
Основная цель разработки корпоративных информационных систем - максимально полное решение функциональных задач, обеспечение высокой надежности, масштабирования и защищенности инвестиций. Надеюсь, изложенный в данной статье опыт специалистов АО «Невская косметика», которым предстояло выбрать системотехническое решение для системы R/3, будет полезен многим.
Руководство «Невской косметики», одного из ведущих предприятий отечественной парфюмерно-косметической промышленности, летом 1999 года приняло решение о внедрении корпоративной системы управления SAP R/3, а компания «Линкс ВСС» приняла участие в консультациях, проектировании, поставке и реализации этого системотехнического решения.
Корпоративная система управления предприятием на базе SAP R/3 предназначена для выполнения основных бизнес-функций АО «Невская косметика»: финансовое управление (модуль FI), материально-техническое снабжение (модуль ММ), контроллинг (модуль СО), управление продажами и дистрибуцией (модуль SD). На первом этапе реализации проекта предполагалось развернуть 50 рабочих мест, а позднее увеличить их количество до 100. При дальнейшем развитии проекта было решено внедрять модули PP (производственное планирование), QM (управление качеством), PN (техническое обслуживание и ремонт) и EIS (информационная система для руководства). Кроме того, планировалось, что КСУП должна обеспечивать ряд вспомогательных функций - целостность данных компании, их архивирование и резервирование. Наиболее важным требованием было обеспечение высокой надежности системы R/3 в целом, а также постоянной доступности основных ресурсов: вычислительных, дисковых, ленточных и сетевых. Руководству «Невской косметики» требовался достаточный уровень масштабируемости, поскольку ресурсоемкость приложений типа R/3 и данных обычно существенно превышает проектную. Поэтому системотехническое решение должно иметь высокий потенциал наращивания производительности по процессорам, оперативной памяти, подсистеме ввода/вывода и т.д, чтобы обеспечить защиту начальных инвестиций и безболезненную адаптацию прикладных систем в случае резкого возрастания нагрузок.
В процессе создания корпоративной системы было предложено использовать сетецентрическую модель реализации вычислительного комплекса, при которой основная функциональность, масштабируемость и надежность решения обеспечиваются центральными серверами, а клиентские места реализуют только доступ к информационным ресурсам. Предлагаемый подход обеспечивает высокую надежность - путем объединения серверов в кластеры высокой готовности; максимальную масштабируемость - за счет применения симметричных мультипроцессорных систем в качестве компонентов кластеров; максимальную защиту инвестиций - благодаря использованию в составе кластеров неоднородного оборудования.
ФУНКЦИОНАЛЬНОСТЬ
Главная черта любой КСУП - это функциональность, которая, в свою очередь, обеспечивается необходимым уровнем производительности оборудования, используемого ПО, качеством компонентов системы, а также составом дополнительного оборудования. Уже на этапе предварительного выбора системотехнического решения стало очевидно, что обеспечение полноценного функционирования R/3 и сопутствующих служб возможно только при использовании кластеров из SMP-серверов на базе RISC-процессоров и ОС UNIX. Решения на базе Windows NT как ненадежные и немасштабируемые были отвергнуты сразу, а закрытые решения не рассматривались в силу их высокой стоимости. По предварительным данным, предоставленным заказчиком, были сформулированы требования к используемой модели КСУП (трехзвенная), а также к серверам R/3 и Oracle. Для реализации этих требований необходимо было создать программно-аппаратную среду, удовлетворяющую следующим требованиям:
- работа в режиме on-line в среде UNIX c СУБД ORACLE и SAP R/3;
- реализация высоконадежного кластерного решения, обеспечивающего быстрый рестарт основных приложений и служб;
- возможность интеграции существующих компонентов ПО и аппаратных средств в общую систему;
- обеспечение приемлемой стоимости решения и его наращивания в будущем;
- низкая стоимость эксплуатации и возможность максимальной автономности при обслуживании комплекса.
НАДЕЖНОСТЬ И МАСШТАБИРУЕМОСТЬ
Для предприятий с непрерывным циклом производства обеспечение надежности решения - это важнейшее качество корпоративной системы управления предприятием. Использование кластера вместо одиночного сервера в качестве ядра такой системы позволяет повысить надежность всех прикладных систем, обеспечивая работу сервера базы данных и приложений в режиме высокой готовности. Однако отказоустойчивость комплекса должна быть обеспечена правильным построением кластера: оптимальная топология, полное дублирование всех компонентов, в том числе и соединений.
В решении было предложено использовать серверы от Fujitsu Siemens, принцип построения которых обеспечивает практически линейный рост производительности при увеличении количества процессоров, оперативной памяти и при наращивании подсистемы ввода/вывода. Кластер представляет собой единую систему из двух серверов с набором процессоров, сетевых подключений, адаптеров, специализированных соединений и дискового массива. Каждый его компонент создавался таким образом, чтобы обеспечить надежность, масштабируемость и управляемость всего кластера в целом. Все поставляемые Fujitsu Siemens системы хранения данных можно использовать в кластерах благодаря избыточности и наличию технологии «горячей замены». Серверы кластера работают под управлением ОС Reliant Unix 5.45, поддерживающей многопроцессорные и многонитевые вычисления, реализующей сетевые и общесистемные службы и интерфейсы. Особенностью ОС Reliant Unix является ее способность практически линейно держать производительность серверов при всем диапазоне нагрузок.
РАСЧЕТ ТРЕБУЕМЫХ РЕСУРСОВ
В рамках трехзвенной модели реализации решения на базе R/3 было предложено использовать отдельный сервер под СУБД Oracle и отдельный сервер для выполнения приложений R/3. Все предварительные расчеты для определения требований к серверам производились согласно SAP AG Check List. Эти расчеты включают в себя определение нагрузки в условных единицах называемых SAPS и оцениваются по следующей методике:
SAPS = SD-dialogsteps/h * 100/6000 SD-dialogsteps/h = SD-dialogsteps/sec * 3600 SD-dialogsteps/sec = N / (Tthink + Tres)
Здесь SD-dialogsteps/sec - количество диалоговых сессий в секундах для пользователей модуля SD, на основе которого выполняются расчеты SAPS. Нагрузка по остальным модулям учитывается путем нормализации их к SD при помощи коэффициентов; Tthink - время между двумя шагами диалога; TRes - время ответа системы; N - общее количество пользователей.
Cогласно методике SAP значение SAPS увеличивается на 32% для учета фоновых нагрузок и на 17% для учета пиковых ситуаций. Таким образом, общая нагрузка Central SAPS будет равна Dialog Workload + Update Workload + DB Workload.
В свою очередь Update Workload и DB Workload рассчитываются по формуле:
Update Workload = Dialog Workload * 0.21 DB Workload = Dialog Workload * 0.2
Данные по загрузке SAPS при Tthink = 27 с, TRes = 2 с с учетом предварительных данных распределения пользователей по модулям SAP R/3 для КСУП АО «Невская Косметика» указаны в Таблице 2.
На основе этих данных можно рассчитать объем необходимой оперативной памяти и количество процессоров на серверах кластера, причем учитывая, что на сервере СУБД будут осуществляться и работы по Update.
Расчет оперативной памяти. Не менее 512 Мбайт оперативной памяти требуется для инсталляции серверной части R/3 и обеспечения одновременной работы 15-20 пользователей R/3. Для увеличения их числа на 100 достаточно увеличить оперативную память на сервере приложений (RM400 E) до 600 Mбайт. Память на сервере БД (необходимый минимум - 256 Мбайт) будет расти незначительно - 280 Мбайт для 100 пользователей, учитывая, что на сервере БД будут выполняться фоновые процессы R/3). Так как в рамках трехуровневой модели предполагается разместить сервер приложений и сервер СУБД на разных машинах кластера, то для выполнения этих задач для 100 пользователей потребуется соответственно 600 и 490 Мбайт памяти. Однако поскольку в случае отказа одного из узлов на оставшемся предполагался рестарт как R/3 так и Oracle, на каждом сервере было рекомендовано установить по 1000 Мбайт оперативной памяти (память сервера БД с серверной частью R/3 для фоновых задач плюс память сервера приложений, на котором запускаются модули диалога).
Расчет производительности процессоров. Для сервера СУБД достаточно одного процессора MIPS R10000/250 МГц для каждых 100 пользователей при загрузке сервера БД на 30-40%. Серверу приложений хватает двух таких процессоров для нормальной работы 100 пользователей при загрузке сервера приложений на 40-50%. Все эти значения предусматривают высокую активность пользователей, для которых R/3 - основной инструмент, и невысокую загрузку серверов - комфортные условия для пользователей и минимум двукратный запас производительности при необходимости увеличения нагрузки без изменения конфигурации. При расчете учитывалась фоновая нагрузка на сервер БД (примерно 20%).
Расчет емкости дискового пространства. Минимальные требования для установки R/3 (совмещенные серверы Oracle и приложений R/3) составляют 18 Гбайт дисковой памяти, кроме этого, необходима память для хранения создаваемых документов. По опыту эксплуатации уже установленных SAP систем R/3 при записи порядка 2000 документов в день используемая дисковая память составляет около 30 Гбайт в течение года. Поэтому, в проекте для АО «Невская косметика» было предложено задействовать 50 Гбайт разделяемой дисковой памяти с резервом роста (максимально 500 Гбайт при заполнении конструктива дискового массива).
Расчет загрузки локальной вычислительной сети и удаленных соединений. В сети с технологией клиент-сервер существует несколько потоков данных, оказывающих влияние на сетевую загрузку:
- диалоговые взаимодействия;
- локальная печать (Application Server Spool);
- взаимодействие клиентских ПК с сервером локальной сети;
- дополнительный сетевой трафик .
В среднем за один диалоговый шаг передается 1,5 - 2,0 Кбайт данных, а одна операция требует обычно прохода по 3 - 4 экранам, поэтому средний объем операции принимается равным 16000 байт. Для того, чтобы обеспечить требуемое время реакции системы, утилизация сети не должна превышать 50%. При этом предполагается, что сеть загружена только диалогами R/3. Расчет трафика диалогов (SAPGUI) предлагается проводить по следующей формуле:
С = 16000 * N / (L * (Tthink + Tres)) бит/с
где: С - требуемая загрузка сети;
L - утилизация сети (0 < L <1);
Tthink - время между двумя шагами диалога;
TRes - время ответа системы;
N - общее количество пользователей.
Таким образом, загрузка при Tthink = 27 с и TRes = 2 с составит:
С = 16000 * 100 / (0,5 * (27 + 2)) = 22857 бит/с
Из полученных расчетов видно, что при использовании в локальной сети Ethernet 10 Мбит/с при 50% утилизации сети трафик SAPGUI составляет примерно 1% от общей пропускной способности локальной вычислительной сети.
РЕКОМЕНДОВАННАЯ ТОПОЛОГИЯ КЛАСТЕРА НА
 |
| Рис. 3. Масштабируемая топология кластера |
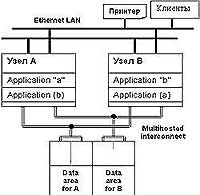
Для обеспечения надежного функционирования системы R/3 на предприятии «Невская косметика», а также с учетом перспектив развития и возможного наращивания системы было решено организовать кластер с использованием масштабируемой топологии (N к N), в которой все узлы и системы хранения имеют доступ друг к другу (рис. 3).
Благодаря гибкости и масштабируемости такой конфигурации в нее могут быть добавлены системы хранения на базе дисковых массивов PXRE, использующие технологии SCSI как для доступа к дискам, так и для соединения с узлами (FC-AL). Сервисы высокой готовности могут быть организованы для любых узлов кластера - все узлы имеют доступ к дисковому массиву. Только такая топология позволяет организовать каскадную отказоустойчивость, когда сервисы перемещаются с неисправного узла на резервный, а в случае его отказа на следующий резервный и так далее.
Масштабируемость данной топологии не только позволяет создавать комплексы высокой готовности, но и обеспечивает увеличение производительности приложений за счет включения новых узлов и распределения нагрузки между ними. Следует отметить, что все рекордные результаты по тестам SAP SD были получены именно на кластерах, построенных по данной топологии, использующих упомянутые системы хранения.
ВЫБОР СЕРВЕРОВ ДИСКОВЫХ ПОДСИСТЕМ И СОЕДИНЕНИЙ
В состав кластера вошли серверы RM400 E60 и RM300 E60 [1], важнейшая особенность которых - эффективная реализация SMP, позволяющая реально обеспечить необходимую производительность системы согласно техническим требованиям задачи: 2 процессора, 1 Гбайт ОП - для сервера приложений и 1 процессор, 1 Гбайт оперативной памяти - для сервера СУБД. Для развертывания дисковой подсистемы была выбрана технология Fujitsu Siemens, реализованная в дисковом массиве PXRE и построенная c помощью средств аппаратного RAID. При использовании такой технологии оптимизируется доступ, скорость выборки и распределение дисковой памяти. Соединение машин и дискового массива осуществляется по интерфейсу UW SCSI-II DF, каждый из которых обеспечивает скорость передачи данных до 80 Мбайт/с. Оба сервера кластера имеют два таких соединения с дисковым массивом. Наличие двух соединений позволяет не только добиться надежности работы кластера, но и повысить производительность дисковой подсистемы и всего кластера в целом.
В качестве межмашинных кластерных соединений используются два канала Fast Ethernet и последовательный интерфейс V.24 SLIP. Внешний доступ к серверам кластера осуществляется через каналы Fast Ethernet - по одному на каждый сервер. Общая схема кластера приведена на рисунке 4.
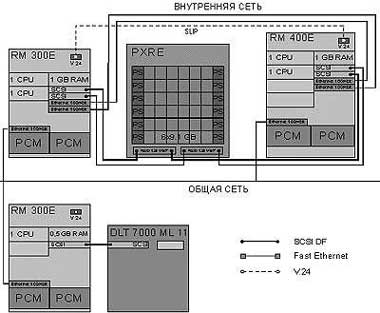 |
| Рис. 4. Общая архитектура кластера |
В состав несимметричного кластера входят два полностью дублированных сервера RM400 и RM300 модели E60 (4- и 2-процессорные R10000/250 МГц и R12000/300 МГц). Данные системы имеют удобный конструктив со встроенным дисковым массивом, избыточными элементами питания и охлаждения. По данным тестов OLTP и SPEC серверы RM400 E показывают практически линейный рост производительности при увеличении количества процессоров и каналов ввода/вывода (коэффициент линейности примерно 0,95).
Одна из машин используется в качестве сервера СУБД, а на второй запускаются приложения системы R/3. Суммарная производительность набора процессоров обеспечивает возможность одновременной работы до 100 пользователей в режиме оперативной обработки данных. Из этого следует, что при начальном числе пользователей около 50 у сервера имеется двукратный запас производительности для удовлетворения растущих потребностей. Избыточность конфигурации обеспечивает рестарт машины и продолжение работы в случае выхода из строя процессора, банка памяти или других компонентов сервера. Каждая машина кластера имеет одну или две 64-разрядные шины PCI с 8 разъемами в каждой. Кластеризация с использованием интерфейсов Fast Ethernet осуществляется через два контроллера, установленных в слоты PCI.
Для удовлетворения требований производительности и обеспечения надежности операций обмена с дисками каждый сервер комплектуется двумя адаптерами PCI SCSI DF CS18, установленными попарно в разъемы PCI. Такое решение обеспечивает общую пропускную способность до 500 Мбайт/c и позволяет увеличивать производительность ввода/вывода. Во встроенный дисковый массив каждой машины устанавливается 2 диска SCSI LVD (80 Мбайт/c) по 9,1 Гбайт, подключенных к интегрированному контроллеру SCSI 16SE. На этих дисках размещается ОС Reliant Unix и пространство подкачки. Для обеспечения высокой надежности диски попарно зеркалируются.
В качестве дисковой системы хранения кластера высокой готовности был использован интеллектуальный дисковый массив PXRE, содержащий 6 дисков SCSI по 9,1 Гбайт каждый. Массив PXRE имеет два встроенных RAID контроллера зеркалируемой кэш-памятью с емкостью 128 Мбайт, батарейное питание кэша, рассчитанное на 48 часов, 4 дисковые полки на шесть устройств каждая, резервные средства питания и охлаждения.
Внутренняя организация системы хранения PXRE обеспечивает полное дублирование всех дисков, интерфейсных плат и модулей питания/охлаждения внутри массива. Количество дисков рассчитывалось исходя из требований технического задания с учетом организации дублирования информации:
- размещение ОС Relant Unix и пространство подкачки на двух отдельных дисках по 9.1 Гбайт, размещенных непосредственно внутри серверов;
- выделение дискового пространства под программное обеспечение R/3 и Oracle - минимум 20 Гбайт;
- не менее 20 Гбайт для данных с учетом роста базы данных на ближайшие 12 - 18 месяцев;
- наличие резервных дисков.
Таким образом, общая потребность в дисковом пространстве составила 50 Гбайт для дискового массива и 20 Гбайт в каждом сервере.
Использование в качестве дисковой подсистемы PXRE позволило создать конфигурацию дискового пространства, полностью удовлетворяющую самым строгим требованиям по скорости доступа и организации дублирования данных. Подключение дискового массива осуществлялось через четыре соединения SCSI DF подключаемых попарно к соответствующим контроллерам в серверах (рис. 4).
В качестве основных внутрикластерных соединений использовались два дублированных канала Fast Ethernet и дополнительный последовательный интерфейс V.24. При этом оба контроллера Fast Ethernet устанавливаются в слоты шины PCI. Внешний доступ к серверам кластера обеспечивался через каналы Fast Ethernet - по каналу на каждый сервер. Все сетевые соединения между серверами и активным сетевым оборудованием устанавливаются при помощи кросс-кабелей категории 5.
Согласно рекомендациям SAP, а также для обеспечения резервирования в предложение для АО «Невская косметика» был включен еще один тестовый сервер RM300 E60, на котором должны подготавливаться новые рабочие версии R/3, проводиться отладка и разработка ПО. В исключительных случаях эта машина может использоваться как резервная - ее архитектура и все комплектующие полностью соответствуют требованиям к компонентам серверов кластера.
ОПЕРАЦИОННАЯ СИСТЕМА
Важным компонентом технического решения была операционная система. Для семейства серверов RM такой ОС является Reliant Unix [2], которая возникла в результате объединения ОС SINIX и DC/OSx, вобрав в себя отличительные черты предшественников: производительность и работоспособность больших кластерных вычислительных систем от DC/OSx и высокую степень соответствия стандартам от SINIX. Система Reliant Unix полностью совместима со своими предшественниками; программные продукты, предназначенные для них, могут свободно выполняться на Reliant Unix. Система была разработана с учетом поддержки всех последующих расширений 64-разрядной архитектуры MIPS. В Reliant Unix могут выполняться одновременно и 32, и 64-разрядные приложения. ОС поддерживает на серверах до 24 Гбайт оперативной пямяти, адресное пространство пользователя - до 1 Тбайт, размер файлов и файловых систем - до 16 Тбайт. Система поддерживает механизмы, необходимые для конфигураций с высокой работоспособностью и безопасностью, а включение в систему продуктов OBSERVE, RMS и AUDIT открывает широкий диапазон возможностей кластеризации и администрирования доменов серверов. Для поддержки многороцессорных систем ядро Reliant Unix расширено функциями синхронизации доступа к системным данным, координации взаимодействия параллельных процессов и управления межпроцессорными коммуникациями. ОС Reliant Unix обеспечивает полностью симметричное мультипроцессирование. При этом все процессоры управляются единственной копией ОС с равными правами доступа ко всем ресурсам; каждый процессор может обрабатывать любой системный вызов, в том числе какую угодно операцию ввода/вывода и любое прерывание. Все процессоры используют единое пространство памяти через систему общих шин (глобальная разделяемая память). Поддержка SMP в ОС Reliant Unix полностью встроена в ядро и не оказывает влияния на выполняемые приложения. Распараллеливание задач производится как на уровне процессов так и на уровне нитей исполнения, время выполнения отдельного приложения не уменьшается, однако общая производительность системы возрастает.
Надежность комплекса была важнейшим критерием выбора платформы для АО «Невская Косметика», поэтому особый интерес заказчик проявил к реализации функций OLR (оперативной замены важных аппаратных компонентов в случае сбоя) и LAR (автовосстановление). OLR доступна в Reliant Unix 5.45 для RM400 и RM300 моделей Е и обеспечивает горячую замену жестких дисков, вентиляторов, контроллеров, блоков питания. Функция LAR позволяет компьютеру продолжать работу при поломке его аппаратных компонентов - дефектные узлы обнаруживаются при перезагрузке системы, деконфигурируются и в дальнейшем не используются. LAR работает совместно с программой порогового мониторинга и программой LOGGING. События, записанные в файле LOGGING, обнаруживаются программой мониторинга. Когда число событий превысит определенный порог, происходит вызов заранее подготовленных сценариев или программ, которые обеспечивают соответствующую реакцию на то или иное событие.
Конфигурирование аппаратуры и администрирование системы выполняются с помощью программы Config. Компоненты системы имеют наглядное графическое представление, что облегчает администрирование и управление в больших конфигурациях. Программа обеспечивает доступ и к удаленным системам, поэтому системный администратор может осуществлять все процедуры инсталляции удаленно. Перед активацией созданная или отредактированная конфигурация проверяется на согласованность, а Config реализует все изменения в системных данных компьютера и запускает процессы, необходимые для управления устройствами. Config выполняет следующие функции:
- администрирование подключенных стоек, UPS, BBU, плат/контроллеров, серверов терминалов и SCSI-устройств хранения (дисков, лентопротяжек, CD-ROM);
- конфигурирование терминалов, ПК-клиентов, принтеров, сетевых принтеров и других последовательных устройств;
- вывод и, если возможно, установку атрибутов устройств;
- анализ подключенной аппаратуры;
- обнаружение и исключение несогласованности в конфигурации;
- создание и распознавание виртуальных конфигураций;
- обнаружение дефектных сетевых узлов, блоков питания и вентиляторов, контроллеров и жестких дисков. Когда это технически возможно, такие устройства автоматически деактивируются (LAR);
- ручная деактивация, реактивация и оперативная замена контроллеров, вентиляторов, блоков питания и жестких дисков (OLR).
RMS - ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ КЛАСТЕРА
На этапе выбора платформы для R/3 заказчик ознакомился с основными характеристиками системы RMS - следящей системы кластера произвольной конфигурации (до 8 узлов), осуществляющей непрерывный мониторинг всех узлов и компонентов кластера (диски, терминалы, принтеры, архивные устройства) и переключение этих компонентов (при необходимости). Если узел кластера вышел из строя, выполняемые на нем задачи перераспределяются между оставшимися узлами. В рамках одного узла возможно отслеживание всех его элементов и действий, задаваемых пользователем. В состав RMS входят средства разработки, позволяющие создавать специальные сценарии мониторинга. Кроме того, RMS включает методы настройки для инсталляции, администрирования кластеров и пользовательских действий, а также для переключения дисковых подсистем. В состав пакета входит ряд дополнительных компонентов, в том числе:
- RMSNET - делает процесс восстановления работоспособности серверов прозрачным для пользователей, подключенных через сеть TCP/IP;
- RMSCON - программное обеспечение для рабочей станции, которое используется в качестве центральной консоли администрирования кластера, а также в качестве централизованного узла удаленного доступа.
При использовании RMS 3.1. обеспечивается: кластеризация до 8 узлов; объединение в кластер серверов разных моделей и использование механизма административных доменов; динамическое добавление узлов; поддержка новейших систем хранения данных PXRE; поддержка API-интерфейсов, позволяющих разработчику совершенствовать существующие приложения.
Наиболее ценными оказались две особенности RMS: полная гарантия автоматического рестарта приложений R/3, Oracle и других необходимых сервисов в течение 10-15 минут с момента возникновения неисправности, а также возможность наращивания кластера до 8 узлов.
RMS 3.1. поддерживает:
- командный интерфейс - набор специальных команд для контроля процесса мониторинга и отображения результатов;
- административное меню FMLI предлагает доступ ко всем функциям, реализуемым через командный интерфейс;
- графический командный интерфейс RMSMON обеспечивает все функции, предлагаемые командным интерфейсом, включая дополнительные функции графического представления, редактирования и слежения;
- конфигуратор - пользователь задает в конфигурационном файле требуемые параметры для непрерывного мониторинга и для отслеживания компонентов в рамках систем. Описываются также сценарии необходимых переключений и действий для RMS в случае возникновения неисправностей;
- отслеживание жизнеспособности узлов - компьютеры в кластере обмениваются специальными сообщениями через регулярные промежутки времени. Пересылка этих сообщений по двум физически независимым резервным линиям позволяет RMS отличить сбой в компьютере от сбоя в коммуникации. Если RMS регистрирует отсутствие сообщений по обеим линиям, это означает, что тестируемый компьютер неисправен;
- контроль переключения - RMS устанавливает все переключатели данной конфигурации в определенное положение и начинает выполнять скрипты, описывающие действия, заданные пользователем;
- средства слежения - готовые к использованию стандартные программы слежения предоставляются для принтеров и процессов;
- библиотека - позволяет потребителям разрабатывать собственные процедуры отслеживания любых объектов. Под объектами могут подразумеваться части аппаратуры, а также переключатели или процессы. Библиотека включает функции, которые поддерживают обмен между RMS и специальной программой слежения;
- сценарии для описания реакции - программирование действия при возникновении отказов в отслеживаемых системах.
При создании описания конфигурации (в виде текстового файла с последующей конвертацией в двоичный формат) пользователь может задавать число компьютеров в кластере, количество линий слежения, число отслеживаемых программных и аппаратных объектов, программы слежения и переключатели. После старта RMS между компьютерами кластера активизируется система контроля жизнеспособности. Если от одного из компьютеров кластера не поступает специальных сообщений по двум следящим линиям, другие компьютеры переключают на себя всю его периферию и выполняют заранее определенные наборы скриптов. После восстановления поврежденного узла кластера автоматически или вручную может быть выполнена процедура обратного переключения.
Кроме контроля за узлами кластера отслеживаются локальные объекты (процессы, принтеры, аппаратные модули и др.), которые задаются в конфигурационном файле. Мониторинг осуществляется программами слежения, которые взаимодействуют с RMS и сообщают о неисправности отслеживаемого объекта. В случае обнаружения изменений в статусе объекта, RMS выполняет необходимый сценарий. В состав пакета RMS включены три стандартных программы слежения: EXIST - проверка существования конкретных процессов; ALIVE - проверка поступления специальных сообщений от отслеживаемых процессов; PRT4 - отслеживание принтеров.
Кластер, управляемый RMS, взаимодействует с другими клиентами КСУП через TCP/IP. При взаимодействии между клиентами и кластером могут возникать следующие проблемы:
- клиенты за приемлемое время не всегда могут распознать отказ компьютера в кластерной конфигурации;
- клиент должен адресоваться к резервному узлу кластера после выхода из строя основного узла и переключения его функций на резервный.
Возможны следующие варианты решения:
- переключение сетевого адреса (с помощью второго сетевого интерфейса, устанавливаемого в каждый компьютер). В этом случае каждый узел кластера снабжается дополнительным сетевым интерфейсом. Во время загрузки конфигурируется только один сетевой интерфейс (задается его сетевой адрес, связанный с именем сервера). Второй интерфейс остается при этом несконфигурированным. В случае выхода из строя основного узла и переключения ПО из сервисов на другой компьютер кластера, на нем происходит конфигурирование второго сетевого интерфейса. При этом он становится доступным в сети по адресу и имени вышедшего из строя узла. После рестарта приложения клиенты снова увидят «свой» сервер. В этом случае RMSNET устанавливаются только на серверах кластера;
- отслеживание текущего статуса узла самим клиентом. В этом случае приложения, расположенные на клиенте, могут сами определять текущий статус всех компьютеров в кластерной конфигурации. На каждом клиенте должен быть установлен RMSNET и запущен соответствующий демон. Если основной сервер выходит из строя, резервный сервер должен сообщить об этом демонам на всех клиентах. При этом приложения, расположенные на клиенте, сами выполняют необходимые действия.
При соблюдении всех требований к организации кластеров НА при использовании агентов служб SAP R/3 и Oracle гарантируется максимально возможная для таких решений скорость восстановления работы приложений и сервисов.
СРЕДСТВА ЦЕНТРАЛИЗОВАННОГО АРХИВИРОВАНИЯ И РЕЗЕРВИРОВАНИЯ
Для организации подсистемы архивирования и резервирования данных в рамках системы R/3 на первом этапе проекта было предложено использовать отдельный лентопротяжный механизм формата DLT7000. Такое решение позволяло осуществлять все операции сохранения и архивирования с использованием штатных средств ОС и R/3 и не требовало покупки дорогостоящей библиотеки и специализированного ПО.
Устройство PXT7-ML11 представляет собой автозагрузчик на 10 кассет, основанный на технологии высокопроизводительного лентопротяжного устройства DLT 7000. Кроме того, в MTC PXT7-ML11 входит система управления картриджами, исключающая возможность попадания загрязняющих веществ на лентопротяжное устройство и ленты из окружающей среды. Программное обеспечение мониторинга автозагрузчика поддерживает отслеживание событий, конфигурирование и диагностику с помощью простого интерфейса. Среднее время безотказной работы PXT7-ML11 составляет 200 тыс. часов при подключенном питании, среднее время восстановления - менее 30 минут. Автозагрузчик гарантирует хранение и прямой доступ к копии данных за каждый день на протяжении всей недели.
Управление автозагрузчиком производится с помощью ПО Legato Networker, предназначенного для выполнения резервного копирования/восстановления и архивирования данных, расположенных на серверах и рабочих станциях. С одной консоли возможна реализация управления неограниченным числом как различных клиентов, расположенных в сети, так и различными типами накопителей, которые также могут находиться в различных участках сети. Данные при такой распределенной конфигурации можно сохранять на ближайшем накопителе, а на центральную консоль возвращать только информацию о том, что и где было скопировано. Серверная часть Networker функционирует под управлением ОС Reliant Unix 5.45. Практически полная автоматизация процесса архивирования позволяет избегать вмешательства оператора в процесс архивирования, что особенно удобно для заказчика. Администратору требуется только задать период плановых операций архивирования для автоматического сохранения данных всех сетевых клиентов. Сохранение информации может быть полным или инкрементальным (только для недавно измененных файлов). Аккуратно планируя процесс автоматического сохранения, администратор системы может получать полные резервные копии за определенный период времени и оптимизировать нагрузку на сеть, выполняя архивирование вне пиковых промежутков времени. Кроме плановых процедур сохранения, администратор может сам проводить те же операции сохранения и использовать те же критерии, что и при автоматическом архивировании.
РАЗВЕРТЫВАНИЕ СИСТЕМЫ
На первом этапе производилась сборка кластера на стендовой площадке «Lynx BCC» все устройства, дополнительные платы, кабели оказались на месте и в течение рабочего дня кластер был полностью собран. Параллельно каждое устройство было проверено на соответствие техническому описанию. Все внутренние тесты по включению питания для всех компонентов кластера прошли без ошибок, что позволило на следующий рабочий день приступить ко второму этапу - конфигурированию отдельных устройств кластера.
Сначала специалистом по дисковым подсистемам была осуществлена конфигурация дискового массива PXRE. Надо отметить, что с точки зрения обслуживания устройство PXRE-HS достаточно продуманно - без каких-либо команд администрирования, только по световым и звуковым индикаторам, можно определить все основные неисправности. Конфигурация и администрирование дискового массива PXRE осуществляются через терминальный вход, подключившись к которому администратор получает доступ к командному интерфейсу устройства. На данном этапе для устройства был установлен режим работы двух RAID контроллеров: один был назначен основным, второй - резервным. Затем была произведена конфигурация самих дисков. Каждому диску было присвоено произвольное логическое имя, затем логические диски были объединены в наборы, на основе которых был создан RAID-массив. После инициализации RAID-массива ему было присвоено логическое имя, под которым он стал доступен из операционной системы.
Параллельно осуществлялась установка ОС Reliant Unix 5.45 на узлах RM400 E60 и RM300 E60 с использованием локальных дисков, подключенных к внутренним SCSI-контроллерам. Для обслуживания внешнего двойного SCSI интерфейса на серверы был установлен пакет DRAID. Он был сконфигурирован обычными средствами SYSADM, после чего был получен дублированный доступ к RAID-массивам как к обычным устройствам Unix в каталоге /dev/draid. Это позволило осуществить подготовку RAID-массивов к работе - разбить их на разделы и создать необходимые файловые системы. После этого была произведена конфигурация протокола SLIP для связи узлов кластера друг с другом по резервному кластерному интерфейсу V.24. Конфигурация осуществлялась стандартными средствами программы администрирования config. Пример конфигурации (файл /etc/hosts) имени узла и двух сетевых интерфейсов для внутренней (private) сети кластера выглядит следующим образом:
127.0.0.1 localhost 192.168.0.1 r0 192.168.0.2 r1 192.168.0.10 r0_slip 192.168.0.20 r1_slip
Во внутренней сети первый хост имеет имя r0, второй - r1.
Для внешней сети имеют значение «виртуальные» имена хостов, которые поддерживаются средствами пакета RMSNET. Хост, исполняющий, с точки зрения кластера, функции «original» (основной), имеет имя orig, а хост «backup» - имя back. Если один из узлов кластера «падает», то обе функции переходят ко второму хосту, который виден из внешней сети и как orig, и как back. Настройка этой функции заключается в создании конфигурационного файла /var/obsnet/ interfaces и добавлении соответствующих строк в файл /etc/hosts:
10.0.0.251 orig 10.0.0.252 back
В конце второго дня работы аналогичные настройки были проведены на втором узле кластера, что позволило вплотную подойти к установке системы R/3.
Установка R/3 осуществлялась в несколько этапов. По желанию заказчика функции узлов были поделены так: r0 исполняет так называемый «central instance» R/3, r1 - «oracle instance». Именно в таком порядке и проводилась инсталляция. Важно отметить, что системные имена узлов в приведенных примерах совпадали с внутренними (private) именами, к которым прикладные программы привязываться не должны. Поэтому перед установкой R/3 имена хостов были изменены на внешние (public) командой uname, а после установки эта операция была проделана еще раз в обратном порядке.
На завершающем этапе настройки был установлен и настроен пакет RMS (точнее его компонент OBSERVE). При этом производилась модификация нескольких файлов конфигурации:
- /opt/observe/reactions/param.usr - основной конфигурационный файл, в котором, в частности, указывается, какие приложения должен поддерживать кластер в режиме HighAvailability. Таких приложений было два - sap («central instance» на r0) и ora («oracle instance» на r1), поэтому в секции приложений присутствуют следующие строки (первая для узла в режиме original, вторая для узла в режиме backup, третья - для хоста, который исполняет в данный момент обе функции):
O_APPLICATIONS=«sap» B_APPLICATIONS=«ora» OB_APPLICATIONS=«orasap»
Интересно, что в конфигурационном файле описаны фактически три приложения - добавлено некое приложение orasap. Дело в том, что когда узел r0 переходит из своего нормального состояния original в состояние original+backup, «oracle instance» запускается на нем заново и требуется также перезапустить «central instance». Это и будет выполнено: так как в третьем режиме приложения sap нет, при переходе в него вызывается сценарий окончания для приложения sap, а в сценарии запуска приложения orasap описывается последовательный старт сначала ora, затем sap.
На узле r1 такие операции не предусмотрены, и соответствующие строки выглядят как:
O_APPLICATIONS=«sap» B_APPLICATIONS=«ora» OB_APPLICATIONS=«ora sap».
- Командные файлы /opt/observe/reactions/usr/020filesystem и /opt/observe/reactions/usr/025obsnetif описывают процедуры монтирования файловых систем на внешнем дисковом массиве и конфигурации внешних интерфейсов. Во время их конфигурации были внимательно прописаны сценарии необходимых процедур (например, fsck).
- В командный файл /opt/observe/reactions/usr/050application были добавлены собственно процедуры запуска/окончания требуемых приложений.
После настройки указанных элементов RMS был создан исходный файл /opt/observe/konfig/test.konfig, в котором перечисляются хосты с их внутренними именами и интерфейсами, способ слежения за процессами и сами процессы, за которыми надо следить. При создании этого файла надо помнить, что имя процесса не обязательно совпадает с именем команды, которой он запускался. Полученный файл test.konfig был откомпилирован специальной утилитой и перенесен на оба узла кластера.
Затем проведена комплексная проверка работы всех элементов кластерного решения, в том числе имитировалось полное прекращение работы одного из узлов и переключение функциональности. Никаких отклонений от ожидаемых режимов работы замечено не было. После окончания испытаний комплекс был перемещен к заказчику, повторно развернут и оттестирован. Таким образом, за 5 рабочих дней был проведен весь комплекс работ по развертыванию, установке и проверке кластера высокой готовности для системы R/3 АО «Невская косметика».
ВОЗМОЖНОСТИ МАСШТАБИРОВАНИЯ
Установленный в АО «Невская косметика» комплекс обладает уникальными возможностями масштабирования. Применение в качестве серверной платформы компьютеров RM400 CS42 позволяет путем модернизации процессоров увеличивать производительность каждого узла в 2 раза, а объем оперативной памяти - до 8 Гбайт. Возможен и другой путь для увеличения производительности комплекса - кластерное ПО RMS поддерживает до восьми узлов, поэтому возможно наращивание мощности комплекса путем включения новых узлов (в том числе и несимметричных) в существующий кластер.
Виталий Кузьмичев - технический директор компании «Линкс ВСС», (Санкт-Петербург). С ним можно связаться по email: vital@lynx.ru
Кластерное решение высокой готовности
Под кластерами традиционно понимается объединение нескольких вычислительных систем (узлов), которые используются как единое целое, обеспечивая доступ пользователей к приложениям, системным ресурсам и данным. В качестве узлов могут применяться как однопроцессорные, так и SMP-серверы. Кластерные решения обеспечивают высокий уровень надежности: в случае отказа одного или нескольких узлов приложения продолжают выполняться на любых других узлах кластера. При этом дополнительная нагрузка может быть равномерно распределена между работающими узлами. Кроме того, путем добавления в кластер новых узлов (процессоров, памяти, дисковых подсистем и т.д.) можно увеличить производительность. Для объединения узлов в кластер применяются различные соединения: линии связи, используемые для обслуживания внутренних потребностей кластера (внутрикластерные - private link) и соединения для подключения потребителей (внешние - public link). На рисунке 1 приводится схема, иллюстрирующая концепцию уровней готовности.
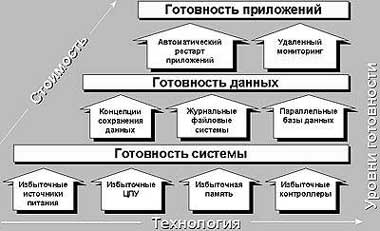 |
| Рис. 1. Концепция высокой готовности |
Первый (базовый) уровень готовности системы может быть обеспечен при использовании отдельных вычислительных систем, два других - готовность данных и готовность приложений - только с помощью кластерных решений HA. При правильной организации такой тип кластера обеспечивает резервирование всех соединений между системами, дисковыми массивами и внешними сетями. Кроме того, каждый компонент кластера (процессорные модули, карты памяти, блоки питания, диски и дисковые массивы, сетевые интерфейсы и т.д.) дублируется или обеспечивает ту или иную степень резервирования. Выход любого компонента кластера не сказывается на его работе в целом. Сервисы данных, связанные с вышедшим из строя узлом, автоматически мигрируют на работоспособный узел, после чего происходит рестарт приложений. Все процессы по восстановлению работы приложений выполняются автоматически. Обобщенная схема кластера высокой готовности приводится на рисунке 2.
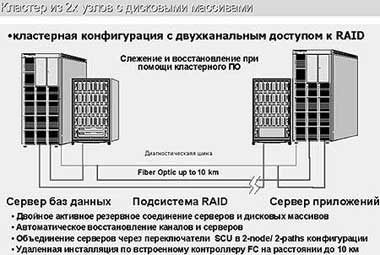 |
| Рис. 2. Обобщенная схема кластера высокой готовности |
Концепция миграции приложений и ресурсов в кластере НА. Основная задача кластера НА - быстрый рестарт приложения, которое функционировало на вышедшем из строя узле. Специализированное ПО организует исполнение приложений на виртуальной машине, имеющей собственное имя (hostname) и сетевой адрес. В каждый момент времени виртуальная машина существует на конкретном физическом узле кластера. В случае выхода узла из строя виртуальная машина автоматически мигрирует на работоспособный физический сервер внутри кластера, сохраняя при этом свое имя и сетевой адрес. С точки зрения клиента, использующего данное приложение и взаимодействующего с виртуальной машиной по ее сетевому адресу, при сбое происходит некоторая задержка, связанная с реконфигурацией кластера, после чего приложение становится снова доступно.
Миграция приложения (точнее, виртуальной машины с приложением) с основного сервера на резервный внутри кластера может, в зависимости от самого приложения, длиться достаточно долго. Программное обеспечение должно быть настроено таким образом, чтобы локализовать сбой внутри сервера и предотвратить миграцию приложения на другой сервер в кластере. В качестве примера таких настроек можно привести ПО OBSNET, которое обеспечивает автоматическое переключение сетевых и дисковых интерфейсов сервера, когда выходят из строя соответствующие адаптеры. Кластерное ПО RMS от Fujitsu Siemens обеспечивает возможность динамического реконфигурирования (Dynamic Reconfiguration) и замены компонентов (процессоров, оперативной памяти, контроллеров ввода/вывода) без остановки сервера и прекращения работы и/или миграции приложения. Одной из важных функций, реализуемых RMS, является поддержка различных путей доступа к устройствам (Alternate Pathing).
Помимо мониторинга состояния сервера и хранилищ данных, кластерное ПО осуществляет постоянный контроль состояния самого приложения, предотвращая ситуации остановки работы в случае внутренней ошибки, «зависания» и т.д. Для этого существуют специальные агенты, разработанные для стандартных приложений: SAP, Oracle, Netscape, NFS и др.
Синхронизация дисковых подсистем. Кластерное ПО должно обеспечивать необходимый уровень синхронизации данных для дисковых массивов, файловых систем и отдельных каталогов, зеркалирование (функции RAID различного уровня), монтирование и восстановление файловых систем при сбоях, осуществление мониторинга всей системы хранения данных.
Маскирование внешних пользовательских сетей. Одна из важнейших задач для кластеров - переключение MAC или IP адресов внешней сети для безболезненного перехода клиентских рабочих мест на работающий узел кластера. Такое маскирование может осуществляться за счет наличия избыточных сетевых интерфейсов, которым назначаются соответствующие адреса IP в случае нарушений в работе узла. В кластерном ПО имеются специальные компоненты, которые через внутрикластерную сеть (private) осуществляют контроль за работой сетевых интерфейсов. Наличие таких компонентов позволяет полностью исключить какое-либо вмешательство оператора при рестарте приложения на другом узле.
Полное дублирование соединений. Кластер НА должен обеспечивать полное дублирование всех соединений для бесперебойного функционирования внутрикластерной сети, внешней сети, дисковых соединений и т.д. Только при полном дублировании всех соединений и компонентов кластера можно говорить о реальном соответствии такой конструкции требованиям высокой готовности.
| Надежность системы | 99,997 |
| Производительность (OLTP TPM) | 15 000 |
| Производительность (SAPS Central) | 300 |
| Объем дискового пространства Гбайт | 100 |
| Масштаб системы | > 2 |
| Число пользователей R/3 | 100 |
| Число одновременно работающих пользователей | 50 |
| Maксимальное время восстановления работоспособности системы | 15 мин. |
| Dialog | Update | DB | Central | |
| Workload [SAPS] | 206 | 35 | 66 | 307 |
| Main Memory [Mбайт] | 567 | 210 | 280 | 912 |
Литература
[1] Виктор Шнитман. Семейство высокопроизводительных серверов RM600E. «Открытые системы», №2,1998 сс.9-14.
[2] Евгений Хухлаев. Операционная система SNI Reliant Unix. . «Открытые системы» №3,1997 сс.11-17.
