовать объемные аудиоприложения с минимальными затратами ресурсов. ALSA поддерживает большое количество звуковых карт и совместима с интерфейсами OSS. Пользователям, желающим несмотря ни на что работать с OSS, доступна такая возможность и в случае ядра 2.6.
ВЗГЛЯД ВПЕРЕД
Разговор о следующей версии еще до выхода версии 2.6 может показаться преждевременным. С другой стороны, уже сейчас понятно, на что можно рассчитывать в ядре 2.7: если повезет, начнется изменение уровня TTY, поскольку сейчас он превратился в скопление кода чудовищного размера. Неплохо также было бы улучшить уровень SCSI. На данный момент он не слишком «умен» и не очень элегантен. Может быть, получится даже унифицировать большие части уровней IDE и SCSI. В любом случае на этом уровне необходимо навести порядок. Тем, кто интересуется совсем свежими новостями, следует ознакомиться с рассылкой, касающейся нового ядра на http://www.tnk.org.
Роберт Лав — специалист компании Montavista Software. Он работает над многими проектами, среди которых — вытесняющие ядра и планировщики.