
Анализ преступлений б- один из важнейших компонентов работы современной полиции. Правоохранительные органы все шире используют компьютерные средства проведения такого анализа. Система, разработанная в университете штата Вирджиния, призвана адаптировать основанные на использовании вычислительной техники методы расследования «традиционных» преступлений с тем, чтобы правоохранительные органы могли применять эти методы в эпоху Internet.
Правоохранительные органы постоянно анализируют огромное количество данных, связанных с правонарушениями, с тем чтобы лучше разбираться в преступлениях, происходящих на территориях, относящихся к их юрисдикции, выявлять существенные изменения в уровне преступной активности, планировать меры, которые необходимо предпринять в обществе в целом и на своей территории в ответ на изменение криминогенной обстановки, расследовать правонарушения и арестовывать преступников. По мере роста числа преступлений и учитывая, что ресурсы (в первую очередь человеческие) остаются практически неизменными, правоохранительные органы все чаще и чаще обращаются к автоматизированным инструментальным средствам для проверки сообщений о правонарушениях и анализа преступной деятельности в различных регионах с учетом географического положения, времени и типа.
Рост числа компьютерных преступлений за последнее десятилетие потребовал создания более совершенных инструментальных средств анализа преступлений, т. е. средств, способных решать вопросы, связанные с новыми видами правонарушений. По словам Дугласа Ганслера, прокурора из штата Мериленд, количество и диапазон компьютерных преступлений поразительно огромны, в том числе «киберслежка, мошенничество с инвестициями, сексуальные домогательства, кража информации, внутригосударственный и международный терроризм, нарушение авторских прав, фальсификация систем, насильственные преступления, жестокое обращение с пожилыми и «старое, доброе» мошенничество» [1].
По мере роста популярности Internet и учитывая, что электронная коммерция становится важнейшей составляющей экономики с оборотом, измеряемым многими триллионами, число компьютерных преступлений будет соответствующим образом расти. Региональные системы анализа преступлений для традиционных правонарушений уже появились, однако Internet требует создания национальных, а в идеале даже международных средств анализа. Более того, «время Internet» требует проведения анализа преступлений самыми высокими темпами и за более короткий срок, чем дни, недели или даже месяцы, которые, как правило, уходят на анализ традиционных преступлений, а «место Internet» требует, чтобы этот инструментарий не был жестко привязан к географическим районам.
Наша система анализа компьютерных преступлений опирается на опыт создания ранее разработанных систем анализа традиционных правонарушений на очень больших территориях. Эти системы могут обюединять преступления по местоположению, времени и методу действий; они также могут выявлять значительные изменения в криминальной обстановке и определять «предпочтения» преступников, что может помочь прогнозировать потенциальные будущие угрозы.
Анализ компьютерных преступлений
Для того чтобы обеспечить непрерывность работы и целостность систем, специалистами проводится анализ компьютерных преступлений в рамках расследования, которое включает в себя всесторонний анализ компьютерных инцидентов и атак. Это помогает выработать политику системной безопасности, процедурную и технологическую политику защиты, а также активные методы для выявления потенциальных и существующих изюянов защиты в конкретных системах.
Группа «скорой компьютерной помощи» Computer Emergency Response Team (CERT) университета Карнеги-Меллона ведет работу по всеобюемлющему анализу преступлений. CERT, созданная в конце 80-х в ответ на быстрое расширение Internet и возникающие в связи с этим проблемы безопасности, ставит своей целью анализ и разработку необходимых мер, касающихся компьютерных преступлений и атак.
Первоначально CERT выполняла только ограниченный анализ данных, связанных с инцидентами и атаками. Однако многие ученые осознали растущую потребность в выявлении и классификации недостатков компьютерной защиты. В 1997 году Джон Ховард подготовил развернутый обзор собранных CERT данных, связанных с нарушением защиты в Internet. В своем исследовании он проанализировал развитие криминальной ситуации, связанной с компьютерной безопасностью, разработал систематику инцидентов и предложил рекомендации по организации защиты [2]. Эта работа составила основу, которую аналитики могут расширить при необходимости промоделировать и проанализировать те или иные типы компьютерных преступлений.
По мере роста уровня использования сетей и Internet, выявление нарушений защиты становится все важнее. Подготовленный недавно технический отчет университета Карнеги-Меллона рассказывает о современных исследованиях и решениях в этой области, описывая проекты, касающиеся обнаружения нарушений защиты, и технологии, которые используют или анализируют правительственные учреждения, промышленные предприятия и научные институты [3]. Эта работа показывает, насколько важно понять мотивы преступника. Действительно, злоумышленник, который раньше охотился за военными секретами, скорее всего, и в дальнейшем будет действовать в том же направлении, в то время как хакер, который разрушил базу данных своего бывшего работодателя, вероятно, продолжит совершать аналогичные противоправные деяния. Понимание целей, которые ставит перед собой злоумышленник, является абсолютно необходимым, поскольку именно цель определяет его поступки.
Для выявления нарушений системной защиты можно использовать методы активной добычи данных [4]. Такой подход предполагает анализ поступков, которые приводят к нарушениям, и сравнивает их с поведением при нормальной работе. Добыча необработанных данных порождает информацию двух типов: ассоциативные правила и часто встречающаяся последовательность действий. Эти сведения используются для создания автоматического классификатора, который способен различать агрессивное и нормальное поведение.
Принципы анализа
Наша система во многом основана на разработанной в университете штата Вирджиния программе Regional Crime Analysis Program (Recap), которая определяет основные принципы анализа преступлений, относящихся к различной юрисдикции. Пользователи Recap могут обюединять в кластер связанные записи, анализировать тенденции во времени и пространстве, выявлять изменения в этих тенденциях и искать регионы с высокой плотностью криминальных событий, называемые «горячими точками».
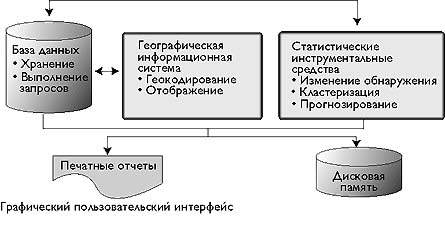 |
| Рис. 1. Компоненты Recap Стрелками показаны связи между базой данных, географической информацией, статистическими инструментальными средствами и графическим пользовательским интерфейсом для генерации отчетов в печатном и электронном виде. |
На рис. 1 показаны методы компонентно-пространственного анализа, который аналитики реализуют, используя географические информационные системы, статистические инструментальные средства и инструментарий генерации отчетов. Географическая информационная система поддерживает статистический анализ за счет геокодирования информации (определение расположения инцидентов в пространстве), вычисления пространственных функций (к примеру, расстояния до дорог и школ) и отображения результатов. Статистические инструментальные средства позволяют изменять обнаружение, обюединять или связывать отчеты об инцидентах и проводить анализ и прогнозирование горячих точек.
База данных Recap поддерживает мультиагентный («межведомственный») анализ, позволяя получать данные из каждого учреждения или из нескольких баз данных одного учреждения и используя национальные стандарты на подготовку отчетов об инцидентах и настраиваемые региональные поля этих отчетов для определения полей, описывающих инцидент. Эти настраиваемые поля содержат информацию так называемого образа действия (modus operandi – MO), излагаемую в описании и не попадающую в другие поля отчета об инциденте.
Большинство компьютерных преступлений имеют «межведомственную» природу, поскольку компьютерные преступники (и в первую очередь действующие в Internet), как правило, не соблюдают границ местных полицейских участков. Оболочка Recap поддерживает анализ компьютерных преступлений за счет сбора и стандартизации отчетов, получаемых от отдельных правоохранительных учреждений так, что пользователи могут связывать отчеты о преступлениях, совершенных на очень больших территориях. Система также способна связывать компьютерные преступления с традиционными правонарушениями.
Статистические средства Recap позволяют проводить анализ именно того типа, который необходим для компьютерных преступлений. Особо стоит отметить инструментальные средства для создания ассоциаций данных, инструментальные средства связи или кластеризации, инструментарий для анализа ситуации в существующих горячих точках и оценки возможной угрозы. Аналитики используют этот инструментарий для выявления связи преступлений по местоположению, времени и методу, выявляя серьезные изменения в криминальной активности, выявляя индивидуальные предпочтения преступников таким образом, чтобы предсказать развитие криминогенной обстановки в будущем.
Компонент пространственного анализа в Recap также имеет немаловажное значение для анализа компьютерных преступлений, причем в них далеко не всегда используются традиционные карты. Топология преступлений в киберпространстве отличается от физической топографии большинства традиционных преступлений. Эта новая «территория» ограничивает и одновременно определяет движения преступников так, что это может существенно повлиять на работу стражей порядка. Фактически пространственные средства анализа могут оказаться намного важнее для расследования компьютерных преступлений, чем традиционных правонарушений. При традиционных преступлениях сотрудники правоохранительных органов, как правило, обладают информацией о физической среде, полученной как опытным путем, так и интуитивно. Однако топология Internet и локальных сетей представляют собой совершенно неизученные области. Тем не менее, отображение преступлений в этих топологиях может помочь сотрудникам правоохранительных органов понять эту относительно новую сферу криминальной деятельности.
Кластеризация и определение ассоциативных связей в компьютерных преступлениях
В физическом мире преступления могут быть классифицированы по различным типам (уличный грабеж, убийство, изнасилование и тому подобное) и по MO. Каждый преступник имеет склонность к определенному образу действия даже при совершении различных, на первый взгляд, преступлений, поэтому задача состоит в том, чтобы обюединить похожие, но не идентичные правонарушения.
Аналитики работают с отчетами об инцидентах, содержащими всю информацию о криминальном событии в том виде, как ее записал представитель полиции. Аналитики пытаются обнаружить в этих отчетах признаки различных правонарушений, которые мог бы совершить один и тот же человек или группа людей. Как только выявлено это ассоциативное множество инцидентов, аналитик пытается обнаружить шаблоны поведения преступника или преступной группы, а затем использовать эти шаблоны, чтобы помочь арестовать виновных.
Ассоциации данных
Для того чтобы автоматизировать этот процесс, мы использовали методологию поиска ассоциативных связей в данных, разработанную Доналдом Брауном и Стефеном Хагеном [5]. Этот подход к выявлению ассоциативных связей между записями в базе данных зависит от параметра сходства или различия, который показывает, насколько соответствуют друг другу две записи на основе значений конкретных атрибутов.
Следователи используют ассоциации данных для обюединения в кластер отдельных людей или групп, которые склонны к совершению преступления с аналогичными MO, в похожем месте и в похожее время. Ассоциации данных помогают определить, что два преступления схожи б- например, при совершении одного из которых взломщик вскрыл дверь с помощью старого железного прута, и другого, когда дверь была открыта с помощью лома. Этот метод также помогает определить, что эти преступления отличаются от другого преступления, когда взломщик для того чтобы проникнуть через дверь, использовал отмычку. Ассоциации данных помогают определить границы расследования и дают возможность понять, какие следует предпринять превентивные меры. Однако огромное количество традиционных преступлений не позволяет вручную находить ассоциативные связи в данных во всех, за исключением очень немногих и очень важных случаях. Для большинства распространенных преступлений, таких как кража, одному аналитику потребуется целый день на то, чтобы оценить ассоциативные связи между новым инцидентом и 500 уже имеющихся записей. Проблема еще сильнее усложняется для компьютерных преступлений, где число инцидентов много больше и продолжает расти, и где база данных инцидентов распределена между огромным количеством местных правоохранительных учреждений.
Методы поиска ассоциативных связей в данных, которые мы разработали для анализа традиционных криминальных инцидентов, представляют значительную ценность для аналитиков, сталкивающихся с такого рода препятствиями при расследовании компьютерных преступлений. Эти методы поиска ассоциативных связей дают возможность измерять сходство между различными инцидентами. Например, пусть н?k(A, B) б- сходство по атрибуту k между записями A и B в базе данных с описанием инцидентов, а wk б- весовой коэффициент атрибута k. Мы вычисляем общий параметр сходства TSM(A, B) между записями A и B как взвешенную сумму параметров сходства атрибута:
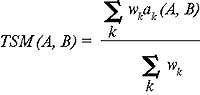
Однако эта методология требует, чтобы мы определили значимые атрибуты, стандартизовали атрибутные функции в базе данных каждого правоохранительного учреждения, определили функции сходства и весовые коэффициенты. Опытные аналитики определяют значимые атрибуты, собранные в отчетах об инцидентах, затем проводят стандартизацию значений, которые получены от различных учреждений. Эта функция стандартизации, как правило, включает в себя таблицы преобразования, которые интегрируют концепции, выраженные в одном учреждении и между базами данных различных учреждений.
Например, сексуальные домогательства по отношению к несовершеннолетним в Internet-чате могут быть по-разному описаны в отчетах об инцидентах разных ведомств. В одних отчетах может быть не указано название конференции и просто описан случай сексуального домогательства через Internet, в то время как в других отчетах может быть приведено название, а в третьих б- даже прямая контактная информация.
Иерархия понятий
В нашем подходе используется иерархия понятий для связи значений в различных отчетах. Например, о контактах в Bob's Sleazy Chat Room может сообщаться как об участии в чате или как о взаимодействии в Internet. Однако, если контакт, который происходит в чате, связывается с взаимодействием в Internet, мы можем вычислить сходство этих отчетов. Мы предлагаем такого рода структуру для каждого из важных атрибутов для компьютерных преступлений, для которых определены ассоциативные связи.
Затем нам необходимо определить ассоциативную функцию н?(A, B). Мы используем данные анализа преступлений для того, чтобы для всех значений, указанных в каждом отчете, определить соответствие некоторому действительному числу в интервале [0,1]. К примеру, пусть атрибут «Метод сексуального домогательства» имеет три значения категорий: электронная почта, чат и голубиная почта. Анализ данных о преступлениях показывает, что сексуальное домогательство в чате имеет коэффициент сходства с сексуальным домогательством по электронной почте равный 0,7, а для сексуального домогательства посредством голубиной почты с двумя другими методами этот коэффициент равен 0,001. Таким образом, каждое значение категории для важных атрибутов в отчете связывается попарно с другими значениями для этого атрибута.
Настройка важности весовых коэффициентов
Наконец, мы вычисляем весовые коэффициенты для атрибутов. Наш подход предусматривает динамическую настройку весовых коэффициентов с учетом данных расследуемых преступлений. Чтобы понять необходимость в динамических весовых коэффициентах, рассмотрим следующую ситуацию. Предположим, что мы расследуем случай атаки типа «отказ в обслуживании». На первый взгляд может показаться, что тип программного обеспечения, использованного для организации атаки, имеет важное значение для связи инцидентов, поэтому этому атрибуту при вычислении общего сходства сначала присваиваются высокие весовые коэффициенты. Однако если при всех таких атаках применяется одно и то же программное обеспечение, этот атрибут должен иметь небольшое значение, поскольку он не играет важной роли для определения различия между атаками.
Идея регулирования важности весовых коэффициентов широко используется в литературе, посвященной многокритериальному принятию решения [6]. В нашем подходе сначала оптимизируются весовые коэффициенты в уравнении, опираясь на данные о тех случаях, о которых известно, что они имеют ассоциативную связь. По сути, принимается такое решение о значении весовых коэффициентов (wk в приведенном выше уравнении), которое минимизирует ошибку классификации, при том, что эта ошибка вычисляется как количество неверных обюединений инцидентов, которые не должны быть обюединены. Затем, при анализе новых инцидентов для динамического регулирования весовых коэффициентов мы используем сомножитель относительной энтропии. Этот сомножитель оценивает предполагаемую информацию, которую представляют значения в каждом отчете. Это предположение заменяет собой байесову вероятность для обюединения отчетов.
Один из наиболее интересных аспектов компьютерного преступления – данные, которые преступники получают прежде, чем предпринять попытку совершить преступление. Но это одновременно дает следователям изобилие информации для анализа преступлений. Следователи используют наши методы поиска ассоциаций в данных для получения информации, имеющейся в базах данных различных ведомств с описаниями инцидентов. К примеру, следователи могут определить, что два преступления похожи: одно, при котором злоумышленник украл пароль и разместил на Web-сайте непристойные рисунки, и второе, при котором с помощью сниффера сетевых пакетов был скопирован пароль и на сайт переданы непристойные фотографии.
Следователи обюединяют результаты измерения общего сходства для оценки количества отдельных лиц или групп, участвующих в кибератаках. Хотя могут использоваться самые разные методологии кластеризации, мы применили метод иерархической кластеризации с полной связью [7]. В этом методе, если показатель сходства двух записей выше определенной фиксированной величины, или порогового значения, эти записи обюединяются в кластер, а если одна или обе записи принадлежат некоторым кластерам, тогда все записи обоих кластеров имеют показатель сходства больше порогового значения.
Выявление предпочтений
Основная цель анализа преступлений состоит в том, чтобы настолько хорошо понять, как происходят криминальные процессы в регионе, чтобы можно было предпринять превентивные правоохранительные меры. Для этого необходимо выявить области и людей, находящихся под угрозой, и принятие мер по снижению этой угрозы. Анализ компьютерных преступлений преследует аналогичную цель.
Существует множество подходов к прогнозированию традиционных преступлений, начиная от методов временных серий до моделирования. Наш подход к моделированию на базе агентов использует для создания модели процессов принятия решений выявление предпочтений, которыми руководствуется преступник. Мы выявляем эти предпочтения преступника во многом так же, как Internet-компании выявляют предпочтения своих потребителей б- наблюдая и анализируя их поведение в Web.
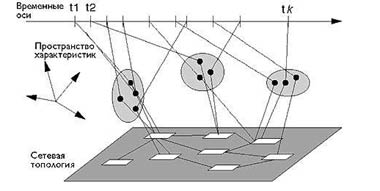 |
| Рис. 2. Подход к выявлению предпочтений преступников Показываетвзаимосвязь между временем инцидента, местом инцидента и кластерами, создаваемыми в пространстве характеристик. Время преступлений представлено на временных осях, место инцидента представлено на сетевой топологии, а кластеры представлены в пространстве характеристик |
На рис. 2 показаны базовые компоненты этого подхода выявления приоритетов. Мы анализируем правонарушения с учетом времени и сетевой топологии и отображаем эти инциденты на пространство характеристик, которое определяется важными атрибутами всех инцидентов. Например, эти атрибуты могут включать в себя характеристики узла, подвергшегося атаке, тип инструментальных средств, используемых при атаке, и время дня, когда была начата атака. В пространстве характеристик эти инциденты обюединяются в один кластер. Более формально, мы создаем оценку плотности для поверхности решений, которая в пространстве характеристик представляет предпочтение преступника для конкретных атрибутов. Эти поверхности затем становятся основой для моделирования поведения преступника во время будущих атак.
Наш подход также использует алгоритм выбора характеристик, который позволяет следователям отбирать минимальный набор, необходимый для описания выявленных предпочтений преступника. К примеру, мы можем различать компьютерного преступника, атакующего сайты с учетом политических воззрений, но игнорирующего выгоду, которую можно получить от этих сайтов, от преступника, действующего по финансовым мотивам и не принимающего во внимание какие-либо политические взгляды. Это значит, что в первом случае характеристики, описывающие политические взгляды, являются важными, в то время как во втором случае они не важны. Поскольку в результате создается наименьший из возможных набор характеристик, мы можем использовать эту информацию для определения предпочтений преступника при моделировании на базе агентов.
Наш алгоритм выбора характеристик был создан в процессе работы над системой анализа традиционных преступлений [8]. Следуя этой методологии, предположим, что инциденты, представленные в пространстве характеристик на рис. 2, показывают обюединение, состоящее из C' кластеров (C1(p) : I = 1, 2, ... , C '). Теперь предположим, что эти инциденты действительно связаны подмножеством общего числа атрибутов, например, по содержимому сайта. Тогда легко показать, что если использовать это подмножество для кластеризации, мы найдем, по крайней мере, столько кластеров, сколько мы получили, используя полное множество атрибутов. Более того, если существует C преступников (или преступных групп), то мы должны обнаружить не меньше C кластеров. Однако если мы оцениваем C, то можно выборочно сокращать число характеристик до тех пор, пока не будут найдены «наилучшие» C кластеров. Мы определяем наилучшие кластеры, вычисляя расстояния как внутри, так и между кластерами.
Мы можем также применить подход выявления ассоциативных связей до определения предпочтений с тем, чтобы найти предпочтения конкретного преступника или группы.
Предсказание преступлений и оценка угрозы
Рис. 3 показывает все эти фрагменты, обюединенные в одну систему. База данных, полученная из баз данных различных ведомств б- это основа для анализа. Мы применяем ассоциации данных к групповым инцидентам и используем выбор характеристик для определения набора характеристик для выявления предпочтений. Методы выявления предпочтений затем генерируют модели принятия решений. Эти модели взаимодействуют с дополнительными Internet-моделями: «модель охраны» (guardianship) и «модель благоприятных возможностей» (opportunity). Модели охраны описывают как статические, так и динамические действия, предохраняющие от нарушения защиты. Благоприятные возможности представляют операции, связанные с созданием новых сайтов, изменением сайтов и другими действиями, благоприятствующими совершению преступлений.
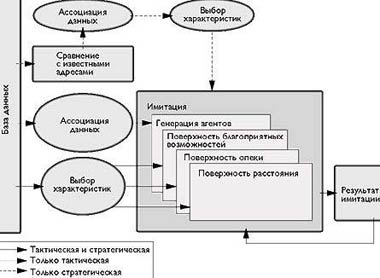 |
| Рис. 3. Система предсказания события преступления на базе агентов После того, как ассоциация данных определяет количество агентов, а выбор характеристик определяет их предпочтения, модель генерирует агентов. Характеристики важности для агентов определяют среду агентов. Модель работает с учетом временного шага и в результате имитации генерируется прогноз. Тактическая версия модели предсказывает поведение компьютерных преступников; а ее стратегическая версия прогнозирует, как изменения среды изменят поведение преступника. |
Мультиагентное моделирование
Мультиагентные модели предлагают эффективные инструментальные средства предсказания поведения компьютерных преступников. Эти модели используют искусственных агентов, способных взаимодействовать со своими средами и друг с другом. Хотя универсального определения агента не существует, в общем случае агент определяется как обюект, имеющий следующие четыре свойства [9].
- Автономия. Агент не должен управляться внешним образом. Часто агент имеет набор правил, которые определяют его поведение.
- Реактивность. Агент может осознавать свое окружение и реагировать на него.
- Социальность. Агент может взаимодействовать с другими агентами в модели.
- Проактивность. Агент может инициировать свое собственное, определяемое его целью, поведение.
Исследователи используют мультиагентное моделирование для создания искусственных сообществ, в которых компьютерные модели имитируют социальное поведение [10]. Однако для этой имитации мы используем значения, полученные из существующих данных, для создания сообщества, соответствующее тому, которое мы реально наблюдаем.
Связывание и выявление предпочтений
Специалисты, начинающие расследование компьютерного преступления, могут получить огромное количество «сырых», предварительных данных. В этом случае весьма полезными могут оказаться автоматизированные инструментальные средства анализа преступлений, которые позволяют следователю автоматически выделить из всех этих данных ценную информацию. Анализ данных позволяет обнаружить важную информацию, в том числе число преступников, действующих в этой среде, и их предпочтения, тем самым давая следователю возможность сузить поиск до конкретных лиц или групп, отличающихся этими предпочтениями.
Например, если обнаружено, что преступник предпочитает наносить ущерб узлам, обладающим конкретным набором характеристик, следователь может заняться поиском групп, у которых есть основание атаковать именно такие узлы. Это знание значительно сужает границы следствия.
Создание мультиагентной модели
Чтобы создать мультиагентную модель для имитации компьютерного преступления, мы определяем число и тип агентов на основе необработанных данных проверки, а затем из необработанных данных выявляем предпочтение преступника. При таком моделировании эти выявленные предпочтения применяются для создания криминальных агентов.
Как только стали известны предпочтения, можно предсказывать виды компьютерных преступлений, которые будет пытаться совершить преступник. Поскольку преступник действует исходя из выявленных предпочтений, можно предсказать наиболее вероятную реакцию на изменения сетевой среды. Это позволяет системному администратору имитировать атаку на систему для того, чтобы обнаружить потенциально уязвимые ссылки, а разработчик правил работы системы получает возможность имитировать, как отразятся изменения правил или процедур на защите компьютерной системы.
Пример анализа
Предположим, что сепаратистская террористическая группа United Loonie Front (ULF) борется за независимость Луны от Земли. Кроме того, существует группа аполитичных хакеров б- Bob's Pretty Good Hack Shop, которая стремится получить большие деньги. Это преступление начинается, когда общенациональный журнал и нью-йоркская газета публикуют статьи в поддержку сохранения политического контроля Земли над Луной.
ULF инициирует два типа атак. Группа предпринимает атаку типа «отказ в обслуживании» против сайта общенационального журнала и трех его рекламодателей (компаний 1, 2 и 3). Террористы взламывают пароль нью-йоркской газеты и оставляют на всех страницах ее Web-сервера непристойные рисунки.
Хакеры группы Bob's замечают атаку и решают использовать распределенный сетевой сниффер для того, чтобы получить имена пользователей и пароли компании 2 (фирма по торговле акциями). Затем, когда системные администраторы будут по горло заняты поддержкой работоспособности систем, хакеры смогут опустошить столько счетов, сколько им вздумается.
На рис. 4 изображены оба источника атак и информация, которую получит об этих атаках сторонний наблюдатель. Для простоты на этом рисунке указано только небольшое число всех возможных вовлеченных в описанные события Web-сайтов.
Пространство характеристик, в которых будут образованы кластеры, имеет следующие параметры.
- Тип компьютерного преступления: ущерб или фальсификация.
- Тип атаки: отказ в обслуживании, взлом пароля или копирование пароля.
- Используемые инструментальные средства: инструментарий 1, инструментарий 2 или инструментарий 3.
- Вид деятельности, осуществляемый на сайте: ювелирные изделия, акции, книги или новости.
- Тип сайтов, с которыми связан ссылками данный сайт: коммерческие новости, розничная торговля или некоммерческие новости.
Алгоритм выбора характеристик определяет, что злоумышленники предпочитают атаковать узлы, обладающие следующими характеристиками.
- Подключенные к сайту любой из газет (ULF).
- Или к сайту газеты, или коммерческому сайту (ULF).
- Компания, торгующая акциями, для другого типа атаки (Bob's).
Это достаточная информация для создания мультиагентной модели для имитации непрерывной атаки. При этой имитации создаются два агента с предпочтениями, полученными выше, и эти агенты действуют в соответствии с полученными предпочтениями. Агент 1 (ULF) будет продолжать атаку на газеты и коммерческие сайты. Он будет использовать и атаку «отказ в обслуживании», и взлом паролей. Агент 2 (Bob's) будет продолжать атаковать узлы, на которые уже было произведено нападение, которые имеют изюяны, позволяющие использовать распределенный сетевой сниффер, и которые имеют определенный уровень бюджета (брокеры, банки и компании, выпускающие кредитные карты).
Поскольку эти агенты действуют в соответствии с полученными предпочтениями, мы можем предсказать их реакцию на изменение в сетевой среде. Эту информацию можно использовать для оценки уязвимости конкретных узлов и, возможно, предупредить их. На рисунке 5 показана карта узлов, подвергнувшихся атаке, а узлы, которые скорее всего пострадают в будущем, изображены пурпурным цветом. Отметим, что в этом примере указаны узлы, которые или скорее всего будут атакованы, или не будут атакованы вовсе. В реальной ситуации для каждого узла указывается вероятность атаки б- от 0 до 1.
Наш метод анализа преступлений использует ассоциации данных для определения числа криминальных агентов, а затем б- выбор характеристик, чтобы определить предпочтения выявленных агентов. Поскольку этот метод автоматизирован, аналитики могут применять их в ситуациях, где имеется огромное количество данных. Таким образом, этот метод особенно полезен в области компьютерных преступлений, где сбор данных выполняется относительно легко, но анализ данных оказывается намного более трудоемким.
Более того, аналитики используют данный метод для изучения предыдущих атак, для оценки числа атакующих и определения их предпочтений, а также для прогнозирования будущих атак. Этот метод находит приложение как в микродоменах конкретной системы, таких как локальная сеть, так и макродоменах всей глобальной системы, таких как Internet или частная финансовая сеть. Данная методология, таким образом, будет интересна членам как компьютерного сообщества, так и специалистам по защите.
Благодарности
Особую поддержку нашей работе оказали гранты, предоставленные Virginia Department of Criminal Justice Services и National Institute of Justice, Crime Mapping Research Center.
Об авторах
Дональд Браун (deb@virginia.edu) – профессор и декан факультета проектирования программного обеспечения университета штата Вирджиния, США. К области его научных интересов относится анализ рисков. Луиза Гундерсон (lfg4a@virginia.edu) – научный сотрудник того же факультета университета штата Вирджиния. Она занимается проблемами моделирования и имитации. Марк Эванс (mhe8e@virginia.edu) – аспирант того же факультета. Он занимается исследованиями в области ИТ-страхования.
Литература
[1] D.F. Gansler, «... and a Free Rein for Criminals,» The Washington Post, 20 Feb. 2000, p. B8
[2] J.D. Howard, An Analysis of Security Incidents on the Internet: 1989-1995, doctoral dissertation, Dept. Eng. and Public Policy, Carnegie Mellon Univ., Pittsburgh, http://www.cert.org/research/JHThesis/Start.html (5 July 2000), 1997
[3] J. Allen et al., State of the Practice of Intrusion Detection Technologies, Tech. Report CMU/SEI-99-TR-028, ESC-TR-99-028, Software Eng. Institute, Carnegie Mellon Univ., Pittsburgh; http://www.sei.cmu.edu/publications/
documents/99.reports/99tr028/ 99tr028abstract.html (5 July 2000), 1999
[4] W. Lee, S.J. Stolfo, and K.W. Mok, «A Data Mining Framework for Building Intrusion Detection Models,» Proc. IEEE Symp. Security and Privacy, IEEE CS Press, Los Alamitos, Calif., 1999, pp. 120-132
[5] D.E. Brown and S. Hagen, Data Association Methods with Applications to Law Enforcement, Tech. Report 001-1999, Dept. Systems Eng., Univ. of Virginia, Charlottesville, Va, 1999
[6] R. Keeney and H. Raiffa, Decisions with Multiple Objectives, Cambridge University Press, New York, 1993, pp. 282-353
[7] M.S. Aldenderfer and R.K. Blashfield, Cluster Analysis, Sage Publications, Newbury Park, Calif., 1986, pp. 33-45
[8] H. Lui and D.E. Brown, «Spatial Temporal Event Prediction: A New Model,» Proc. IEEE Int'l Conf. Systems, Man, and Cybernetics, IEEE CS Press, Los Alamitos, Calif., 1998, pp. 2933-2937
[9] N. Gilbert and K.G. Troitzsch, Simulation for the Social Scientist, Open University Press, Buckingham, UK, 1999, p. 159
[10] J. Doran and N. Gilbert, «Simulating Societies: An Introduction,» in Simulating Societies: The Computer Simulation of Social Phenomena, N. Gilbert and J. Doran, eds., UCL Press, London, 1994, pp. 1-8
Interactive Analysis of Computer Crimes, Donald E. Brown, Louise E. Gunderson, Marc H. Evans, IEEE Computer, August 2000, pp. 69-77. Copyright IEEE CS, Reprinted with permission. All rights reserved.
О двух задачах служб безопасности
Александр Антонов
Повседневная деятельность служб безопасности охватывает множество аспектов функционирования физических, технических и общественных обюектов. Среди множества актуальных задач, решение которых невозможно без привлечения компьютерных технологий, можно выделить поиск аномального обюекта среди заданного множества подобных и определение связей выделенного обюекта в заданном множестве.
Таможенник, созерцая ожидающую проверки группу пассажиров, решает, кого он будет «трясти» с особой тщательностью. Есть ряд известных ему, например, чисто психологических признаков, однако часто он даже не может обюяснить, почему выбрал для проверки именно этого туриста. Решение принимается на основании анализа большого количества признаков, каждый из которых по отдельности ничего не значит. Способностью к такому анализу и отличается опытный таможенник от своего молодого, внимательного, но неопытного коллеги.
Или еще одна задача. В столице задержан с наркотиками студент-африканец, однако выявить его контакты напрямую невозможно – хотя бы потому, что он не знает русского языка). Логично вести поиск среди всех его соседей по общежитию или среди студентов его вуза. Иначе говоря, при наличии подозреваемого обюекта, поиск его возможных связей ведется среди похожих на него по одному признаку, а лучше б- по совокупности признаков.
Это примеры из традиционной среды функционирования службы безопасности. Сегодня же основным источником информации, хранилищем «следов» стало электронное хранилище б- переписка по электронной почте, архивы ICQ и т.д. Новое информационное «пространство» дает в руки сотрудников службы безопасности новые возможности, но и создает новые трудности.
Проблемы анализа электронного текстового архива
На первый взгляд кажется, что инструменты для решения описанных выше задач уже есть б- достаточно хранить в архиве переписку интересующих вас персон и, анализируя ее достаточно большой обюем (за месяц, год), можно определить все интересные черты выделенного обюекта, а сопоставляя результаты анализа по разным обюектам можно решать обе задачи. Правда, есть, как минимум две проблемы: большой обюем исходных данных и сложность выделения полного набора признаков для представления результатов анализа.
Допустим, вы б- сотрудник службы безопасности относительно небольшой компании. В вашей организации работает 100 человек. Каждый из них пишет и получает 10 писем в день. Итого 1000 в день или 360 тыс. в год. Анализ такого обюема информации выходит далеко за рамки физических возможностей службы безопасности компании.
Придумать же набор признаков, адекватный каждому из рассматриваемых обюектов, и, одновременно, универсальный для них б- задача, смею утверждать, неподюемная. Решение ее подобно решению задачи «пойди туда, не знаю куда, найди то, не знаю, что».
Трудность решения этих задач и лежит в основе расчетов тех, кто надеется сохранить конфиденциальность своего общения, ведя переписку открытыми средствами. Известно, где проще всего спрятать лист б- в лесу.
| Главные темы (слова) | Главные темы (словосочетания) |
| BOND | JAMES BOND |
| LLEWELYN | BOND FILM |
| 007 | WORLD IS |
| FILM | BOND MOVIE |
| BROSNAN | VIC FLICK |
| CONNERY | STEVIE WONDER |
| MGM | FILM CLIP |
| DESMOND | OF BOND |
| FILMS | IAN FLEMING |
| PIERCE | ROBERT CARLYLE |
| SEAN | DENISE RICHARDS |
| JAMES | SOPHIE MARCEAU |
| ACTOR | SECRET AGENT |
| BORGE | ZETA JONES |
| MOVIE | Q IN |
| WONDER | BOND S |
| ROBARDS | BOND GIRL |
| Q | FLEMING S |
| STEVIE | JUDITH JAMISON |
| FLICK | ACTOR DESMOND |
Информационный Портрет как концентрат текста
Для того чтобы решить поставленные проблемы, необходимо выделить из переписки обюекта некий концентрат, из которого автоматически отфильтровывается общий для всех других обюектов «фон».
Иначе говоря, такой концентрат должен в какой-то степени решать проблему выделения полного набора признаков. При построении концентрата необходимо учитывать специфику текстового материала: он состоит из элементарных конструкций языка, таких, например, как слова и словосочетания. Остается только выделить из этих конструкций особо значимые, образующие Информационный Портрет обюекта.
Основные принципы формирования Информационного Портрета из языковых конструкций таковы.
- Полнота создаваемого образа (никакие существенные детали не должны быть пропущены).
- Избыточность текстового материала (при наличии всего лишь нескольких страниц, относящихся к обюекту, особые технологии не нужны).
- Оценка значимости отдельной конструкции на основе сравнения ее представления в других обюектах (это необходимо для фильтрации общего «фона»).
- Статистическая достоверность и устойчивость полученных результатов (результаты не должны резко меняться при получении дополнительного материала).
- Работа в реальном времени (если оценки занимают слишком много времени, анализ может опоздать).
Одна из технологий, позволяющих построить Информационный Портрет, применяется в системе «Галактика-Зум». Некоторое время назад ее начали использовать информационные службы РТР, НТВ, ТВЦ, Радио России, службы безопасности нескольких отечественных банков и аналитических центров. Так, справочно-информационная служба «Вести» содержит огромный обюем сведений о жизни России и зарубежных стран, начиная с 1991 года. Общий обюем справочных баз составляет около 6 миллионов документов (свыше 17 Гбайт), ежедневно обрабатывается около 15 Мбайт текстовой информации. Анализ нужной информации занимает от 30 минут до нескольких часов.
Приведем пример Информационного Портрета, построенного по этой технологии. Для того чтобы отстраниться от конкретных лиц и организаций, ограничимся базой англоязычных документов б- сообщений мировых информационных агентств за 1999 год:
Обюект б- Джеймс Бонд, агент 007.
База б- 800 тыс. сообщений,
1,8 Гбайт текста.
Исходный запрос «bond & 007»
Найдено 191 сообщение.
После проведения анализа в течение 20 секунд была получена таблица значимых конструкций, слова и словосочетания в которой ранжированы по значимости в смысле основных принципов формирования Информационного Портрета из языковых конструкций.
Конечно, не следует ждать абсолютной информационной полноты и кристальной чистоты такого портрета в виду ограниченности выборки и несовершенства программы. Однако видно, что обюект оценивается достаточно подробно. Приведены профессия б- SECRET AGENT, место «функционирования» обюекта б- FILM, MOVIE, исполнители б- BROSNAN, CONNERY, начало названия последнего фильма «WORLD IS ...», литературный автор б- IAN FLEMING, другие главные герои б- Q. Даже предварительно ничего не зная про обюект и не изучая первичных документов можно получить достаточно развернутый Информационный Портрет, на основании которого можно проводить дальнейшие исследования.
| Главные темы (слова) | Главные темы (словосочетания) |
| SPANISH | FORMER CHILEAN |
| PINOCHET | CHILEAN DICTATOR |
| SPAIN | SPANISH JUDGE |
| ETA | TYPE SPANISH |
| BASQUE | SPANISH NAT |
| CHILEAN | DICTATOR AUGUSTO |
| COLOMBIA | JOSE MARIA |
| CHILE | ACCESS COLOMBIA |
| GARZON | MARIA AZNAR |
| MADRID | FORMER DICTATOR |
| PUERTO | BASQUE COUNTRY |
| TORTURE | MINISTER JOSE |
| LORDS | ACCESS SPAIN |
| EXTRADITION | SPANISH PRIME |
| AUGUSTO | GROUP ETA |
| FUJIMORI | SPANISH GOVERNMENT |
| CUBA | FIDEL CASTRO |
| AZNAR | MADRID SPAIN |
| DICTATOR | CHILEAN GOVERNMENT |
| CLEMENCY | BASQUE NATIONALIST |
Сравнение Информационных Портретов
Итак, на основе языковых конструкций б- слов и словосочетаний построен образ исследуемого обюекта б- Информационный Портрет, но для решения сформулированных задач одного такого образа недостаточно. Для выбора аномального обюекта, а также для определения связей заданных обюектов необходимо уметь сравнивать образы обюектов и оценивать их близость. Наиболее далекие от остальных обюектов определяются как аномальные, а наиболее близкие к заданному обюекту как связанные.
Операции сравнения и оценки близости требуют введения меры расстояния между обюектами. Такую меру можно ввести, представив Информационные Портреты, как вектора в пространстве языковых конструкций б- тогда мера расстояния между такими векторами определится величиной проекции одного вектора на другой. Часто такую методику называют методом наименьших квадратов.
| Главные темы (слова) | Главные темы (словосочетания) |
| GERMAN | GERHARD SCHROEDER |
| GERMANY | GERMAN CHANCELLOR |
| BERLIN | CHANCELLOR GERHARD |
| SCHROEDER | ARMY FACTION |
| FISCHER | RED ARMY |
| NATO | BERLIN GERMANY |
| CHANCELLOR | FRANCE GERMANY |
| RUSSIAN | RUSSIAN PRESIDENT |
| RUSSIA | ACCESS GERMANY |
| GERHARD | GERMANY ITALY |
| YELTSIN | MINISTER IGOR |
| MEYER | LUDWIG MEYER |
| BONN | GREEK EMBASSY |
| MOVED | HORST LUDWIG |
| CHECHNYA | BERLIN WALL |
| TURKEY | ISTANBUL TURKEY |
| MOSCOW | WEST GERMANY |
| MINISTERS | CZECH REPUBLIC |
| OCALAN | PRESIDENT BORIS |
| JOSCHKA | IGOR IVANOV |
Определение аномального обюекта
Вновь обратимся к базе англоязычных документов б- сообщений мировых информационных агентств за 1999 год.
Множество обюектов б- крупные европейские страны: Испания, Франция, Италия, Германия и проблема террора.
База б- 800 тыс. сообщений, 1,8 Гбайт текста.
Исходный запрос «Terrorism, terrorist, terror»
Найдено 6839 сообщений.
Затем запросы уточняются по странам.
Испания б- 1576 сообщений, Франция б- 3532, Италия б- 1764, Германия б- 2742.
После проведения анализа Информационных Портретов в течение 5 минут была получена таблица расстояний между ними.
Видно, что наиболее удаленный обюект б- Испания, точнее, ее Информационный Портрет в разрезе проблемы террора среди аналогичных Информационных Портретов других стран. Проиллюстрируем полученные результаты Информационным Портретом Испании.
| Террор & | Испания | Франция | Италия | Германия |
| Испания | 0,00 | 0,77 | 0,79 | 0,81 |
| Франция | 0,77 | 0,00 | 0,57 | 0,41 |
| Италия | 0,79 | 0,57 | 0,00 | 0,58 |
| Германия | 0,81 | 0,41 | 0,58 | 0,00 |
В 1999 году испанцев больше всего беспокоила деятельность группировки баскских сепаратистов ETA, а также экстрадикция Пиночета. Естественно, эти проблемы волновали остальные европейские страны в меньшей степени. Посмотрим теперь на Информационный Портрет Германии.
Немцев, помимо RED ARMY FACTION (RAF), беспокоит чеченский вопрос и позиция России. Близкие результаты, за исключением германской специфики дают Информационные Портреты Франции и Италии, что можно обюяснить тесной интеграцией политики этих стран в отношении проблемы терроризма. Это видно и из приведенной таблицы (словосочетания «FRANCE GERMANY», «GERMANY ITALY»).
Приведенные примеры показывают продуктивность предложенной технологии для решения задач службы безопасности. Конечно, область применения этих методов сильно зависит от информационного содержания доступных источников, однако главный результат б- появление практического инструмента автоматического анализа больших информационных массивов в реальном времени. Этот инструмент обладает способностью самонастройки на определяющий набор признаков и позволяет найти подход к решению классической задачи «пойди туда, не знаю куда, найди то, не знаю, что». С его помощью сотрудник службы безопасности получает возможность выявить неявные связи и аномальные обюекты.
Александр Антонов – сотрудник корпорации «Галактика». С ним можно связаться по адресу: alexa@galaktika.ru
