
Web-службы и средства интеграции приложений предприятия (enterprise application integration — EAI)
Общественное мнение сегодня практически целиком сосредоточено на тех Web-службах, которые строятся на стеке стандартов SOAP, UDDI и WSDL. Сказанных за пару лет их существования слов более чем достаточно для того, чтобы сложилось впечатление вполне законченной картины, а сами Web-службы представляются некоей подлинной реальностью, существующей давным-давно [1].
На самом деле ситуация куда сложнее, она лишена однозначности и окрашена определенной драматичностью. Во-первых, данный стек протоколов — далеко не единственный подход к созданию распределенных вычислений средствами Интернета. Во-вторых, внутри лагеря адептов именно этой категории Web-служб пока еще нет полного единства взглядов. И, наконец, в-третьих, среди лидеров закрепились, скажем так, некоторые явно «антисетевые» компании, а сделавшие для развития Сети больше других, отнюдь не доминируют. Первые вынуждены менять свое лицо, а вторые явно чувствуют себя ущемленными. К сегодняшнему дню материализация Web-служб сильно преувеличена: они еще слишком далеки от практической реализации, и, соответственно, не сложились стабильные решения, связанные с интеграцией приложений предприятия (enterprise application integration — EAI) на основе именно этого типа Web-служб. И все же, несмотря на преждевременность, говорить об этом приходится, повинуясь требованиям времени.
Начать стоит с одного важного замечания: несмотря на то, что в названиях двух технологий — World Wide Web и Web-службы — присутствует объединяющее их слово, их пути к потребителю отличаются, как небо и земля. Всемирная паутина — гениальное открытие небольшой группы ученых, возглавляемых Тимом Бернерсом-Ли. Оно было построено на ограниченном количестве стандартов, не потребовало слишком больших инвестиций и дошло до каждого пользователя Интернета естественным образом и без каких-либо маркетинговых усилий. Напротив, Web-службы, явление в своей отдаленной перспективе столь же глобальное, требуют для своей реализации консолидации практически всех серьезных производителей программного обеспечения, колоссальных средств и огромного, еще не вполне оцененного количества стандартов. Сегодня трудно найти американскую ИТ-компанию, которая бы не причисляла себя к производителям Web-служб. Но не менее трудно найти у представителей этих компаний внятное объяснение того, что они делают.
Выработкой стандартов занимается множество организаций и комитетов. На ведущую роль в этом движении к стандартизации претендует учрежденная Microsoft и IBM организация WS-I (Web Services Interoperability Organization). Две эти корпорации являются ее членами-учредителями и пользуются, наряду с еще несколькими ведущими производителями определенными привилегиями. WS-I появилась позже других аналогичных образований, но именно она координирует вопросы стандартизации Web-служб, поэтому работает в тесном сотрудничестве с такими доминирующими в этой области организациями, как World Wide Web Consortium и Internet Engineering Task Force. В WS-I вошли также компании Oracle, BEA Systems и Hewlett-Packard. Однако среди ее членов пока нет Sun Microsystems, которая ранее продвигала альтернативный подход к службам, основанный на стандарте ebXML, и, учитывая свои заслуги по части Java, требует теперь для себя в случае вступления исключительного положения среди участников WS-I, равного статусу Microsoft и IBM. Даже по неполному перечню комитетов и организаций несложно сделать вывод о том, что процесс стандартизации идет полным ходом. (Содержательный обзор последних событий в области стандартизации Web-служб можно найти в [2].)
Беспрецедентная активность крупных вендоров объясняется тем, что Web-службы оцениваются всеми ими как безусловно перспективное начинание. Однако Web-службы относятся к той категории новаций, которые создаются и продвигаются компаниями-разработчиками, а пользователями могут быть востребованы только тогда, когда достигнут определенного уровня зрелости. Не то, что бы Web-службы навязываются вендорами, но потребность в них не осознана пользователями и не вызрела в полной мере.
Потребителей нужно разбудить, а потребность воспитать. Между хронологически первыми разработками такого типа и массовым принятием технологии проходит длительное время, в течение которого процесс ее становления подчиняется закономерности, которая с подачи самого известного аналитика ИТ-рынка, компании GartnerGroup, получила название «кривой хайпа». Поскольку английское слово hype имеет очевидный негативный оттенок — а оно действительно переводится как «активная реклама», «пускание пыли в глаза» и даже «очковтирательство» — кривую хайпа чаще рассматривают не как объективную закономерность, а как сознательную деформацию естественных процессов, вызванную чрезмерными маркетинговыми действиями заинтересованных сторон. Скорее всего, подобные утверждения ошибочны; более вероятно, что каждому типу новаций соответствует определенная динамика перехода технологии или изделия от начальной фазы до массового принятия потребителями. Сравните: это могут быть мгновенные взрывы, как это произошло с простейшими изделиями, например, кубик Рубика или томагочи, а может быть вообще неопределенное время внедрения, как в случае с управляемой термоядерной реакцией или нанотехнологиями (понятно, что они когда-нибудь будут, но когда — неизвестно).
Родословная Web-служб
Как любое сложное явление, Web-службы не имеют одной точки зарождения; они появились в разных местах и под влиянием разных фактов. Поэтому происхождение Web-служб можно искать в нескольких источниках, например, идя от WWW. Сегодня, говоря о Web-службах, почти всегда имеют в виду только те решения, которые основаны на стеке протоколов SOAP, UDDI и WSDL. Строго говоря, это неверно, поскольку службы, работающие через Web, появились практически одновременно с самой Паутиной и прошли определенный эволюционный путь. Группа авторов из исследовательской лаборатории Hewlett-Packard предлагает деление служб на поколения [3].
Первое поколение: CGI и Perl. С момента своего появления World Wide Web дала возможность просматривать статические страницы средствами браузеров, но, кроме того, с самого начала обеспечивалось пассивное обслуживание. Язык HTML поддерживает механизм FORMS как средство для работы с меню и передачи информации посредством интерфейса Common Gateway Interface небольшим скриптам, написанным большей частью на языках Perl или Shell. Скрипты, в свою очередь, могут воспринимать введенные пользователем данные как запросы и выводить необходимые пользователю страницы, что расширяет возможности работы за рамки навигации.
Второе поколение: Java. С ростом Web стали востребованными такие виды служб, как онлайновые продажи, заказы билетов и т.д. Java-апплеты добавили браузерам возможности для графического интерфейса, благодаря чему Java стал первым настоящим языком программирования для Web-служб. Следующим шагом внутри этого поколения служб стали сервлеты, позволяющие в динамическом режиме генерировать HTML-страницы. Появились близкие по смыслу технологии JSP (Java Server Pages) от Sun Microsystems, ASP (Active Server Pages) от Microsoft, PHP для ОС Linux и др. Они позволили отделить представление страниц от их содержимого, обеспечили простейшую форму аутентификации с использованием имени и пароля пользователя и еще некоторые возможности обслуживания.
Третье поколение: J2EE. Для переноса служб на корпоративный уровень потребовалось развитие языка Java и Java-библиотек. Решение пришло в форме J2EE (Java 2 Platform, Enterprise Edition). Предложенная Sun Microsystems платформа стала развиваться и другими компаниями, в том числе IBM, превратившись в стандарт де-факто для всей отрасли. Появились серверы приложений; прежде же разработчик должен был самостоятельно собирать разрозненные приложения, подключать их к Web-серверу, управлять конфигурацией. Серверы приложений — это, по сути, предварительно собранные пакеты, предназначенные для разделения служб и бизнес-логики и позволяющие разработчику сосредоточить свое внимание на функциональной части. Наибольшую известность получили построенные на основе J2EE серверы HP AS, IBM WebSphere, BEA WebLogic, Sun iPlanet и Oracle 9i AS.
Четвертое поколение: платформы для Web-служб. Первые три поколения предназначались в основном для пользователей, их возможности ограничивались возможностями HTML. Появление языка XML с его простым синтаксисом и возможностью описывать синтаксис средствами собственной нотации XML Schema стало поворотным моментом и повлекло за собой возникновение служб нового поколения. Сегодня они реализуются на платформах Sun ONE (Open Net Environment) и Microsoft .Net. Принципиальное отличие служб четвертого поколения заключается в том, что они обеспечивают взаимодействие между приложениями. Они никак не ориентированы на человека, поэтому называть их службами не совсем верно.
Уже сейчас просматриваются черты пятого поколения, где будет использоваться динамическая сборка Web-служб, агентские технологии и т.д.
Появление четвертого поколения Web-служб можно воспринимать еще и как логический итог развития распределенных вычислений. На корпоративном уровне потребность в распределенных вычислительных системах возникла давно, вслед за тем, как в качестве альтернативы мэйнфреймам стали использовать сетевые конфигурации, объединяющие рабочие станции и мини-ЭВМ. Одной из первых возникла задача обеспечения электронного обмена данными (electronic data interchange, EDI). Уже тогда были сделаны первые шаги по направлению к нынешним Web-службам. Многие технические решения, датируемые началом 80-х годов, остаются актуальными и сегодня. В свое время они были воплощены в операционных системах DEC VMS, в различных версиях Unix, поставлявшихся компаниями Tandem, Hewlett-Packard и Sun, а IBM со своим продуктом MQSeries тогда от этой группы приотстала.
Однако главным стимулом к созданию распределенных систем стало появление персональных компьютеров и коммерциализация Интернета. Одной из первых, объединенных в рамках отрасли попыток по созданию стандартов распределенных систем, была предпринята в конце 80-х, когда была образована организация Distributed Computer Environment (DCE), но она не получила широкой поддержки. Следующим шагом по созданию инфраструктуры распределенных вычислений стала инициатива Common Object Request Broker Architecture (CORBA), предложенная консорциумом Object Management Group, который в соответствии со своим названием был сосредоточен на объектном подходе к кросс-платформенным приложениям. Microsoft на появление CORBA ответила компонентной объектной моделью Component Object Model (COM) и ее распределенной версией DCOM. Впрочем, и то, и другое решения уступают инициативе DCE по возможности масштабирования. Архитектуры CORBA и DCOM создают иллюзию превращения сети однородных компьютеров в единый образ машины, в которой обмен между приложениями осуществляется на уровне объектов. Средствами CORBA и DCOM строится программное обеспечение промежуточного слоя, независимое от операционных систем и от языков программирования. Специфической чертой обеих технологий является наличие простой схемы обнаружения нужных для выполнения объектов; для этой цели объектам присваиваются идентификаторы, а CORBA еще дополнительно поддерживает описание служб, предоставляемых объектами. Примерно такой же функциональностью обладает Java RMI (Sun Microsystems), с поправкой на нейтральность по отношению к аппаратным платформам, обеспечиваемую виртуальной машиной Java; интерфейс Java Native Interface служит для расширения языковых возможностей.
Будучи распределенными, архитектуры CORBA и DCOM относятся к категории «жестко связанных» систем: каждая из архитектур имеет собственную систему двоичного кодирования сообщений. Объекты и методы действуют в рамках своей архитектуры, объект из CORBA не может вызвать метод из DCOM и наоборот.
Для того чтобы снять ограничения на масштабирование, приложения, являющиеся компонентами системы, должны быть «слабо связанными». Впервые идея объединения компонентов в систему посредством служб приобрела привлекательность на аппаратном уровне, когда стали появляться более интеллектуальные и во все большей степени самоуправляемые устройства, способные предоставлять услуги другим устройствам. Виртуализация устройств, реализуемая при таком подходе, позволяет перевести пользование физическими устройствами в обращение к виртуальным устройствам, иначе говоря, в термины обращений к объектам. По мере того, как расширялись физические границы систем, формировалась «службо-центричная» (service-centric) архитектура, предполагающая коммуникации между процессами. Благодаря этому стал возможен поворот к ориентированному на службы программному обеспечению промежуточного слоя, т. е. к службам без префикса Web. Первыми ласточками были клиентская служба e-speak от компании HP, Jini от Sun Microsystems и T-Spaces от IBM.
Web-службы — одна из возможных технологий для EAI
Enterprise Application Integration, это название по своей нелогичности может составить конкуренцию Web-service или knowledge management. Речь ведь идет о системе управления предприятием, а в таком случае механическая интеграция отдельных подсистем находится в противоречии не только с положениями общей теории систем, но и со здравым смыслом. Трудно представить себе, что систему управления летательным аппаратом будут интерпретировать как интеграцию отдельных модулей. Рисуется страшная картина: стоящий на поле самолет, а рядом ворох оборудования, во много раз превосходящий его по размерам. Рожденный летать в таком случае даже ползать не сможет.
Сравним отношение к предмету или объекту управления в технических системах и корпоративных информационных системах. Любой вузовский курс по специальности «Системы автоматического управления» включает в себя предмет «Теория автоматического регулирования». Почти полностью этот предмет строится на основе математических моделей объектов управления; изучающий его студент, быть может, еще и в глаза не видел реальных регулирующих устройств и объектов управления, на которых они работают. И это только начало: базис технических систем автоматического регулирования образован целым комплексом математических дисциплин. Именно они являются квинтэссенцией знаний, а инженерными методами создаются конкретные технические устройства; соответственным образом распределены роли ученых и практиков. Если же мы обратимся к корпоративным информационным системам, то здесь нет ни нормальных моделей, ни специалистов по управлению, а есть какие-то странные словосочетания, как, например, «интеграция приложений»...
Впрочем, в этом комментарии, как в большинстве многих эмоциональных высказываний, есть небольшое преувеличение — нельзя грести все информационные системы под одну гребенку. Для корпоративных информационных систем, как для любых других, характерно волнообразное развитие. На первой волне (70-е годы) создавались в основном финансовые приложения, на второй (80-е годы) — системы планирования ресурсов предприятия (enterprise resource planning — ERP), на третьей (90-е годы) — системы управления отношениями с клиентами (customer relationship management — CRM). Нынешняя, четвертая, обладает новым качеством. В информационных системах появляются самообслуживание и самоуправление, которые и могут быть реализованы средствами слабосвязанных приложений — и Web-службами в том числе. В результате эволюционного развития корпоративные системы превращаются в новый «зоопарк» — зоопарк приложений.
Раньше подобным образом характеризовали комплекс разнородных аппаратных средств; со временем сетевые стандарты и инфраструктуры позволили связать их вместе. Однако корпоративный зоопарк не исчез, изменились его «обитатели», и ныне большинство компаний располагают набором приложений, который надо как-то упорядочить [4]. Это могут быть старые унаследованные и плохо документированные приложения, а могут быть и современные коробочные продукты классов ERP, CRM и SCM (supply chain management — «управление цепочками поставок»), а также порталы. Обычно они представляют собой «черные ящики», которые работают каждый на собственном наборе данных, выполняют возложенные на них функции, но не могут обмениваться между собой данными в режиме реального времени и не образуют единую систему.
Развивающиеся системы категорий B2B, B2C и аналогичные им требуют представления полной информации в приемлемое время. Необходимость в коммуникации с внешним миром является первостепенным по значимости требованием для создания интегрированной системы приложений предприятия (enterprise application integration — EAI). Процесс создания EAI — это процесс объединения систем ERP, CRM, SCM, баз данных, хранилищ данных и других внутренних подсистем предприятия.
Для начала определим место Web-служб в современном представлении о процессе интеграции приложений, а для этого нужна предварительная систематизация. Существует несколько основных взаимодополняющих подходов и групп технологий для решения задачи интеграции приложений, которые могут использоваться по отдельности или совместно.
- Интеграция пользовательских интерфейсов (User Interface Integration). Это, в конечном счете, не что иное, как замена уникальных для каждой из подсистем графических или текстовых интерфейсов единообразным интерфейсом, обычно на основе браузеров. Бизнес-логика остается распределенной по тем же системам ERP, CRM и SCM. Иногда такой подход образно обозначают словом refacing ("изменение лица"); для подобной косметической операции хватает функциональности порталов.
- Интеграция данных (Data Integration). Эта наиболее распространенная из существующих на сегодняшний день форма интеграции предполагает объединение баз данных и источников данных. Чаще всего сводится к той или иной форме миграции данных, а бизнес-логика, как и в случае интеграции пользовательских интерфейсов остается распределенной по первичным системам. Существуют некоторые виды программного обеспечения промежуточного слоя, которые обеспечивают процесс репликации данных. Одно из наиболее современных решений, которое называют ETL (Extract, Transform, Load), выделяет, преобразует, фильтрует и сохраняет данные в хранилищах или киосках данных.
- Интеграция бизнес-процессов (Business Process Integration). Этот тип интеграции не затрагивает бизнес-логики отдельных процессов, существует специальное промежуточное программное обеспечение, которое согласовывает работу отдельных приложений, используя для этого брокеры сообщений, отвечающие за синхронизацию.
- Функциональная интеграция (Function Integration). Функциональная интеграция как наиболее системный подход предполагает непосредственное взаимодействие кросс-платформенных приложений (application-to-application, A2A), работающих в сети. Для этого могут быть использованы просто языковые средства (Cobol, C++, Java), API-интерфейсы, вызовы удаленных процедур (remote procedure call, RPC), распределенное программное обеспечение промежуточного слоя, брокерные архитектуры на базе брокеров (CORBA, DCOM), удаленные вызовы Java (remote method invocation, RMI), промежуточное ПО, ориентированное на сообщения (message oriented middleware, MOM). Наряду с перечисленными методами для функциональной интеграции могут использоваться Web-службы.
Полная интеграция приложений предполагает использование всех четырех подходов.
Подчеркнем, что Web-службы не следует путать с собственно EAI. Web-службы — это всего лишь еще одна технология, обеспечивающая создание интегрированной платформы, но в отличие от более традиционных подходов использующая для этой цели слабо связанные приложения. При этом не стоит принижать возможности действующих средств, предназначенных для интеграции приложений, которые сложились за последние годы: они обладают вполне достаточными возможностями и сохранят применимость еще на годы.
Очень интересное сравнение возможностей Web-служб и архитектуры J2EE Connector Architecture можно найти на сайте dev2dev.com, поддерживаемом компанией BEA Systems специально для разработчиков [5]. Технологии Web-служб, во всяком случае, по их состоянию на сегодняшний день и на ближайшее будущее, не перекрывают все возможности перечисленных выше четырех подходов к интеграции. Сейчас они привлекательны такими возможностями, как быстрая публикация, обнаружение и включение служб в приложение, но в этом виде они могут быть использованы только на уровне функциональной интеграции. Будущие поколения Web-служб обретут способность инкапсулировать и пользовательские интерфейсы, и средства для обеспечения безопасности, и многое другое, что образует потребительские качества корпоративной информационной системы. Для полноценного использования этих возможностей потребуются значительные изменения в самих интегрируемых компонентах, которые должны будут обладать способностью предоставления своей функциональности в виде служб, чтобы можно было использовать в качестве связующих средств XML, SOAP и UDDI. На этом уровне задачи EAI сведутся не к интеграции приложений, а к интеграции служб. Несмотря на такую острожную оценку возможностей Web-служб, в их нынешнем состоянии создание интегрированных приложений описанными средствами обладает значительными преимуществами, которые проявятся в будущем.
Перечислим основные различия между традиционными решениями категории EAI и Web-службами.
- Простота. Как любое хорошо структурированное модульное решение, Web-службы гораздо проще проектировать, разрабатывать, внедрять и поддерживать, чем более монолитные сильно связанные распределенные технологии, например, DCOM или CORBA. Достаточно создать общую структуру, а потом менять и модифицировать ее по блокам.
- Открытые стандарты. До сих пор почти все проекты EAI являются частными решениями, Web-службы, по определению строятся на стеке стандартов, который со временем, будем надеяться, сложится.
- Гибкость. Слабая связанность приложений делает прозрачным весь проект, исключает соединения типа "точка-точка". Следствием этого является простота модификации.
- Низкая стоимость. Практика показала, что решения EAI на основе брокеров сообщений обычно бывают дорогими; Web-службы проще и универсальнее, они должны быть дешевле.
- Масштабирование. Использование Web-служб позволяет дробить большие системы, подобные ERP, на более мелкие модули, выбирать и собирать вместе наиболее нужное.
- Эффективность. Системы, построенные по принципу гранулирования, обычно оказываются эффективнее в эксплуатации.
- Динамичность. Традиционные методы EAI обычно статичны по своей природе; есть надежда, что Web-службы придадут системам большую динамичность.
Что делать?
С большой долей вероятности Web-службы смогут изменить весь ландшафт ИТ, включая возможности индивидуальных и корпоративных пользователей. Рано или поздно компаниям, для того чтобы остаться конкурентоспособными, придется соучаствовать в распределенной системе B2B, где будут интегрироваться внешние приложения и службы. Эти гипотетические системы B2B со временем вполне могут поглотить существующие системы EAI. К этому нужно быть готовиться и начинать с внутренних сетей интранет, естественным образом резко не отказываясь от других решений, основанных на других программных средствах промежуточного слоя.
Известная истина гласит: информирован, значит, вооружен. Сегодня главное оружие на фронте EAI — Web-службы — это информированность. Иногда говорят, что не стоит бежать впереди паровоза. Возможно, это и так, если есть возможность выбраться с рельсов. А если нет?
Литература
- Kapil Apshankar et al, Web Services Business Strategies and Architectures. Expert Press, ISBN: 1904284132, 2002
- Uche Ogbuji, "The Past, Present and Future of Web Services", 2002, http://webservices.org/article/articleprint/663/-1/24/
- Akhil Sahai et al, The unfolding of the web services paradigm. Hewlett-Packard Laboratories, 2002, http://www.hpl.hp.com/techreports/2002/HPL-2002-130.pdf
- Gunjan Samtani, Dimple Sadhwani, EAI and Web Services. Easier Enterprise Application Integration? 2001, http://www.webservicesarchitect.com/content/articles/samtani01.asp
- Tyler Jewell, Architecting and Architecture: Which Integration Approach is Best? www.dev2dev.com
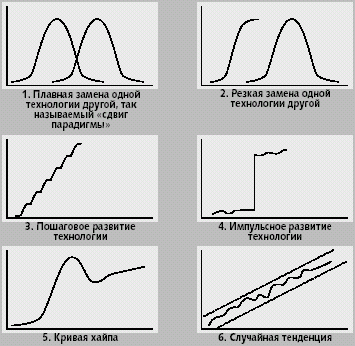
|
| Рис. 1. Типы инновационных процессов. В учебном курсе по футурологии, который преподает Роджер Калдуэлл в университете штата Аризона, приводится систематизация процессов внедрения. Калдуэлл выделяет шесть типов процессов становления новых технологий |
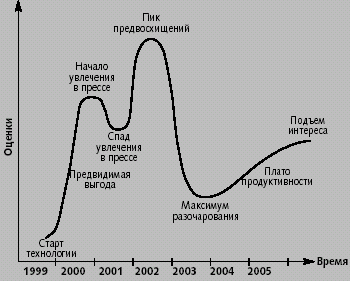
|
| Рис. 2. Кривая хайпа для Web-служб по состоянию на сентябрь 2002 года. В Gartner цикл «кривой хайпа» разделяют на шесть последовательных фаз: энтузиасты оценивают потенциал технологии; технология находится на пике хайпа, число ее энтузиастов достигает максимума, но данных об эффективности нет; начинают появляться данные об эффективности, а также первые разоблачения и разочарования; технологии остаются все еще неприбыльными, необходимо углубленное изучение вопроса и развития; случайные попутчики уходят со сцены, количество энтузиастов технологии падает до минимума; технология доказывает свое право на существование, к ней возвращается часть из тех, кто ушел |
Примеры организаций, занимающихся вопросами стандартизации
- Apache Axis
- Apache Web Services Inspection Language for Java API
- Business Process Management Initiative
- ebXML.org
- Internet Engineering Task Force LDAP Schema for UDDI
- Liberty Alliance
- OASIS Web Services for Interactive Applications
- OASIS Web Services for Remote Portals
- OASIS Web Services Security Technical Committee
- UDDI.org
- W3C Web Services Architecture Working Group
- W3C Web Services Description Working Group
- W3C Existing XML Protocol Working Group
Web-службы для Семантической Сети
Недавно по телевидению были показаны кадры испытания первого серийного автомобиля «Форд». Похожая на муравья, на своих тонких велосипедных колесах «Жестянка Лиззи» с трудом перебиралась через, казалось бы, непреодолимые препятствия, грозя рассыпаться на каждом из них. А следом в этой же программе шел не нуждающийся в комментарии клип о каком-то современном навороченном внедорожнике. Из этих двух сюжетов невольно родилось сопоставление современного и будущего состояний Web вообще и Web-служб в частности.
Какими бы мощными силами не поддерживались нынешние Web-службы, они используют ту самую Паутину, которая была создана вовсе не для цели общения между приложениями, а для взаимодействия между людьми. Web будущего должны заселить не столько люди, сколько устройства. Поэтому службы, обеспечивающие взаимодействие, станут здесь явлением вполне естественным, а то, что понимают под Web-службами сейчас — это лишь начало. Если продолжить «автомобильную» аналогию, то Web-службы в их нынешнем состоянии пока напоминают популярный, пожалуй, лишь в нашей стране вид транспорта — легковой автомобиль с чудовищным по размерам багажником или же с грузовым прицепом. При всем желании ничего подобного в развитых странах найти не удастся.
Понимая ограниченные возможности Всемирной Паутины в ее нынешнем виде, несколько лет назад ее «главный» автор Тим Бернерс-Ли в группе коллег по академическому сообществу World Wide Web Consortium выступил с инициативой, которая получила название Semantic Web (SWeb). Основные идеи, положенные в основу Семантической Сети, Бернерс-Ли изложил в популярной форме в статье, которая была опубликована в журнале Scientific American в мае 2001 года. Она так и названа — «The Semantic Web»; желающим не представляется ни малейшей сложности ее найти, жаль только, что она не переведена на русский язык. Некоторые аспекты SWeb представлены на русском языке в статье [1]. Однако пока в полном объеме Sweb — это некий идеальный образ будущего виртуального пространства. Понятно, что это нельзя проделать сразу, единовременно, как невозможно было сто лет назад построить совершенный автомобиль. К идеалу нужно идти годами. Но потребность в использовании Web в сложившемся статус-кво общепризнана, поэтому неудивительно, что почти синхронно с рождением SWeb стартовала более прагматичная кампания по продвижению Web-служб, стимулированная гигантами ИТ-индустрии, корпорациями: IBM, Microsoft, Sun Microsystems, а также другими игроками этого рынка. Она не предполагает радикальных метаморфоз — этот подход к службам целиком и полностью основан на нынешней платформе Web.
В итоге возникло два параллельных потока. В сознании многих комментаторов параллельность двух миров свелась к противоборству, где с одной стороны выступает академическая наука, для которой важнее всего содержание, а с другой — индустрия, для нее важнее службы, сервис, а это естественно означает и коммерцию. На первый взгляд, складывается еще одна ось противостояния между наукой и бизнесом — теперь в форме «Semantic Web против Web-служб». На самом деле такое суждение глубоко неверно; надо признать, что сегодня есть объективная потребность в реализации Web-служб теми средствами, которые сегодня имеются в наличии. Естественно, работающие на рынок, удовлетворяют эту потребность как могут. Но при этом надо признать и другое. Во-первых, они удовлетворяют ее примитивно, об этом говорят и пишут многие (см., например, [2]). Во-вторых, современная наука не может развиваться в собственной башне из слоновой кости и должна лояльно воспринимать потребности пользователей.
Со стороны науки, настроенной практически, ответ на потребность в Web-службах последовал в форме, которая получила название Semantic Web Services. Это будущее поколение Web-служб, в которых объединятся и существующие и разрабатываемые отраслевые стандарты, и новые академические разработки. Общая модель распространения служб, по-видимому, не подвергнется большим изменениям, но отдельные составляющие будут заменены новыми. Прежде всего это относится к описанию функциональности служб и к средствам для взаимного поиска соответствующих друг другу служб. В английском языке для этого используется термин service matchmaking, т. е. буквально «сватовство» служб. В итоге может сложиться иной, более сложный, нежели сейчас, стек стандартов. Часть существующих стандартов будет заменена, другие будут расширены.
Наиболее стабильно положение стандарта SOAP, на который пока еще никто не посягал.
Скорее всего, первым из существующего стека стандартов может выпасть WSDL. Его может заменить стандарт DAML-S; так называют средство описания онтологий для Web-служб. Принятые сегодня средства описания службы на уровне WSDL не достаточны для того, чтобы с ними могли работать автоматические агенты Semantic Web.
Но прежде несколько слов о языке DAML и о том, почему он появился. Развитие Web воплощается в развитии языковых средств. Все началось с HTML, который позволил виртуализировать информацию, но при этом не предлагал средств для описания того, что эта за информация, и как она может быть интерпретирована и найдена. HTML был рассчитан на человека, а не на программных агентов.
Для компенсации этих недостатков консорциум W3C предложил язык расширяемой разметки XML, который позволяет описывать информацию (в том числе, и информацию о службах) путем разметки с помощью тегов. Он позволяет включать разметочные метаданные, определяющие семантику объектов. XML был воспринят многими как спасительный круг, отдельные очень крупные и к тому же старые фирмы даже прибавили к своему названию суффикс «XML company».
Но и XML имеет свои ограничения. Он слаб в части описания отношений между объектами, которые называют в Semantic Web онтологиями. Онтология — один из краеугольных камней Семантической Сети. Для того чтобы можно было использовать этот аппарат, в качестве расширения языка XML, был создан новый язык разметки, DAML, который расширяет не только XML, но и Resource Description Framework (RDF); последняя его версия носит название DAML+OIL. Напомню, что RDF был разработан в W3C примерно в то же время, что и XML, и служит дополнением к нему, представляя собой язык для моделирования полуструктурированных метаданных для приложений, связанных с управлением знаниями. W3C также предложил облегченный язык RDF Schema, который служит для описания классов и свойств. Но возможностей этих средств для реализации Semantic Web оказалось тоже недостаточно.
Поэтому под патронажем подведомственного Министерству обороны США агентства DARPA — как тут не вспомнить зарождение Internet — был создан более выразительный язык DARPA Agent Markup Language (DAML), который не является инициативой W3C, но создан при его активном участии. В 2002 году было опубликовано весьма добротное введение в DAML [3]; его, как и многие другие полезные сведения, можно найти на daml.org.
Большие изменения ждут и схему декларирования служб, которая сегодня реализуется средствами, определяемыми стандартом UDDI. Новый подход к «сватовству служб» очень похож на действия человека в аналогичной ситуации: он включает публикацию объявлений в соответствующем репозитории, поиск и просмотр. В некоторых работах в качестве основы для развития избран не UDDI, а разрабатываемый комитетом CEFACT Организации Объединенных Наций и OASIS стандарт ebXML. Одной из альтернатив UDDI может стать Semantic Web Ontology-Based Information Service.
Работы по созданию Semantic Web Services пока сосредоточены в основном в Стэндфордском университете, в исследовательском центре SRI International Menlo Park, в английском филиале Hewlett-Packard Laboratories в Бристоле, в компании Oracle и в нескольких лабораториях Голландии, Германии, Испании и даже Болгарии. Сделанные ими публикации пока имеют частный характер, описывают решение отдельных вопросов. Возможно, сейчас полученные результаты еще не имеют большого практического значения, но знаменателен сам факт их существования. Они позволяют по-новому взглянуть на происходящее вокруг Web-служб и убедиться в том, что активно популяризируемые взгляды на Web-службы будь то под флагом Microsoft .Net, будь то под флагом Sun ONE, не есть истина в последней инстанции, а всего лишь первые шаги.
И, наконец, еще одно соображение. Процесс разработки семантических Web-служб очень показателен по своей логической структуре. Почти во всех областях ИТ исчерпан потенциал простых инженерных решений, требуются нетривиальные научно обоснованные решения. В данном случае при развитии Web-служб используются подходы из области искусственного интеллекта, разрабатывавшиеся еще 60-е — 70-е годы.
Литература
- Стин Декер, Сергей Мельник, Франк ван Хермелен, Дитер Фенсел, Мишель Клейн, Джин Брукстра, Майкл Эрдманн, Ян Хоррокс, Semantic Web: роли XML и RDF. // Открытые системы, 2001, № 9
- Леонид Черняк, Стоит ли бежать впереди паровоза. // Открытые системы, 2002, № 11
- Roxane Ouellet, Uche Ogbuji, Introduction to DAML. daml.org
