
Однако в конце 1998 года ведущие производители PVP-компьютеров, - NEC и SGI/Cray Research, объявив о выпуске систем SX-5 и Cray SV1 соответственно, продемонстрировали, что развитие PVP-архитектуры не останавливается. Настоящая статья содержит обзор архитектуры новых суперкомпьютеров NEC SX-5, самых высокопроизводительных на сегодня PVP-систем.
Архитектура PVP — «классика», которой учат студентов во всем мире. Суперкомпьютеры этой архитектуры на протяжении двадцати с лишним лет служат источником архитектурных идей при разработке компьютеров других классов. Векторные операции (правда, с векторами длиной всего 2 элемента) в последнее время активно внедряются в архитектуру микропроцессоров (AMD 3DNow!, расширение системы команд Katmai в Pentium III).
В применениях, требующих высокой пропускной способности оперативной памяти, суперкомпьютеры PVP-архитектуры по-прежнему сильно опережают конкурентов. Типичный пример операций, для которых характерна плохая локализация в кэше и соответственно повышенные требования к пропускной способности памяти, — операции «сборки/разборки» (gather/scatter), в которых обращение циклически происходит к элементам массива A(INDEX(I)), то есть не последовательно.
PVP-системы и по сей день работают в крупнейших отечественных суперкомпьютерных центрах, в том числе, в ИВВиБД (Санкт-Петербург) и ОИЯИ (Дубна).
Краткая история семейства SX
NEC имеет давние традиции производства больших универсальных ЭВМ; достаточно упомянуть выпускавшиеся в 80-х годах мэйнфреймы ACOS. В это же время появились и первые суперкомпьютеры семейства SX. Процессоры в SX-1 имели пиковую производительность 570 MFLOPS. Во второй половине 80-х были разработаны NEC SX-2 со временем цикла 6 нс; пиковая производительность старшей модели SX2-400 составила 1,3 GFLOPS. В 1989 году была выпущена NEC SX-3 с пиковой производительностью центрального процессора около 5 GFLOPS, имевшая до 4 процессоров. Хотя SX-3 по-прежнему сохраняют лидирующие позиции в рейтингах производительности на тестах Linpack, к современному поколению суперкомпьютеров следует относить КМОП-cистемы NEC SX-4 (объявлена в 1995 году) и SX-5.
Суперкомпьютеры различных поколений SX совместимы снизу вверх. При этом архитектуры SX-4 и SX-5 особенно близки. Учитывая, что объем доступной информации о них ограничен и что данных о SX-4 несколько больше, мы будем во многих случаях рассказывать о SX-4, указывая затем на основные отличительные черты SX-5. Автор выражает благодарность Ф. Танненбауму из компании HNSX Supercomputers (http://www.hstc.necsyl.com) за предоставленную информацию.
Следует подчеркнуть, что суперкомпьютеры, как и мэйнфреймы, достаточно долго продолжали использовать ECL-технологию, которая позволяла достигнуть высоких тактовых частот. КМОП-процессоры первоначально характеризовались более низкими частотами. В частности, время цикла в NEC SX-4 составляет 8 нс против 6 нс в SX-2, и лишь в SX-5 время цикла стало меньше (4 нс). Однако эти процессоры по-прежнему уступают SX-3 со временем цикла 2,5-2,9 нс в зависимости от модели.
С точки зрения производительности основным преимуществом КМОП-технологии с самого начала была гораздо более высокая степень интеграции (CБИС в процессорах SX-5 содержат порядка 15 млн. транзисторов). Кардинальное уменьшение числа компонентов, из которых состоит центральный процессор (в предельном случае - одна микросхема), при использовании КМОП-технологии означает минимум внешних соединений, привносящих основную задержку при передаче сигналов. Определяющей становится не традиционная задержка на вентиль, а задержка при передаче сигналов между микросхемами или между платами.
С точки зрения надежности применение КМОП-микросхем, изготавливаемых по отлаженной технологии, тоже дает преимущества перед ECL, не говоря уже об уменьшении числа соединений и компонентов процессора, что также упрощает диагностику неисправностей.
Наконец, КМОП-микросхемы потребляют гораздо меньше электроэнергии. В результате в суперкомпьютерах на их базе возникает не только существенно экономить электроэнергию, но и уменьшить затраты на охлаждение. Благодаря применению КМОП-технологии системы SX-4 стали первыми в мире суперкомпьютерами PVP-архитектуры, работающими с воздушным, а не с жидкостным охлаждением (мы не учитываем здесь минисуперкомпьютеры PVP-архитектуры). Этим свойством обладают и модели SX-5.
Архитектура SX-4 и SX-5
К основным компонентам архитектуры NEC SX-5, как и SX-4, относятся центральный процессор, подсистема оперативной памяти и подсистема ввода-вывода. Данные компоненты объединяются в узлы SMP-архитектуры, которые, в свою очередь, связаны через межсоединение Internode Crossbar Switch (IXS). При этом вся память всех узлов является общей; иными словами, многоузловые модели SX-4/5 обладают архитектурой NUMA.
Центральные процессоры
Каждый центральный процессор в NEC SX-5 состоит из двух основных блоков: векторного и скалярного устройств.
Начнем с векторного устройства, наличие которого как раз и служит обязательным признаком PVP-архитектуры. Аргументы векторных команд располагаются в векторных регистрах. Длина векторного регистра в SX-4 cоставляет 32 элемента. В архитектуре SX имеется 8 операционных векторных регистров (над ними выполняются основные команды) и 64 векторных регистра данных. Последние в основном играют роль своеобразного «векторного кэша». Только часть команд SX-4 работает с этими регистрами, которые могут получать данные из исполнительных конвейеров одновременно с операционными регистрами.
В SX-5 емкость всех векторных регистров, выступающих в качестве программно адресуемого векторного кэша, составляет 144 Кбайт. В большинстве случаев применение векторных регистров позволяет сильно уменьшить трафик при обмене данными между центральным процессором и оперативной памятью.
Исполнительные блоки векторного устройства конвейеризованы. Основные конвейеры в SX-4/5 — блоки сложения/сдвига, умножения, деления и логических операций. Как это характерно для многих PVP-систем, операции над векторами могут выполняться при участии маски, для чего в архитектуре предусмотрено наличие регистров маски.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
В SX-4 векторное устройство содержит 8 блоков, которые являются фактически самостоятельными векторными устройствами и имеют по 4 конвейера вышеуказанного типа. Каждый такой блок сам по себе отвечает архитектуре SX и работает с регистрами длиной 32 элемента.
Все эти блоки соединены между собой через коммутатор. В результате образуется массив из 32 векторных конвейеров, который разбивается на 4 группы по 8 конвейеров в каждой в соответствии с типом выполняемых конвейером операций. Особенности строения ЦП SX-4 позволяют выполнять операции над векторами длиной до 256 элементов.
Группы конвейеров могут работать параллельно, что при одновременном выполнении сложения и умножения над векторами определяет пиковую производительность процессора SX-4 в 2 GFLOPS. Для SX-5 группа содержит уже 16 конвейеров, плюс тактовая частота SX-5 (250 МГц) вдвое выше, чем SX-4; cоответственно, пиковая векторная производительность SX-5 в четыре раза выше - 8 GFLOPS. Если не считать процессор Hitachi S3800, то это, насколько известно автору, самая высокая производительность центрального процессора и среди PVP-систем, и среди микропроцессоров RISC- и «пост-RISC»-архитектуры (то есть с поддержкой VLIW, как в Merced или в российском проекте E2k), как уже действующих, так и еще только анонсированных.
Скалярное устройство SX-4/5 логически выглядит как микропроцессор, наделенный всеми основными чертами современных высокопроизводительных представителей RISC-архитектуры: суперскалярность, внеочередное выполнение команд, предсказание переходов, предварительная выборка данных и т.п.
Известно, что блок-схемы скалярного устройства SX-4 и процессора SGI/Mips R10000 близки, и что NEC является одним из основных производителей этого микропроцессора. Конечно, нельзя сказать, что это «почти одинаковые» процессоры: из 223 RISC-команд SX-4 116 команд - векторные; SX-4 обеспечивает совместимость с SX-2 и SX-3, и т.д.
В SX-4 целые числа могут быть как 32-х, так и 64-разрядными. Для чисел с плавающей запятой применяется стандарт IEEE 754 (как для 32-х, так и для 64-разрядных чисел). Кроме того, в отличие от R10000, SX-4 может работать со 128-разрядными числами с плавающей запятой расширенной точности и с форматами чисел с плавающей запятой, используемыми в PVP-системах Cray и мэйнфреймах IBM. При этом производительность SX-4 не зависит от формата представления, а сам этот формат выбирается при компиляции.
Относительно скалярного устройства SX-5 мы не располагаем данными о схожести его микроархитектуры с SX-4 или R10000, хотя можно предположить, что основные ее особенности сохранены. Кстати, и тактовая частота SX-5 совпадает с максимальной на сегодня частотой R10000. Cоответственно, к пиковой векторной производительности (8 GFLOPS) следует приплюсовать пиковую скалярную производительность. Она равна 500 MFLOPS, поскольку скалярное устройство SX-5, как и R10000, может выдавать два результата с плавающей запятой за такт (сложение плюс умножение).
Известно, что скалярное устройство в SX-5 содержит 64-килобайтный кэш данных и 64-килобайтный кэш команд, а также 128 64-разрядных регистров общего назначения. Все команды выдает на выполнение скалярное устройство, способное декодировать до 4 команд за такт.
Как скалярное, так и векторное устройства SX-5 оперируют с 32-х и 64-разрядными числами с плавающей запятой в формате IEEE. Скалярное устройство SX-5 поддерживает также 128-разрядные числа расширенной точности. В дополнение к форматам IEEE, применение подпрограмм из библиотеки времени выполнения обеспечивает возможности чтения двоичных файлов, содержащих числа в форматах Cray и IBM.
Скалярное устройство SX-5, как, впрочем, и SX-4, кроме 32-х и 64-разрядных целых чисел, работает с 8-ми и 16-разрядными целыми со знаком и без знака.
В составе процессора, кроме основных блоков - скалярного и векторного - можно также выделить интерфейс с оперативной памятью и так называемые коммуникационные регистры. Они служат в первую очередь для обеспечения синхронизации при распараллеливании задач.
Каждый процессор в SX-5 имеет 128 собственных 64-разрядных коммуникационных регистров. Кроме того, каждый SMP-узел SX-5 имеет еще 128 таких регистров. Они являются привилегированными и используются операционной системой. Идея общих регистров для многих процессоров, в том числе используемых для синхронизации, восходит еще к первым многопроцессорным суперкомпьютерам Cray XMP/22 [1], которые cодержали общие для двух процессоров регистры, в том числе семафорные. Всего в SMP-узле SX-5 может быть до 16 процессоров с пиковой производительностью 128 GFLOPS.
Подсистема оперативной памяти
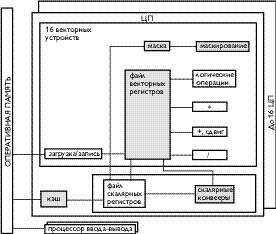 Рис. 1. Архитектура SMP-узла SX-5 |
Подсистема памяти SMP-узлов SX-4/5, то есть «локальная» оперативная память, доступна процессорам через неблокирующийся коммутатор. Применение коммутаторов, которые использовались еще в мэйнфреймах IBM, в SMP-системах высокой производительности стало почти нормой. В качестве примера можно указать, скажем, HP/Convex SPP2000 (серверы класса S) или Sun UltraEnterprise 10000. Преимущества использования коммутации по сравнению с обычной системной шиной обусловлены, как известно, гарантированной пропускной способностью неблокирующихся коммутаторов.
Как и процессоры, оперативная память располагается на отдельных платах. В узле SX-4 каждый процессор имеет порт к коммутатору с пропускной способностью 16 Гбайт/с, так что общая пропускная способность коммутатора 32-процессорного узла составляет 512 Гбайт/с. В узле SX-5 порт памяти к коммутатору обладает пропускной способностью 32 Гбайт/с, и соответственно пропускная способность памяти вдвое выше, чем в SX-4. Если сравнить ее с пропускной способностью коммутаторов/системных шин в наиболее мощных SMP-cерверах (15,3 Гбайт/с в SPP2000, 10,4-12,5 Гбайт/с в Ultra Enterprise 10000), то видно, что пропускная способность только одного порта памяти в SX-4 по порядку величины близка к пропускной способности всей оперативной памяти самых мощных SMP-серверов на базе высокопроизводительных RISC-процессоров.
Такой огромный отрыв и является, с точки зрения автора, основным «аппаратурным» преимуществом современных суперкомпьютеров PVP-архитектуры по сравнению с многопроцессорными cерверами на базе универсальных серийно выпускаемых микропроцессоров.
Если в оперативной памяти SX-4 используется технология SSRAM, то память SX-5 составлена из более дешевых 64-мегабитных микросхем SDRAM. Каждая плата памяти SX-5 может обладать емкостью 4 Гбайт, а весь 16-процессорный узел - до 128 Гбайт. Вся оперативная память разбита на банки. Платы памяти SX-5 умеют обрабатывать запросы к оперативной памяти во внеочередном порядке, что повышает эффективную пропускную способность при наличии конфликтов по обращению к банку памяти.
Конвейерная выдача данных из памяти, поддержка возможности переупорядочения запросов к памяти для уменьшения конкуренции из-за доступа к ней, наличие аппаратных средств, позволяющих скрыть задержки при обращении к оперативной памяти - все это позволяет поддерживать высокую реальную пропускную способность памяти.
Многоузловые модели SX-4/5
Следует проанализировать иерархическое строение оперативной памяти в многоузловых моделях суперкомпьютеров NEC SX-4/5, то есть реализацию архитектуры NUMA. Для этого мы должны сначала рассмотреть коммутатор IXS, соединяющий SMP-узлы в таких конфигурациях.
В SX-4 коммутатор IXS использует пары оптических каналов с пропускной способностью 8 Гбайт/с. Каждый SMP-узел SX-4 связан с парой таких каналов - входным и выходным, работающими независимо. Время межузловой задержки в IXS составляет 3 мкс на кабель длиной 30 м. Узлы могут располагаться на удалении до 200 м друг от друга.
Пропускная способность порта неблокирующегося коммутатора IXS в SX-5 равна 16 Гбайт/с. Половинная пропускная способность, то есть скорость, с которой обмениваются данными две «половины» системы, для 32-узловой системы SX-5 составляет 512 Гбайт/с.
Из-за дополнительных задержек при передаче данных между узлами SX-4/5 обмен данными организован блоками данных, а не отдельными элементами. Это увеличивает эффективность распараллеливания в модели обмена сообщениями. Между тем пропускная способность при обмене данными между SMP-узлами (при доступе в удаленную оперативную память «чужого» узла) находится на уровне «внутренней» пропускной способности наиболее мощных SMP-серверов.
В SX-5 передача данных сквозь IXS может происходить как в синхронном, так и в асинхронном режимах. При этом максимальный размер передаваемого блока данных составляет 2 Кбайт и 32 Мбайт соответственно.
Итак, в многоузловых моделях SX-4/5 имеется два уровня коммутации (не считая коммутатора внутри процессора) и два уровня оперативной памяти. Первый относится к локальной памяти узла, второй - к удаленной памяти других узлов. Доступ к удаленной памяти из-за прохождения данных через IXS медленнее, чем к локальной памяти, однако вся память всех узлов является общей глобально адресуемой. Адрес глобальной памяти включает в себя номер узла, для которого соответствующая физическая память является локальной.
Такая физически распределенная, но логически разделяемая всеми узлами оперативная память отвечает архитектуре неунифицированного доступа к памяти NUMA. Ее не следует путать с архитектурой ccNUMA (cache-coherent NUMA), используемой, в частности, в SGI Origin 2000 и в Sequent NUMA-Q. В отличие от ccNUMA, когерентность кэшей в SX-4/5 осуществляется только для процессоров в пределах одного SMP-узла.
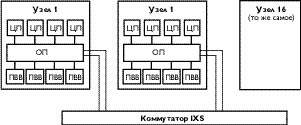 Рис. 2. Общая архитектура многоузловых моделей SX-5 |
В SX-4/5 идет работа с реальной, а не виртуальной памятью. Насколько известно автору, отказ от использования виртуальной памяти в суперкомпьютерах восходит еще к временам Cray-1. Однако в NEC SX-4/5 используется страничная адресация оперативной памяти. Это позволяет программным модулям загружаться в несмежные области физической оперативной памяти, то есть устраняет проблемы фрагментации.
IXS обеспечивает работу с таблицами страниц при глобальной адресации оперативной памяти, с коммуникационными регистрами и командами глобальной пересылки данных.
Отметим также, что SX-4 помимо обычной оперативной памяти может иметь также расширенную память по типу SSD в Cray T90, которая используется ОС SUPER-UX для целей кэширования дисков, свопинга и т.п.
Причины применения расширенной памяти в SX-4 - общие для всех компьютеров, имеющих подобный механизм: основная память, построенная по технологии SSRAM, обладает высоким быстродействием, но дорого стоит. Поэтому ее емкость ограничена и для многих приложений может оказаться недостаточной. В этих случаях и прибегают к использованию более дешевой и более медленной расширенной памяти. В SX-4 в таком качестве задействована обычная память DRAM со временем цикла 60 нс. Емкость расширенной памяти для компактных (до 4 процессоров) SMP-моделей SX-4/C cоставляет до 8 Гбайт, а для моделей с числом процессоров до 32 - до 32 Гбайт; пропускная способность расширенной памяти при этом соответственно 4 и 16 Гбайт/с.
Подсистема ввода/вывода
Основными блоками подсистемы ввода/вывода в NEC SX-4/5 являются процессоры ввода/вывода, впервые появившиеся, насколько известно автору, в CDC 6x00. В отечественном компьютеростроении они впервые использовались, вероятно, при разработке ЕС ЭВМ. Процессоры ввода/вывода разгружают центральный процессор от непосредственного управления вводом/выводом.
В NEC SX-5 пропускная способность процессоров ввода/вывода была увеличена вдвое по сравнению с SX-4 и составляет около 3,2 Гбайт/с. В SMP-узле SX-5 может быть до 4 таких устройств. Каждое из них способно поддерживать работу многих каналов ввода/вывода при наличии соответствующих канальных плат. Основные типы канальных карт в SX-5 - HIPPI-800, FC-AL и SCSI.
HIPPI-800 с пропускной способностью 100 Мбайт/с используется обычно для соединения в локальную сеть и подключения высокоскоростных массивов RAID, в том числе, NEC N7764 и Storage Systems Gen5 XLE, обеспечивающих поддерживаемую пропускную способность 75 Мбайт/с. Для дисковых массивов применяются также каналы Fibre Channel.
Кроме того, поддерживаются два типа каналов SCSI: Ultra SCSI и Fast & Wide в дифференциальном исполнении, которые NEC рекомендует использовать для подключения ленточных накопителей.
Выводы
Результаты тестирования производительности NEC SX-5 на общепринятых тестах (в частности, Linpack, NAS parallel benchmark) пока не публиковались, зато соответствующие данные для SX-4 доступны. Сопоставление этих результатов с данными по Cray T90 показывает, что по производительности эти компьютеры при равном числе процессоров почти равноценны. Поскольку пиковая производительность процессоров SX-5 в 4 раза выше, чем у SX-4, преимущество SX-5 по производительности перед Cray T90 очевидно.
Вплоть до 1998 года основными конкурентами на рынке больших PVP-систем были NEC SX-4 и Cray T90. Однако в прошлом году на смену минисуперкомпьютерам Cray J90 пришли новые системы Cray SV1 с пиковой производительностью центральных процессоров в 4 GFLOPS. Производительность этих устройств вдвое выше, чем у процессора Cray T90, но они все же уступают процессорам в SX-5. Если учесть ограниченные возможности масштабирования Cray T90 - до 32 процессоров, и Cray SV1 - до 32 SMP-узлов с производительностью до 32 GFLOPS на узел, то очевидно, что NEC SX-5 становятся абсолютными лидерами по производительности. SX-5 опережают Cray T90 по емкости и пропускной способности памяти. Лишь пропускная способность ввода/вывода в Cray T9x выше, чем в SMP-системах SX-5.
Суперкомпьютеры NEC ориентированы на решение задач «великого вызова». Речь идет о таких сферах применения, как аэрокосмическая и автомобильная промышленность, задачи энергетики и нефтяной отрасли, предсказание погоды, вычислительная химия и др.
Учитывая большую производительность центральных процессоров SX-5, высокую пропускную способность оперативной памяти и масштабируемость, недостижимые в настоящее время на многопроцессорных суперкомпьютерах на базе RISC-процессоров, можно сказать, что общий кризис PVP-систем NEC миновал. Рекордные показатели, достигнутые американцами на массивно-параллельных системах, построенных на базе серийно выпускаемых микропроцессоров, в том числе, SGI ASCI Blue Mountain и Intel ASCI Option Red, не меняют эту оценку. Подобные системы, во-первых, собраны пока в единичных экземплярах, а, во-вторых, по пиковой производительности они уступают SX-5 в максимальной конфигурации.
Поскольку есть приложения, где производительность важнее соотношения стоимость/производительность, можно предположить, что NEC SX-5 обеспечен высокий уровень спроса, как минимум, в течение нескольких лет. К тому же пока универсальные серийно производимые микропроцессоры не обладают интегрированной поддержкой векторных операций (3DNow! и Katmai, очевидно, не в счет). Причиной тому, по мнению автора, - отсутствие массового спроса на подобные операции. Как бы то ни было, в обозримом будущем эти микропроцессоры вряд ли смогут догнать центральный процессор SX-5 по производительности.
С другой стороны, массивно-параллельные системы на базе серийных микропроцессоров, гораздо более дешевле, чем PVP-системы, прочно заняли ведущие места в таблицах тестов производительности и вытеснили PVP-системы в большинстве суперкомпьютерных центров. По всей вероятности, выпуск новых PVP-систем картины не изменит.
