
Тенденции развития компьютерной индустрии определяются разнообразными факторами: научными открытиями, новыми промышленными технологиями, конъюктурой на финансовых рынках. В этой связи не стало исключением новое направление в области ИТ - метакомпьютинг, главной движущей силой которого выступают высокопроизводительные приложения, требующие компьютерных архитектур с пиковыми на сегодняшний день техническими характеристиками и вызванные к жизни трудными, и наиболее значимыми для общества проблемами науки и инженерии.
Метакомпьютинг можно обозначить как использование компьютерных сетей для создания распределенной вычислительной инфраструктуры национального и мирового масштаба. Несмотря на то, что сегодня сети доказали свою беспрецедентную практическую полезность в качестве средства глобальной доставки различных форм информации, их потенциал раскрыт далеко не полностью. Сети, объединяющие высокопроизводительные компьютерные системы, могут стать средством организации вычислений следующего поколения.
Что собой представляет Internet известно сегодня любому - это множество соединенных друг с другом узлов, имеющих собственные процессоры, оперативную и внешнюю память, устройства ввода/вывода. Такая конструкция весьма напоминает многопроцессорную систему, в которой роль магистральных шин выполняет Сеть. Цель метакомпьютинга заключается в том, чтобы превратить аналогии в реальность - стереть барьеры между разнородными, пространственно распределенными вычислительными системами и образовать сверхкомпьютер или метакомпьютер [1,2], который для пользователей и программистов выступал бы в виде единой вычислительной среды, доступной с любого рабочего места (ПК или станции).
Характеризуя метафору метакомпьютера, подчеркнем его виртуальность: он динамически организуется из географически распределенных ресурсов, временно делегированных фактическими владельцами. Отдельные установки, соединенные высокоскоростными сетями передачи данных, являются составными частями метакомпьютера и в то же время служат точками подключения пользователей (рис. 1).
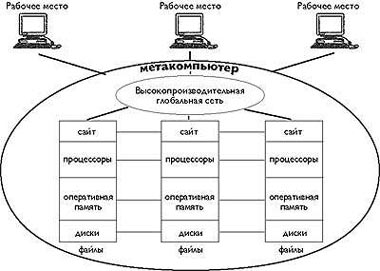 |
| Рис.1. Метафора метакомпьютера |
Необходимо подчеркнуть принципиальную разницу метакомпьютерного подхода и программных средств удаленного доступа. В метакомпьютере этот доступ прозрачен - пользователь имеет полную иллюзию использования одной машины, но гораздо более мощной, чем та, что стоит на его столе. Он может работать с ней в рамках той же модели, которая принята на его персональном вычислителе.
Кому и зачем нужен метакомпьютер?
Непосредственные потребности исходят от высокопроизводительных приложений. В различных прикладных областях (космологии, гидрологии окружающей среды, молекулярной биологии и т.д.) поставлены задачи, характеризующиеся, например, следующими требованиями к компьютерным ресурсам [3]: быстродействие 0,2 - 20 TFLOPS; 100-200 Гбайт оперативная память; 1-2 Tбайт дисковая память; 0,2 - 0,5 Гбайт/с пропускная способность ввода/вывода.
На сегодняшний день нижняя граница таких запросов - это уникальные архитектуры от SGI,CRAY, Fujitsu или Hitachi с тысячами процессоров. С другой стороны, суммарный объем ресурсов в Сети уже сейчас далеко превосходит эти показатели, вопрос в том, как объединить эти ресурсы и передать в руки реальному потребителю.
Такая постановка сегодня очень серьезно воспринимается во всем мире и, в частности, в США, где роль организующего начала взял на себя Национальный научный фонд (NSF - National Science Foundation). Для NSF проект вычислительной сетевой среды стал естественным продолжением общенациональной программы по созданию Суперкомпьютерных Центров (1985 - 1997 гг.), в результате ее реализации которой суперкомпьютерные мощности стали доступны многим заинтересованным исследователям. Произошла быстрая эволюция архитектур: от векторных систем (PVP) к машинам с массовым параллелизмом (MPP) и далее к машинам с симметричным мультипроцессированием на базе разделяемой памяти (SMP). Кстати говоря, опыт этой программы показал, насколько ложным было представление, что суперкомпьютеры - это экзотика, и что даже в научном мире они не найдут большого применения. После того как в 1992 году появилась 512-процессорная CM-5, количество проектов Национального центра суперкомпьютерных приложений (National Center for Supercomputing Applications - NCSA), потребляющих свыше 1000 процессорных часов в год (в единицах CRAY X-MP), увеличилось с 10 до 100 (рис. 2). Желающие найдутся быстро - были бы возможности.
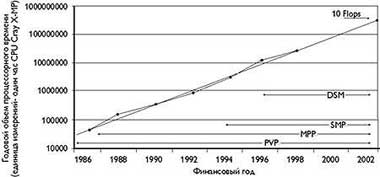 |
| Рис. 2 Динамика потребности в вычислительных ресурсах |
На следующий же день по окончании Суперкомпьютерной программы стартовала новая - Partnership for Advanced Computational Infrastructure (PACI), в которой участвуют сразу два крупных научных объединения: National Computational Science Aliance (NCSA) и National Partnership for Advanced Computational Infrastructure (NPACI) с суммарным финансированием в 340 млн. долл. Средства поступают от NSF, DARPA, NASA и Министерства обороны.
В планах PACI - создание Национальной Технологической Сети GRID, которая будет способна открыть доступ к самой большой из когда-либо собранных вычислительных сред для решения научных и инженерных задач. Термин GRID используется как аналог электрической сети - включение в GRID пользователей должно быть столь же легким, как и включение бытовых приборов.
Имея штаб-квартиру в суперкомпьютерном центре при Университете штата Иллинойс, NCSA объединяет исследователей из более 50 университетов, национальных лабораторий и промышленных организаций с очень широкой географией - Бостон, Висконсин, Миннесота, Аргонн, Беркли, Мичиган, Мериленд, Техас и т.д. Структуру проекта определяют три главных направления: «Новейшей техники» (AH - Advanced Hardware), «Прикладных технологий» (AT - Application Technology) и «Системных технологий» (ET - Enabling Technology). Включение в проект команды AT дает возможность двум другим отталкиваться от конкретных потребностей реальных задач, а также опробовать собственные решения на практике, так что GRID существует в виде постоянно действующего и развивающегося прототипа.
Формы метакомпьютера
Понятно, что проекты метакомпьютера не делаются за один день и требуют долговременных усилий (например, NCSA предполагает пока оформить свою работу только в виде прототипа), поэтому прежде всего важно определить формы и этапы развития метакомпьютерной среды.
1. Настольный суперкомпьютер. Пользователь получает возможность запускать свои задачи на удаленных вычислительных установках с объемом вычислительных ресурсов, необходимым для успешного счета. При этом от пользователя не требуется искать подходящие и не занятые в данный момент мощности: распределять задачи в сети в соответствии с нужными для них ресурсами - функция метакомпьютера. Не следует понимать название «настольный суперкомпьютер» слишком буквально. Кроме доступа к многопроцессорным комплексам для решения параллельных задач, этот режим полезен и для выхода на ресурсы иных типов, например, на мощные графические станции со специализированными процессорами или на базы данных с большими объемами информации, которые по тем или иным причинам не могут быть тиражированы (рис. 3).
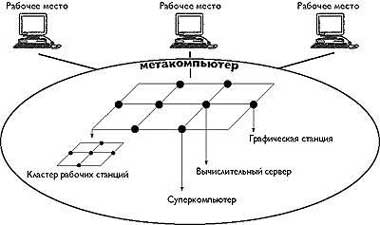 |
| Рис.3. Типы узлов метакомпьютера |
Переход к работе в режиме настольного суперкомпьютинга достаточно безболезнен как для пользователей, так и для программистов - фактически все они продолжают работать со штатными ОС. Этот режим, однако, представляется весьма важным этапом, открывающим реальные возможности освоения передовых компьютерных технологий всему научному и инженерному сообществу, независимо от расположения рабочих мест пользователей и необходимых им ресурсов. Как результат, можно ожидать более эффективного использования уникального и дорогостоящего оборудования, резкого роста числа приложений, в которых находят применение современные методы обработки данных.
2. Интеллектуальный инструментальный комплекс. Практический опыт из многих прикладных областей показывает - просто быстро считать еще недостаточно: часто необходимо в реальном времени собирать большие объемы данных, поступающие с датчиков, производить анализ текущей ситуации, вырабатывать решения и выдавать управляющие воздействия. Все это требует тесной интеграции управления, обработки данных разного вида, моделирования процессов, визуализации в реальном времени. Вычислительные комплексы такого рода получили название интеллектуальных инструментов.
В качестве примера приведем схему мониторинга облачного покрова, реализованную в экспериментальном стенде I-WAY [3] (рис. 4). Спутник производит съемку облачного покрова, а на Землю передается большой объем собранных данных, который обрабатывается на суперкомпьютере, выполняющем подавление шумов и выделение образов. Затем по скоростным линиям информация поступает на удаленный графический суперкомпьютер, производящий рендеринг и генерацию наблюдаемой панорамы. В конце концов графическое изображение попадает на рабочее место исследователей, которые в реальном времени управляют сенсорами спутника.
 |
| Рис.4. Мониторинг облачного покрова на экcпериментальном стенде I-WAY |
Данный вариант метакомпьютера характеризуется распределением обработки по Сети и, следовательно, требует высокопроизводительных линий связи. Кроме того, создание таких приложений требует специальных средств взаимодействия программных компонентов, выполняющихся на распределенных вычислительных системах, физически размещенных в разных точках земного шара.
3. Сетевой суперкомпьютер. При таком подходе идея метакомпьютинга доводится до своей логической завершенности, а именно: происходит масштабирование всех возможных вычислительных ресурсов путем прозрачного бесшовного объединения через Сеть отдельных вычислительных установок разной мощности и архитектуры. Составляющими элементами такой конструкции могут быть суперкомпьютеры, серверы, рабочие станции и ПК. Отличительная особенность этой формы - суммарные ресурсы агрегированной архитектуры могут быть использованы в рамках одной задачи.
В такой форме можно выделить два уровня. Первый применим как альтернатива суперкомпьютеру «в ящике» - сетевой суперкомпьютер создается путем соединения локальной сетью относительно недорогих компонентов: серверов и рабочих станций. Известно, что стоимость такого решения даже на базе дорогого и мощного сетевого оборудования в несколько раз меньше цены суперкомпьютера при сопоставимых характеристиках производительности.
Второй уровень предназначен для владельцев Суперузлов - это настоящие или сетевые суперкомпьютеры. Объединение их в региональном и национальном масштабах скоростными линиями связи способно дать беспрецедентные мощности. Собственно говоря, именно этот уровень масштабирования наиболее точно соответствует термину метакомпьютинг.
Сопоставляя приведенные четыре формы метакомпьютинга, следует сказать, что их полезностьв конкретных условиях в большой мере определяется степенью развитости сетевой инфраструктуры и наличием (или отсутствием) высокопроизводительной техники. В российских реалиях (дефицит достаточного числа открытых для широкого использования суперкомпьютеров и качественных линий связи) ценность метакомпьютерного подхода не только не уменьшается, а напротив возрастает, нужны только правильные и достижимые приоритеты, которые могут быть выстроены в следующем порядке:
- обеспечение дистанционного доступа к крупным корпоративным вычислительным центрам (настольный суперкомпьютер);
- создание единой вычислительной среды в тех же центрах с помощью локальных сетей (сетевой суперкомпьютер);
- агрегация вычислительных центров в региональном и национальном масштабе (интеллектуальные инструменты и метакомпьютер).
Проблемы создания метакомпьютера
Распространение метакомпьютерных технологий может произойти только при гармоничном сочетании двух направлений: развития технической базы и создания программного обеспечения нового поколения.
Для демонстрации требований, предъявляемых к технике, обратимся к американскому проекту PACI. Далеко не полный список задействованных в сети GRID Суперузлов включает: SGI Origin2000 (512 процессоров), HP Exemplar-2000 (64 процессора) в Национальном центре суперкомпьютерных приложений Иллинойского университета; IBM SP (400 процессоров) в Центре высокопроизводительных вычислений университета Нью-Мексико; SGI Triton (4 процессора), SGI T3E (128 процессоров) в Суперкомпьютерном центре университета штата Огайо; IBM SP (160 процессоров) в Аргоннской национальной лаборатории; SGI/CRAY Origin2000 (128 процессоров) в Бостонском университете; HР Exemplar-2000 (64 процессора) в университете штата Кентукки; Condor-пул из 500 рабочих станций в университете штата Висконсин. Суперузлы распределены по всей стране, и для совместной работы они должны быть соединены быстрыми линиями связи. По американским оценкам тамошний коммерческий Internet реально дает производительность днем несколько сотен кбит/с., а ночью 2-3 Мбит/с, что для вычислений недостаточно.
Развитие GRID ориентировано на сети второго поколения. В первую очередь это магистрали vBNS (www.vbns.net), ESNet (Министерство энергетики), DREN (МО США), NASA Science Internet, Internet2, в которых используются протоколы от DS-3 с пропускной полосой
45 Мбит/с до OC-12 (622 Мбит/с). Планы NCSA ставят задачу довести производительность до 38,4 Гбит/с, параллельно с этим подключая новых участников проекта (рис. 5).
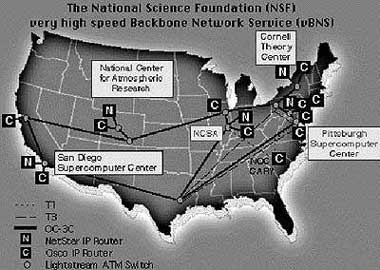 |
| Рис. 5. Сетевая магистраль vBNS |
Создание ПО метакомпьютинга стимулирует глубокие изменения в способах организации вычислений и методах программирования. Фактически планируется переход от операционных сред, рассчитанных на обслуживание автономных установок и сравнительно небольшого числа пользователей, к интегрированной программно-аппаратной инфраструктуре коллективного пользования. Масштабируемое ПО метакомпьютера должно сделать доступным все ресурсы Сети и при этом полностью скрыть наличие сетевых коммуникаций, включая и присущие им недостатки: нестабильность, высокую вероятность аварий, ограничения по производительности.
Достаточно ясно, что метафора метакомпьютинга затрагивает все базовые подсистемы современных ОС: управление памятью, процессами и файлами, ввод/вывод, безопасность. Возможно, будут трансформированы традиционные модели программирования и привычные интерфейсы пользователя (хотя этого, как раз и хотелось бы избежать).
В некоторых аспектах расширение ОС в сетевую среду может быть реализовано прозрачно, пример чему дает управление памятью. Можно организовать сверхбольшое адресное пространство для задач, используя виртуальную память нескольких машин. Для этого при подкачке страницы требуется переслать ее по сети с узла, на котором она хранится в данный момент, на узел, где к ней произошло обращение. Такая схема реализована в программах (TreadMarks [4]), эмулирующих аппаратные архитектуры типа DSM (распределенной общей памяти) и действующих на уровне механизмов ОС прозрачно для любых приложений. При этом не требуется вносить каких-либо изменений и в готовые приложения - они получают большую память бесплатно.
Иная ситуация с механизмом безопасности. В современных ОС он основан на персональной регистрации каждого пользователя, получающего доступ к машине, что практически непригодно в динамически организующейся среде метакомпьютера, где каждый пользователь может претендовать на «чужие» ресурсы. Здесь нужен принципиально иной подход, сохраняющий за каждым административным доменом право проводить собственную политику безопасности и гарантирующий надежность, но в то же время предполагающий однократную регистрацию пользователей в общей распределенной среде.
По аналогии с сетевой виртуальной памятью можно бы было обходиться и с процессами: если задача порождает несколько параллельных процессов, некоторые из них можно переслать на другой узел и выполнить там. Однако, чтобы это имело смысл, нужно знать, какова вычислительная сложность каждого процесса, каковы возможности сетевого канала между узлами. Если такой информации нет, можно не ускорить, а, наоборот, замедлить ход выполнения задачи в целом. Поэтому в области высокопроизводительных приложений применяется «промежуточное» решение - кластерные системы пакетной обработки заданий (CMS). Пользователи могут запускать задания не на конкретной физической машине, а на кластере в целом. Задания оформляются в виде скрипта командной оболочки с добавлением паспорта требуемых ресурсов: времени счета, объема памяти и дискового пространства, количества процессоров и т.д. Система пакетной обработки ведет очереди заданий и выполняет их распределение по наличным ресурсам, оптимально балансируя нагрузку на узлы. Независимо от проблем метакомпьютинга, системы пакетной обработки можно рекомендовать для организаций, заинтересованных в обеспечении эффективного вычислительного процесса. Например, простаивающие по ночам ПК могут загружаться долговременными расчетами в пакетном режиме.
Примерно такого же принципа управления задачами, но уже на уровне Internet придерживается метакомпьютерная среда Globus [5], развиваемая в рамках проекта PACI. Пул ресурсов, которым способен управлять Globus, формируется из крупных сайтов, разбросанных по всему миру. Информация об их состоянии динамически собирается на выделенном сервере, к которому могут обращаться все сертифицированные пользователи. Потенциально можно запустить задание на суперкомпьютер, расположенный в Цюрихе и получить результат на свое рабочее место.
Архитектура метакомпьютерной среды
На сегодняшний день архитектура ПО глобальной вычислительной среды предполагает два слоя. Первый, локальный включает: систему управления пакетной обработкой [6,7] (в кластере или без него), распределенную файловую систему [8] и систему эмуляции распределенной общей памяти [4].
Сейчас известно более 20 систем кластерного управления, как коммерческих, так и свободно распространяемых. Выбрать какую-то определенную систему (даже из коммерческих) непросто: все они имеют существенные недостатки, о которых естественно не сообщается в документации - нужен опыт эксплуатации. Организуя в ИПМ РАН экспериментальный стенд распределенных вычислений мы попробовали две системы: DQS [10] и PBS [11], и в конце концов остановились на последней. Основанием для выбора послужила динамика развития PBS и оперативная поддержка со стороны разработчиков (исследовательский центр NASA AMES).
Второй, метакомпьютерный уровень означает выход за пределы локальной сети, а для этого, как показывает анализ, все кластерные решения нуждаются в существенном изменении. В чем основные отличия двух уровней?
1. Аппаратная среда глобального уровня ненадежна и недетерминирована. Сетевая аппаратура, интерфейсы и протоколы транспортного уровня, применяемые в локальных сетях, практически имеют столь же высокие технические характеристики, что и, например, интерфейсы ввода/вывода отдельных компьютеров. Если исключить сбои сетевого оборудования - они возможны и в компонентах отдельных машин - локальная сеть гарантирует доставку сообщений, причем с предсказуемым временем.
Совершенно иная ситуация в глобальной сети. Здесь весьма вероятны обрывы соединений, как по физическим причинам (отключение канала, обслуживающего хоста), так и из-за превышения лимитов на время подтверждения (time-out). Решающим фактором, от которого зависит качество обслуживания, становится трудно прогнозируемая величина - текущая загруженность сети, определяющая сетевые задержки, которые могут достигать десятков секунд. В результате не только падает производительность системы, но и становится проблематичным выполнение синхронизирующихся параллельных приложений.
2. Некоторые средства доступа к распределенным ресурсам в глобальных сетях не работают. Например, NFS, которая используется в кластере для доступа к файлам, но в Internet работать не может.
3. Многие механизмы базовых ОС отказывают при работе в глобальной среде. К примеру, для контроля прав доступа к ресурсам в кластерных решениях используется тождественность входных имен или идентификаторов пользователей (uid, gid) на всех хостах кластера плюс доверительные отношения между ними. В глобальном масштабе такие соглашения практически невозможно выдержать, а степень защиты, которую они обеспечивают, совершенно недостаточна.
4. Способ доступа к ресурсам как в кластере, так и в метакомпьютере предполагает определенную организацию общего пространства ресурсов. На кластерном уровне конфигурирование этого пространства производится за счет единой политики администрирования. Напротив, метакомпьютер - это самоорганизующаяся система, в которой нет общего администратора, а отдельные структурные единицы сохраняют автономию.
Несмотря на перечисленные отличия, без кластерного уровня обойтись нельзя - они образуют важные структурные единицы метакомпьютера. Это связано с тем обстоятельством, что владельцами ресурсов и основными их потребителями выступают различные хозяева, которые лишь на время отдают часть своих ресурсов в своих административных доменах в общее пользование. В связи с этим трудно ожидать единой политики обслуживания, планирования и безопасности. Метакомпьютерный подход предполагает невмешательство во внутренние аспекты организации кластеров, но для включения во внешнюю среду должны быть определены внешние аспекты политики, касающиеся взаимодействия с метакомпьютерным уровнем.
Кластерные и метакомпьютерные системы находятся на разных стадиях развития. Первые уже пережили по-крайней мере одно поколение и предлагают замкнутые рассчитанные на пользователя решения. Метакомпьютерный подход еще только формируется, развиваясь в двух направлениях: появляются средства взаимодействия кластеров (к такой переходной форме можно отнести Condor, MOL), создается аппарат, в полной мере учитывающий специфику распределенной открытой глобальной сети. Последнее направление, представленное сегодня проектами Legion и Globus, по-видимому более перспективно, однако пока эти разработки можно охарактеризовать как среду для программиста, а не пользователя. В этом плане способы управления заданиями в пользовательском интерфейсе CMS задают эталон, который должен быть достигнут в метакомпьютерных системах.
Метакомпьютинг и системное ПО
Первое соображение, обосновывающее общезначимость технологий, развиваемых в рамках метакомпьютерного направления, состоит в том, что современные ОС во все большей степени становятся «завязаны» на Сеть, ориентируясь на коллективные и мобильные формы работы пользователей с прямым доступом к общей информации и ПО.
Кроме того, на массовом ИТ-рынке наметилась тенденция в сторону параллелизации серийно выпускаемых архитектур (рядовыми стали многопроцессорные RISC и Intel -серверы), ОС и работающих под их управлением приложений. Ведущие производители делают одну версию ОС для всей линейки своих машин - от рабочих станций до суперкомпьютеров, поэтому фактически даже на простейших однопроцессорных машинах есть как базовая, так и инструментальная поддержка параллельных вычислений.
Сетевые технологии: модель клиент-сервер, прикладные протоколы HTTP и FTP, X Window, удаленный вызов процедур RPC, объектные методы распределенной обработки CORBA, DCOM, JINI сыграли важную роль, показав возможности сетей и введя их в повседневную практику. Становится, однако, понятно, что эти средства решают далеко не все проблемы, а часть их оказалась чрезмерно ориентированной на конкретные приложения (к примеру протокол HTTP [9]).
Метакомпьютерный подход, ставя проблему создания полной среды и инфраструктуры сетевых вычислений, определяет контекст, в которым могут занять свое место перечисленные методы. Однако метакомпьютерная постановка шире, и для практики конкретный интерес представляют ведущиеся в рамках метакомпьютинга работы по глобальным файловым системам, системам сертификации и авторизации пользователей, оптимизации сетевой передачи данных, управлению ресурсами, планированию и диспетчеризации процессов.
Приведенные аргументы подтверждаются и тем, что хотя в проекте PACI в основном участвуют исследователи из академических учреждений, они работают в тесном сотрудничестве с ведущими разработчиками аппаратно-программных платформ: SGI, IBM, Microsoft и др., которые и сами инвестируют в собственные проекты по аналогичным темам.
Есть все основания полагать, что уже сделанные существенные продвижения в области метакомпьютинга, направленные на будущее, связаны не только со сферой высокопроизводительных вычислений. Предлагаемые подходы способны оказать глубокое влияние на компьютерную индустрию в целом, включая и то, что принято называть массовым рынком.
Работа выполнена при финансовой поддержке Российского фонда фундаментальных исследований (проект N 99-01-00389) и Министерства науки и технологий РФ (проект 037.01.139.26/1-99)
Виктор Коваленко, Дмитрий Корягин - сотрудники ИПМ им. М.В.Келдыша РАН. С ними можно связаться по email: kvn/koryagin@keldysh.ru
Инструментальная инфраструктура метакомпьютинга Globus
Наш практический опыт освоения метакомпьютерных технологий начался с системы Globus, которая стала прототипом центра серверного обслуживания, интегрирующего вычислительные узлы.
В современном состоянии развития Globus в большей степени представляет собой инфраструктуру сервисов и набор инструментов для разработки распределенных приложений, чем замкнутый комплект утилит для пользователей. К основным видам сервисов, включенных в Globus, можно отнести следующие:
- связь;
- управление ресурсами;
- безопасность;
- информационное обслуживание;
- доступ к удаленным данным;
- запуск и управление заданиями.
Связь
Существует несколько причин, по которым до сих пор остается актуальной разработка коммуникационного прикладного интерфейса (API) самого нижнего уровня. Взаимодействие в метакомпьютерной среде может происходить в самых разных режимах: от передачи сообщений точка-точка до широкого вещания, причем, такие приложения как, например, управление инструментами могут одновременно использовать несколько режимов. Применяемые в Internet протоколы не вполне удовлетворительны: велики накладные расходы, потоковая модель TCP непригодна для ряда режимов, а интерфейсы не позволяют контролировать все параметры.
Идея альтернативных интерфейсов связи (API Nexus) системы Globus состоит в том, чтобы накрыть сверху нижележащие протоколы и методы, оставляя за приложением возможность выбора, одновременно обеспечивая автоматическую селекцию. Nexus вводит понятие коммуникационной связи, понимаемой как совокупность начальной и конечной точки сетевого соединения. Операция передачи инициируется путем запроса на удаленный сервис (RSR) и пересылке данных к ассоциированным конечным точкам и, в конечном счете, к открывшим их процессам. С одной начальной точкой может быть связано несколько конечных и, наоборот, поэтому могут быть сконструированы сложные коммуникационные структуры.
Модель «коммуникационная связь/RSR» может быть отображена на различные методы коммуникации с разными характеристиками производительности. (Под методом коммуникации понимается не только протокол, но и такие аспекты как безопасность, надежность, качество обслуживания и компрессия.) Приложение может управлять методом коммуникации на каждой отдельной связи, приписывая атрибуты начальной и конечной точкам. Например, приложение, в котором часть связей должна быть надежной, а для других требуются малые задержки, может установить две разные связи с соответствующими атрибутами. В общем контексте метакомпьютерной среды предполагается наличие базы данных с динамически собираемой информацией о сети, необходимой для правильного выбора, включая: топологию, поддерживаемые протоколы, пропускную способность и задержки.
Описанный подход иллюстрирует, каким образом метакомпьютерная среда позволяет справиться с гетерогенностью. Приложения или библиотеки более высокого уровня задают все операции в терминах унифицированного API, оставаясь мобильными и способными эффективно выполняться на широком спектре вычислительных платформ и сетей. Однако, в ситуациях, где производительность становится критичной, может быть задействован более тонкий аппарат адаптации управления.
Базовый коммуникационный слой Nexus применяется для реализации высокоуровневых сервисов и средств программирования. Так например на базе Nexus построена переносимая версия стандарта MPI для гетерогенных сетей - MPICH, а для языка параллельного программирования CC++ реализован протокол удаленного вызова процедур.
Информационное обслуживание
Функционирование метакомпьютерной среды основано на открытии, распределении и конфигурировании всевозможных типов ресурсов: компьютеров, сетей, протоколов и алгоритмов. Понятно, что поиск ресурсов возможен, только если о них что-то известно - имеется метаинформация. В локальных системах все упрощается - конфигурационные данные добывается, например, командами типа uname и sysinfo, в распределенных приложениях проблема решается ручным конфигурированием. В кластерах, где по информации о ресурсах проводится планирование, метаинформация собирается либо путем простого опроса хостов, либо путем хранения собранных данных в частных форматах в недоступных извне файлах.
Управление информацией в Globus (MDS - Metacomputing Directory Service), базируется на протоколе LDAP - упрощенной версии X.500. LDAP специфицирует иерархическое древовидное пространство имен объектов (информационное дерево каталогов - DIT) и спроектирован как распределенная служба: произвольные поддеревья могут размещаться на различных серверах. Выбор протокола LDAP в качестве базы для MDS имеет несколько технических и практических плюсов, например, расширяемое представление данных в LDAP (можно определять новые типы объектов). Сегодня LDAP начинает играть существенную роль в Web- системах и можно ожидать развертывания информационных служб на его базе, появления каталогов с полезной информацией и распространения форматов LDAP.
Модель данных MDS представляет различные типы ресурсов, использующихся в распределенных вычислениях. В протоколе LDAP ресурсы формализуются понятиями объекта и атрибутов. В MDS это сайты (административные домены), вычислительные хосты вместе со сведениями о платформе, производительности процессоров, объеме памяти и т.д. Заметим, однако, что до сих пор нет стандарта на типы ресурсов, представимые в MDS, а без этого невозможно организовать взаимодействие автономно администрируемых единиц метакомпьютерной среды.
Информационно насыщенная метакомпьютерная среда - это не только механизмы именования и распространения информации, но и агенты, добывающие полезные данные, и службы, которые их потребляют. Обе эти роли распределены между компонентами метакомпьютера - в принципе, каждый вид сервиса, во-первых, ответственен за производство информации, в которой нуждаются его пользователи, и, во-вторых, использует информацию для увеличения своей производительности. Например, локальный менеджер ресурсов, управляющий кластером, должен содержать компонент, ответственный за сбор и публикацию информации о типах ресурсов, их состоянии и доступности. В то же время компонент планирования данного локального менеджера использует эту информацию для распределения ресурсов.
Примером того, как используется глобальная информационная служба может служить упомянутый API Nexus. Во время выполнения приложения Nexus конфигурирует коммуникационные связи, выбирая для каждой определенный метод. Этот выбор для данной пары процессоров Nexus производит по информации из MDS: тип протокола нижнего уровня, показатели динамической загрузки канала и встроенных правилах (например, ATM предпочтительнее IP) или предпочтениях приложения (нужен надежный протокол).
Безопасность
Безопасность в метакомпьютерной среде, как и в отдельных компьютерах - многоаспектный аппарат, включающий аутентификацию, авторизацию, разграничение прав и пр. В глобальной вычислительной среде возможные решения по аутентификации должны справляться еще с двумя проблемами, которые обычно не возникают в стандартных технологиях. Первая проблема - поддержка локальной гетерогенности. Дело в том, что в работе метакомпьютера участвуют объекты, фактически определенные в разных административных доменах с собственной политикой и соответствующими программными средствами: может, например, применяться одноразовый пароль, Kerberos или Secure Shell.
Вторая проблема - поддержка глобального контекста безопасности. В традиционных приложениях клиент - сервер аутентификация происходит между одним клиентом и одним сервером. Сетевые же приложения могут получать ресурсы и запускать процессы на множестве компьютеров, причем их может быть действительно много - несколько сотен. Запущенные процессы взаимодействуют друг с другом, образуя динамически организованное логическое целое. Следовательно, возможное решение должно устанавливать и контролировать доверительные отношения потенциально между любыми двумя процессами.
Эти проблемы определяют основные черты политики безопасности в метакомпьютерной среде. Во-первых, пользователь аутентифицирует себя всего один раз за сессию, создавая «мандат», по которому процессы получают ресурсы от имени пользователя без какого-либо его дополнительного вмешательства. Во-вторых, проблема локальной гетерогенности решается путем отображения именования пользователя в глобальной среде на его локальное именование на каждом домене, где он получает ресурс.
В Globus схема безопасности реализуется на базе стандарта GSS - Generic Security Services, определяющем процедуры и API получения сертификатов для взаимной аутентификации клиента с сервером, для кодирования/декодирования сообщений и электронной подписи. При этом GSS независим от какого-либо конкретного механизма безопасности и может быть надстроен над различными методами. Способствуя интероперабельности, стандарт GSS определяет, каким образом должна реализовываться его функциональность над Kerberos и кодированием с открытыми ключами, а также описывает механизм переговоров, посредством которого два процесса могут выбрать взаимно согласованный набор протоколов, если имеется более одной альтернативы. Сейчас реально их две - символьные пароли и Secure Socket Layer (SSL) с кодированием на основе открытых ключей. Последний вариант кроме повышенного уровня безопасности обеспечивает интероперабельность с LDAP и HTTP.
Управление ресурсами
Под управлением ресурсами в метакомпьютинге принято понимать круг проблем, связанных в первую очередь с обнаружением и выделением ресурсов, а также аутентификацию, авторизацию, создание процессов и другие действия по подготовке ресурсов к использованию в сетевом приложении. Решение этих задач осложняется тем, что управление ресурсами как в ОС, так и в кластерах не стандартизовано, средства управления существенно различаются в разных клонах Unix, а соответствующие компоненты ПО не входят в конфигурацию ОС локальной машины. Управление ресурсами в метакомпьютерной системе должно удовлетворять ряду требований.
1. Автономия сайтов (структурных единиц метакомпьютера - кластеров или отдельных компьютеров) отражает тот факт, что у всех ресурсов имеются владельцы, которые работают с ними в рамках своего административного домена. Следовательно, невозможно рассчитывать на какую-либо общность политики использования, планирования, механизмов безопасности и т.д.
2. Гетерогенность сайтов - под метакомпьютерной средой имеется дополнительный уровень управления - локальные системы управления ресурсами (CMS). Необходимость налаживания взаимодействия двух управляющих слоев существенно осложняет задачу, поскольку на практике многие важные характеристики состояния оказываются упрятаны в CMS, а самое главное, различия в конфигурациях, политике планирования и возможные частные модификации делают поведение сайтов плохо предсказуемым в принципе.
3. Подобно тому как в кластере существует политика управления, должна быть политика управления и в метакомпьютерной среде. Однако, она не должна быть единой - фактически эта политика определяет правила взаимодействия локальных сайтов с глобальной средой, и они должны устанавливаться снизу - от локальных администраторов иначе нельзя будет говорить о расширяемости политики. Решение для управления ресурсами в метакомпьютерной среде должно поддерживать возможность постоянного развития и изменения структур управления, специфичных для доменов, без изменения кодов установленного на них метакомпьютерного ПО.
В системе Globus средством заказа ресурсов служит язык спецификации RSL (Resource Specification Language), который, в соответствии с требованиями автономии и гетерогенности сайтов, не исключает возможности существования и других отличных от него языков аналогичного назначения - он определяет унифицированные для всей глобальной среды формы задания ресурсов и служит для реализации связи между компонентами метакомпьютера, обслуживающими запросы.
Запросы RSL конструируются из спецификаций параметров - ресурсов, соединенных логическими операторами &, |, +. Множество терминальных символов, представляющих имена параметров расширяемо - все они могут определяться в локальных компонентах метакомпьютера. Имеется два типа параметров, различающихся по смыслу и по способу обработки:
- имена атрибутов MDS используются для задания ограничений на ресурсы, например, memory>=64, network=atm. В этом случае имена параметров соответствуют полям объектов MDS, описывающих ресурсы. В поисковом запросе спецификация параметра сравнивается с текущим значением соответствующего поля в MDS;
- локальные параметры выражают информацию относительно задания: count (число запрашиваемых узлов), max_time (время счета) и т.д. Они интерпретируются в локальных системах.
В пределах сайта или более крупного субстрата могут действовать свои частные соглашения о языке описания ресурсов. В этом плане RSL выполняет роль переходника между ними. К примеру, на сайте S может действовать система пакетной обработки LSF и все задания, которые на нем запускаются, составляются на языке этой системы. Если какое-то задание диспетчеризуется во внешнюю метакомпьютерную среду, то необходимо преобразовать ресурсный запрос в независимую от конкретной CMS форму, провести планирование и преобразовать запрос в форму той локальной среды, в которой задание будет выполняться.
За преобразование RSL в более конкретные спецификации и наоборот ответственны компоненты метакомпьютера - брокеры. Вообще говоря, в метакомпьютерной среде может быть построена иерархия брокеров, выполняющих разнообразные трансформации, например, на уровне пользователя ресурсный запрос может формулироваться в предметно-ориентированных терминах, тогда должен быть реализован брокер, переводящий его в RSL.
Брокерный подход имеет достаточную общность, чтобы в его рамки укладывались совершенно различные стратегии, включая: планировщиков прикладного уровня, которые используют информацию о типах ресурсов; локаторов ресурсов, собирающих информацию об их доступности; трейдеров, создающих рынок ресурсов. В каждом случае брокер может, используя информацию, собираемую локально или получаемую от MDS, отобразить ее в новую спецификацию, содержащую больше деталей. Запрос может последовательно передаваться между нескольким брокерами до тех пор, пока он не будет годиться для менеджера ресурсов.
Среди всех возможных брокеров должен быть один, который по строке RSL производит обнаружение ресурсов. Реализация этого брокера существенно опирается на информационный сервис, обеспечивающий эффективный доступ к данным о текущем статусе ресурсов. Предполагается, что база данных содержит актуализированные по времени метаданные, состав которых достаточен для обнаружения ресурсов с требуемыми динамическими и статическими характеристиками. Информационные задачи решаются брокером через подсистему MDS, использующую формы представления данных и прикладной программный интерфейс стандартного протокола LDAP. Формат языка RSL выбран не случайно - он совпадает синтаксически с поисковыми фильтрами LDAP, поэтому функция брокера - это просто передать строку RSL поисковой машине LDAP и обработать ответ. Результатом выполнения поискового запроса становится один или несколько адресов локальных менеджеров ресурсов, подходящих для запускаемого задания.
Конкретная реализация поискового брокера - прерогатива субстратов метакомпьютера (что, впрочем не отменяет необходимости иметь достаточно общие конфигурируемые решения). Протокол LDAP способствует проведению автономной политики в аспекте ограничения сферы поиска ресурсов и организации собственных метадиректорий. В LDAP определяется иерархическое, древовидное пространство именования, называемое информационным деревом директорий. LDAP поддерживает как распределенное на разные серверы хранение любых ветвей дерева, так и репликацию. Локальный сервис MDS может быть реализован в виде сервера LDAP, который дополнен утилитами для пополнения сервера актуализирующей информацией о структуре и состоянии ресусов в данном узле. Глобальный сервис MDS складывается как объединение всех серверов, а LDAP гарантирует доступность распределенной информации независимо от места ее расположения и места происхождения запроса.
Локальное управление ресурсами и заданиями
Самый низший уровень в архитектуре Globus - уровень управления ресурсами реализует локальный менеджер GRAM, который выполняет:
- обработку спецификаций RSL, либо отвергая запрос, либо запуская одно или более заданий, указанных в запросе параметром executable;
- дистанционный мониторинг и контроль заданий;
- периодическую актуализацию метаинформации сервиса MDS.
Для обеспечения автономии сайтов GRAM спроектирован таким образом, чтобы он мог служить интерфейсом между глобальной метакомпьютерной средой и ее автономной частью, которая фактически создает процессы - это может быть ОС компьютера или система кластерного управления. В последнем случае менеджер ресурсов не закрепляется за единственным вычислителем, а действует от лица всего множества имеющихся в кластере ресурсов.
Предполагается, что спецификация, передаваемая в GRAM от брокеров достаточно примитивна, конкретна и по ней можно идентифицировать параметры - ресурсы без какого-либо дальнейшего взаимодействия с брокерами. При обработке спецификаций GRAM либо самостоятельно выделяет ресурсы, либо делает это посредством обращения к некоторому другому механизму распределения, то есть к конкретной CMS.
В программном интерфейсе GRAM представлены функции запуска, снятия задания и опроса его состояния. На базе этого API (и с помощью API других сервисов) в системе Globus реализован пользовательский интерфейс для управления заданиями по эталону аналогичных средств CMS, однако он не зависит от конкретной среды, в которой задание будет выполняться.
Как и в кластерных системах, пользовательская команда запуска в метакомпьютере (Globus) содержит имя скрипта, запрос ресурсов в котором специфицируется в виде строки RSL. Клиентское ПО выделяет этот запрос и передает его поисковому брокеру, осуществляющему через стандартное API LDAP поиск в базе данных MDS. Возвращаемая информация содержит сетевые адреса тех GRAM, которые обладают требуемыми ресурсами. Далее по полученному адресу пересылается паспорт и само задание. Подстановка заданий в метакомпьютере поддерживает ряд дополнительных опций, принятых в кластерных системах, например: транзитную (через локальные компоненты управления ресурсами) доставку стандартных файлов, доставку файлов приложений (опции stagein, stageout).
Литература
[1] W.J. Kauffmann, L.L. Smarr. Supercomputing and the transformation of science, Scientific American Library, New York.
[2] C. Catlett and L. Smarr. Metacomputing. CACM, 35(6):44-52, 1992.
[3] R.Stevens, P.Woodward, T.DeFanti, C.Catlett. From the I-WAY to the National Technology Grid, CACM, 40(11):50-61, 1997.
[4] C.Amza, A.Cox, S.Dwarkadas, P.Keleher, H.Lu, R.Rajamony, W.Yu, W.Zwaenepoel, TreadMarks: Shared memory computing on networks of workstations, IEEE Computer, Feb. 1996.
[5] I.Foster, C.Kesselman. Globus: A metacomputing infrastructure toolkit. Int. J. Supercomput. Appl., 1997. http://www.globus.org
[6] J.P. Jones, C. Brickell. Second evaluation of job queuing/scheduling software. NAS Technical Report, June 1997 , http://science.nas.nasa.gov/Pubs/ TechReports/NASreports/NAS-97-013/jms.eval.rep2.html
[7] J.P. Jones. NAS requirements checklist for job queuing/scheduling software. NAS Technical Report, April 1996. http://parallel.nas.nasa.gov/parallel/jms/
[8] В.Коваленко. Проблемы сетевых файловых систем. Открытые системы, N 3, 1999.
[9] A.Vahdat, P.Eastham, T.Anderson. WebFS: A Global Cache Coherent File System, University of California, Berkeley, http://
www.cs.berkeley.edu/~vahdat/webfs/webfs.html
[10] http://www.scri.fsu.edu/~pasko/dqs.html
[11] http://pbs.mrj.com
