
.

Прежде, когда речь заходила о вычислительных машинах, экономно потребляющих электроэнергию, имелись в виду прежде всего мобильные и встроенные платформы. Серверы — многопроцессорные системы старшего класса, работающие с высокими нагрузками, — обычно комплектовались мощными системами охлаждения и располагались в построенных по особым проектам помещениях, оснащенных мощными силовыми линиями. Но за последние годы стало очевидно, что по мере быстрого спроса на вычислительные ресурсы даже системам старшего класса приходится сталкиваться с ситуациями, когда увеличение энергопотребления становится невозможным. Более того, не будем забывать, что массовые компьютеры оснащаются в настоящее время воздушными системами охлаждения. Так вот, вычислительные системы уже подходят к тому пределу, когда производители будут не в состоянии обеспечивать эффективное охлаждение, не используя дополнительных средств наподобие систем водяного охлаждения. В этих условиях средства управления энергопотреблением становятся важным компонентом любого сервера.
Проблемы энергосбережения, с которыми сталкиваются администраторы коммерческих серверов, отличаются от проблем, с которыми приходится иметь дело пользователям мобильных систем. Приемы, обеспечивающие сокращение потребления мощности и энергии на уровнях микросхем и микроархитектур, хорошо известны [1]. Другие методы снижения энергопотребления определяются особенностями сервера, а также специфическими характеристиками и природой рабочих нагрузок. Несмотря на отдельные достижения в области разработки средств энергосбережения, эти средства пока не в состоянии полностью удовлетворить потребности серверов.
Дисковые ресурсы все чаще изолируются, а доступ к ним организуется в форме сетей хранения. В этих условиях центральным звеном стратегии энергосбережения в коммерческих серверах становится экономия энергии в подсистемах памяти и микропроцессоров. Рабочие нагрузки коммерческих серверов обычно структурируются в соответствии с выполнением определенной группы приложений. Поэтому простейшие методы, которые хорошо подходят главным образом к средам с одной выполняемой программой, не вполне подходят для многопроцессорных коммерческих серверов. Для них пригодны скорее подходы в контексте системы в целом.
Коммерческие серверы
В состав коммерческого сервера входит один или несколько высокопроизводительных процессоров и связанных с ними кэшей; обладающие высокой емкостью модули динамической памяти, оснащенные несколькими контроллерами; имеющие высокое быстродействие интерфейсы, обеспечивающие широкую полосу пропускания для обменов с памятью; контроллеры ввода-вывода и, наконец, высокоскоростные сетевые интерфейсы.
Многопроцессорные серверы обычно обладают SMP-архитектурой; это означает, что все процессоры обращаются к основной памяти и что любой процессор может обращаться к любой области памяти. Такая организация дает ряд преимуществ.
- Многопроцессорные системы могут масштабироваться под более значительные нагрузки, нежели однопроцессорные системы.
- При совместном использовании памяти упрощается задача балансировки нагрузки нескольких процессоров.
- Такая архитектура позволяет применять парадигму программирования с совместным использованием памяти, взятую на вооружение большинством программистов.
- Многопроцессорные системы обладают большой мощностью и памятью с широкой полосой пропускания, поэтому они могут эффективно справляться с нагрузками, предусматривающими интенсивное использование ресурсов памяти.
Память коммерческих серверов организована иерархически. В этих устройствах между процессором и основной памятью обычно размещаются кэши двух или трех уровней. К числу типичных коммерческих серверов старшего класса можно отнести такие устройства, как IBM p690, HP Superdome и Sun Fire 15K.
На рис. 1 показана схема высокоуровневой организации процессоров и памяти в одном «многомикросхемном» модуле MCM (multichip module), который применяется с IBM Power4. Каждый процессор Power4 содержит два процессорных ядра, и каждое ядро выполняет один программный контекст.
Оба ядра процессора оснащаются кэшами первого уровня; кроме этого, два ядра совместно используют кэш второго уровня, являющийся «точкой когерентности» для иерархической структуры памяти. Каждый из процессоров подключается к размещаемому вне модуля кэшу третьего уровня, к контроллеру памяти и к основной памяти. В некоторых конфигурациях процессоры совместно работают с кэшем третьего уровня. Четыре процессора устанавливаются на MCM-модуле и взаимодействуют по выделенным каналам связи «точка-точка». Более крупные системы, такие как IBM p690, базируются на нескольких взаимосвязанных MCM-модулях.
В таблице 1 описывается энергопотребление двух конфигураций сервера IBM p670, являющегося версией среднего класса модели p690. В верхней строке таблицы показано, как распределяется мощность, потребляемая небольшим четырехпроцессорным сервером (на базе одного модуля MCM и четырех интегральных схем, каждая из которых содержит одно ядро) с 128-мегабайтным кэшем третьего уровня и памятью на 16 Гбайт. В нижней строке представлено распределение мощности, потребляемой более крупным 16-процессорным сервером (на базе двух MCM-модулей и четырех интегральных схем, каждая из которых содержит два ядра) с 256-мегабайтным кэшем третьего уровня и памятью на 16 Гбайт.
В потреблении энергии участвуют:
- процессоры, в том числе MCM-модули, оснащенные ядрами процессоров и кэшами первого и второго уровней, контроллеры кэшей и каталоги;
- память, состоящая из размещаемых вне кристаллов кэшей третьего уровня, модулей DRAM, контроллеров памяти и обеспечивающих высокую пропускную способность интерфейсных плат, которые располагаются между контроллерами и модулями DRAM;
- подсистема ввода-вывода;
- вентиляторы, охлаждающие процессоры и память, а также компоненты ввода-вывода.
Мы замеряли потребление энергии при функционировании серверов в холостом режиме. Обычно от высококлассных коммерческих серверов требуется в первую очередь высокое быстродействие, поэтому их конструкции не предусматривают возможности использования широкого спектра средств управления энергопотреблением. Иначе говоря, как при работе в холостом режиме, так и под нагрузкой энергопотребление остается примерно на одном и том же уровне.
Энергопотребление вентиляторов оценивалось по их спецификациям. Для оценки энергопотребления других компонентов малой конфигурации замерялась мощность потребляемого постоянного тока. Чтобы оценить энергопотребление большой конфигурации, показатели малой конфигурации соответствующим образом масштабировались. Для определения энергопотребления процессоров с двумя ядрами выполнялись отдельные замеры.
В малой конфигурации энергопотребление процессоров составляет 24% от соответствующего показателя системы в целом, тогда как на энергопотребление памяти приходится всего лишь 19%. В более крупной конфигурации процессоры потребляют 28% от всей потребляемой энергии, а память — 41%. Следовательно, традиционную модель управления энергопотреблением с упором на процессоры пора заменять подходом, основанным на методах управления энергопотреблением системы памяти.
Поскольку процессоры потребляют большие объемы энергии, они при этом генерируют много тепла, а значит, для их обслуживания требуются мощные средства охлаждения. Вентиляторы потребляют дополнительную энергию. Доля вентиляторов в энергопотреблении систем, находящихся в монтажных шкафах, довольно стабильна. Так вот, на вентиляторы приходится подавляющая часть энергопотребления малой конфигурации (51%); в большой конфигурации этот показатель составляет 28%, что тоже немало. Если уменьшить потребление вычислительной системы, это даст возможность соответственно уменьшить «аппетиты» системы охлаждения.
Мы не принимали в расчет энергопотребление дисковых подсистем, так как в исследуемой системе использовались главным образом удаленные накопители; к тому же число дисков, применяемых в той или иной конфигурации, может колебаться в очень широких пределах. Современные диски SCSI при функционировании в активном режиме потребляют в среднем 11-18 ватт.
К счастью, анализ организации рассматриваемой компьютерной системы подсказывает несколько естественных вариантов решения проблемы энергосбережения. Так, если использовать отдельные процессоры, появляется возможность в соответствии с потребностями включать и отключать группы процессоров. Подобным же образом, используя группы микросхем кэш-памяти, контроллеров памяти и модулей DRAM, мы можем получить естественные объекты, обеспечивающие управление энергопотреблением подсистемы памяти. Кроме того, возможности обработки, которыми обладают контроллеры памяти (при всей их ограниченности), могут быть использованы новыми механизмами управления энергопотреблением.
Цели управления энергопотреблением
Меры по управлению энергопотреблением принимаются прежде всего для того, чтобы снизить максимальный порог энергопотребления и повысить эффективность использования энергии. Две эти цели не противоречат друг другу, но они не идентичны! Некоторые меры по управлению энергопотреблением служат достижению обеих целей, но чаще бывает, что тот или иной метод способствует реализации либо одной цели, либо другой.
Решение проблемы энергопотребления имеет жизненно важное значение в контексте обеспечения надежности системы и уменьшения мощности средств охлаждения. Традиционно ответом на возросшее потребление энергии считается совершенствование технологий охлаждения и размещения компонентов внутри систем. Но в последнее время в целях снижения теплового напряжения конструкторы совершенствуют технологии создания микросхем, а также их микроархитектуры.
Повышение эффективности использования энергии достигается двумя путями: нужно либо увеличить число операций в расчете на единицу потребленной энергии либо уменьшить количество энергии, потребляемой в расчете на одну операцию. Повышение эффективности потребляемой энергии влечет за собой сокращение эксплуатационных расходов на обеспечение системы энергией и охлаждением. Достижение эффективности энергопотребления особенно важно в больших организациях типа вычислительных центров, ибо в них расходы на энергоснабжение и охлаждение могут достигать высоких значений.
Недавно в сфере управления энергопотреблением появилась новая проблема — утечка тока в полупроводниковых цепях, в результате которой транзисторы, предназначенные для функционирования с высокими частотами, потребляют энергию даже не будучи включенными.
Рабочие нагрузки серверов
В понятие рабочие нагрузки серверов входят обработка транзакций — скажем, для Web-серверов или баз данных — и пакетная обработка — для неинтерактивных «долгоиграющих» программ. Возможности управления энергопотреблением для систем, выполняющих обработку транзакций и пакетную обработку, несколько отличаются друг от друга.
|
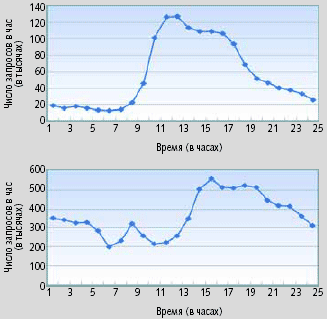
| Рис. 2. Изменение загрузок в течение одного дня; число запросов изменяется в широких пределах в зависимости от времени суток и других факторов. (a) Web-сайт финансовой компании; (b) Web-сайт Олимпийских игр в Нагано в 1998 году |
Как явствует из рис. 2, серверы, ориентированные на обработку транзакций, не всегда функционируют с максимальной мощностью; их рабочие нагрузки часто варьируются в значительных пределах в зависимости от времени суток, дня недели и от других внешних факторов. Такие серверы имеют солидную резервную мощность, которая гарантирует сохранение эксплуатационных характеристик в случае внезапного повышения рабочей нагрузки. А значит, при работе в нормальном режиме значительная часть мощности устройства остается неиспользованной.
Функционируя с пиковой мощностью, серверы транзакций могут вызывать запаздывание передачи отдельных запросов, вследствие чего они не будут укладываться в заданные значения для времени отклика. А вот у пакетных серверов требования по запаздыванию бывают не столь жесткими, и они могут работать с пиковой скоростью передачи в пакетном режиме. Однако эти более либеральные требования по запаздываниям оборачиваются тем, что иногда за ночь бывает достаточно выполнить одно большое задание. Вывод: как серверы транзакций, так и пакетные серверы имеют свои периоды простоя — и конструкторы могут использовать эти периоды для снижения объемов потребляемой энергии.
Рабочие нагрузки серверов могут состоять из множества приложений с различными требованиями к вычислительной мощности и быстродействию системы. Организация серверных систем часто соответствует этому типу. Так, типичный Web-сайт для ведения электронной торговли состоит из серверов нескольких уровней. Первый уровень составляют организованные в кластер серверы страниц; второй уровень — это более мощные серверы, на которых выполняются Web-приложения; высокопроизводительные серверы третьего уровня обслуживают базы данных.
Подобные гетерогенные конфигурации в первую очередь позволяют снижать затраты и повышать производительность системы. Но кроме этого, они предоставляют более широкие возможности для энергосбережения. Машины, входящие в упомянутые конфигурации, оптимизируются для выполнения тех или иных задач и допускают настройку в соответствии с применяемыми рабочими нагрузками, которая обеспечивает более высокий коэффициент использования энергии для каждой фазы соответствующей рабочей нагрузки.
Процессоры
Управление мощностью и энергопотреблением процессоров — это в первую очередь вопрос усовершенствований в области микроархитектур, однако часто также требуется применение в той или иной форме системного программного обеспечения.
Масштабирование частот и напряжений
Потребление энергии КМОП-схемами пропорционально их частоте и квадрату рабочего напряжения. Однако напряжение и частота не являются характеристиками, не зависимыми друг от друга. ЦП может в безопасном режиме использовать более низкое напряжение лишь в том случае, если частота его функционирования достаточно низка. Одновременное снижение частоты и напряжения ведет и к уменьшению объема потребляемой энергии и к снижению эксплуатационных характеристик сервера. Но зависимости при этом разные. Если частота и напряжение пропорциональны квадрату объема энергии в расчете на операцию, то взаимозависимость частоты и напряжения с одной стороны, и эксплуатационных характеристик — с другой описывается линейной функцией.
Первые работы по исследованию динамического масштабирования частот и напряжений (dynamic frequency and voltage scaling, DVS), иными словами, возможности динамически корректировать тактовую частоту процессора и напряжения, показали, что организация работы, при которой ЦП часть времени функционирует с максимальной частотой, а часть времени простаивает, не дает оптимальных результатов. Процессор должен динамически изменять свою тактовую частоту в соответствии с текущей нагрузкой, тем самым устраняя периоды простоя [2]. Чтобы иметь возможность подбирать для ЦП оптимальную частоту и напряжение, система должна прогнозировать загрузку ЦП на предстоящий период времени.
В последнее время исследователи уделяют очень серьезное внимание эвристическим методам прогнозирования [3, 4], но как бы то ни было, проблема прогнозирования загрузки процессоров в контексте рабочих нагрузок серверов требует проработки. На пути реализации методов DVS в SMP-серверах остаются и другие препятствия. К примеру, многие протоколы, обеспечивающие когерентность кэшей, исходят из того, что все процессоры функционируют с одной и той же тактовой частотой. Чтобы упомянутые протоколы стали совместимыми с технологией DVS, их необходимо модифицировать, а это задача далеко не простая.
Цель стандартных методик DVS в том, чтобы свести к минимуму время, в течение которого процессор обслуживает холостой цикл операционной системы. Некоторые исследователи изучают возможности использования методов DVS в других целях, а именно, в целях сокращения «холостых» циклов, возникающих вследствие больших задержек доступа к памяти.
Значительное время доступа к памяти часто приводит к ограничению производительности приложений, которые предполагают интенсивную обработку данных. Поэтому если такие приложения выполняются с пониженной частотой ЦП, это имеет ограниченное воздействие на производительность.
Оптимальную частоту ЦП для того или иного приложения или фазы приложения можно определить с помощью профилирования в автономном режиме. Для непосредственного изменения частоты программист может предусмотреть специальные операции. С другой стороны, такие операции может выполнять операционная система в период планирования процессов.
Многопотоковая обработка
Если DVS позволяет сократить число холостых циклов процессора за счет снижения его тактовой частоты, то многопотоковая обработка(simultaneous multithreading, SMT) обеспечивает повышение коэффициента загруженности процессора при фиксированной тактовой частоте. Отдельные программы допускают появление холостых циклов вследствие «пробуксовывания» доступа к памяти или из-за того, что в схему программы не заложен параллелизм на уровне команд. Так вот, для того чтобы сформировать команды, способные задействовать ресурсы, которые в противном случае оставались бы без использования, технология SMT одновременно отображает в процессоре несколько контекстов программ («потоков»). В результате повышается коэффициент использования процессоров, а значит и производительность системы. Однако если одни и те же ресурсы используются несколькими потоками, общая эффектичность снижается [5].
Реализация метода SMT в сущности сводится к дублированию регистров, которые описывают состояние потока. Непроизводительные энергозатраты при этом оказываются гораздо ниже, чем в случае добавления еще одного процессора.
Упаковка процессоров
Метод упаковки процессоров применяется не к отдельным процессорам, а к группам процессоров. Исследования, проведенные в IBM, показывают, что в среднестатистическом Web-сервере коэффициент использования процессоров колеблется в пределах от 11 до 50% [4]. И это обстоятельство позволяет сократить энергопотребление SMP-серверов. Метод упаковки процессоров предусматривает не балансировку нагрузки по всем процессорам, когда каждый из них использует лишь небольшую часть своих возможностей, а распределение нагрузки по минимально возможному числу процессоров и отключение всех остальных. Главное препятствие на пути реализации метода упаковки процессоров состоит в том, что в настоящее время не имеется аппаратных решений для включения и отключения процессоров в SMP-серверах.
Некоторые типы рабочих нагрузок таят в себе дополнительные возможности снижения энергопотребления процессоров. Как правило, серверы одновременно обрабатывают множество различных запросов, транзакций или других данных. Если эти задачи имеют внутренний параллелизм, разработчики могут вместо высокопроизводительных процессоров использовать большее число менее быстродействующих, но и, потребляющих меньшие мощности процессоров, обеспечивающих такую же производительность.
Примерами подобных систем могут служить Piranha [6] и Super-Dense Server [7]. При выполнении задач по обработке транзакций прототип SDS, функционирующий в конфигурации кластера, потреблял в два раза меньше энергоресурсов, нежели обычный сервер.
Энергопотребление подсистем памяти
В серверах обычно используются модули памяти DDR SDRAM. Память такого типа может функционировать в двух режимах энергосбережения: в режиме сниженного потребления (power-down) и в режиме самообновления (self-refresh). В крупных серверах число модулей памяти обычно превосходит число ожидающих запросов к памяти, так что модули часто простаивают. Контроллеры памяти могут переводить эти простаивающие модули в режим энергосбережения до тех пор, пока к ним не начнут поступать запросы от процессора.
Для перевода модуля в энергосберегающий режим или обратно в активный режим требуется лишь один цикл памяти; при этом потребление энергии простаивающими модулями DRAM может быть сокращено более чем на 80%. С появлением новых технологий этот показатель может повыситься. Но еще более внушительную экономию может дать в перспективе режим самообновления; правда, на сегодняшний день для возвращения модуля в активное состояние требуется несколько сотен циклов. Таким образом, для реализации потенциальных преимуществ данного режима требуются более совершенные методы.
Размещение данных
Распределение данных по физическим элементам памяти определяет, к каким устройствам хранения данных обращается процессор в том или ином случае, и, соответственно, когда именно наступают активные и пассивные периоды функционирования этих устройств. Устройства памяти, не содержащие активных данных, могут функционировать в энергосберегающем режиме.
Когда процессор обращается к памяти, контроллеры памяти могут до начала реализации обращения переводить модули работающие в энергосберегающем режиме в активный режим. В целях оптимизации производительности операционная система может активизировать память, к которой обращается вновь запланированный процесс в ходе периода переключения; тем самым запаздывание, связанное с выходом из режима низкого энергопотребления, в значительной степени маскируется [8, 9].
Экономия энергии достигается также посредством применения более рациональных политик распределения страниц. Выделение новых страниц уже используемым устройствам памяти позволяет сокращать число активных устройств памяти [10]. Дальнейшее снижение энергопотребления достигается с помощью «интеллектуальной» миграции страниц — перемещения данных с одного устройства хранения на другое с целью сокращения числа активных устройств памяти [11].
Однако надо иметь в виду, что с уменьшением числа активных устройств памяти сокращается и пропускная способность памяти, выделенной для данного приложения. Ведь если ранее существовала возможность параллельного обращения к нескольким устройствам хранения данных, то после уменьшения их числа обращения должны выполняться последовательно к одному и тому же устройству памяти.
Надо сказать, что первоначально схемы размещения данных разрабатывались для недорогих систем. Разработчики должны учитывать это обстоятельство и с большой осторожностью подходить к применению их в серверах старших классов, ибо здесь снижение пропускной способности памяти может существенно повлиять на производительность системы.
Отображение адресов памяти
Системы памяти серверов предусматривают настраиваемое отображение адресов, обеспечивающее эффективное использование энергии. Эти системы распределяют память по контроллерам памяти так, что каждый контроллер несет ответственность за несколько банков физической памяти.
Настраиваемые параметры в организации системной памяти определяют чередование (interleaving), модифицируя соответствие между адресом памяти и его размещением в физическом устройстве памяти. Это отображение часто осуществляется с той степенью детализации, которую предусматривает размер строки кэша более высокого уровня.
В соответствии с одной возможной схемой чередования последующие строки кэша размещаются в модулях DRAM, которые управляются различными контроллерами памяти, так что вся физическая память распределяется по всем контроллерам. Другой подход предполагает отображение последующих строк кэша в одном и том же контроллере; при этом вся физическая память размещается на одном контроллере и лишь после этого подключается следующий контроллер. При работе с одним контроллером чередование адресов памяти может подобным же образом осуществляться на нескольких физических банках памяти.
Направляя последовательные обращения — или даже одно обращение — на несколько устройств и контроллеров, мы можем расширить полосу пропускания памяти, но такой метод может привести к увеличению энергопотребления, потому что серверу придется активизировать большее число устройств памяти и контроллеров.
Взаимодействия схем чередования с настраиваемыми параметрами DRAM наподобие политик страничного режима и размер пакета оказывают дополнительное воздействие на задержки памяти и на энергопотребление. В целях достижения желаемого соотношения энергопотребление/производительность для каждого варианта рабочей нагрузки разработчик может отказаться от широко распространенной сегодня практики, когда каждая система поставляется с уже настроенной схемой чередования, и избрать схему чередования по своему усмотрению.
Сжатие памяти
Ортогональный подход к сокращению объема активной физической памяти состоит в том, чтобы использовать систему, оснащенную памятью меньшей емкости. Исследователи IBM показали, что могут сжимать хранимые в памяти сервера данные так, что их объем сокращается вдвое [12]. Модифицированный контроллер памяти сжимает и распаковывает данные в то время, когда он обращается к памяти. С другой стороны, сжатие — это дополнительный этап процедуры обращения к памяти, и на него может уходить значительное время.
Метод сжатия, предложенный инженерами IBM, предполагает использование дополнительного 32-мегабайтного кэша третьего уровня, который значительно сокращает объем данных, передаваемых памяти; таким образом компенсируется потеря производительности, вызванная введением этапа сжатия. Фактически сервер, оснащенный сжатой памятью, может функционировать с чуть меньшим быстродействием, нежели сервер, не оснащенный средствами сжатия и имеющий вдвое больший объем памяти.
Хотя для функционирования модифицированных контроллеров памяти и более объемных кэшей требуется больше энергии, серверы с большими объемами памяти должны с учетом всех затрат давать экономию. Впрочем, при рабочих нагрузках с самыми высокими требованиями к пропускной способности памяти и при рабочих наборах памяти, превосходящих размер буфера компрессии, это решение может и не давать экономии энергии.
Когерентность кэшей
Результатом снижения непроизводительных расходов за счет трафика поддерживающего когерентность кэшей может стать и повышение эффективности энергопотребления. В целях поддержания когерентности кэшей серверов с совместно используемой памятью часто применяются протоколы «недостоверности». Использовать их можно, к примеру, так: выделить кэши одного уровня (обычно речь идет о кэшах второго уровня) для отслеживания — или выслеживания — запросов к памяти, поступающих от всех процессоров.
Контроллеры кэшей всех процессоров сервера обмениваются данными с памятью и другими кэшами через одну и ту же шину. Благодаря присущей контроллерам кэшей способности наблюдать за трафиком данных памяти, поступающих на все кэши и со всех кэшей, а также собирать информацию о содержимом удаленных кэшей каждый контроллер кэша выполняет соответствующие операции для поддержания согласованности кэшей. «Разведывательные» обращения со стороны других процессоров значительно увеличивают энергопотребление кэшей второго уровня.
В [13] описывается кэш-подобная структура, получившая название Jetty. На это устройство, которое устанавливается на каждом кэше второго уровня, возлагается задача отфильтровывания поступающих «разведывательных» запросов. Jetty предсказывает, содержит ли локальный кэш запрашиваемую строку без ложных отказов. Когда процессор сначала обращается с «разведывательным» запросом к Jetty, этот запрос передается в кэш второго уровня лишь в том случае, если Jetty прогнозирует наличие в нем запрашиваемой строки. В результате энергопотребление кэша второго уровня при обработке всех обращений сокращается примерно на 30%.
В [14] вместо параллельных «разведывательных» обращений предлагается использовать последовательные обращения. Во многих системах с «разведывательными» кэшами «разведывательные» обращения параллельно передаются в широковещательном режиме всем кэшам, находящимся на шине SMP. Если содержимое кэшей других процессоров исследуется по одному, общее количество «разведывательных» обращений сокращается. Но хотя такой метод позволяет снизить энергопотребление, при его использовании возрастает средняя задержка, связанная с холостыми обращениями к кэшам. Поэтому разработчики должны стремиться к установлению баланса между экономией энергии в системе памяти с одной стороны, и с потребленной энергией — с другой.
Механизмы управления энергопотреблением
Практически все методы управления энергопотреблением включают в себя один или несколько механизмов, определяющих энергопотребление, а также политику, которая определяет наиболее эффективное их использование.
Надо сказать, что разработчики могут предложить чисто аппаратную реализацию некоторых приемов управления энергопотреблением, однако больший интерес представляют решения, в которых аппаратные механизмы сочетаются с программными правилами. Программная реализация политики облегчает модификацию и адаптацию. Кроме того, в этом случае пользователи и администраторы получают более естественные интерфейсы. Наконец, в программных политиках можно использовать информацию более высокого уровня — скажем, приоритеты приложений, характеристики рабочих нагрузок и технические показатели, к которым необходимо стремиться.
Наиболее часто применяемые механизмы управления энергопотреблением предусматривают возможность эксплуатации системы в нескольких рабочих состояниях, характеризующихся различными уровнями энергопотребления. Классифицируем эти рабочие состояния по основным категориям.
- Активные состояния, в которых процессор или устройство продолжает функционировать, но, возможно, при этом снижается его производительность и энергопотребление. Процессоры могут иметь целый ряд активных состояний, отличающихся различными тактовыми частотами и параметрами энергопотребления.
- Состояния простоя, в которых процессор или устройство не функционируют. Существуют различные состояния простоя; они отличаются друг от друга уровнями энергопотребления и задержками, которые возникают при возвращении компонента в активное состояние.
В спецификации Advanced Configuration and Power Interface (www.acpi.info) предлагается общая терминология и стандартный набор интерфейсов для программных механизмов управления расходом мощности и потреблением энергии. ACPI определяет до 16 активных — или эксплуатационных — состояний от P0 до P15, а также три состояния простоя — или энергетических состояния — от C1 до C3 (либо от D1 до D3 для устройств). Данная спецификация определяет набор таблиц, в которых задаются такие зависящие и от процессоров, и от устройств характеристики этих состояний, как мощность/быстродействие/запаздывание.
Простой, но эффективный подход к определению политик в области энергопотребления состоит в том, чтобы специфицировать набор рабочих состояний системы — структуру состояний и режимов системных компонентов, — а затем написать политику, обеспечивающую переход от нынешнего состояния системы и функционирования приложения к иному рабочему состоянию системы, определенному в соответствии с желаемыми характеристиками энергопотребления и производительности.
Именно по такому пути пошли IBM и MontaVista Software при работе над программной архитектурой Dynamic Power Management (DPM), которая должна была обеспечить динамическое масштабирование напряжений и частот для решений категории «система на кристалле» [15]. Разработчики могут использовать DPM для манипуляций частотами ядер процессоров и соответствующих шин согласно политикам высокого уровня, которые они создают с помощью факультативных диспетчеров политик.
На первых порах специалисты сосредоточивают свои усилия на динамическом масштабировании напряжений и частот в «системах на кристалле», однако вполне возможна разработка подобной архитектуры, предназначенной для управления другими параметрами в серверах старшего класса.
Первые работы, посвященные программным средствам управления энергопотреблением, проводились главным образом в целях совершенствования встроенных и портативных систем. Исследователи изыскивали возможности экономии энергии — а следовательно, увеличения срока работы от батарей — за счет снижения производительности систем.
С недавнего времени получил распространение подход, что энергосберегающие политики должны быть реализованы в операционных системах. ОС должны управлять расходом энергии так же, как и другими системными ресурсами, такими, как время использования ЦП, распределение памяти и доступ к дискам [16].
Затем были разработаны опытные образцы систем, в которых энергия рассматривается как первоклассный ресурс, управляемый ОС [17]. В этих прототипах абстракция энергии используется для унификации управления энергетическими состояниями и системными компонентами, включая ЦП, диск и сетевой интерфейс.
Расширение таких операционных систем с тем, чтобы они могли управлять значительно более сложными машинами высокого класса, а также разработка политик, соответствующих требованиям серверных систем, — задачи непростые. В числе ключевых вопросов, которые нужно будет решить на этом пути, — проблемы управления частотами и непроизводительными простоями. Кроме того, предстоит упростить излишне сложные процедуры измерения мощности и организации учета и сократить непроизводительные расходы, связанные с управлением энергопотреблением крупномасштабных систем.
Возможно, облегчению решения задач управления энергопотреблением систем высокого класса будет способствовать использование гипервизора — программного слоя, позволяющего одновременно запускать на одном сервере несколько операционных систем, — хотя это повлечет за собой повышение уровня сложности системы в целом. Гипервизор по необходимости инкапсулирует политики совместного использования системных ресурсов среди образов исполнения. Включение в эти политики правил, обеспечивающих эффективное использование энергии, дает гипервизору возможность контролировать управление энергопотреблением в масштабах всей системы. Кроме того, в этом случае разработчики смогут реализовать механизмы управления энергопотреблением и политики, созданные с учетом особенностей данного сервера, без необходимости внесения изменений в выполняемые на нем операционные системы.
Известно, что многие серверы организованы в кластеры и что включение и отключение целых систем выполняется относительно легко. Поэтому некоторые исследователи рассматривают возможность управления энергопотреблением на уровне кластеров. Так, в [14] описана модель, которая определяет число активных серверов, необходимых для работы системы, путем сопоставления выигрыша в производительности, получаемого при добавлении нового сервера, и энергетических затрат, связанных с его эксплуатацией.
Для сокращения числа работающих серверов был создан метод распределения запросов с учетом расходуемой энергии (power-aware request distribution, PARD). Этот метод обеспечивает перенесение нагрузки на несколько серверов и отключение всех остальных машин. При изменении нагрузок PARD предусматривает включение и выключение машин по необходимости.
Дальнейшие направления поиска
Эффективность средств управления энергопотреблением серверных систем будет в значительной степени определяться результатами исследований в трех следующих областях:
- архитектуры, обеспечивающие эффективное энергопотребление управление средствами и политиками управления энергопотреблением в масштабах систем и
- оценка компромиссов, достигаемых при различных соотношениях уровней энергопотребления и технических показателей.
Хорошие перспективы использования в качестве обеспечивающей высокую эффективность энергопотребления архитектуры имеют гетерогенные системы. Эти системы состоят из нескольких обрабатывающих элементов, каждый из которых предназначен для обслуживания конкретных типов рабочих нагрузок с высокой степенью эффективности в сферах энергопотребления и производительности. Например, гетерогенная система для Internet-приложений включает и сетевые процессоры, и набор процессоров, отличающихся высокой эффективностью энергопотребления. Таким образом, обеспечивается и эффективная обработка сетевых протоколов, и вычисления на уровне приложений.
В условиях, когда плотность размещения транзисторов постоянно повышается, идея использования гетерогенных структур пробивает себе дорогу и на микроархитектурной арене, где на одном кристалле располагается несколько ядер, и каждое из них ориентировано на эффективную обработку того или иного типа рабочей нагрузки. В рамках первых исследований в этой области использовался кристалл, на котором располагалось несколько процессоров Alpha различных поколений. При этом выполнение рабочих операций возлагалось только на то ядро, которое характеризуется наименьшим энергопотреблением, но в то же время обеспечивает достаточную производительность для обслуживания текущей рабочей нагрузки [20]. При изменении рабочей нагрузки системное программное обеспечение передает исполняемую программу от одного ядра к другому, стремясь обеспечить необходимую скорость выполнения приложения, сохраняя энергопотребление на минимальном уровне.
В серверах могут одновременно использоваться несколько методов управления энергопотреблением. Чтобы не потерять дорогу в сложном лабиринте различных методов и приложений и достичь желаемого соотношения энергопотребление/производительность, нужно непременно обеспечить скоординированное управление. Одно из ключевых направлений в этой сфере — разработка высокоуровневых политик управления энергопотреблением и соотнесение этих политик с существующими механизмами.
Другой существенный вопрос состоит в том, где именно реализовывать упоминавшиеся ранее различные политики и механизмы: в специализированных прикладных программах, обеспечивающих управление энергопотреблением, в других приложениях, в ПО промежуточного слоя, в операционных системах, в гипервизорах или в индивидуальных аппаратных компонентах. Ясно, что сама по себе ни одна из этих альтернатив не может дать исчерпывающего решения проблем управления энергопотреблением. Для получения такого решения необходимо как минимум, наладить эффективный обмен информацией между различными уровнями системы.
Главная трудность состоит в том, чтобы обеспечить корректную работу такой направляемой автономии, сохраняя при этом уровень непроизводительных расходов в разумных пределах. Некоторые исследователи предлагают использовать модели, основанные на принципах экономики [17]. Еще один вариант — при организации управления энергопотреблением применять методы управления с помощью обратной связи и методы прогнозирования. В проекте, описанном в [21], управление производительностью на уровне систем осуществляется с привлечением прогностических методов, но проблема использования этих методов исследуется не столь интенсивно.
Конструкторам и инженерам требуются методики, позволяющие точно и без излишних хлопот оценивать средства управления энергопотреблением. А для этого нужны исходные данные, которые принимают в расчет не только пиковую производительность системы, но и быстродействие в сочетании с расходуемой мощностью и со стоимостью потребленной энергии. С рассматриваемой проблемой тесно связан и вопрос использования метрик, в которых сочетаются соображения, связанные как с потреблением энергии, так и с быстродействием. Еще один ключевой компонент — возможность осуществлять подробный мониторинг функционирования системы и коррелировать полученные данные с энергопотреблением.
За последние несколько лет средства мониторинга производительности получили большое развитие; теперь в этих процессах задействуются высококлассные процессоры, обслуживающие массивы программируемых счетчиков, которые выполняют мониторинг событий. Но для управления энергопотреблением на уровне системы необходимы сведения о транзакциях на уровне шин и о процессах, происходящих в иерархических структурах памяти. Между тем, пока мы располагаем лишь незначительной частью этой информации. Не менее важна и возможность соотнесения значения упомянутых счетчиков как с уровнем энергопотребления, так и с фактической производительностью на уровне приложений. Ведь как бы то ни было, конечная цель состоит в том, чтобы добиться нужного соотношения между быстродействием приложений и уровнем энергопотребления системы.
Литература
- T. Mudge, "Power: A First-Class Architectural Design Constraint", Computer, Apr. 2001.
- M. Weiser et al., "Scheduling for Reduced CPU Energy", Proc. 1st Symp. Operating Systems Design and Implementation, Usenix, 1994.
- K. Flautner, T. Mudge, "Vertigo: Automatic Performance- Setting for Linux", Proc. 5th Symp. Operating Systems Design and Implementation, Usenix, 2002.
- P. Bohrer et al., "The Case for Power Management in Web Servers", Power-Aware Computing, R. Gray-bill, R. Melhem, eds., Series in Computer Science, Kluwer/Plenum, 2002.
- J. Seng, D. Tullsen, G. Cai, "Power-Sensitive Multithreaded Architecture", Proc. 2000 Int'l Conf. Computer Design, IEEE CS Press, 2000.
- L.A. Barroso et al., "Piranha: A Scalable Architecture Based on Single-Chip Multiprocessing", Proc. 27th ACM Int'l Symp. Computer Architecture, 2000.
- W. Felter et al., "On the Performance and Use of Dense Servers", IBM J. Research and Development, vol. 47, no. 5/6, 2003.
- V. Delaluz et al., "Scheduler-Based DRAM Energy Management", Proc. 39th Design Automation Conf., ACM Press, 2002.
- H. Huang, P. Pillai, K.G. Shin, "Design and Implementation of Power-Aware Virtual Memory", Proc. Usenix 2003 Ann. Technical Conf., Usenix, 2003.
- A.R. Lebeck et al., "Power-Aware Page Allocation", Proc. Int'l Conf. Architectural Support for Programming Languages and Operating Systems, ACM Press, 2000.
- V. Delaluz, M. Kandemir, I. Kolcu, "Automatic Data Migration for Reducing Energy Consumption in Multi-Bank Memory Systems", Proc. 39th Design Automation Conf., ACM Press, 2002.
- R.B. Tremaine et al., "IBM Memory Expansion Technology (MXT)", IBM J. Research and Development, vol. 45, no. 2, 2001.
- A. Moshovos et al., "Jetty: Filtering Snoops for Reduced Energy Consumption in SMP Servers", Proc. 7th Int'l Symp. High-Performance Computer Architecture, IEEE CS Press, 2001.
- C. Saldanha, M. Lipasti, "Power Efficient Cache Coherence", High-Performance Memory Systems, H. Hadimiouglu et al., eds., Springer-Verlag, 2003.
- B. Brock, K. Rajamani, "Dynamic Power Management for Embedded Systems", Proc. IEEE Int'l SOC Conf., 2003.
- A. Vahdat, A. Lebeck, C. Ellis, "Every Joule Is Precious: The Case for Revisiting Operating System Design for Energy Efficiency", Proc. 9th ACM SIGOPS European Workshop, ACM Press, 2000.
- H. Zeng et al., "Currentcy: A Unifying Abstraction for Expressing Energy Management Policies," Proc. General Track: 2003 Usenix Ann. Technical Conf., 2003.
- J. Chase et al., "Managing Energy and Server Resources in Hosting Centers", Proc. 18th Symp. Operating Systems Principles, ACM Press, 2001.
- K. Rajamani, C. Lefurgy, "On Evaluating Request-Distribution Schemes for Saving Energy in Server Clusters", Proc. IEEE Int'l Symp. Performance Analysis of Systems and Software, IEEE Press, 2003.
- R. Kumar et al., "A Multi-Core Approach to Addressing the Energy-Complexity Problem in Microprocessors", Proc. Workshop on Complexity-Effective Design, 2003.
- L. Russell, S. Morgan, E. Chron, "Clockwork: A New Movement in Autonomic Systems", IBM Systems J., vol. 42, no. 1, 2003.
Чарльз Леферджи (lefurgy@us.ibm.com), Картик Раджамани (karthick@us.ibm.com), Фриман Росон (frawson@us.ibm.com), Уэс Фелтер (wmf@us.ibm.com), Майкл Кистлер (mkistler@us.ibm.com), Том Келлер (tkeller@us.ibm.com) — сотрудники исследовательской лаборатории IBM Austin Research Lab.
Charles Lefurgy, Karthick Rajamani, Freeman Rawson, Wes Felter, Michael Kistler, Tom Keller, Energy Management for Commercial Servers. IEEE Computer, December 2003. IEEE Computer Society, 2003, All rights reserved. Reprinted with permission.
Энергосбережение в серверах, объединенных в кластеры
Проблемы сокращения мощности и энергосбережения в высокопроизводительных серверах приобретают особую значимость — особенно в тех случаях, когда речь идет о машинах, объединенных в большие кластерные конфигурации, как, скажем, в вычислительных центрах или центрах Web-хостинга [1].
Группы исследователей из Университета Рютгерса [2] и Университета Дьюка [3] разработали сходные стратегии управления энергопотреблением кластеров Web-серверов. Идея обоих проектов) состоит в том, чтобы распределять поступающую на серверный кластер нагрузку динамически — так, чтобы при наличии небольших нагрузок система могла высвобождать часть аппаратных ресурсов и переводить их в режимы с низким потреблением энергии. При больших нагрузках система должна реактивировать ресурсы и перераспределять нагрузку с тем, чтобы не допускать снижения производительности. Поскольку кластеры Web-серверов тиражируют данные о файлах во всех узлах и традиционное серверное оборудование обладает очень высокой базовой мощностью, расходуемой в ситуациях, когда система включена, но не несет нагрузки, — эти системы динамически отключают и подключают к работе целые узлы, что сводится к реконфигурации всего кластера.
|
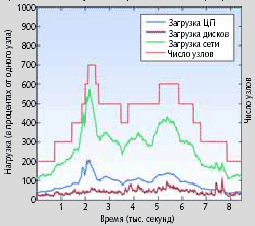
| Рис. A. Эволюция кластера и прилагаемые нагрузки в пересчете на ресурс. На протяжении всего эксперимента наиболее узким местом оставался сетевой интерфейс |
На рис. A отображены статистические данные, характеризующие функционирование исследуемого учеными из университета Рютгерса кластера. Он состоит из семи узлов и выполняет реальную, но ускоренную Web-трассировку. Эволюция кластерной конфигурации и нагрузки, прилагаемые к каждому ресурсу, представлены на рисунке как функции времени. Нагрузка на каждый ресурс отображается в виде процента от номинальной производительности того же ресурса в одном узле. Рисунок показывает, что на протяжении всего эксперимента узким местом оставался сетевой интерфейс.
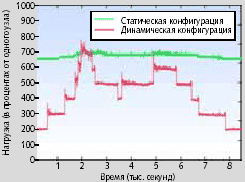
Рис. B демонстрирует энергопотребление описанного кластера для двух версий того же эксперимента; и здесь данные тоже представлены как функция времени. Нижняя кривая (динамическая реконфигурация) представляет реконфигурируемую версию системы, а верхняя кривая (статическая конфигурация) представляет конфигурацию из семи узлов. Рисунок показывает, что реконфигурации позволяет значительно сократить энергопотребление на протяжении почти всего эксперимента; в общей сложности экономия энергии составляет 38%.
|
| Рис. B. Энергопотребление статической и динамической конфигураций. Реконфигурация обеспечивает значительное снижение энергопотребления практически на протяжении всего эксперимента. Общая экономия энергии составляет 38% |
В [4] представлено исследование потенциала средств реконфигурирования кластеров в том, что касается энергосбережения, через использование резервных серверов, а также сведений об истории пиковых нагрузок серверов. Кроме того, они моделировали важнейшие системные и нагрузочные параметры, влияющие на применение описанной методики.
В [5] описаны результаты оценки различных сочетаний кластерных реконфигураций и двух типов динамического масштабирования напряжения — независимого и скоординированного — для кластеров с относительно низкой базовой мощностью. В случае независимого масштабирования напряжения каждый узел сервера принимает собственное решение относительно того, какое напряжение и частоту он будет использовать, в зависимости от получаемой узлом нагрузки. В ситуации скоординированного масштабирования узлы координируют свои параметры, определяющие напряжение и частоты. Результаты моделирования показали, что при одних нагрузках предпочтительнее метод скоординированного масштабирования напряжения, при других — метод реконфигурации, но в любом случае наилучшие результаты всегда дает сочетание двух методик.
По итогам другого исследования [6] предложен такой метод снижения энергозатрат легко загруженного процессора, как пакетирование запросов. Процессор сетевого интерфейса накапливает поступающие запросы в памяти, тогда как хост-процессор сервера функционирует в состоянии пониженного энергопотребления. Когда время пребывания запроса в стадии ожидания превышает заданное пороговое значение, система выводит хост-процессор из состояния «спячки».
В [7] проблема реконфигурации рассматривается в контексте гетерогенных серверных кластеров. Результаты их экспериментов с кластером, состоящим из традиционных узлов и лезвий, показывают, что сервер использующий потенциал гетерогенной архитектуры в состоянии обеспечить в два с лишним раза большую экономию энергии, нежели сервер, не использующий таких возможностей.
Литература
- R. Bianchini, R. Rajamony, Power and Energy Management for Server Systems, tech. report DCS-TR-528, Dept. Computer Science, Rutgers Univ., 2003.
- E. Pinheiro et al., "Dynamic Cluster Reconfiguration for Power and Performance", L. Benini, M. Kandemir, J. Ramanujam, eds., Compilers and Operating Systems for Low Power, Kluwer Academic, 2003.
- J.S. Chase et al., "Managing Energy and Server Resources in Hosting Centers", Proc. 18th ACM Symp. Operating Systems Principles, ACM Press, 2001.
- K. Rajamani, C. Lefurgy, "On Evaluating Request-Distribution Schemes for Saving Energy in Server Clusters", Proc. 2003 IEEE Int'l Symp. Performance Analysis of Systems and Software, IEEE Press, 2003.
- E.N. Elnozahy, M. Kistler, R. Rajamony, "Energy-Efficient Server Clusters", Proc. 2nd Workshop Power-Aware Computing Systems, LNCS 2325, Springer, 2003.
- E.N. Elnozahy, M. Kistler, R. Rajamony, "Energy Conservation Policies for Web Servers", Proc. 4th Usenix Symp. Internet Technologies and Systems, Usenix Assoc., 2003.
- T. Heath et al., "Self-Configuring Heterogeneous Server Clusters", Proc. Workshop Compilers and Operating Systems for Low Power, 2003.
Рикардо Бьянчини (ricardob@cs.rutgers.edu) —профессор Университета Рютгерса.
Рэм Раджамони (rajamony@us.ibm.com) —сотрудник лаборатории IBM Austin Research Lab.
