Эта статья посвящена проблеме обнаружения нового знания в хранилищах данных - (KDD - knowledge discovery in databases) и основному шагу этого процесса - data mining (исследование данных или, дословно, «добыча данных»). После применения традиционных методов увеличения доходов (маркетинговые исследования и действия на рынке, работа с конкурентами) или уменьшения расходов (изменение технологии, работа с поставщиками), перед менеджерами высшего звена встает задача по дальнейшему увеличению прибыли, как основной цели деятельности любого коммерческого предприятия.
Для этого в последнее время был разработан ряд технологий, которые призваны извлекать из хранилищ данных (data warehouse) большого объема новую информацию путем построения различных моделей. Они и получили название data mining. Простой доступ пользователя к хранилищу данных обеспечивает только получение ответов на задаваемые вопросы, в то время как технология data mining позволяет увидеть («добыть») такие интересные взаимоотношения между данными, которые прежде даже не приходили пользователю в голову, и применение которых может способствовать увеличению прибыли предприятия.
Что может data mining?
Большинство организаций накапливают за время своей деятельности огромные объемы данных, но единственное что они хотят от них получить - это информация. Как можно узнать из данных о том, что нужно наиболее предпочтительным для организации клиентам, как разместить ресурсы наиболее эффективным образом или как минимизировать потери? Новейшая технология, адресованная к решению этих проблем - это технология data mining. Она использует сложный статистический анализ и моделирование для нахождения моделей и отношений, скрытых в базе данных - таких моделей, которые не могут быть найдены обычными методами.
Модель, как и карта - это абстрактное представление реальности. Карта может указывать на путь от аэропорта до дома, но она не может показать аварию, которая создала пробку, или ремонтные работы, которые ведутся в настоящий момент и требуют объезда. До тех пор пока модель не соответствует существующим реально отношениям , невозможно получить успешные результаты.
Существуют два вида моделей: предсказательные и описательные. Первые используют один набор данных с известными результатами для построения моделей, которые явно предсказывают результаты для других наборов, а вторые описывают зависимости в существующих данных, которые в свою очередь используются для принятия управленческих решений или действий.
Конечно же, компания, которая долго находится на рынке и знает своих клиентов уже осведомлена о многих моделях, которые наблюдались в течение нескольких последних периодов. Но технологии data mining могут не только подтвердить эти эмпирические наблюдения, но и найти новые, неизвестные ранее модели. Сначала это может дать пользователю лишь небольшое преимущество. Но такое преимущество, если его соединить за несколько по каждому товару и каждому клиенту, дает существенный отрыв от тех, кто не пользуется технологиями data mining. С другой стороны с помощью методов data mining можно найти такую модель, которая приведет к радикальному улучшению в финансовом и рыночном положении компании.
Что не может технология data mining?
Data mining - это набор средств, а не волшебная палочка. Он не находится в базе данных и не посылает электронную почту, когда видит интересную модель. Он не исключает необходимости знания Вашего бизнеса и понимания самих данных или аналитических методов. Этот набор средств помогает аналитикам в нахождении моделей и отношений в данных, но он не говорит о ценности этих моделей для организации. Каждая модель должна проверяться в реальном мире.
Хотя хороший инструментарий data mining и ограждает пользователя от возможных сложностей в применении статистических методов, он все-таки требует от него понимания работы этого инструментария и алгоритмов, на которых он базируется. Кроме этого, технология нахождения нового знания в базе данных не может дать ответы на те вопросы, которые не были заданы. Она не заменяет аналитиков или менеджеров, а дает им современный, мощный инструмент для улучшения работы, которую они выполняют.
Data mining и OLAP
Самый часто задаваемый вопрос, который возникает у профессионалов обработки данных - это вопрос о разнице между средствами data mining и средствами OLAP (On-Line Analytical Processing) - средствами оперативной аналитической обработки.
OLAP - это часть технологий направленных на поддержку принятия решения. Обычные средства формирования запросов и отчетов описывают саму базу данных. Технология OLAP используется для ответа на вопрос, почему некоторые вещи являются такими, какими они есть на самом деле. При этом пользователь сам формирует гипотезу о данных или отношениях между данными и после этого использует серию запросов к базе данных для подтверждения или отклонения этих гипотез. Средства data mining отличаются от средств OLAP тем, что вместо проверки предполагаемых взаимозависимостей, они на основе имеющихся данных могут производить модели, позволяющие количественно оценить степень влияния исследуемых факторов. Кроме того, средства data mining позволяют производить новые гипотезы о характере неизвестных, но реально существующих отношений в данных.
Средства OLAP обычно применяются на ранних стадиях процесса KDD потому, что они помогают вам понять данные, фокусируя внимание аналитика на важных переменных, определяя исключения или интересные значения переменных. Это приводит к лучшему пониманию данных, что в свою очередь ведет к более эффективному результату процесса KDD.
Data mining и хранилища данных
Наличие хранилища данных является необходимым условием для успешного проведения всего процесса KDD. Принципы построения хранилищ - это очень большая тема, заслуживающая отдельной статьи или ряда статей. С ней в полном объеме можно познакомиться в работах Билла Инмона (Bill Inmon). В частности в книге «Building the Data Warehouse» (Построение хранилища данных) Здесь я ограничусь лишь основными принципами построения хранилища данных. Итак, хранилище данных - это предметно-ориентированное, интегрированное, привязанное ко времени, неизменяемое собрание данных для поддержки процесса принятия управленческих решений. Предметная ориентация означает, что данные объединены в категории и хранятся в соответствии с теми областями, которые они описывают, а не с приложениями, которые их используют. Интегрированность означает, что данные удовлетворяют требованиям всего предприятия (в его развитии), а не единственной функции бизнеса. Тем самым хранилище данных гарантирует, что одинаковые отчеты, сгенерированные для различных аналитиков, будут содержать одинаковые результаты. Привязанность ко времени означает, что хранилище можно рассматривать как совокупность «исторических» данных: можно восстановить картину на любой момент времени. Атрибут времени всегда явно присутствует в структурах хранилища данных. Неизменяемость означает, что, попав однажды в хранилище, данные уже не изменяются в отличие от оперативных систем, где данные обязаны присутствовать только в последней версии, поэтому постоянно меняются. В хранилище данные только добавляются.
Для решения перечисленного ряда задач, неизбежно возникающих при организации и эксплуатации информационного хранилища, существует специализированное программное обеспечение. Современные средства администрирования хранилища данных обеспечивают эффективное взаимодействие с инструментарием data mining. В качестве примера можно привести два продукта компании SAS Institute: SAS Warehouse Administrator и SAS Enterprise Miner, степень взаимной интеграции которых позволяет использовать при реализации проекта data mining также и метаданные из информационного хранилища.
Data mining и аппаратное обеспечение
Ключевой возможностью применения технологий data mining стало огромное падение цены за последние несколько лет на устройства хранения информации с десятков долларов за хранение мегабайта информации, до десятков центов. Это существенно удешевило и увеличило возможности сбора и хранения больших объемов информации.
Падение цен на процессоры с одновременным увеличением их быстродействия также способствует развитию технологий связанных с обработкой огромных массивов информации. В результате этого было преодолено множество барьеров стоящих на пути нахождения нового знания в хранилищах информации.
Клиент-серверная архитектура также является необходимым атрибутом технологии data mining. Такой подход предоставляется возможность выполнять наиболее трудоемкие процедуры обработки данных на высокопроизводительном сервере как разработчикам проектов, так и пользователям. На этом же сервере могут храниться и по запросам клиентов выполняться корпоративные проекты data mining.
Применение методов data mining
Методы data mining распространены во многих организациях из-за того, что они могут сделать существенный вклад в увеличение доходов. Эти методы могут использоваться для управления взаимоотношениями с клиентами. Определяя характеристики клиентов, которые могут уйти к конкурентам, компания может предпринимать действия для их удержания, так как сохранить клиента всегда дешевле, чем приобрести нового.
Маркетинг данных - это другая область, в которой активно применяется технологии data mining. Определяя круг кандидатов для рассылки целевой рекламы с помощью методов data mining можно увеличить продажи, при этом уменьшив расходы на проведение такой рекламы.
Применение технологий data mining распространено в широком спектре индустрий. Телекоммуникационные компании и компании, выпускающие кредитные карточки, являются лидерами в применении этих технологий для определения возможных потерь клиентов. Страховые компании и фондовые биржи тоже применяют эти технологии для определения потерь клиентов. Ещё одна область применения методов data mining - это медицина; здесь предсказывается эффективность применения медикаментов, хирургических процедур и медицинских тестов. Компании, действующие на финансовом рынке, определяют рыночные и отраслевые характеристики для предсказания индивидуальных и фондовых предпочтений в ближайшем будущем. Супермаркеты определяют, какие продукты продавать и как их расположить внутри магазина для достижения наибольшего количества продаж. Фармацевтические фирмы используют хранилища данных по химическим соединениям для нахождения таких комбинаций этих соединений, которые в дальнейшем можно будет использовать как лекарства для лечения различных заболеваний.
Ключом к успешному применению методов data mining служит не просто выбор алгоритма, а мастерство человека, который проводит построение модели, и возможности программы проводить процесс моделирования. Информативность реализованного проекта data mining зависит от этих факторов в большей степени, чем от алгоритмов. Существуют две стороны успеха в поиске данных. Во-первых - это четкая и ясная формулировка задачи, которая подлежит решению. Во-вторых - это использование правильных данных. После выбора данных из всех доступных источников (или даже приобретения данных из внешних источников) необходимо их преобразовать или сгруппировать в определенном порядке.
Чем больше аналитик может «играть» с данными, строить моделей, оценивать результаты (то есть больше работать с данными за единицу времени), тем лучше может быть результат. Работа с данными становится более эффективной, когда возможна интеграция следующих компонентов: визуализация, графический инструментарий, средства формирования запросов, оперативная аналитическая обработка, которые позволяют понять данные и интерпретировать результаты, и, наконец, сами алгоритмы, которые строят модели.
Виды моделей
Рассмотрим основные виды моделей, которые используются для нахождения нового знания на основе данных хранилища. Целью технологи data mining является производство нового знания, которое пользователь может в дальнейшем применить для улучшения результатов своей деятельности. Результат моделирования - это выявленные отношения в данных. Можно выделить по крайней мере шесть методов выявления и анализа знаний: классификация, регрессия, прогнозирование временных последовательностей (рядов), кластеризация, ассоциация, последовательность. Первые три используются главным образом для предсказания, в то время как последние удобны для описания существующих закономерностей в данных.
Вероятно, наиболее распространенной сегодня операцией интеллектуального анализа данных является классификация. С ее помощью выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил. Во многих видах бизнеса болезненной проблемой считается потеря постоянных клиентов. В разных сферах (таких, как сотовая телефонная связь, фармацевтический бизнес или деятельность, связанная с кредитными карточками) ее обозначают различными терминами - «переменой моды», «истощением спроса» или «покупательской изменой», - но суть при этом одна. Классификация поможет вам выявить характеристики «неустойчивых» покупателей и создать модель, способную предсказать, кто именно склонен уйти к другому поставщику. Используя ее, можно определить самые эффективные виды скидок и других выгодных предложений, которые будут наиболее действенны для тех или иных типов покупателей. Благодаря этому вам удастся удержать клиентов, потратив ровно столько денег, сколько необходимо. Однажды определенный эффективный классификатор используется для классификации новых записей в базе данных в уже существующие классы и в этом случае он приобретает характер прогноза. Например, классификатор, который умеет идентифицировать риск выдачи займа, может быть использован для целей принятия решения, велик ли риск предоставления займа определенному клиенту. То есть классификатор используется для прогнозирования возможности возврата займа.
Регрессионный анализ используется в том случае, если отношения между переменными могут быть выражены количественно в виде некоторой комбинации этих переменных. Полученная комбинация далее используется для предсказания значения, которое может принимать целевая (зависимая) переменная, вычисляемая на заданном наборе значений входных (независимых) переменных . В простейшем случае для этого используются стандартные статистические методы, такие как линейная регрессия. К сожалению, большинство реальных моделей не укладываются в рамки линейной регрессии. Например, размеры продаж или фондовые цены очень сложны для предсказания, потому что могут зависеть от комплекса взаимоотношений множества переменных. Таким образом, необходимы комплексные методы для предсказания будущих значений.
Прогнозирование временных последовательностей позволяет на основе анализа поведения временных рядов оценить будущие значения прогнозируемых переменных. Конечно, эти модели должны включать в себя особые свойства времени: иерархия периодов (декада-месяц-год или месяц-квартал-год), особые отрезки времени (пяти- шести- или семидневная рабочая неделя, тринадцатый месяц), сезонность, праздники и др.
Кластеризация относятся к проблеме сегментации. Этот подход распределяет записи в различные группы или сегменты. Кластеризация в чем-то аналогична классификации, но отличается от нее тем, что для проведения анализа не требуется иметь выделенную целевую переменную.
Ассоциация адресована, главным образом, к классу проблем, типичным примером которых является анализ структуры покупок. Классический анализ структуры покупок относится к представлению приобретения какого-либо количества товаров как одиночной экономической операции (транзакции). Так как большое количество покупок совершается в супермаркетах, а покупатели для удобства используют корзины или тележки, куда и складывается весь товар, то наиболее известным примером нахождения ассоциаций является анализ структуры покупки (market-basket analysis). Целью этого подхода является нахождение трендов среди большого числа транзакций, которые можно использовать для объяснения поведения покупателей. Эта информация может быть использована для регулирования запасов, изменения размещения товаров на территории магазина и принятия решения по проведению рекламной кампании для увеличения всех продаж или для продвижения определенного вида продукции, хотя этот подход пришел исключительно из розничной торговли, он может также хорошо применяться в финансовой сфере для анализа портфеля ценных бумаг и нахождения наборов финансовых услуг, которые клиенты часто приобретают вместе. Это, например, может использоваться для создания некоторого набора услуг, как части кампании по стимулированию продаж. Другими словами, ассоциация имеет место в том случае, если несколько событий связаны друг с другом. Например, исследование, проведенное в супермаркете, может показать, что 65% купивших картофельные чипсы берут также и «кока-колу», а при наличии скидки за такой комплект «колу» приобретают в 85% случаев. Располагая этими сведениями, менеджерам легко оценить, насколько действенна предоставляемая скидка.
Последовательность. Традиционный анализ структуры покупок имеет дело с набором товаров, представляющим одну транзакцию. Вариант такого анализа встречается, когда существует дополнительная информация (номер кредитной карты клиента или номер его банковского счета) для связи различных покупок в единую временную серию. В такой ситуации важно не только сосуществование данных внутри одной транзакции, но и порядок, в котором эти данные появляются в различных транзакциях и время между этими транзакциями. Правила, которые устанавливают эти отношения, могут быть использованы для определения типичного набора предшествующих продаж, которые могут повести за собой последующие продажи определенного товара. То есть, если существует цепочка связанных во времени событий, то говорят о последовательности. После покупки дома в 45% случаев в течение месяца приобретается и новая кухонная плита, а в пределах двух недель 60% новоселов обзаводятся холодильником.
Эти основные типы моделей используются для нахождения нового знания в хранилище данных. Обратимся теперь к методам, которые используются для проведения интеллектуального анализа данных.
Методы анализа данных
Интеллектуальные средства анализа данных используют следующие основные методы:
- нейронные сети;
- деревья решений;
- индукцию правил;
- системы рассуждения на основе аналогичных случаев;
- нечеткая логика;
- генетические алгоритмы;
- алгоритмы определения ассоциаций и последовательностей;
- анализ с избирательным действием;
- логическая регрессия;
- эволюционное программирование;
- визуализация данных.
Иногда применяется комбинация перечисленных методов.
Нейронные сети относятся к классу нелинейных адаптивных систем с архитектурой, условно имитирующей нервную ткань из нейронов. Математическая модель нейрона представляет собой некоторый универсальный нелинейный элемент с возможностью широкого изменения и настройки его характеристик. В одной из наиболее распространенных нейросетевых архитектур - многослойном персептроне с обратным распространением ошибки - эмулируется работа нейронов в составе иерархической сети, где каждый нейрон более высокого уровня соединен своими входами с выходами нейронов нижележащего слоя. На нейроны самого нижнего слоя подаются значения входных параметров, на основе которых производятся вычисления, необходимые для принятия решений, прогнозирования развития ситуации и тд. Эти значения рассматриваются как сигналы, передающиеся в вышележащий слой, ослабляясь или усиливаясь в зависимости от числовых значений (весов), приписываемых межнейронным связям. В результате этого на выходе нейрона самого верхнего слоя вырабатывается некоторое значение, которое рассматривается как ответ, реакция всей сети на введенные значения входных параметров. Для того чтобы сеть можно было применять в дальнейшем, ее прежде надо «натренировать» на полученных ранее данных (примерах), для которых известны и значения входных параметров, и правильные ответы на них. Процесс «тренировки» состоит в подборе весов межнейронных связей и модификации внутренних параметров активационной функции нейронов. Для каждого сочетания обучающих данных на входе выходные значения сравниваются с известным результатом. Если они различаются, то вычисляется корректирующее воздействие, учитываемое при обработке в узлах сети. Указанные шаги повторяются, пока не выполнится условие останова, например необходимая коррекция не будет превышать заданной величины.
Нейронные сети, по существу, представляют собой совокупность связанных друг с другом узлов, получающих входные данные, осуществляющих их обработку и генерирующих на выходе некий результат. Между узлами видимых входного и выходного уровней может находиться какое-то число скрытых уровней обработки. Нейронные сети реализуют непрозрачный процесс. Это означает, что построенная модель, как правило, не имеет четкой интерпретации. Некоторые алгоритмы могут транслировать модель нейронной сети в набор правил, помогающих уяснить, что именно она делает. Такую возможность предлагают некоторые оригинальные продукты, использующие технологию нейронной сети. Многие пакеты, реализующие принципы нейронных сетей, применяются не только в сфере обработки коммерческой информации. Нередко без них трудно обойтись при решении более общих задач распознавания образов, скажем расшифровки рукописного текста или интерпретации кардиограмм.
Деревья решений - это метод, который пригоден не только для решения задач классификации, но и для вычислений и поэтому довольно широко применяется в области финансов и бизнеса, где чаще встречаются задачи численного прогноза.В результате применения этого метода к обучающей выборке данных создается иерархическая структура классифицирующих правил типа «ЕСЛИ... ТО...», имеющая вид дерева (это похоже на определитель видов из ботаники или зоологии). Для того чтобы решить, к какому классу отнести некоторый объект или ситуацию, мы отвечаем на вопросы, стоящие в узлах этого дерева, начиная с его корня. Вопросы могут иметь вид «значение параметра A больше x?» для случая измеряемых переменных или вида «значение переменной В принадлежит подмножеству признаков С». Если ответ положительный, мы переходим к правому узлу следующего уровня, если отрицательный - то к левому узлу; затем снова отвечаем на вопрос, связанный с соответствующим узлом. Таким образом мы, в конце концов, доходим до одного из оконечных узлов - листьев, где стоит указание, к какому классу (сочетанию признаков) надо отнести рассматриваемый объект. Этот метод хорош тем, что такое представление правил наглядно и его легко понять.
Сегодня наблюдается всплеск интереса к продуктам, применяющим деревья решений. В основном это объясняется тем, что многие коммерческие проблемы решаются ими быстрее, чем алгоритмами нейронных сетей. К тому же они более просты и понятны для пользователей. В то же время нельзя сказать, что деревья решений всегда действуют безотказно: для определенных типов данных они могут оказаться неприемлемыми. В частности, методы дерева решений не очень эффективны, если целевая переменная зависит линейным образом от входных переменных, так как в этом случае дерево должно иметь большое число листьев. Иногда возникают проблемы при обработке непрерывных величин, скажем данных о возрасте или объеме продаж. В этом случае их необходимо группировать и ранжировать. Однако выбранный для ранжирования метод способен случайно скрыть выявляемую закономерность. Например, если группа объединяет людей в возрасте от 25 до 34 лет, то тот факт, что на рубеже 30 лет некий параметр испытывает существенный разрыв, может оказаться скрытым. Этого недостатка не имеет продукт SAS Enterprise Miner в силу того, что реализованные в нем методы построения дерева решений могут автоматически выявлять границу (численный критерий) разделения данных на более однородные подгруппы.
Для деревьев решений очень остро стоит проблема значимости. Дело в том, что отдельным узлам на каждом новом построенном уровне дерева соответствует все меньшее и меньшее число записей данных - дерево может сегментировать данные на большое количество частных случаев. Чем больше этих частных случаев, чем меньше обучающих примеров попадает в каждый такой частный случай, тем менее надежной становится их классификация. Если построенное дерево слишком «кустистое» - состоит из неоправданно большого числа мелких веточек - оно не будет давать статистически обоснованных ответов. Как показывает практика, в большинстве систем, использующих деревья решений, эта проблема не находит удовлетворительного решения. Исключением из этого ряда является упомянутый выше SAS Enterprise Miner, включающий в себя широкий спектр диагностических инструментов, с помощью которых аналитик может выбрать статистически наиболее обоснованную модель из производимого множества деревьев решений и более того - сравнить полученную модель дерева с принципиально другими типами моделей (регрессионной и нейросетевой). В данном продукте в качестве целевой переменной можно использовать как измеряемые, так и дискретные (не измеряемые переменные или признаки), что существенно расширяет область применения рассмотренных выше методов.
Индукция правил создает неиерархическое множество условий, которые могут перекрываться. Индукция правил осуществляется путем генерации неполных деревьев решений, а для того чтобы выбрать, какое из них будет применено к входным данным, используются статистические методы.
Идея систем рассуждения на основе аналогичных случаев крайне проста. Для того чтобы сделать прогноз на будущее или выбрать правильное решение, эти системы находят в прошлом близкие аналоги наличной ситуации и выбирают тот же ответ, который был для них правильным. Поэтому этот метод еще называют методом «ближайшего соседа» (nearest neighbour). Системы рассуждения на основе аналогичных случаев показывают очень хорошие результаты в самых разнообразных задачах. Главный их минус заключается в том, что они вообще не создают каких-либо моделей или правил, обобщающих предыдущий опыт, - в выборе решения они основываются на всем массиве доступных исторических данных, поэтому невозможно сказать, на основе каких конкретно факторов эти системы строят свои ответы.
Нечеткая логика применяется для таких наборов данных, где причисление данных к какой-либо группе является вероятностью находящейся в интервале от 0 до 1, но не принимающей крайние значения. Четкая логика манипулирует результатами, которые могут быть либо истиной, либо ложью. Нечеткая логика применяется в тех случаях, когда необходимо манипулировать степенью «может быть» в дополнении к «да» и «нет».
Строго говоря, интеллектуальный анализ данных - далеко не основная область применения генетических алгоритмов, которые, скорее, нужно рассматривать как мощное средство решения разнообразных комбинаторных задач и задач оптимизации. Тем не менее, генетические алгоритмы вошли сейчас в стандартный инструментарий методов data mining. Этот метод назван так потому, что в какой-то степени имитирует процесс естественного отбора в природе. Пусть нам надо найти решение задачи, наиболее оптимальное с точки зрения некоторого критерия. Пусть каждое решение полностью описывается некоторым набором чисел или величин нечисловой природы. Скажем, если нам надо выбрать совокупность фиксированного числа параметров рынка, наиболее выраженно влияющих на его динамику, это будет набор имен этих параметров. Об этом наборе можно говорить как о совокупности хромосом, определяющих качества индивида - данного решения поставленной задачи. Значения параметров, определяющих решение, будут тогда называться генами. Поиск оптимального решения при этом похож на эволюцию популяции индивидов, представленных их наборами хромосом. В этой эволюции действуют три механизма: во-первых, отбор сильнейших - наборов хромосом, которым соответствуют наиболее оптимальные решения; во-вторых, скрещивание - производство новых индивидов при помощи смешивания хромосомных наборов отобранных индивидов; и, в-третьих, мутации - случайные изменения генов у некоторых индивидов популяции. В результате смены поколений вырабатывается такое решение поставленной задачи, которое уже не может быть далее улучшено.
Генетические алгоритмы имеют два слабых места. Во-первых, сама постановка задачи в их терминах не дает возможности проанализировать статистическую значимость получаемого с их помощью решения и, во-вторых, эффективно сформулировать задачу, определить критерий отбора хромосом под силу только специалисту. В силу этих факторов сегодня генетические алгоритмы надо рассматривать скорее как инструмент научного исследования, чем как средство анализа данных для практического применения в бизнесе и финансах.
Алгоритмы выявления ассоциаций находят правила об отдельных предметах, которые появляются вместе в одной экономической операции, например в одной покупке. Последовательность - это тоже ассоциация, но зависящая от времени.
Ассоциация записывается как А(Б, где А называется левой частью или предпосылкой, Б - правой частью или следствием.
Частота появления каждого отдельного предмета, или группы предметов, определяется очень просто - считается количество появления этого предмета во всех событиях (покупках) и делится на общее количество событий. Эта величина измеряется в процентах и носит название ?распространенность?. Низкий уровень распространенности (менее одной тысячной процента) говорит о том, что такая ассоциация не существенна.
Для определения важности каждого полученного ассоциативного правила необходимо получить величину, которая носит название ?доверительность А к Б? (или взаимосвязь А и Б). Эта величина показывает как часто при появлении А появляется Б и рассчитывается как отношение частоты появления (распространенности) А и Б вместе к распространенности А. То есть если доверительность А к Б равна 20%, то это значит, что при покупки товара А в каждом пятом случае приобретается и товар Б. Необходимо заметить, что если распространенность А не равна распространенности Б, то и доверительность А к Б не равна доверительности Б к А. В самом деле, покупка компьютера чаще ведет к покупке дискет, чем покупка дискеты к покупке компьютера.
Ещё одной важной характеристикой ассоциации является мощность ассоциации. Чем больше мощность, тем сильнее влияние которое появление А оказывает на появление Б. Мощность рассчитывается по формуле: (доверительность А к Б) / (распространенность Б).
Некоторые алгоритмы поиска ассоциаций сначала сортируют данные и только после этого определяют взаимосвязь и распространенность. Единственным различием таких алгоритмов является скорость или эффективность нахождения ассоциаций. Это особенно важно из-за огромного количества комбинаций, которые необходимо перебрать для нахождения наиболее значимых правил. Алгоритмы поиска ассоциаций могут создавать свои базы данных распространенности, доверительности и мощности, к которым можно обращаться по запросу. Например: «Найти все ассоциации, в которых для товара Х доверительность более 50% и распространенность не менее 2,5%»
При нахождении последовательностей добавляется переменная времени, которая позволяет работать с серией событий для нахождения последовательных ассоциаций на протяжении некоторого периода времени.
Подводя итоги этому методу анализа, необходимо сказать, что случайно может возникнуть такая ситуация, когда товары в супермаркете будут сгруппированы при помощи найденных моделей, но это, вместо ожидаемой прибыли, даст обратный эффект. Это может получиться из-за того, что клиент не будет долго ходить по магазину в поисках желаемого товара, приобретая при этом ещё что-то, что попадается на глаза, и то, что он изначально не планировал приобрести.
Анализ с избирательным действием - одна из самых старых математических технологий классификации, которая известна по работам Р.Фишера с 1936 года. Она находит плоскости (или линии для двумерного пространства), которые разделяют группы. Полученные модели очень просты для объяснения, так как все, что пользователь должен сделать с полученной моделью - это определить по какую сторону плоскости или линии попадает точка. Такая технология часто применяется в медицине, социальных науках или биологии.
Однако следует признать, что анализ с избирательным действием не очень часто применяется при анализе данных с помощью технологии data mining по трем причинам.
Во-первых, предполагается, что переменные, которые необходимо предсказать, нормально распределены (то есть их гистограммы напоминают колоколообразные кривые). Во-вторых, невозможно предсказать категориальные переменные, которые нельзя упорядочить (красный-желтый-зеленый). В-третьих, границы, которые разделяют классы это линии или плоскости (в их классическом, Евклидовым, понимании), но данные большей частью не могут быть разделены таким способом.
Новые методы анализа с избирательным действием решают некоторые из этих проблем, позволяя границам быть не линейными, а квадратичными. Также возможно заменить предположение нормальности оценкой реального распределения, то есть теоретическую колоколообразную кривую параметрами реального распределения предсказываемой переменной.
Логическая (логистическая) регрессия имеет много общего с обычной линейной регрессией,. но используются для предсказания вероятности появления того или иного значения дискретной целевой переменной, таких как (0 или 1), (?да? или ?нет?), («отлично», «хорошо», «плохо»). Так как эта переменная дискретна, она не может быть смоделирована методами обычной многофакторной линейной регрессией. Тем не менее, результат (вероятность) может быть выражен в виде линейной комбинации входных переменных, что позволяет получить количественные оценки влияния этих параметров на зависимую переменную. Полученные вероятности могут использоваться и для оценки шансов.Шанс - это отношение вероятности появления события к вероятности того, что событие не произойдет. Это отношение значит то же самое, что и шанс в играх или спортивных соревнованиях. Когда мы говорим о том, что шансы команды выиграть футбольный матч 3 к 1, это значит, что вероятность победы в три раза больше чем вероятность поражения. То есть, мы имеем 75-процентную вероятность победы и 25-процентную вероятность поражения. Аналогичная терминология применяется и к шансам определенного типа клиента (то есть клиента с заданным полом, доходом, семейным положением и др.) ответить на целевую рекламу.
Логическая регрессия - это, с одной стороны, классификационный инструмент, который используется для предсказания значений категориальных переменных (сделает ли определенный клиент покупку или нет) и, с другой стороны, регрессионный инструмент, который используется для оценки степени влияния входных факторов (в данном случае индивидуальных характеристик клиентов).
Эволюционное программирование - сегодня самая молодая и наиболее перспективная ветвь data mining. Суть метода в том, что гипотезы о виде зависимости целевой переменной от других переменных формулируются системой в виде программ на некотором внутреннем языке программирования. Если это универсальный язык, то теоретически на нем можно выразить зависимость любого вида. Процесс построения этих программ строится как эволюция в мире программ (этим метод немного похож на генетические алгоритмы). Когда система находит программу, достаточно точно выражающую искомую зависимость, она начинает вносить в нее небольшие модификации и отбирает среди построенных таким образом дочерних программ те, которые повышают точность. Таким образом, система «выращивает» несколько генетических линий программ, которые конкурируют между собой в точности выражения искомой зависимости. Специальный транслирующий модуль переводит найденные зависимости с внутреннего языка системы на понятный пользователю язык (математические формулы, таблицы и пр.), делая их легкодоступными. Для того чтобы сделать полученные результаты еще понятнее для пользователя-нематематика, имеется богатый арсенал разнообразных средств визуализации обнаруживаемых зависимостей.
Поиск зависимости целевых переменных от остальных ведется в форме функций какого-то определенного вида. Например, в одном из наиболее удачных алгоритмов этого типа - методе группового учета аргументов (МГУА) зависимость ищут в форме полиномов. Причем сложные полиномы заменяются несколькими более простыми, учитывающими только некоторые признаки (групп аргументов). Обычно используются попарные объединения признаков. По всей видимости, этот метод не имеет существенных преимуществ по сравнению с нейронными сетями с их готовым набором стандартных нелинейных функций, не смотря на то, что полученная формула зависимости, в принципе, поддается анализу и интерпретации (хотя на практике все же бывает слишком сложна для этого).
Комбинированные методы. Часто производители сочетают указанные подходы. Объединение в себе средств нейронных сетей и технологии деревьев решений должно способствовать построению более точной модели и повышению ее быстродействия. Программы визуализации данных в каком-то смысле не являются средством анализа информации, поскольку они только представляют ее пользователю. Тем не менее, визуальное представление, скажем, сразу четырех переменных достаточно выразительно обобщает очень большие объемы данных. Некоторые производители понимают, что для решения каждой проблемы следует применять оптимальный метод. Например, Продукт SAS Enterprise Miner 3.0 включает в себя модуль автоматического построения результирующей гибридной модели, определенной на множестве моделей, созданных предварительно принципиально различными методами - методами дерева решений, нейронных сетей, обобщенной многофакторной регрессии. Другой продукт под названием Darwin, готовящийся к выпуску в первой половине этого года компанией Thinking Machines (Бедфорд, шт. Массачусетс), позволит не только строить модели на основе нейронных сетей или деревьев решений, но также использовать визуализацию и системы рассуждения на основе аналогичных случаев. Кроме того, продукт включает в себя своеобразный генетический алгоритм для оптимизации моделей. Чрезвычайно активно работает в области анализа и интерпретации информации хранилищ данных и компания IBM. Многие из полученных в ее лабораториях результатов нашли применение в выпускаемых компанией инструментальных пакетах, которые можно отнести к четырем из пяти стандартных типов приложений «глубокой переработки» информации: классификации, кластеризации, выявлению последовательностей и ассоциаций. Выделение подмножества данных. Одной из наиболее серьезных проблем анализа и интерпретации информации является необходимость выделения подмножества данных (из соображений производительности). При построении своей модели вы можете искать компромисс между числом записей (строк) в выборке данных и количеством оцениваемых переменных. В SAS Enterprise Miner для преодоления такого рода трудностей имеется специальный модуль, позволяющий легко настроить процесс выборки из генеральной совокупности.
Процесс нахождения нового знания
Для того чтобы найти новое знание на основе данных большого хранилища недостаточно просто взять алгоритмы data mining, о которых говорилось выше, запустить их и ждать появления интересных результатов. Нахождение нового знания - это процесс, который включает в себя несколько шагов, каждый из которых необходим для уверенности в эффективном применении средств data mining. Основные шаги этого процесса следующие:
- определение проблемы (постановка задачи);
- подготовка данных;
- сбор данных; а) оценка данных; б) объединение и очистка данных; в) отбор данных; г) преобразование;
- построение модели; а) оценка и интерпретация; б) внешняя проверка;
- использование модели;
- наблюдение за моделью;
- Определение проблемы. Для того чтобы наиболее полно использовать все преимущества технологий data mining необходимо ясно представить цели будущего анализа. В зависимости от целей проводится построение модели. Если необходимо увеличить прибыль торговой организации, то для целей: «увеличение количества продаж» и «увеличение эффективности рекламы» необходимо строить различные модели. В этом же пункте определяются способы оценки результатов будущего проекта и возможные (максимальные) затраты на его реализацию.
- Подготовка данных. Самый времяемкий шаг. Вся подготовка данных может занимать от 50% до 85% времени всего процесса нахождения нового знания.
- Сбор данных. На этом этапе необходимо определить источники получения данных. Это могут быть данные, накопленные самой организацией или, так называемые, внешние данные от общедоступных источников (сведения о погоде или переписи населения и др.) или частных источников (различные архивные данные, базы нотариальных контор и др.).
- Оценка данных. При построении модели необходимо помнить одно правило, касающееся корректности исходных данных: «Если на вход задачи поступает ?мусор?, то и результатом тоже будет ?мусор?». Исходные данные могут находиться или в одной базе, или в нескольких. Перед «загрузкой»? данных в хранилище необходимо учесть, что различные источники данных могут быть спроектированы под определенные задачи и, соответственно, возникает проблемы, связанные с объединением данных: различные форматы представления данных (одна и та же по смыслу переменная - например, количество - может быть представлена в различных базах разными типами данных - int или short); разное кодирование данных (например, разный формат даты); различные способы хранения данных; отличающиеся единицы измерения (дюймы и сантиметры); а также частота сбора данных и дата последнего обновления.
Даже если данные находятся в одной базе, то все равно надо обращать пристальное внимание на пропущенные значения и значения, нарушающие целостность базы («выбросы»).
Аналитик должен всегда знать, как, где и при каких условиях собираются данные, и быть уверенным, что все данные, которые используются для проведения анализа измеряют одно и то же одинаковым способом.
- Объединение и очистка данных. На этом этапе производится построение хранилища данных, которое будет подвергаться дальнейшей обработке, или, говоря другими словами, производится наполнение хранилища или ?загрузка? в него тех данных, которые были отобраны на предыдущих этапах. В это же время производится исправление всех ошибок, которые были выявлены, то есть очистка. Существуют различные аспекты очистки данных. Все они направлены на нахождение и исправление ошибок, которые были допущены ещё на этапе сбора информации. Ошибкой в данных могут считаться:
- пропущенное значение;
- невозможное событие (неверно набранное значение - «выброс»).
Коррекция производится на основе здравого смысла, использования правил и/или с привлечением хорошо знающего предметную область эксперта. То есть транзакция или запись в базе данных, в которой есть такая ошибка, может быть исправлена или, в спорных случаях, исключена из дальнейшего рассмотрения.
После проверки согласованности данных, данные преобразовываются и переформатируются в соответствии с результатами оценки. Это делается для большего удобства наблюдения за данными. Данные дискретных событий преобразовываются в специально разработанную или стандартную форму, если таковая имеется, в которой отражаются время и описание событий. Когда пользователи будут легко разбираться в этой форме, они смогут быстро изучить события, которые лежали в основе построения этой формы. Может показаться, что этот шаг дублирует этап сбора данных, но на самом деле это два совершенно разных этапа. На первом из них происходит отбор данных для ускорения машинной обработки информации (анализа) без потери качества, на втором данные приводятся к виду, удобному для визуального контроля пользователя. Теперь человек проводящий анализ может наиболее полно представить себе исходные данные. Это бывает необходимо для различного рода отчетов, когда необходимо кратко охарактеризовать исходные данные применяемые для анализа.
- Отбор данных. Когда сформировано хранилище и определены типы моделей, которые будут строиться для решения задачи, поставленной на первом шаге, производиться отбор данных необходимых именно для этих моделей. Это подразумевает не только уменьшение количества записей в базе по определенному условию, но также и изменение количества полей, слияния разных таблиц в одну или наоборот создание на основе одной таблицы нескольких. То есть преобразование проходит в «трех измерениях»: по количеству записей, по количеству полей и по структуре.
- Преобразование данных подразумевает обогащение полученной базы, то есть добавление различных отношений на основе существующих полей (не просто «цена» и «количество», а их произведение - «общая сумма», не долг и доход, а отношение долга к доходу), добавление интервалов (по номеру месяца можно поставить номер квартала, а процент выполнения плана можно дополнить характеристиками «плохо-удовлетворительно-хорошо»), добавление критических значений (максимум, среднее, минимум).
- Построение модели. Самое важное, о чем всегда нужно помнить - это то, что построение любой модели представляет из себя итерационный процесс. То есть необходимо построить ряд моделей для нахождения одной, наиболее удовлетворяющей поставленным целям.
Процесс построения моделей можно разделить на две группы: контролируемый (модели классификации, регрессии и прогнозирования временных последовательностей) и неконтролируемый (кластеризация, ассоциация и последовательность)
Следующее описание фокусирует свое внимание на контролируемых моделях, так как это наиболее понятные процессы. Неконтролируемые модели также требуют итерационного построения для получения оптимального результата, но не имеют строго определенных процедур проверки и оценки такого результата. После того, как определен тип модели, необходимо выбрать алгоритм построения модели, или технологию добычи знания.
Сущность процесса построения контролируемой модели сводится к нахождению зависимостей на одной части данных («тренировка модели») и проверки этих зависимостей на другой части данных (оценка точности). Модель считается построенной, когда завершается цикл «тренировок» и проверок.
Так как «тренировочные» и тестовые данные находятся в одной части базы данных, то часто возникает необходимость в третьем наборе данных - дополнительном проверочном, который выбирается из таких данных, которые не пересекаются с «тренировочными» и тестовыми. Он необходим для независимого измерения точности модели. Как правило все три набора данных принадлежат одному и тому же множеству данных, необходимом для реализации проекта data mining.
Наиболее известный тестовый метод - называется простая оценка. В этом случае деление данных на два набора производится случайным образом, для того чтобы наиболее полно отражать данные, для которых производится моделирование и данные тестового набора никак не используются для построения модели. Процент отношения количества тестовых данных к количеству данных, на которых производится построение модели должно быть в пределах от 5% до 33%.
После построения модели ее используют для предсказания значений на тестовом наборе. Делением количества удачных результатов к общему количеству записей в тестовом наборе определяют меру точности модели (можно использовать такую переменную, как мера неточности, которая равна 1 - «мера точности»)
Как было сказано раньше, модель считается построенной, когда завершается цикл «тренировок» и проверок. Если мера предиктивной способности модели при очередных итерациях не улучшается, то это говорит о завершении построения модели.
Если для построения модели полностью используется не очень большая база данных, то применяется так называемая перекрестная оценка точности. В этом случае данные случайным образом делятся на две примерно равные части. После этого модель строиться на одной из них, а другая используется для определения меры точности. Потом части базы меняются ролями. Полученные две независимые оценки точности объединяются (как среднее арифметическое, как отношение суммы удачных результатов к общему количеству записей в базе или другим способом) для наилучшей оценки меры точности модели, построенной на всей базе.
Для ещё меньших баз, в несколько тысяч записей, используется n-перекрестная оценка точности. В этом случае база делится на n примерно равных непересекающихся групп. Далее первая из этих групп становится тестовым набором, а остальные группы объединяются, и на их основе производится построение модели. Полученная модель используется для предсказания значений для тестового набора и таким образом получается первая мера точности. Аналогичным образом рассчитываются все n независимых мер точности. Среднее из них является мерой точности всей модели.
Еще один способ используется для нахождения меры точности в малых базах данных. В этом случае модель строиться на основе данных всей базы. После этого случайным образом из записей базы создается множество тестовых наборов (минимум 200, а иногда даже больше 1000). Одна и та же запись может присутствовать в различных тестовых наборах. Для каждого из них определяется мера точности. Опять же среднее из них является мерой точности всей модели.
После того как построение модели завершено, можно построить модель, используя другие параметры, или даже изменить алгоритм (технологию) построения модели, так как никогда нельзя сказать какой алгоритм, какая технология добычи знания даст наилучшие результаты. Нельзя быть уверенным, что определенная технология будет работать лучше всего. Чаще всего приходиться строить большое количество моделей и для каждой проводить процедуру оценки для нахождения самой лучшей. Кроме этого; для разных моделей необходима различная подготовка данных, следовательно, неизбежно повторение шагов. Все это увеличивает время нахождения лучшей модели, поэтому необходимо применять технологии параллельных вычислений.
- Оценка и интерпретация. После построения модели необходимо оценить результаты и объяснить (интерпретировать) их значимость. При оценке модели вычисляется мера точности, но надо помнить, что это значение применимо только к тем данным, на которых модель построена и быть готовым, что данные, к которым в дальнейшем будет применяться модель, могут отличаться от исходных неизвестным образом.
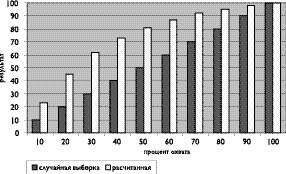
Таблица 1.
Процент охвата Количество потенциальных клиентов при случайной выборке. Количество потенциальных клиентов при выборке по модели абсолютная величина % абсолютная величина % 10 80 10 184 23 20 160 20 360 45 30 240 30 496 62 40 320 40 584 73 50 400 50 648 81 60 480 60 696 87 70 560 70 736 92 80 640 80 760 95 90 720 90 784 98 100 800 100 800 100 Большую пользу в оценке полезности модели могут оказать графики «подъема» и рентабельности (возврата инвестиций). Первый график показывает, как изменяется ответ (количество откликов на целевую рекламу, количество сохранённых клиентов и др.) при применении модели. Второй график учитывает стоимость модели и ее применения, так как модель сама по себе может быть очень интересная, но ее применение не окупит затрат на её построение. Значение этих графиков станет боле понятным из следующего примера: Пусть фирма проводит целевую рекламу (рассылку рекламы по определенным адресам). Количество кандидатов, которое она хочет охватить, возьмем равным 10000. Это могут быть как физические, так и юридические лица. Из них, количество потенциальных клиентов - 800 (эту величину можно оценить, сделав контрольную рассылку в группе, равной величине репрезентативной выборки). Если случайным образом выбрать 10% из общего списка, то есть 1000 кандидатов, то в эту группу потенциальных клиентов тоже попадет 10% от их общего числа, то есть 80. Если же 1000 кандидатов выбирать с помощью модели, то количество потенциальных клиентов в этой группе будет значительно больше. Предположим, что оно будет таким, как показано в таблице 1.
Разница между процентными величинами количества потенциальных клиентов при выборке по модели и при случайной выборке называется «подъемом». График «подъема» представлен на рисунке 1.

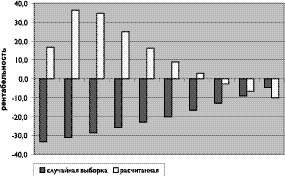
Рис. 1. График Для построения второго графика необходимо наличие дополнительной информации. Пусть стоимость построения модели - 1100 условных денежных единиц (у.д.е.). Средний доход фирмы от привлечения каждого потенциального клиента - 25 у.д.е. Стоимость единицы рассылки меняется в зависимости от охвата и, соответственно, уменьшается при увеличении охвата. Исходные данные для построения графика рентабельности приведены в таблице 2. При этом количество потенциальных клиентов берется из таблицы 1.
Из графика представленного на рисунке 2 видно, что при охвате больше чем 60% рентабельность модели становится отрицательной и финансовый результат от её применения не покроет всех затрат на её построение и применение. Другими словами, надо определить для выборки какого максимального объема целесообразно применять модель
Таблица 2.
Процент охвата Стоимость рассылки, у.д.е. Общий доход при случайной выборке. Общий доход при выборке по модели абсолютная величина % абсолютная величина % 10 3000 2000 -33.3 3500 16.7 20 5800 4000 -31.0 7900 36.2 30 8400 6000 -28.6 11300 34.5 40 10800 8000 -25.9 13500 25.0 50 13000 10000 -23.1 15100 16.2 60 15000 12000 -20.0 16300 8.7 70 16800 14000 -16.7 17300 3.0 80 18400 16000 -13.0 17900 -2.7 90 19800 18000 -9.1 18500 -6.6 100 21000 20000 -4.8 18900 -10.0 Необходимо заметить, что максимум возврата инвестиций, который достигается при 20%, не совпадает с максимальным «подъемом», который достигается при сорокапроцентном охвате. То есть в каждом конкретном случае надо решать, что лучше: высокий подъем (эффективность применения модели) при невысокой рентабельности, или большая рентабельность (возврат затрат на построение и применение модели) при не самом максимальном подъеме. Если скомбинировать оба графика, то кроме вышесказанного, можно ещё найти величину прибыли, приходящуюся на каждую единицу «подъема». В нашем примере эта величина достигает максимума (90.6) при 30-процентном (!) охвате кандидатов.
Рис. 2. График - Внешняя проверка. Как было сказано выше, высокая мера точности модели не является гарантией того, что модель правильно отражает реальный мир. Одной из причин для этого является существование так называемых неявных предположений в модели. То есть сам по себе коэффициент инфляции не может являться частью модели, объясняющей склонность покупателей к покупке того или иного товара, но резкое изменение этого коэффициента с 3% до 20% уже наверняка может объяснить такое поведение.
Другая причина - это существование неизбежных проблем с данными, которые могут привести к некорректности модели, поэтому очень важно проверить модель в реальном мире. Например, если модель используется для отбора кандидатов для целевой рекламы, то можно сделать тестовую рассылку для проверки модели на небольшом объеме данных. Если модель используется для предсказания риска невозврата кредита, то благоразумно будет испытать эту модель на небольшом количестве претендентов на ссуду. Чем больше риск, связанный с некорректностью модели (не только финансовый), тем более важно провести предварительные эксперименты для проверки модели перед началом её полной эксплуатации.
- Использование модели. После построения и оценки модели она может быть использована различными способами. Например аналитик может посмотреть группы, которые определила модель кластеризации, графики эффективности модели или полученные правила.
Иногда аналитик хочет на основе модели определить некоторые значения, например вероятность определенного действия (вероятность ответа на прямую рекламу для определенного списка рассылки). С другой стороны аналитик может использовать модель для выбора некоторых записей из базы данных, для того чтобы провести какой-то дополнительный анализ.
Основываясь на результатах такого использования модели, аналитик может рекомендовать действия, которые можно предпринять в деловой сфере. Однако, часто технология data mining - это часть автоматизированной системы (например: нахождения кредитных рисков, определения возможности потери клиентов и др.), то есть модель встраивается в систему, которую менеджер может применять для принятия решения. С другой стороны модель можно включать в систему, которая генерирует некоторое действие (приказ), если прогнозируемая величина начинает выходить за пределы каких-то значений.
Модели нахождения знаний часто применяются к одной экономической операции (транзакции) в единицу времени. То есть при поступлении новой записи для анализа, которая представляет собой характеристику экономического действия (покупки, заявления на выдачу кредита, операции по магнитной карте) необходимо тут же провести обработку этой записи. Если частота поступления каждой транзакции превосходит время необходимое на его обработку, но надо применять параллельные алгоритмы обработки.
В едином приложении, методы data mining это небольшая, хотя и немаловажная часть конечного программного продукта. Например, процедура нахождения знания при помощи таких методов может соединяться со знаниями экспертов и применяться к данным в базе. В системе, применяющейся в юриспруденции и помогающей определить степень мошенничества ответчика, известные ранее случаи мошенничества могут объединяться с модулями, полученными при помощи технологии data mining. Когда на рассмотрение поступает новое дело, то может понадобиться доступ к данным о других исках, поданных этим же истцом, и о других исках, в которых принимали участие те же адвокат и судья.
- Наблюдение за моделью. Когда модель начинает работать в реальном мире, то необходимо измерить меру точности модели на реальных данных. Однако, даже если модель работает просто превосходно, и можно посчитать, что работа на этом заканчивается, то все равно необходимо продолжать наблюдение за моделью. Все системы имеют свойства развиваться, и данные (их структура, точность, периодичность), которые они поставляют, тоже меняются. Внешние переменные, такие как коэффициент инфляции, своим изменением тоже могут влиять на поведение людей и на факторы, которые оказывают воздействие на это изменение. Таким образом, время от времени модель необходимо подвергать процедуре повторного тестирования, и даже перестроения. Самым простым способом наблюдения за результатами деятельности модели являются графики различий между предсказываемыми величинами и реальными значениями. Они просты для построения и понимания и могут встраиваться в программные продукты, следовательно, такая автоматизированная система может следить сама за собой и оповещать пользователя, если величина этих различий начинает выходить за определенный пороговый уровень.
Современны