
Самоуправляемые, или адаптивные, системы — это, по сути, аппаратно-программные компьютерные системы, действующие независимо от человека. Именно их боятся некоторые любители постановки «общефилософских» вопросов, рисующие в своем воображении компьютер, вышедший из подчинения. Можно вспомнить и классику научной фантастики («Космическая одиссея 2001 года») и подивиться точности временных прогнозов Артура Кларка. На дворе 2003 год, и ИТ-отрасль начинает активно обсуждать концепцию адаптивных систем, развиваемую в настоящее время ведущими компьютерными фирмами.

Сегодня Fujitsu Siemens предлагает готовое решение FlexFrame for mySAP Business Suite, в котором реализуется концепция адаптивных систем на всех уровнях — от аппаратуры до собственно прикладного программного обеспечения [1].
Необходимо отметить, что как «степень автономии» адаптивных систем, так и те области, в которых эта автономия реализована, никем жестко не зафиксированы. Как мы увидим, целый ряд хорошо известных (некоторые из них — на протяжении десятилетий) особенностей аппаратно-программных комплексов подпадают под концепцию — по крайней мере, в том смысле, в котором ее применяют сегодня в Fujitsu Siemens.
Не будем пытаться строго определить, какую систему можно считать адаптивной, а про какую — сказать, что в ней используются «элементы» технологии аадаптивных систем. По всей видимости, полная реализация данной концепции должна охватывать все уровни — от аппаратного уровня до приложения, как это и предлагается в FlexFrame от Fujitsu Siemens.
Зачем нужны адаптивные системы
Конечно, есть «лобовой» ответ на этот вопрос: хочется, чтобы все работало само по себе. По данным, приводимым Fujitsu Siemens, применение ИТ в нынешних реалиях гетерогенных распределенных систем на крупных предприятиях способно превратиться в ночной кошмар. Приходится поддерживать обычно не менее четырех операционных систем, сотни, а то и тысячи серверов (в среднем — по два десятка серверов на администратора) и т.д. Понятно, что в этих условиях встает задача консолидации этого серверного зоопарка.
Как полагают в Fujitsu Siemens, адаптивные системы способны гарантировать обеспечение нужного сервиса пользователям при минимизации стоимости владения. Минимизация стоимости обеспечивается, в первую очередь, за счет упрощения работы обслуживающего персонала, уменьшения объема этой работы, и благодаря оптимизации всей ИТ-инфраструктуры. При этом сам обслуживающий персонал может сосредоточиться на задачах более высокого уровня.
Кроме задач консолидации (включая консолидацию не только аппаратных средств, но и данных, и приложений), повышения доступности путем снижения как плановых, так и внеплановых простоев, уменьшения зависимости от человеческого вмешательства, адаптивные системы способствуют улучшению использования программных и аппаратных ресурсов. Повышение так называемой «утилизации» ресурсов серверов означает, что за то же самое время они смогут сделать больше. Поэтому для выполнения определенного объема работ понадобится меньше использовать инфраструктуру (аппаратура, программы, персонал), что обойдется, соответственно, дешевле.
В Fujitsu Siemens говорят об адаптивных системах как о межплатформной концепции самоуправляющихся систем, способных упростить управление ИТ-инфраструктурой в рамках общей стратегии компании для всех областей рынка — от мобильных решений до критических бизнес-приложений. Но хотя в Fujitsu Siemens говорят об адаптивных системах в контексте управления всей ИТ-инфраструктурой, включая любые возможные клиентские устройства (настольные ПК, ноутбуки, КПК, «планшеты»), думаю, внедрение концепции начнется с серверной части информационных систем.
Адаптивные системы охватывают ряд функциональных уровней, и достигаемая «степень автономии» будет, очевидно, возрастать с течением времени по мере развития решений для соответствующих компонентов ИТ-инфраструктуры. В настоящее время мы находимся в самом начале пути развития того, что стали называть термином «адаптивные системы».
Концепция SysFrame
Обсуждая общую концепцию адаптивных систем, предлагаемую Fujitsu Siemens, мы с неизбежностью будем обращаться к примерам, относящимся не только к продукции этой компании, но и к другим технологиям, характеристикам архитектуры и даже данным, ныне относящимся уже к истории развития вычислительной техники. Это связано с тем, что, хотя Fujitsu Siemens является одним из пионеров в данной области, сама концепция никак не «привязана» к продукции какой-либо одной компании.
Прежде чем рассмотреть SysFrame, полезно вкратце упомянуть о некоторых технологиях и подходах общего характера (т.е. выходящих за рамки адаптивных систем), которые применяются в SysFrame:
- виртуализация ресурсов (упрятывание деталей реализации, увеличение «гранулярности» ресурсов и т.д.);
- избыточность (создание пула функционально идентичных ресурсов, наличие «запасных» ресурсов, например, spare-блоки жестких дисков);
- парционирование (разбиение сервера на логические или физические разделы [2]);
- кластеризация (в том числе, построение кластеров высокой готовности);
- динамическая реконфигурация (добавление/удаление/замена ресурсов «на ходу»);
- средства принятия решений, реализующие алгоритмы, определенные внешне заданными правилами и данными;
- мониторинг утилизации ресурсов и рабочей нагрузки, сбор информации о событиях, относящихся к безопасности и др. [1].
В функциональном плане концепция SysFrame включает четыре основные группы задач по «самоуправлению»: cамоконфигурирование; самооптимизация; самолечение; самозащита.
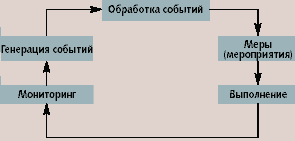
|
| Рис. 1. Полный адаптивный цикл |
Ниже мы рассмотрим все эти группы функций подробнее, в том числе, на примерах конкретных реализаций Fujitsu Siemens. А сейчас необходимо проанализировать ключевое понятие SysFrame — «адаптивный цикл» [1]. Он включает в себя ряд последовательно решаемых задач по осуществлению функций адаптивных систем (рис. 1) по отношению к соответствующим ресурсам. Концепция адаптивного цикла применяется для всех четырех указанных выше групп функций адаптивных систем, т.е. для каждой из этих групп функций можно изобразить соответствующий адаптивный цикл.
Адаптивный цикл предполагает последовательное решение пяти основных задач по управлению соответствующими ресурсами.
- Мониторинг. Интуитивно понятные действия, включающие отслеживание использования ресурсов, уровня рабочей нагрузки, событий, относящихся к компьютерной безопасности и проч.
- "Генерация событий" при возникновении определенной ситуации. Эта задача может быть как достаточно тривиальной (например, генерация сигнала машинного сбоя), так и весьма сложной.
- Обработка события. Описывает процедуру, решающую, какие меры необходимо предпринять в качестве реакции на полученное событие. Каждому событию ставится в соответствие набор правил, определяющих те меры, которые надо предпринять по обработке события. Эти правила могут учитывать конфигурацию системы, время дня и т.д.
- "Мероприятия". Набор акций, включающих активизацию предварительно определенной политики обработки или модификацию этой политики с адаптацией к новой ситуации.
- Выполнение "предложенных" ранее мероприятий, обеспечивающее разрешение проблемной ситуации.
Без рассмотрения конкретных примеров эти задачи подчас выглядят несколько абстрактно. В общем случае отделить друг от друга некоторые из этих задач зачастую бывает достаточно трудно.
Функции самоуправления адаптивных систем
Рассмотрим четыре группы функций по самоуправлению подробнее. Снабдим общую характеристику этих функций конкретными примерами их реализации на уровне аппаратных средств от Fujitsu Siemens (серверы Primepower и Primergy), операционной системы и системных программных средств, которые могут использоваться с этими серверами. Ниже, при обсуждении FlexFrame, полной реализации адаптивных систем от Fujitsu Siemens, приведем дополнительные примеры реализации данной концепции в функциональном плане.
Напомним, что многопроцессорные серверы Primepower используют 64-разрядные микропроцессоры SPARC64 и работают с ОС Solaris 9. Серверы Primergy с числом процессоров до 16 построены на платформе Intel Xeon MP и могут использоваться с ОС Linux. Собственно, SysFrame и интегрирует эти серверы, а также мэйнфреймы BS200 в составе единой адаптивной системы.
Cамолечение. В части, касающейся аппаратуры, реализация элементов адаптивных систем, пожалуй, наиболее известна и используется очень давно. Классические примеры — повторение команд процессора и ввода-вывода в каналах IBM S/370 и мэйнфреймов последующих поколений, а также в аналогичных моделях ЕС ЭВМ. В данном случае соответствующие функции адаптивных систем относятся не только к уровню аппаратуры, но и к уровню ОС [3]. Эти функции позволяют автоматически при сбое процессора переключать выполнение задачи на другой процессор в мультипроцессорной системе; при сбое канала — переключиться на доступ к внешним устройствам через другой канал; при сбое в работе со сменными внешними устройствами (например, с магнитными лентами) — переставлять носитель на другое внешнее устройство, не завершая принудительно выполнение соответствующей задачи, и др. При таком понимании адаптивных систем к ним можно отнести любые решения, защищающие от сбоев, например, RAID и коды ECC.
И RAID, и коды ЕСС, и возможности горячей замены, и кластеры высокой готовности — это аппаратные средства и технологии обеспечения отказоустойчивости, которые реально используются в современных адаптивных системах от Fujitsu Siemens. Отметим, что кроме решения проблем аппаратных сбоев, а также их предсказания (примеры вовсе не ограничиваются компьютером из упомянутого выше произведения Артура Кларка; можно сослаться, скажем, на известную архитектуру SMART для жестких дисков) имеется проблема сбоев программного обеспечения и предсказания этих сбоев. Возможно, подобные функции также могут быть отнесены к самолечению. (В качестве еще одного примера из этой области можно вспомнить возможности повторной загрузки реентерабельных модулей операционной системы в мэйнфреймах IBM при сбое в памяти и «порче» соответствующего модуля.)
Используемые в серверах Fujitsu Siemens технологии наподобие кодов ECC или автоматического повторения команд известны, пожалуй, всем. Между тем, специальные средства самолечения, доступные при работе с серверами Primepower, относительно мало известны [4]. Упомянем только некоторые:
- ASR&R (Automatic Server Recognition&Restart);
- RTP (управление процессами, аудит и восстановление);
- REMCS, Teleservice;
- динамически расширяемая файловая система и пространство подкачки (хорошие примеры самолечения на программном уровне!), поддерживаемые программным инструментарием EventAdmin 2.
Если в одиночном сервере самолечение реализовано путем применения технологий типа горячей замены или разбиения на разделы, то в кластере высокого уровня готовности (в том числе, в Primecluster) возможно переключение выполнения задачи на «здоровый» узел, а в отказоустойчивых системах применяются дополнительные меры — зеркалирование состояния сервиса, альтернативные пути маршрутизации сообщений и др.
Самозащита. Эта группа функций адаптивных систем предполагает использование стандартных механизмов обеспечения безопасности для обеспечения защиты от неавторизованного доступа и использования. Все базовые механизмы обеспечения безопасности (аутентификация, авторизация, контроль доступа, аудит и др.) сюда подпадают. Однако если, скажем, для удаленного доступа к серверу вы используете ssh, еще рано говорить о том, что у вас есть адаптивная система, даже если ваш сервер имеет некоторые свойства отказоустойчивости. Необходимо наличие «признаков» адаптивных систем по всем четырем группам функций.
Для адаптивных систем SysFrame на базе серверов Primepower доступны следующие средства самозащиты — HORUS Toolkit, средства шифрования (SSL, ssh), CA eTrust, Kerberos v.5, IPsec и др. Большинство этих средств хорошо известны. С Primepower можно использовать и Pitbull — безопасную версию Unix, сертифицированную по классу B1/E3. Она двоично совместима с Solaris, однако наделена целым рядом усовершенствований в области безопасности, включая контроль доступа к сети и файлам с более высокой гранулярностью, но при этом проста в использовании и администрировании [4].
Самооптимизация. Эта группа функций предполагает, в частности, автоматическое распределение/высвобождение ресурсов, и под эту группу функций, в соответствии с концепцией Fujitsu Siemens, подпадают такие хорошо известные вещи, как балансировка нагрузки (включая как рабочую нагрузку, так и сетевой трафик), разбиение на разделы, кластеризация и др. Вообще говоря, само по себе разбиение на разделы или кластеризация не должны подпадать под самооптимизацию. Так, разбиение на разделы обычно происходит не автоматически, а по командам системного администратора.
Однако серверы Primepower могут использоваться с некоторыми высокоуровневыми средствами, позволяющими реализовать при этом функции самооптимизации. В их числе можно упомянуть ARMTech Resource Management от Aurema (этот инструментарий умеет работать и с разделами), RTP (управление распределением нагрузки), Scalable Internet Services (балансировка нагрузки), средства мониторинга производительности, предусматривающие также возможности определенного реагирования (EventAdmin, Sight Lime, Open SM2) и др. [4].
Так, EventAdmin, снабженный удобным графическим интерфейсом пользователя, обладает не только средствами мониторинга системных ресурсов (процессоры, память, диски, сетевые ресурсы), но и средствами формулирования тенденций их использования, а также средствами автоматизации последовательностей операций при возникновении определенных событий. Эти события относятся к области программного обеспечения и являются конфигурируемыми (так, можно устанавливать значения порогов, правила, сценарии и проч.).
EventAdmin в состоянии добавлять или изымать ресурсы из разделов динамически, во время работы в них приложений под управлением ОС Linux или Solaris. При этом выполняющееся приложение, например, CУБД Oracle или mySAP, будучи приписаны к группе adm, могут направлять запросы на добавление и освобождение ресурсов в их разделе, а EventAdmin принимает окончательное решение и осуществляет соответствующие действия. Взаимодействие приложений в разделах с EventAdmin реализовано в обычной модели «клиент-сервер».
Необходимо отметить, что поставляемые Fujitsu Siemens средства парционирования PPAR/XPAR для серверов Primepower имеют важные усовершенствования по сравнению с другими подобными системами [2]. Эти усовершенствования связаны с тем, что граница раздела в Primerpower может проходить «внутри» 8-процессорной платы, которая может быть разделена на четыре раздела так, что в каждом разделе можно независимо подавать и снимать напряжение. Такая высокая гранулярность является несомненным плюсом для тонкой оптимизации.
Другие средства высокого уровня предоставляются в кластерах, использующих программное обеспечение Primecluster и ОС Linux/Solaris. Во-первых, это программные средства RMS, работающие на каждом узле кластера. Во-вторых, это средства AMS (Automatic Manager Software), которые относятся уже к межкластерному уровню.
Очевидно, к этой группе функций адаптивных систем относятся все средства автоматической балансировки (в том числе, и существующие свыше 20 лет средства типа SRM для мэйнфреймов IBM [3]).
Самоконфигурирование. Под функции этой категории, в частности, подпадают: для оборудования — горячая замена и добавление устройств; для firmware и программного обеспечения — внесение изменений, модернизация и инсталляция. Здесь видно, что иногда становится тяжело разделить группы функций адаптивных систем: например, для аппаратных средств указанные выше функции горячей замены явно относятся также и к самолечению.
Хорошей иллюстрацией самоконфигурирования может быть пример серверов-лезвий [5], в которых можно выделить группу серверов с одинаковой аппаратной и программной конфигурацией, выполняющих одинаковые задачи. В этом случае установку программного обеспечения можно провести на одном сервере, а затем по очереди «реплицировать» на другие серверы, не прерывая выполнения сервиса остальными серверами [1]. В техническом плане эта задача близка к задаче «размножения» программного обеспечения в узлах Linux-кластеров Beowulf, для чего существует ряд готовых продуктов.
В линейке Primepower можно указать, в частности, на следующие функции самоконфигурирования:
- cредств автоматизации инсталляции InstallAdmin;
- модификации firmware и операционной системы в оперативном режиме;
- автоматического конфигурирования аппаратуры;
- динамического разбиения на разделы PPAR/XPAR (здесь очевидно пересечение с самооптимизацией);
- динамической реконфигурации процессоров и памяти.
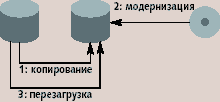
|
| Рис. 2. Пример самоконфигурирования операционной системы |
Наиболее ярко самоконфигурирование проявляется при активной адаптации системы (динамической реконфигурации). Примером самоконфигурирования при работе с операционной системой Solaris 9 может служить «функция» LiveUpdate, модернизация, осуществляемая на работающей операционной системе (рис. 2).
Подводя итог обсуждению основных групп функций адаптивной системы, отметим, что, во-первых, эти группы могут «перекрываться» между собой, и, во-вторых, многие из них по отдельности давно известны. Адаптивные системы сводят эти функции воедино. (Возможно, первыми адаптивными системами стали мэйнфреймы IBM, хотя самого термина тогда еще не существовало.)
FlexFrame: адаптивные системы в действии
Не менее важной, чем концепция SysFrame, возможно, является демонстрация того, как адаптивные системы могут работать уже сегодня. Реализация SysFrame при работе с приложениями mySAP называется FlexFrame for mySAP Business Suite [1, 6]. Как утверждают в компании, применение FlexFrame позволяет значительно сократить TCO за счет существенного уменьшения (в некоторых случаях — до 60%) стоимости администрирования и улучшения общей утилизации ресурсов. Другими причинами экономии является консолидация прикладных систем, приводящая к уменьшению стоимости аппаратуры и уменьшению требуемых площадей, возможность дешевой модернизации приложений SAP R/3 в mySAP Business Suite и т.д. [6].
Разработка FlexFrame велась в кооперации с SAP и Network Appliance.
Инфраструктура FlexFrame включает три основных компонента: узлы управления, узлы приложений и централизованную систему хранения (рис. 3).

Все базовые функции, которые необходимы для управления инфраструктурой FlexFrame, выполняются управляющими узлами. Они состоят из двух серверов, образующих кластер высокой готовности. Их работа необходима для обеспечения постоянной доступности всех необходимых для работы mySAP видов сервиса.
В узлах приложений выполняются как базовые сервисы (например, базы данных), так и приложения mySAP. Последние не «привязаны» к конкретным узлам приложений: любое из них может выполняться на любом сервере. В качестве узлов приложений могут использоваться все серверы линеек Primergy и Primerpower, сертифицированные для работы с mySAP [1].
В роли централизованной дисковой системы хранения, посредством IP-cети соединенной с узлами приложений, выступает Network Appliance Filer. Таким образом, ресурсы хранения централизованы для узлов приложений, для чего используется виртуализация. Поддержка в этой подсистеме автоматических операций с дисковой памятью повышает доступность данных и отвечает функциям самолечения.
В качестве примера самоконфигруирования можно указать на автоматическую загрузку узлов приложений из одной общей точки. При этом загружаемые ОС для серверов Primepower и Primergy (могут использоваться и серверы-лезвия, до 20 серверов-лезвий на 3U-шасси, что дает очень высокую плотность упаковки) самоконфигурируют необходимый образ ОС. После загрузки узел приложения автоматически распознается и управляется управляющим узлом.
В качестве примера самооптимизации можно указать на применение в Network Appliance Filer файловой системы WAFL (Write Anywhere File System), которая автоматически распределяет файлы по нескольким томам. Когда в состав подсистемы Network Appliance Filer добавляется новое дисковое устройство (это может быть сделано, не прерывая реальной работы по обслуживанию пользователей, т.е. без прерывания работы mySAP), оно автоматически становится доступным всем узлам приложений. Загрузка приложений автоматически распределяется между узлами приложений.
Функции самолечения очевидны, в частности, для работы кластера высокой готовности из двух управляющих узлов. Если такой узел обнаружит, что имеется неработоспособный узел приложений, он проинструктирует другой узел приложений, чтобы тот обеспечил продолжение выполнения приложений mySAP. Для этого могут использоваться избыточные (запасные) прикладные серверы. Поэтому FSC предложила даже специальный термин — RAIS (Redundant Array of Independed Servers, «избыточный массив независимых серверов»), напоминающий известный всем RAID [6].
Среди функций самозащиты можно упомянуть, например, загрузку «корпоративной» операционной системы по сети из одной точки, что предотвращает неавторизованное вмешательство. Доступ в режиме «только чтение» к централизованным образом администрируемой операционной системы препятствует ее возможным несанкционированным модификациям.
Наконец, полезно вкратце упомянуть о тех конкретных преимуществах, которые дает применение адаптивной системы FLexFrame. На макроуровне, кроме уже отмеченного выше уменьшения TCO, использование FLexFrame способствует улучшению качества обслуживания при его обеспечении на уровне интерфейсов пользователя и администратора. Уменьшение стоимости администрирования связано, в частности, с тем, что изменение операционных систем серверов приложений делается только один раз (а не для каждого сервера), и затем автоматически реплицируется. Когда добавляются новые прикладные узлы, системному администратору нет необходимости самому изменять конфигурационные файлы. Разделение компонентов инфраструктуры FlexFrame упрощает масштабирование, которое можно проводить по отдельности, а не все вместе.
Виртуализация прикладных сервисов позволяет добавлять новый прикладной узел динамически при обслуживании пользователей. При замене узла приложения сервис продолжает предоставляться другими узлами. Высокая гибкость системы позволяет оптимизировать степень использования ресурсов установленных серверов. Те сервисы mySAP, которые в данный момент не нужны, могут быть остановлены, а освобожденные ресурсы — использованы для выполнения других видов сервиса. Иными словами, мы получаем что-то типа «mySAP-сервисов по запросу». Виртуализация в Network Appliance Filer позволяет быстро и гибко масштабировать дисковое пространство требуемое приложениям [1]. Пожалуй, к недостаткам FlexFrame можно отнести лишь довольно большое время переноса сервиса на другой узел (при отказе узла приложения, требующем загрузки сервиса) — до нескольких минут.
Заключение
Итак, мы являемся свидетелями становления нового направления ИТ — адаптивных систем (новым оно является из-за интеграции широкого круга функций и обеспечения более высокого, нежели ранее, уровня адаптивности). Конкретные предложения адаптивных систем — такие, как FlexFrame от Fujitsu Siemens — несомненно, способствуют тому, чтобы потенциальные пользователи обратили бы особое внимание на соответствующую продукцию.
Литература
- Autonomic Systems: Concept for Self-Managing IT Infrastructure White Paper. Fujitsu Siemens Computers, March 2003.
- Михаил Кузьминский, Доменная архитектура многопроцессорных компьютеров. // Открытые системы, № 10, 2000.
- OS VS/2 MVS Overview. GC28-0984-1, IBM, N.Y., 1980.
- SysFrame Implementation in Primepower. Fujitsu Siemens Computers, 2003.
- Михаил Кузьминский, Серверы-лезвия: за и против. // Открытые системы, № 2, 2003.
- Autonomic Systems Framework. Fujitsu Siemens Computers, Jan. 2003.
