Организация интерфейсов в поисковых системах
Вагиф
Касумов
Физическое развитие Internet, увеличение объема
информации, доступной через Сеть, а также расширение круга пользователей ставит
задачу эффективного использования ресурсов и каналов. В данной статье
рассматриваются вопросы организации интерфейса между пользователем, поисковой
системой и сетевыми ресурсами, а также обсуждаются методы изменения
эффективности канала связи.
В связи с большим объемом функциональных
возможностей и непрерывным развитием информационных и компьютерных сетей,
сервис, предоставляемый Internet, становится все более труднодоступным для
широкого круга пользователей. Это можно объяснить тем, что доступ к большинству
информационных систем осуществляется через интерфейс с меню, в котором
пользователь ограничен определенными системными рамками, что противодействует
повышению производительности. С другой стороны, меню успешно применяется в тех
случаях, когда пользователь непосредственно работает с одним или небольшим
числом информационных ресурсов.
Одна из услуг Сети - поиск информации, выполняемый
поисковыми системами (ПС). Эффективность ПС зависит от методов организации
поиска, обнаружения источников и их индексирования, организации
пользовательского интерфейса [1-2]. Однако эффективность зависит также и от
интерфейсов с пользователем и системными ресурсами. Это особенно заметно для ПС
с географически распределенной структурой [3].
Интерфейс пользователя (ИП) - это граница, на
которой пользователь и система осуществляют взаимодействие между собой.
Особенности ПС вытекают из "интеллекта" пользовательских рабочих мест. Для
"тупых" терминалов все функции взаимодействия пользователя с системой
возлагаются на узел, к которому терминал прикреплен, или на другие узлы сети.
Для "умных" рабочих мест ИП реализуется непосредственно на станции (Netscape,
Explorer и т.п.). Если синтаксический аспект разработки ИП не находит обычно
детального анализа (считается, что синтаксические вопросы в распределенной
обработке не порождают принципиально новых задач, связанных с технологией
распределенной обработки), то вопрос о семантическом аспекте реализации ИП в ПС
выглядит гораздо шире и сложнее. Во-первых в ПС объем информационно-программных
ресурсов слишком большой, что исключает возможность знакомства или запоминания
пользователем каких-либо признаков организации информации, серверов или БД.
Во-вторых, распределенность и динамичность ресурсов отделяет пользователей от
сетевых адресов и форматов обращения к данным. По этим причинам семантический
аспект реализации ИП в ПС считается определяющим фактором для разработчиков. С
другой стороны, ИП не является самостоятельным продуктом, а образует часть
прикладных программ (ПП) и сетевых серверов, следовательно, рекомендации и
правила, выработанные для разработки ИП одновременно являются и требованиями
(или ограничениями) для прикладных программистов.
Составные компоненты системы
общения
Распределенные системы, в частности ПС, могут иметь
в своем составе следующие интерфейсные средства [3]:
? интерфейс пользователя с
поисковой машиной (ПМ);
? интерфейс ПМ с системными
ресурсами;
? интерфейс пользователя с
сетевыми ресурсами (браузеры и т.п.).
К этим средствам
предъявляются следующие требования:
? максимальная приближенность к
естественному языку;
? максимальная полнота и
гибкость;
? независимость от архитектуры
системы и организации сетевых ресурсов;
? высокая реакция системы и
высокая надежность;
? синтаксическая и семантическая
устойчивость.
Для учета данных
требований в ПС должен быть использован интеллектуальный ИП, который может иметь
двухуровневую структуру. На первом уровне пользователю предоставляется
специальный словарь для общения с ПМ, в результате чего выясняются имена
ресурсов, по которым должен быть реализован пользовательский запрос. На втором
уровне пользователю предоставляются средства общения с сетевыми серверами для
полного удовлетворения его запроса. Общая структура системы общения в ПС
представлена на рис.1.
|
|
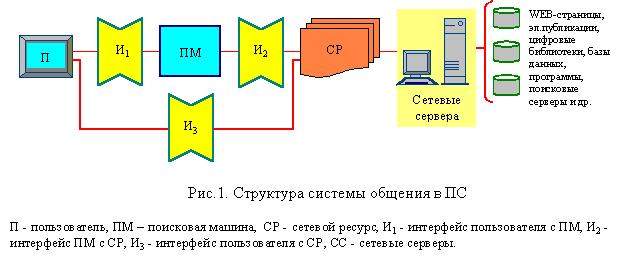 |
Как обычно ПМ (по крайней мере ее интерфейсные
программы) располагается во всех серверах обслуживания пользователей, и,
следовательно, может отсутствовать географическая разобщенность между
пользователем и ПМ. Однако, СР, как правило, разбрасывается по узлам сети и
часто пользователь и СР оказываются географически рассредоточенными. Таким
образом, интерфейсы И2 и И3 должны обладать
быстродействием ведения диалога. ПМ через интерфейс И2 устанавливает
связь между пользователем и соответствующим СР с помощью заранее подготовленных
запросов, который выполняется один раз перед установкой сеанса между
пользователем и СР, после чего начинается взаимодействие пользователя с СР через
интерфейс И3. Однако И2 - это диалог и чем больше
расстояния между пользователем и СР, тем менее эффективным будет взаимодействие
из-за низкого коэффициента использования канала связи. Одним из способов
устранения этого недостатка является вызов программы диалога на узел
пользователя для оформления запроса. Однако это дает положительный эффект лишь в
том случае, когда пользователь имеет множество запросов. Для одноразовых
запросов такая пересылка монитора диалога из узла в узел является нерациональным
усложнением управления системой.
Структура интерфейса и
эффективность канала связи
При переходе от локальной обработки к
распределенной вопрос структурной организации интерфейса пользователя и
технология его взаимодействия с пользователем в распределенной среде имеет
определенное значение. Наличие разнообразных СР, а также постоянная
наращиваемость последних предопределяет целесообразность применения в ПС
интерфейса пользователя с СР как с установлением соединения (on-line) так и без
него. Эти типы интерфейса придерживаются двух противоборствующих подходов.
Во-первых, если общение пользователя с СР будет проводиться в режиме on-line, то
канал связи между пользователем и СР будет излишне загружен, и, следовательно,
стоимость общения будет высока. Кроме того, даже в ПС с малым коэффициентом
загрузки, но с высоким коэффициентом распределенности, это обстоятельство может
привести к резкому снижению эффективности системы в целом. С другой стороны,
если для формирования запроса переслать программу диалога в узел пользователя (в
режиме off-line), то в этом случае усложняется системное управление и канал
будет излишне загружен пересылкой части СР (программы диалога). Здесь возникает
вопрос, какой из этих двух вариантов диалога с точки зрения эффективного
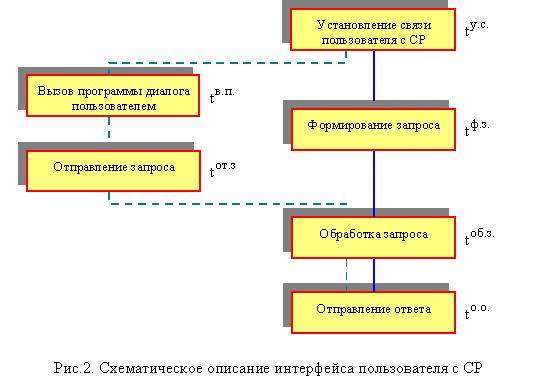
использования средств связи рационален. Для исследования этого вопроса на рис.2
приведено схематическое описание интерфейса пользователя для обоих вариантов
[3].
 |
|
|
На рис.2 справа от
процедур приведены обозначения времен соответствующих процессов. Видно, что
время, затрачиваемое на взаимодействие пользователя с СР для обоих случаев
определяется суммой времени, затрачиваемых на выполнение отдельных процедур.
Учитывая специфические особенности по отношению к каналу связи и исключая общих
членов (время на установление связи, время на обработку запроса и время на
отправки ответа) получим, что время взаимодействия без пересылки программы
диалога Tб/п измеряется
значением tф.з, время
взаимодействия с пересылкой программы Tс/п равно сумме tв.п и
tот.з.
Время формирования запроса
качественно пропорционально количеству поисковых признаков Nq в
запросе и интенсивности запросов l, так как при вызове
программы диалога пользователь может формировать не один, а несколько запросов.
Если t - время, которое затрачивается пользователем на
подготовку части запроса, определяемой одним поисковым признаком, то
Tсб/п=tNql.
Время вызова программы диалога
можно определить как отношение средней длины программы диалога Lд.п
на пропускную способность канала С. Аналогичным образом время отправления
запроса определяется как отношение средней длины запроса Lз на
пропускную способность канала С. Таким образом,
Tсс/п=(Lд.п +Lз)/С.
Таким образом, можно делать вывод, что временная
разница DT=Tсб/п-Tсс/п
будет расти пропорционально интенсивности
запросов, так как в этом случае время взаимодействия с пересылкой не зависит от
интенсивности запросов, а время взаимодействия без пересылки пропорционально
интенсивности запросов l.
Можно также сказать, что при слишком большой
интенсивности запросов временная разница DT
стремится к бесконечности. Другими словами,
эффективность использования каналов связи при интерфейсе пользователя с
распределенной структурой растет пропорционально росту интенсивности
пользовательских запросов.
Приведем сравнительный расчет параметров для
академической сети Азербайджана. Среднее число поисковых признаков в запросе
Nq равно 5. Доля времени на формирование части запроса на один
признак t=5с.
Пропускная способность канала С=33.6Кбит/с.╩4000Байт/с. Средняя длина
программы диалога Lд.п=25.6 Кбайт и средняя длина запроса
Lз=64 байт. Тогда Tсб/п=25 сек. и
Tсс/п╩6 сек.
Теперь проанализируем временную разность
DT в
зависимости от нагрузки системы на примере сети с данными параметрами. На рис.3
приведены результаты сравнительного расчета времени реакции системы, для
различных вариантов реализации интерфейса пользователя, проведенного на
имитационной модели упомянутой сети. Параметр r характеризует
географическую распределенность нагрузки и определен как процентное отношение
интенсивности запросов к системе, реализуемых географически удаленными СР, на
общую интенсивность запросов. Кривые, расположенные слева от заштрихованных
областей соответствуют локальным пользовательским интерфейсам, а расположенные
справа - распределенным интерфейсам. В четвертом случае кривая одна (оба кривые
совпадают), так как отсутствует поток распределенных запросов.
Таким образом на примере академической сети
подтверждается теоретический вывод о прямой зависимости временной разности
DT от
нагрузки системы. Однако, поскольку эта зависимость неявная, следует дать анализ
ее графической иллюстрации. Во-первых, линейность зависимости временной разности
от интенсивности запросов не видна, т.к. кривые описывают время реакции системы,
которая включает в себя также времена задержек в каналах. Во-вторых, главным
воздействующим параметром на временную разность DT является не сама
нагрузка, а ее часть, определяемая долей распределенных пользовательских
запросов ri, i=1,2,3 и, следовательно,
заштрихованная область, ширина которой соответствует указанной разности,
сужается слева направо, и в случае ri=0 полностью исчезает. Наконец,
изменение ширины заштрихованной области в пределах каждого случая соответствует
изменению временной разности в зависимости от нагрузки.
Описание поискового
алгоритма
Интерфейс И3 предназначен для
предоставления пользователю нужного ему СР для удовлетворения своего запроса.
Важным здесь считается тот факт, что пользователь не имеет подробного
представления об информационном обеспечении системы - он только знает, что ему
нужно. Стоимость использования сетевых и системных ресурсов, а также каналов
связи очень высока. Одновременное обслуживание многочисленного потока запросов
пользователей приводит к перегрузке информационных сетей, сетевых ресурсов и
каналов связи и, в конечном счете, производительность информационных систем,
в.т. поисковых систем сильно снижается. Поэтому ПС помимо удовлетворения
запросов пользователей, должны решать проблему оптимальной адресации запросов
пользователей к источникам и другим информационным системам [4].
Для организации интерфейса типа И3
используются браузеры и поисковые машины, которые по своему принципу построения
являются базами данных, содержащих информацию о СР и об их адресах расположения.
Сегодня появилась тенденция использовать базу знаний об информационных ресурсах
системы. В этом случае пользовательский запрос формально можно представить
четверкой [3] Z={R,S,T,P}, где R - множество объектов, S - множества свойств, T
- временные, а P - пространственные характеристики объекта. Так, например,
запрос о том, каковы были расходы предприятий из бюджета I квартале 1991 г. по
нефтедобывающей промышленности, по данной модели представляется в следующем
виде: zi - запрос, ri - предприятие, si -
бюджетные расходы, ti - 1 кв. 1991 г., pi -
нефтедобывающая промышленность.
Однако полное перечисление прелагаемой модели для
Internet, оказывается практически невозможным. Хотя не все комбинации {R,S,T,P}
определяют запросы, однако, для семантической устойчивости диалога бессмысленные
комбинации должны быть обеспечены соответствующими системными ответами
пользователю. Кроме того, в этом случае включение в систему новых СР потребует
доработки интерфейсных программ.
Положение облегчается,
если вместо полного описания используется база знаний о запросе. Для
представления такого типа знаний используем реляционную модель с нечеткими
элементами - отношения нечеткого предпочтения СР по объектам, свойствам,
временным и пространственным характеристикам. Это отношение представляется
функциями важности этих характеристик для СР: jR,
jS, jT и
jP, значения которых лежать на числовой
оси [0,1].
С другой стороны,
соответствие СР к объектам, свойствам, временным и пространственным
характеристикам можно представить нечеткими отношениями, определяемые функциями
соответствия mR, mS,
mT
и mP, которые получают значения в пределе
[0,1].
Таким образом, выбор требуемой СР сводится к выбору
наиболее соответствующей СР заданному списку элементов из {R, S, T, P}. На языке
нечетких множеств данная задача сводится либо к выбору эффективных альтернатив,
либо к многокритериальной оптимизации с нечеткими критериями, которая решается
минимаксным методом.
Для определения значений j и m применяется метод
экспертных оценок, и во время эксплуатации их значения подвергаются адаптации -
обучению методом поощрения и штрафов. Если при выборе пользователь не находит
искомого ответа, то ему предоставляется возможность возврата и формирования
нового списка из элементов {R, S, T, P}. Если при повторном заходе к системе с
новым списком элементов запрос пользователя будет удовлетворен, то
осуществляется сравнение нового списка со старым и определяются исключенные из
нового списка элементы. Затем отношения между СР и исключенными элементами
подвергаются штрафованию.
Выбор наилучшего направления
поиска
Информационные ресурсы Internet насколько объемны и
динамичны, что даже непрерывная адаптация БЗ в поисковых машинах не обеспечивает
единственность выбора направлений поиска в Web пространстве. Другими словами ПМ
всегда предоставляет пользователям не одно, а множество направлений поиска по
введенному набору признаков, в частности ключевых слов.
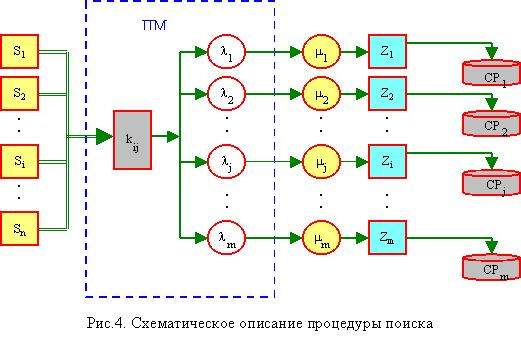
Для осуществления наилучшего выбора направлений
поиска определим оценку релевантности следующим образом. Пусть ПМ содержит
таблицу отношений поисковых признаков к направлениям, в частности к Web-сайтам в
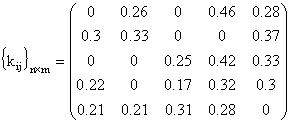
виде двухмерной матрицы ||kij||nxm, где kij -
неотрицательные числа (рис.4), характеризующие вес i-го признака к j-му
направлению, которые вычисляются на основе соответствующих наборов степеней
соответствия поисковых признаков к Web-сайтам, т.е. если zij -
коэффициенты важности поисковых признаков для Web-сайтов, тогда kij
можно выразить как отношение zij на сумму коэффициентов важности
признаков к Web-сайтам по всем направлениям.
Выбор направления поиска сводится к определению
значений (или значимости) направлений mj, j=1,2,┘,m по совокупности поисковых
признаков, которые определяются как сумма весов признаков для направлений
kij по всем направлениям. Здесь mj
характеризуют способности Web-сайтов удовлетворить запросы.
С другой стороны определим также запрос
пользователя как набор чисел S={si,i=1,2,┘,n}, соответствующих
важности ключевых признаков в запросе пользователя. Если lij -
среднеквадратичное отклонение запроса от направлений по отдельным признакам,
тогда значимости направлений выбора lj для запроса пользователя можно
определить как сумма lij для всех i. Отклонение направлений от
запроса определяется с учетом значимостей направлений для запроса и суммарных
весов признаков для направлений по следующей формуле: rj=lj/(mj-lj), j=1,2,┘,m.
Чем меньше rj, тем больше степень релевантности
направления к запросу.
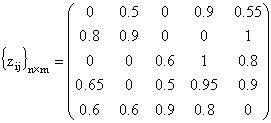
Для демонстрации
адекватности предложенного алгоритма приведем пример. Пусть
W={w1,w2,w3,w4,w5}
- Web-сайты в системе (m=5), которые определяются поисковыми признаками
T={t1,t2,t3,t4,t5}
(n=5). Коэффициенты важности признаков для Web-сайтов задается следующей
матрицей:
 Важность этих признаков в пользовательском запросе
задается вектором:
Важность этих признаков в пользовательском запросе
задается вектором:
S={0.9, 0, 0.9, 0.95,
0.6}.
Получим следующую матрицу весов
поисковых признаков для направлений:
Среднеквадратичное отклонение запроса от
направлений по отдельным признакам имеет вид: {lj}m={0.48, 0.48, 0.39, 0.19,
0.32}.
Значимости направлений по совокупности поисковых
признаков mj, j=1,2,┘,m получают следующие
значения: {mj}m={0.72, 0.80, 0.73, 1.47,
1.29}.
Таким образом, отклонение направлений от запроса в
целом будет:
{rj}m={2, 1.5, 1.13, 0.15,
0.34}.
Видно, что третье направление имеет минимальное
отклонение и это направление является наиболее релевантным запросу
пользователя.
Об авторе:
Вагиф Касумов,
Информационно-Телекоммуникационный Научный Центр Академии Наук Азербайджана. С
ним можно связаться по адресу: vagif@dcacs.ab.az
Литература
[1] Храмцов П. Моделирование и анализ работы
информационно-поисковых систем Internet. Открытые Системы. Москва. № 6. 1996.
http:/www.osp.ru/os/1996/06/46.htm
[2] V.N.Gudivada. Information search on
World Wide Web. Compouter Weekly. Moscow. № 35. 1997. pр.19-21,
26,27.
[3]. Abbasov A., Alguliev R., Gasumov V., Aliyev E.
System management for large computer network: exprience on design and creation
of the Azerbaijan Republic Information Computer Network. Proceedings of INET'93.
San Francisco. 1993. pp.A27-A32.
[4] Романенко А.Г. Адресация запросов в
распределенных информационных системах и сетях. Информационный поиск. НТИ.
Москва, Сер.2, № 5, 1988, стр. 7-14.