
Статья посвящена анализу многонитевой (multithreading) архитектуры — одному из перспективных направлений развития современных микропроцессоров. Приведены основные варианты архитектурных схем и подробно рассмотрены микропроцессоры Compaq Alpha 21464, а также многонитевые модернизации Intel Xeon MP и Itanium Processor Family.
Основные направления развития архитектуры современных микропроцессоров универсального назначения определяются стремлением к увеличению их производительности [1,2], которую можно повышать, грубо говоря, двумя путями: увеличение тактовой частоты, увеличение количества команд, выполняемых за один такт. На практике используется комбинация обоих путей.
Наращивание тактовой частоты имеет технологические ограничения, а росту производительности подобных суперконвейерных процессоров препятствуют архитектурные барьеры (простои конвейеров, задержки при непопадании в кэш и т.п.). Второму пути отвечают суперскалярные процессоры, которые могут выполнять сразу несколько команд за такт за счет использования нескольких функциональных исполнительных устройств (ФИУ). Однако реальные коды программ не позволяют обеспечить эффективную загрузку процессоров, ФИУ простаивают.
Практически все современные процессоры — это суперскалярные RISC-системы. Формально это утверждение несправедливо по отношению к архитектуре x86, однако реально Intel и AMD выпускают процессоры, которые выполняют аппаратную трансляцию CISC-команд во внутренние RISC-подобные команды. IA-64 относится уже к следующему поколению архитектур. Поэтому можно сказать, что основная задача разработчиков современных процессоров — реальное увеличение числа команд, выполняемых программами за такт (IPC — Instructions Per Cycle). Так, для Compaq Alpha 21264 этот показатель равен 6 [3, 4], столько же микроопераций за такт может выдать Pentium 4 [5], а в Alpha 21464 планировалось уже 8 или 10 [4]. Но это предельные значения, а реальные программные коды, в частности, из-за различных взаимозависимостей, дают гораздо более низкое значение IPC (см. таблицу 1). Дальнейшее увеличение числа ФИУ оказывается неэффективным. Кроме того, отслеживание взаимозависимостей различных команд программного кода с увеличением числа ФИУ стремительно растет, отнимая все больше аппаратных ресурсов.
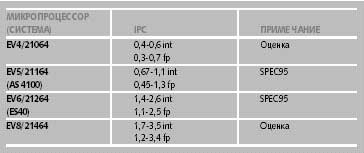
|
| Таблица 1. Достигаемые значения IPC в Alpha |
В результате, на пути повышения IPC в современных RISC-процессорах проявился очень серьезный кризис, который ведет к тому, что архитектурный облик высокопроизводительных микропроцессоров ближайшего будущего станет кардинально отличным от того, что мы имеем сейчас. Некоторые специалисты говорят о наступлении эпохи «пост-RISC».
К сегодняшнему дню наметилось три основных пути выхода из кризиса. Первый, наиболее близкий к обычной RISC-архитектуре, реализовала корпорация IBM в Power4 [1,2]. Этот подход, получивший название «мультипроцессирование на уровне микросхем» (CMP), заключается в размещении на одном кристалле сразу нескольких процессоров. В Power4 таких процессоров два. При этом задача повышения производительности работы отдельных приложений требует распараллеливания последних, т.е. проблема перемещается с аппаратного на программный уровень. Конечно, эффективность распараллеливания потенциально может оказаться очень высокой из-за мощных аппаратных возможностей коммуникаций процессоров внутри микросхемы. Кроме того, даже без распараллеливания Power4 демонстрирует повышенную производительность в мультипрограммном режиме при выполнении смеси задач. Опыт IBM доказывает, что этот путь может быть очень перспективным (на момент подготовки статьи Power4/1,3 ГГц был лидером по производительности вычислений с плавающей запятой — SPECfp2000=1169). Для CMP-устройств характерно также наличие большого разделяемого кэша второго уровня. Кроме Power4, данный подход, вероятно, найдет применение также в будущих 64-разрядных процессорах AMD SledgeHammer.
Исторически Power4 можно в некотором роде считать «асимметричным» ответом IBM на проект Intel/HP по внедрению архитектуры EPIC [6, 7], которая реализует другой путь выхода из кризиса. Однако задержки с появлением процессоров архитектуры Itanium Processor Family не позволили им, как предполагалось разработчиками, выйти в лидеры производительности: на тестах SPEC2000 они уступают Power4 и Pentium 4. Тем не менее в Intel дают понять, что с появлением следующего поколения 64-разрядных процессоров — McKinley — ситуация изменится.
В IA-64 архитектура EPIC использует архитектуру сверхбольшого командного слова, и для достижения высокого IPC предполагается явное программирование с высоким уровнем параллелизма на уровне команд (ILP). Таким образом, достижение высокой производительности одной задачи также осуществляется во многом за счет ПО. В отличие от суперскалярных RISC-процессоров с внеочередным спекулятивным выполнением команд, аппаратура которых динамически пытается обеспечить высокое значение IPC, в EPIC применяется статический подход — компилятор должен сгенерировать необходимые высокоэффективные коды, а сама архитектура предоставляет развитые средства для достижения высокого показателя ILP.
Третий путь связан с концепцией TLP (Thread Level Parallelism — «параллелизм на уровне нитей»). Некоторые эксперты считают TLP основной альтернативой EPIC. Идеи TLP также весьма естественны. Если сегодняшние программные коды не в состоянии загрузить работой все или даже большинство ФИУ, то можно разрешить процессору выполнять более чем одну задачу (нить), чтобы дополнительные нити загрузили-таки все ФИУ. Нетрудно усмотреть здесь аналогию с многозадачной операционной системой: чтобы процессор не простаивал, если задача оказывается в состоянии ожидания (например, завершения ввода-вывода), операционная система переключается на выполнение другой задачи. Более того, некоторые механизмы диспетчирования в ОС (например, квантование) имеют, как мы увидим, аналоги в многонитевой архитектуре (MultiThreading Architecture — MTA). Очевидно, MTA, поддерживающая TLP, должна гарантировать, чтобы нити не использовали одновременно одни и те же ресурсы, для чего требуются дополнительные аппаратные средства (например, дублирование регистровых файлов и т.п.). Однако оказалось, что можно реализовать МТА на базе современных суперскалярных процессоров лишь путем их относительно небольших аппаратных доработок, что резко повышает привлекательность МТА в глазах проектировщиков.
Основы многонитевой архитектуры
«Базовым» типом TLP можно считать грубозернистый (coarse grained) [4]. При этом в микропроцессоре имеется не менее двух аппаратных контекстов нитей. Контекст включает, в частности, регистры общего назначения, счетчик команд, слово состояния процесса и т.п. В любой момент времени работает только одна нить, чей контекст активен. Нить выполняется до возникновения «прерывания» (например, выполнение команды загрузки регистра при отсутствии данных в кэше). При прерывании процессор осуществляет замену контекста нити на контекст другой нити и начинает выполнение последней. Поскольку при непопадании в кэш операции с памятью могут потребовать порядка 100 тактов процессора, его простои по причине ожидания данных могли бы быть весьма значительными. Современные процессоры, имеющие возможности спекулятивного внеочередного выполнения команд, в подобной ситуации могут продолжить выполнение других команд, но на практике число независимых команд быстро исчерпывается и процессор останавливается. В [4] указывается, что, возможно, данный тип TLP доступен (для двух контекстов нитей) в PowerPC RS64 «Northstar».
Следующий тип TLP и соответственно MTA — тонкозернистый (fine grained). В подобном процессоре поддерживается N контекстов нитей, а команды каждой нити распределяются на выполнение каждый N-й такт [4]. Суммарная «пропускная способность» процессора при этом возрастает, поскольку для нитей будут (возможно, частично) скрыты задержки выполнения некоторых длинных команд. Пусть, например, умножение с плавающей запятой занимает 4 такта (N=4). Тогда на первом такте, когда контекст нити активен, запустится команда умножения. Через 4 такта, когда контекст нити снова станет активным, устройство с плавающей запятой как раз завершит выполнение умножения, и нить сможет выполнять следующую команду. Нетрудно усмотреть в этом варианте МТА аналогию с простейшей формой квантования времени в многозадачных ОС. Аппаратная «стоимость» такого решения невелика: необходима поддержка N контекстов нитей, плюс логика для переключения команд и данных различных нитей. Недостаток такого подхода также ясен: хотя суммарная пропускная способность процессора на смеси нитей возрастает, производительность для отдельной нити уменьшается. Подобная архитектура реализована в процессоре МТА компании Tera [1].
Наиболее продвинутой является архитектура с одновременным выполнением нитей (SMT — Simultaneous Multi-Threading). Само ее название указывает на допустимость одновременного выполнения нескольких нитей, когда на каждом новом такте на выполнение в какое-либо ФИУ может направляться команда любой нити. В SMT, если программные коды нити обеспечивают высокий уровень ILP, такая нить будет потреблять большинство ресурсов процессора. «Плохие» же в смысле ILP нити будут разделять ресурсы с другими подобными себе. По сравнению с суперскалярными процессорами, поддерживающими внеочередное спекулятивное выполнение команд и использующими механизм переименования регистров, для SMT необходимы, в частности, следующие аппаратные средства [4]:
- несколько счетчиков команд (по одному на нить) с возможностью выбора любого из них на каждом такте;
- средства, ассоциирующие команды с нитью, которой они принадлежат (необходимо, в частности, для работы механизмов предсказания переходов и переименования регистров);
- несколько стеков адресов возврата (по одному на нить) для предсказания адресов возврата из подпрограмм;
- специальная дополнительная память в процессоре (в расчете на каждую нить) для осуществления процедуры удаления из буфера выполненных внеочередным образом команд.
Замечательной для SMT особенностью многих современных процессоров является переименование регистров, когда логические (архитектурные) регистры отображаются в физические, с которыми и ведется реальная работа. Техника переименования регистров может, очевидно, применяться для того, чтобы избежать прямого дублирования файлов регистров как части аппаратного контекста нити.
SMT: проект Alpha 21464
Одним из первых процессоров, в котором планировалось реализовать идеи SMT, мог стать Alpha 21464 (EV8). Однако в 2001 году Compaq заявила о своем отказе от самостоятельных планов развития линии Alpha и выпуска EV8 и о начале сотрудничества с Intel по разработке новых микропроцессоров архитектуры IA-64, которые поддерживали бы SMT. Проект EV8, тем не менее, представляет интерес как пример возможной эффективной реализации SMT «над» RISC-архитектурой. В EV8 планировалось увеличить число целочисленных ФИУ с 4 (в EV6/EV7) до 6 (4 из которых могли бы выполнять команды загрузки регистров/записи в память), а число ФИУ с плавающей запятой — с 2 до 4. Соответственно EV8 мог выдавать бы на выполнение до 10 команд за такт (поддерживаемый уровень — 8 команд за такт). Ясно, что при столь большом числе ФИУ средства типа SMT становятся необходимыми. EV8 и был задуман как процессор, поддерживающий SMT с аппаратными контекстами для 4 нитей. Возможности по одновременному выполнению нитей различных процессов (различных адресных пространств), насколько известно, явно не описывались. В [4] содержится предположение, что такие возможности были заложены и реализованы с помощью регистров номера адресного пространства (по одному регистру на нить).
Микроархитектура EV8 является естественным развитием архитектуры процессоров Alpha предыдущего поколения. В Alpha 21264 (EV6; микроархитектура EV7, т.е. Alpha 21364, мало отличается от EV6 — главным образом, интегрированным кэшем большой емкости и наличием каналов связи между процессорами) применяется переименование регистров. В EV6 предусмотрено 72 физических регистра с плавающей запятой и 80 физических регистров общего назначения (точнее, два дублирующих набора по 80 регистров). Логических регистров, конечно, меньше — 31 регистр общего назначения, плюс нулевой регистр, который всегда равен 0 [3]. Состояние отображения регистров в EV6 хранится в специальной таблице (контекстно-адресуемой памяти). В EV8 вместо 4 таких таблиц (по одной на нить) сохранена одна общая, в которой хранится идентификатор нити (2 бита), не считая 5 бит на логический регистр. Тогда контекст нити 0 отображает логические регистры 0-31, контекст 1 — соответственно регистры 32-63 и т.д. Оценки показывают, что для EV8, чтобы он не простаивал в ожидании освобождения регистров, понадобятся дополнительно еще 96-128 физических регистров общего назначения. Даже в IA-64 число регистров меньше (128). Аппаратная реализация столь большого многопортового файла регистров ограничивает рост тактовой частоты, поэтому разработчики пошли на расщепление доступа по чтению/записи на две стадии, увеличив общую длину базового конвейера до 9 стадий (против 7 в EV6) [4].
Диспетчирование нитей в процессоре может происходить различными путями. Во-первых, по схеме Round Robin (простая циклическая очередь). При этом либо одна нить выполняет все 8 команд за такт, либо 2 нити выполняют по 4 команды за такт и т.д. Во-вторых, возможно приписать нитям приоритет [4].
Очень важный аспект SMT состоит в том, как соответствующий процессор выглядит с точки зрения операционной системы. В EV8 введена абстракция виртуального однонитевого процессора (TPU — Thread Processor Unit). ОС «видит» эти виртуальные процессоры, точнее, их видят известные для всех поколений Alpha средства уровня абстракции архитектуры (HAL — Hardware Abstraction Level). Каждый процессор Alpha EV8 представляется четырьмя TPU, имеющими общие таблицы TLB и кэш-память.
Другим важнейшим аспектом SMT является механизм синхронизации нитей. Обычно RISC-процессоры применяют модель с замками для загрузки регистров условной записи. При этом для установки или ожидания семафора используются программные spin-циклы, что хорошо подходит для одно- и многопроцессорных систем [4]. Однако spin-цикл в процессоре с SMT-архитектурой, очевидно, будет потреблять ресурсы. В EV8 для решения этой проблемы разработчики предложили специальную разновидность такого цикла — покоящийся (quiscing) цикл, который позволяет TPU, связанному с нитью, находящейся в таком цикле, «заснуть» и не потреблять ресурсы процессорв до тех пор, пока не будет модифицирован соответствующий семафор.
Проведенные исследования показали, что на широком диапазоне рабочих нагрузок SMT может удвоить суммарную пропускную способность процессора, т.к. в EV8 удается увеличить достигаемое значение IPC почти вдвое. При этом общее увеличение площади микросхемы EV8 за счет добавления поддержки SMT не превышает 10% [8]. Это свидетельствует о том, что применение SMT в сочетании с RISC-архитектурой может рассматриваться как альтернатива подходу на базе EPIC.
По сравнению с CMP применение SMT имеет своим преимуществом экономию, т.к. имеется только один процессор, занимающий меньше площади. Кроме того, в SMT когерентность кэша не требует дополнительной логики и нагрузки на процессор. Наконец, CMP и SMT могут применяться вместе, дополняя друг друга: скажем, две копии Alpha EV8 могут образовать CMP-конфигурацию [4].
Технология Hyper-Threading
Intel также активно работала над архитектурой МТА [9]; результаты этой работы уже скоро можно будет увидеть в Xeon MP, а также в будущих поколениях серверных процессоров, появление которых ожидается в первой половине 2002 года. Можно предположить, что они станут первыми массово выпускаемыми процессорами с архитектурой SMT. Эти процессоры будут иметь аппаратные контексты для двух нитей, выпускаться по технологии 0,13 мкм и будут ориентированы, по крайней мере первоначально, на рынок многопроцессорных серверов. Следующим шагом может оказаться применение подобных процессоров и в рабочих станциях.
Измерения для прототипов таких процессоров, выполненные в Intel Microprocessor Software Labs, показали увеличение производительности для функций Microsoft Active Directory на 18%, для Microsoft SQL Server — на 22%, для Microsoft Exchange — на 23%, а для Microsoft IIS выигрыш может составить 30%. Конечно, производительность отдельных нитей может оказаться и ниже, например, за счет меньшей емкости используемой под данную нить кэш-памяти по сравнению с полной емкостью кэша процессора.
Согласно информации Intel, включение возможностей SMT добавляет к площади процессора Foster менее 5%. Это является убедительной демонстрацией того факта, что приведенное солидное увеличение производительности достигается весьма «дешевым» способом. Действительно, новой аппаратуры SMT привносит совсем немного — в основном это дублирование регистров и назначение ресурсов нитям. При этом дублируются как видимые, так и внутренние (физические) регистры. Кэш-память по сравнению с Pentium 4 практически не поменялась. Начальные стадии конвейера Pentium 4 (до работы планировщика команд) не меняются, однако атрибуты (биты, указывающие на принадлежность к определенной нити), конечно же, присутствуют. По некоторым данным, соответствующие биты уже имелись в предыдущих реализациях Pentium 4. Исполнительное ядро Pentium 4, включая все ФИУ, также не изменяются — эти ресурсы разделяются между двумя нитями. Завершающий выполнение микроопераций блок процессора, отвечающий за восстановление архитектурного состояния на основании выполненных внеочередным спекулятивным образом микроопераций (retirement) также не изменился по сравнению с Pentium 4, но работает последовательно (по нитям). Среди добавленных в новый процессор компонентов можно упомянуть еще средства APIC (Advanced Programmable Interrupt Controller) — назначение прерываний для обработки разными процессорами в мультипроцессорной системе, что повышает производительность работы ОС.
Первоначальная загрузка операционной системы для таких процессоров происходит в однопроцессорном режиме (один из процессоров находится в состоянии останова), а затем инициализируется второй процессор, т.е. они представляются для ОС как два логических процессора. Поскольку в процессоре нет средств синхронизации нитей, то ситуация с ожиданием семафора (Intel называет ее spin wait) создает угрозу захвата ресурсов процессора в цикле ожидания. Intel сообщает о возможности применения в таких циклах специальной микрооперации PAUSE. Разработаны рекомендации по оптимизации ПО, позволяющие избежать существенных потерь производительности.
Спекулятивные предвычисления
Уже отмечалось, что из трех основных подходов — SMT, CMP, EPIC — первые два не являются «антагонистами» и могут применяться совместно. С другой стороны, EPIC - единственный подход, направленный на повышение производительности одной нити. По сравнению с SMT архитектура EPIC имеет и недостатки [4], например увеличенный размер кодов оптимизированной программы, что ведет к потенциально более частому возникновению ситуации непопадания в кэш команд. Кроме того, остающаяся в Itanium и McKinley аппаратная поддержка совместимости с x86, препятствует росту тактовой частоты [4]. В то же время комбинация EPIC и SMT трудно реализуема, чему препятствует необходимость еще большего увеличения емкости регистровых файлов (для поддержки более чем одной нити), что затрудняет рост тактовой частоты. Кроме того, встает необходимость дублирования сложных аппаратных блоков типа RSE [6, 7]. Однако в работе [10] предложен интересный подход, в котором идеи МТА использованы для ускорения выполнения одной нити. Авторы назвали свой подход спекулятивным предварительным вычислением (SP — Speculative Precomputation) и применили его для моделирования процессора, исходной архитектурой которого является IA-64. Общая структура конвейера модернизированного процессора представлена на рис. 1, а в таблице 2 даны его типичные параметры. Последние данные интересны и сами по себе, безотносительно к МТА, т.к. они дают некоторые возможные оценки того, как процессоры IA-64 будут развиваться в будущем.
Данная модель предполагает поддержку 8 аппаратных контекстов нитей. В аппаратуре имеется 8 счетчиков команд, 8 копий всех видимых файлов регистров, 8 очередей расширения по 8 связок (bundle) на очередь [6, 7]. Интегрированная кэш-память (с первого по третий уровень) является не блокирующейся (до 16 непопаданий). Если к выборке и выполнению готово более одной нити, из них выбираются две и каждой дается половина пропускной способности (т.е. по одной связке на выборку), а если готова только одна нить — ей отдается вся пропускная способность.
Идеи SP можно рассматривать и как дальнейшее развитие идей спекулятивного выполнения и предварительной выборки (prefetch). Например, в SP возможно предварительно выполнить цепочки зависимых команд L — загрузки регистров. В SP ограничиваются только статическими командами L. В [10] указано, что не более 10 подобных «виновных» команд L (Delinquent Load — DL) вызывают более 80% непопаданий в кэш первого уровня. Основная (неспекулятивная) нить может порождать спекулятивные нити, которые выполняют р-кванты (precomputation slices) — последовательности зависимых команд, извлеченных из неспекулятивной нити. Спекулятивная нить может быть порождена либо при достижении командой из неспекулятивной нити определенной стадии конвейера (базовый триггер), либо спекулятивной нитью, которая явно порождает другую спекулятивную нить (циклический триггер).
От идеальной аппаратной реализации SP авторы [10] отказались ввиду сложности и дороговизны такого решения, и предложили более экономичную, программную реализацию (SSP). Оказалось, базовые механизмы, необходимые для реализации SP, уже имеются в Itanium: это RSE и легковесный механизм восстановления при обработке исключительных ситуаций, возникающих при «неверном» спекулятивном выполнении, т.е. при наличии взаимозависимости по управлению или по данным [6,7]. RSE использует специальные буферы для временного хранения регистров, и часть этих буферов авторы предложили использовать для контекстов нитей под «оживляющие» (Live-In) буферы LIB.
Кроме того, в процессор добавлена новая аппаратная структура — очередь незавершенных квантов (PSQ — Pending Slice Queue). Она является неким расширением LIB и применяется для того, чтобы обеспечить поддержку большего количества спекулятивных нитей, чем полное число аппаратных контекстов нитей. Наконец, добавлена 4-строчная ассоциативная структура OSC (Outsatnding Slice Counter), каждая строка которой относится к определенной команде DL и содержит, в частности, указатель на команду DL и адрес первой команды в p-кванте, идентифицирующий этот квант. Таким образом, добавление возможностей спекулятивных предвычислений в микроархитектуру Itanium не требует большого объема дополнительных аппаратных средств.
В идеальном случае спекулятивные предвычисления с базовыми триггерами дает прирост производительности на 30%, но в реалистических ситуациях выигрыш гораздо меньше. Применение базовых и цепочечных триггеров в 8-нитевом процессоре позволяет в реальных ситуациях увеличить производительность на 169% (в среднем — на 76%). Моделирование для оценок производительности проводилось на тестах art, equake (из состава SPECfp2000) и gzip, mcf (SPECint2000).
В качестве общего резюме хотелось бы отметить, что многонитевая архитектура является перспективным направлением как с точки зрения пропускной способности на многозадачной смеси, так и с точки зрения производительности одной задачи (нити). При этом реализация МТА не требует внесения больших аппаратных доработок в современные суперскалярные микропроцессоры.
Работа поддержана РФФИ, проект 01-07-90072.
Литература
- В. Корнеев, Эволюция микропроцессорных архитектур. «Открытые системы», 2000, № 4
- М. Кузьминский, Будущее архитектуры Power4. «Открытые системы», 2000, № 4
- М. Кузьминcкий, Микроархитектура DEC Alpha 21264, «Открытые системы», 1998, № 1
- Paul De Mone, «Alpha EV8: Simultaneous Multi-Threat», http://www.realwordtech.com/page.cfm?articleid=RWT121300000000 http://www.realwordtech.com/page.cfm?articleid=RWT122600000000
- М. Кузьминский, Дорога к высоким тактовым частотам. «Открытые системы», 2001, № 2
- М. Кузьминский, Краткий обзор IA-64. Открытые системы, 1999, № 9-10
- М. Кузьминский, Микроархитектура Itanium. «Открытые системы», 2001, № 9
- K. Diefendorff, Compaq Chooses SMT for Alpha. Microprocessor Report, v.13, (1999) № 6, p.1
- Introduction to Hyper-Threading Technology, Doc.N 250008-002, Intel, 2001
- J.D.Collins, H.Wang, D.M.Tulssen, C.Hughes, Y.F.Lee, D.Lavery, J.P.Shen, «Speculative Precomputation: Long-Range Prefetching of Deliquent Loads», Proc. 28th Int. Symp. Computer Architecture, July 2001
