
В современном мире, где информация и способы ее обработки имеют решающее значение для выполнения бизнес-задач, при создании центра обработки данных важно обеспечить отказоустойчивость, доступность, обслуживаемость и масштабируемость систем.

Вместе с серверным комплексом система хранения данных является главной составной частью вычислительного центра, а потому следует подумать и об ее отказоустойчивости. Систему хранения следует рассматривать не только как дисковые массивы для хранения данных, но и более широко — как комплекс, включающий еще и транспорт ввода/вывода (I/O), методы размещения данных, программное обеспечение для оптимизации транспорта, обеспечения гарантированной доставки, размещения и хранения данных и т. д.
Прежде всего необходимо добиться оптимального соотношения производительности, доступности (надежного хранения и отказоустойчивости) и совокупной стоимости владения при условии максимального соответствия требованиям заказчика (см. Рисунок 1). Мы рассмотрим способы повышения отказоустойчивости системы хранения в случае сбоев технического и логического характера. Реализация каждого из них по-своему влияет на производительность и стоимость всего центра, а также может повлечь за собой изменения в его структуре. Тема отказоустойчивости в случае природных или техногенных катастроф выходит за рамки данной статьи, наилучшим способом обеспечения непрерывности бизнес-процессов и сохранения данных в таких ситуациях остается построение резервного центра.
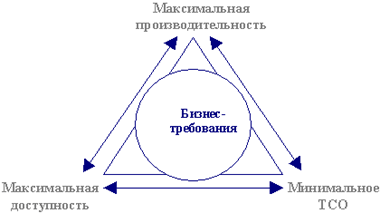
|
| Рисунок 1. Задача построения системы хранения данных. |
Спектр методов повышения отказоустойчивости систем хранения широк: это и дублирование компонентов оборудования, и выбор уровня RAID, и размещение данных с точки зрения файловой системы, и обеспечение надежности транспорта для передачи данных, и встроенные средства приложений.
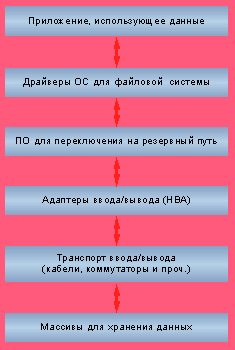
|
| Рисунок 2. Цепочка по транспортировке и хранению данных. |
Как правило, сбои технического характера происходят из-за нарушения функционирования какого-либо компонента центра обработки данных. Несмотря на самое тщательное тестирование оборудования всегда есть вероятность выхода его из строя. Сбои логического характера случаются по причинам нарушения целостности информации вследствие ошибок системного программного обеспечения или из-за неправильных действий персонала.
Цепочка по транспортировке и хранению данных представлена на Рисунке 2, и далее мы рассмотрим, каким образом можно снизить риски отказа на каждом этапе этого процесса.
ПОВЫШЕНИЕ ОТКАЗОУСТОЙЧИВОСТИ МАССИВОВ
Повышение отказоустойчивости дисковых массивов может быть достигнуто полным или частичным дублированием компонентов оборудования. За последнее время никаких революционных новаций в этой области не появилось, а само по себе дублирование компонентов применяется практически во всех типах оборудования ИТ. Естественно, подобные решения предлагают все производители дисковых массивов, однако полное дублирование (системы, где дублируются все компоненты) реализовано лишь в некоторых продуктах, поэтому к их выбору нужно подходить очень внимательно.
Системы хранения данных отчасти являются аналогами вычислительных систем, т. е. массивы большой емкости имеют не только «полки» с дисками, но и ряд других компонентов:
- систему ввода/вывода, которая, в свою очередь, может содержать как порты (SCSI, SSA, FC, FCIP, iSCSI и проч.), так и интеллектуальную составляющую, т. е. процессоры и память для управления производительностью, полномочиями доступа к данным с точки зрения, например, коммутации Fibre Channel, функциями взаимодействия между массивами и др.;
- дисковые контроллеры, или, как их чаще называют, контроллеры RAID; они могут включать в свой состав более одного процессора и немалое количество памяти для кэширования при записи и/или чтении, а также каналы доступа к дискам;
- внутренние коммутационные компоненты.
Очевидно, что чем больше из вышеперечисленных компонентов продублировано, тем выше отказоустойчивость самого массива как аппаратной составляющей системы хранения. Влияние дублирования разных компонентов на стоимость массива различно. Например, дублирование блоков питания не приведет к ее резкому увеличению, однако дублирование контроллеров RAID или, скажем, внутренних коммутационных компонентов заметно повлияет на цену. Поэтому задачи повышения отказоустойчивости зачастую проще и дешевле решаются установкой нескольких независимых массивов либо средствами операционной системы, специализированного программного обеспечения или приложений.
В массивах старшего и среднего класса все перечисленные компоненты дублируются, поэтому их функционирование не зависит друг от друга с точки зрения отказоустойчивости (т. е. в случае отказа, например, процессора или блока памяти, пакеты данных направляются на другой процессор или блок памяти внутри массива). В массивах среднего и младшего класса эти компоненты объединены аппаратно в один модуль (и ввод/вывод, и контроллер RAID). В случае отказа любой его части — модуля памяти или порта ввода/вывода — блок целиком будет выведен из эксплуатации, и отказоустойчивость дискового массива сразу резко понизится, так как все его компоненты окажутся непродублированными.
Следует также отметить, что дублирование любых компонентов не влияет на производительность систем хранения.
«ВНУТРЕННИЙ» ФУНКЦИОНАЛ МАССИВОВ
Кроме повышения отказоустойчивости путем организации дисковых групп (RAID 5, RAID 10 и др.), т. е. за счет избыточности, у некоторых систем хранения имеются так называемые «внутренние» возможности. У разных производителей они называются по-разному, но их можно свести к нижеследующей классификации.
Мгновенная копия (Cloning). Принцип работы схож с тиражированием, т. е. в некий момент времени имеются две синхронизированные области данных, затем, после изменения оригинальной области внутри массива, создается журнал транзакций, в соответствии с которым вносятся изменения во вспомогательную область, чем достигается идентичность хранимой информации. Связь между двумя областями можно разорвать когда угодно и получить независимую копию, правда, в этом случае уже нельзя гарантировать согласованности данных. Например, в базе данных Oracle не все данные сразу размещаются на диске, но взамен можно работать с журналами (redolog) или перевести базу данных в состояние, когда данные принудительно записываются на диски. Мы получаем копию данных, которую можно поместить на ленточные устройства или сохранить в другом массиве. Ее же можно использовать и в случае ошибки технического характера. Но это уже, скорее, относится к вопросу доступности и сохранности данных.
Мгновенный снимок (SnapShot). Идея практически идентична мгновенной копии, только вспомогательная область, куда производится дублирование информации, отсутствует, а вместо этого записываются изменения, произошедшие с какого-то момента. С одной стороны, мы получаем существенную экономию места, а с другой — возможность «отката» до состояния на тот момент, когда производились снимки. Это позволяет скорректировать логические ошибки, если таковые возникли в период после выполнения одного из снимков. Метод более всего подходит для защиты от сбоя логического характера, так как при аппаратной неисправности информация, естественно, будет потеряна.
Удаленная синхронизация данных (Remote Mirror). Средствами массива без вмешательства персонала и независимо от серверов данные постоянно пересылаются на рядом стоящий или удаленный массив, например через FICON или Fibre Channel. В результате можно всегда иметь актуальную копию данных в другом месте, а в случае полного отказа одного массива появляется возможность быстро перевести серверы на работу с теми же данными, но находящимися на другом (других) массиве. Решение работает по тому же принципу, что и кластер высокой готовности в серверной технологии. Вопрос о согласованности данных частично решается регламентами и процедурами с учетом конкретного приложения и способа организации самой файловой системы.
Следует заметить, что организация дисковых групп RAID 5, RAID 10 и т. д. потребует дополнительных затрат. При этом, например, применение RAID 5 приведет к существенному снижению производительности системы до недопустимого для поддерживаемых приложений уровня в связи с дополнительными вычислениями (например, в системах биллинга с большим числом абонентов).
ОТКАЗОУСТОЙЧИВЫЙ ТРАНСПОРТ
В любых типах систем хранения данных существует набор компонентов, который обеспечивает передачу данных между дисками массивов и серверным аппаратным обеспечением. К транспорту ввода/вывода обычно относят кабели (SCSI, Fibre Channel и др.), оптические коммутаторы и другое оборудование, необходимое для передачи данных в рамках существующей системы ввода/вывода. Различия транспорта в зависимости от типа системы хранения будут рассмотрены ниже.
Direct Attached Storage (DAS). В напрямую подключаемых к серверам системах хранения транспорт реализуется по схеме: адаптер шины (Host Bus Adapter, HBA) -> соединительный кабель -> ввод/вывод устройства хранения. В этом случае возможно дублирование всего I/O, т. е. установка второго адаптера и использование одного массива хранения данных с дублированным модулем ввода/вывода или двух массивов, между которыми необходимо синхронизовать данные, например с помощью специализированного ПО.
Network Attach Storage (NAS). В специализированных файловых серверах IP можно задействовать средства сетей IP для повышения отказоустойчивости транспорта и средства массива для избыточного хранения данных. Преимущество решения в простоте управления и применении уже имеющейся структуры сетей IP, что не требует дополнительных затрат. Однако недостатками являются низкая отказоустойчивость самого транспорта и низкая же скорость — по сравнению с SAN.
Storage Area Network (SAN). Отказоустойчивость транспорта можно повысить несколькими способами. Наиболее распространенный — построение двух полностью независимых транспортных контуров с коммутаторами, кабелями и независимым электрическим питанием. Другой способ заключается в установке коммутаторов, отказоустойчивость которых обеспечивается на уровне электрического оборудования (наличие двух внутренних шин для коммутации независимых модулей ввода/вывода, раздельные контуры электрического питания и проч.).
Fibre Channel. Вышесказанное справедливо и при использовании Fibre Channel в качестве транспортного протокола для передачи данных, но существуют ограничения на протяженность такой сети. Решение на базе Fibre Channel считается классическим, однако оно достаточно дорого.
iSCSI. Этот относительно новый протокол расширяет SCSI на сети IP. По сравнению с Fibre Channel ограничений на дальность не возникает, но, естественно, сразу проявляются проблемы, присущие сетям IP. Отказоустойчивость реализуется теми же средствами, что и в сетях IP. Кроме того, к недостаткам следует отнести малое количество LUN на канале SCSI. Оборудование либо представляет собой специальные шлюзы в протокол iSCSI, либо целиком, начиная от карт и заканчивая массивами, совместимо с iSCSI. Хочется отметить, что HBA с поддержкой iSCSI пока далеки от совершенства, так как использование программно реализованных драйверов для сетевых адаптеров («программные HBA») приводит к заметному снижению производительности серверов и низкой производительности ввода/вывода в целом, а аппаратные HBA еще недостаточно широко представлены на рынке.
FCIP (Fibre Channel поверх IP). В случае FCIP происходит инкапсуляция протокола Fibre Channel в IP. Соответственно, отказоустойчивость должна обеспечиваться как на участке Fibre Channel, так и далее на FCIP, но уже средствами сетей IP. Этот транспорт также позволяет избежать ограничения на удаленность узлов. Как и в решениях для iSCSI, существуют специализированные устройства — маршрутизаторы/коммутаторы для трансляции Fibre Channel в FCIP и обратно.
Таким образом, повышение отказоустойчивости транспорта влечет за собой заметный рост стоимости оборудования и обслуживания, а также дополнительные затраты на системы мониторинга и управления транспортом и, кроме того, потребность в высококвалифицированном персонале. Вместе с тем, меры по обеспечению отказоустойчивости практически не сказываются на общей производительности системы, а в случае использования коммутаторов директорского класса возможно даже ее улучшение.
ОТКАЗОУСТОЙЧИВОСТЬ СРЕДСТВАМИ ОС
Некоторые проблемы из-за сбоя оборудования могут быть решены на уровне операционной системы или специализированного программного обеспечения. «Программными» решениями повышения отказоустойчивости часто пытаются заменить дорогостоящее аппаратное дублирование — в результате решение удается значительно удешевить, но снижается производительность, появляются скрытые затраты на администрирование и поддержку.
Средства ОС. Протоколирование файловой системы позволяет обеспечить согласованность данных при сбоях в работе массива или каналов связи. Практически все файловые системы имеют эту функцию, однако в случае ее применения для повышения надежности производительность работы с самой файловой системой снижается. Для разных файловых систем и выполняемых задач потери производительности составляют в среднем 5—10%.
Средства приложений. Приложения в данном контексте надо понимать двояко. Прежде всего, это средства обеспечения высокой доступности (High Availability) — программное обеспечение, предоставляющее доступ к одному и тому же ресурсу хранения данных посредством использования разных физических путей. Такое ПО выпускают как независимые разработчики, так и все производители вычислительного оборудования. Во многие операционные системы подобные средства уже интегрированы. Они обеспечивают безотказность транспорта на всем пути от сервера до диска (начиная от адаптеров, коммутационных кабелей, коммутационного оборудования, ввода/вывода массива хранения данных, контроллера RAID и заканчивая внутренней разводкой от контроллера RAID до самих дисков) только при наличии работоспособной аналогичной цепочки. Большинство из них умеет организовывать виртуальные массивы RAID с избыточностью записи, части которого физически находятся на разных массивах.
При другой трактовке — это средства приложений, которые умеют организовывать зеркалирование данных на разные носители (и внутри одного массива, и на разные дисковые массивы).
Использование программных или смешанных решений для повышения отказоустойчивости системы позволяет значительно экономить средства как на начальной стадии — покупке, так и на последующей — управлении и обслуживании. Следует учесть, что при этом будут задействованы вычислительные ресурсы серверов, т. е. требуются дополнительные изменения в серверном комплексе — повышение производительности, например путем добавления процессорной мощности, или, если возможно, выделение отдельных серверов под эти задачи.
ЗАКЛЮЧЕНИЕ
При повышении отказоустойчивости важна проработка решения на каждой стадии и каждом уровне перемещения, размещения и хранения данных. Не всегда самый дорогой вариант обеспечивает решение насущных проблем, иногда он еще и добавляет новые. Любой руководитель службы ИТ ставит перед собой главную цель — построить высокопроизводительную вычислительную систему с высокой степенью отказоустойчивости и при этом снизить как закупочную, так и эксплуатационную стоимость, т. е. стоимость владения. В ходе проектирования и построения правильно сбалансированного комплекса, привлечения компаний с опытом интеграционных решений можно избежать излишних трат и денег, и времени. Компромисс между простотой решения, производительностью и отказоустойчивостью необходимо отыскивать на стадии проектирования и разработки, постоянно корректировать действия исходя из стоимости владения и показателей производительности.
Стоит отметить, что повышение отказоустойчивости в большинстве случаев приводит не только к удорожанию системы, но и к усложнению процесса мониторинга и, как следствие, к более сложному распределению ресурсов и управлению ими. Эти факторы, в свою очередь, ведут к необходимости повышения квалификации обслуживающего персонала, внедрения специализированного ПО, что неизбежно ведет к увеличению эксплуатационных затрат и стоимости владения.
Андрей Узварик — эксперт департамента системных решений IBS. С ним можно связаться по адресу: AUzvarick@ibs.ru.