
 Кто бы мог предположить полтора десятка лет назад, когда символами производительности были векторные суперкомпьютеры, мэйнфреймы и мощные Unix-серверы, что будущее компьютерных систем вообще и высокопроизводительных вычислений (High Performance Computing, HPC) в частности в значительной мере будет связано не с ними. Тогда никто бы не поверил, что со временем фокус внимания сместится на кластеры и центры обработки данных, собранные из простейших, так называемых стандартных серверов. Но вышло именно так. А началось все с примитивных на первый взгляд, кластеров Beowulf, на которые на первых порах смотрели как на экзотику, не принимая всерьез.
Кто бы мог предположить полтора десятка лет назад, когда символами производительности были векторные суперкомпьютеры, мэйнфреймы и мощные Unix-серверы, что будущее компьютерных систем вообще и высокопроизводительных вычислений (High Performance Computing, HPC) в частности в значительной мере будет связано не с ними. Тогда никто бы не поверил, что со временем фокус внимания сместится на кластеры и центры обработки данных, собранные из простейших, так называемых стандартных серверов. Но вышло именно так. А началось все с примитивных на первый взгляд, кластеров Beowulf, на которые на первых порах смотрели как на экзотику, не принимая всерьез.
Еще недавно создание кластеров Beowulf не считали сложной задачей. Их даже называли кластерами, созданными «по необходимости, в нужный момент» (ad-hoc cluster), предполагая, что их можно не только собрать, но и потом при необходимости разобрать. Это стало излюбленным занятием студентов и аспирантов в университетах, а также сотрудников НИИ. Понять их можно?— в пересчете на «флопы» стоимость вычислений на этих, собранных из ПК системах на несколько порядков меньше, чем на обычных серверах.
Для сравнения, комплекс из двух весьма недешевых Unix-серверов RM 600 Е20-Е60, установленный в Институте проблем химической физики РАН, имеет пиковую производительность 10 GFLOPS, а 130-процессорный кластер CLI-X, собранный из обычных ПК, в 100 раз мощнее (1,18 TFLOPS) и в десятки раз дешевле. Разумеется, следует сделать поправку на меньшую универсальность и несопоставимые показатели надежности, готовности и обслуживаемости, однако есть немало конкретных приложений, где скорость счета важнее.
Впрочем, рано или поздно романтический «гаражный» период заканчивается и начинается период индустриальный; эта закономерность прослеживается во многих областях человеческой деятельности. По истечении определенного времени на смену изобретателям-энтузиастам приходят инженеры и технологи,?— достаточно вспомнить романтику авиации в первой трети XX века и сравнить ее с современными пассажирскими и грузовыми авиаперевозками. Кластеростроение не исключение.
Появление высокопроизводительных кластеров не явилось большой неожиданностью. Показательно, что немногим более десяти лет назад вышла статья Дмитрия Арапова «Можно ли превратить сеть в суперкомпьютер?» (Открытые системы, № 4, 1997). Несмотря на немалый срок, прошедший с того момента, она не потеряла своей актуальности. Эта статья?— явное свидетельство того, что вопрос об объединении сетевых ресурсов в единый вычислительный пул «висел в воздухе». Примерно в то же время на него был получен ответ, разумеется, положительный. Соответствующее решение было найдено с использованием технологий, предназначенных для локальных сетей (прежде всего Ethernet), достигших к тому времени нужного уровня развития. Будущее показало, что локальные сети?— не единственный способ превратить множество вычислительных узлов в единый компьютер: сети такого рода могут быть как глобальными, так и сетями на одном кристалле.
Как оказалось, ответ на поставленный вопрос был дан раньше, чем он прозвучал. Еще в 1994 году сотрудники NASA Дональд Беккер и Томас Стерлинг создали кластер Beowulf. Он состоял из 16 процессоров DX4, соединенных 10-мегабитной сетью Ethernet. Однако в силу обстоятельств сведения о нем дошли до компьютерной общественности с задержкой на несколько лет. Со временем так стали называть все высокопроизводительные системы подобного типа. Кластеры Beowulf сегодня доминируют во всех списках самых производительных вычислительных систем. Главной особенностью таких компьютеров было и остается то, что их можно собрать из имеющихся на рынке продуктов, раньше это были системные блоки, а сегодня?— серверы-лезвия.
После первых открытых публикаций идея сборки кластеров нашла своих приверженцев в научных коллективах. Доступность вычислительных ресурсов привела к тому, что за несколько лет сформировалось множество новых направлений, объединенных названием e-Science. Суперкомпьютеры в состоянии изменить сложившуюся научную и инженерную парадигму. Мы привыкли к тому, что вначале создается теория, затем проводятся физические, химические или технические эксперименты и испытания. Направление e-Science предполагает более интенсивное использование методов моделирования численными методами. В свою очередь, развитие e-Science стимулирует прогресс в супервычислениях, ориентированных на интенсивную работу с данными (Data-Intensive Super Computing, DISC).
Заметим, что параллельно с кластерами создавались еще и специализированные сети?— из рабочих станций. Наиболее известной работой в данном направлении в рамках проекта Network Of Workstations руководили Дэвид Куллер и Дэвид Паттерсон из университета Беркли. Так, в NOW-2 было 105 рабочих станций Sun Ultra-1 на процессорах UltraSPARC, объединенных в коммутируемую сеть технологией Myrinet. При внешней схожести между Beowulf и NOW (иногда эту сеть еще называют Cluster of Workstations) есть принципиальное различие. Действительно, у Beowulf есть центр управления, а потому его можно рассматривать как единую машину; в NOW его нет, это всего лишь некоторое количество рабочих станций, объединенных в сеть, способную к решению общей задачи. NOW как направление развития оказалось малоперспективным, однако его авторы впоследствии реабилитировали себя, создав через десять лет сети на кристалле RAMP, о которых речь далее.
Первое поколение Beowulf и его проблемы
Системное единство Beowulf обеспечивается тем, что логически неоднородная сеть состоит из двух типов серверных узлов: в сети должен быть хотя бы один мастер-узел, управляющий множеством клиентских узлов (рис. 1). Вся функциональность, связанная с управлением и взаимодействием с внешним миром, сосредоточена в мастер-узле, а остальные служат только для счета. Во всех известных руководствах по строительству Beowulf отмечается: чем проще («тоньше») вычислительные узлы, тем лучше с эксплуатационной точки зрения. Кластеры обычно работают под управлением ОС Linux, а для коммуникации между узлами используются технологии PVM (Parallel Virtual Machine?— «параллельная виртуальная машина») или MPI (Message Passing Interface?— «интерфейс, основанный на обмене сообщениями»).

В 2004 году праздновалось десятилетие Beowulf. Выступая на мероприятии, Беккер сказал: «Десять лет назад никто не приветствовал появление на свет Beowulf; сегодня в это трудно поверить, но первая реакция научной общественности была сугубо отрицательной. Мы даже не могли предположить подобной оппозиционности, поэтому удивлены тем, что сегодня все поголовно превратились в приверженцев нашей концепции. При создании Beowulf мы руководствовались тремя соображениями. Во-первых, соотношение цена/производительность в сегменте ПК снижалось существенно быстрее, чем в остальных классах компьютеров, у ПК лучшие экономические перспективы. Во-вторых, мы пришли к осознанию того факта, что использование общедоступной аппаратной базы позволит развивать программное обеспечение силами сообщества. И история доказала нашу правоту. И, в-третьих, к концу 1993 года Linux уже представляла собой надежную операционную систему, способную работать в сети, и ею могло воспользоваться сообщество, образовавшееся вокруг идеи Beowulf».
Однако тот же самый десятый год в истории оказался Beowulf не только юбилейным, но и переломным, вместе с ним закончилась научно-инициативная полоса развития и началась профессиональная. Ее стимулировало появление ультратонких серверов и серверов-лезвий. На смену стеллажам с установленными на них системными блоками, приходят стандартные 19-дюймовые стойки, начинается массовое распространение кластеров. Вместе с ним проявляются и неизбежные, принципиально новые проблемы.
Источником успеха первого поколения кластеров Beowulf являлась простота их инфраструктуры, она же послужила стала причиной сложностей на следующем этапе. Ничто не дается даром. Оставив за компьютерами только «голую» вычислительную начинку, кластеры Beowulf первого поколения потребовали взамен больших затрат труда на установку, конфигурирование и эксплуатацию, они сложны в администрировании и модернизации, допускают только статическое масштабирование. До тех пор пока кластер можно было после эксперимента разобрать на системные блоки, подобные проблемы воспринимались естественно, но, когда они превратились в коммерческий продукт, отношение к этим проблемам изменилось.
Второе поколение Beowulf и виртуализация
Кластеры Beowulf первого поколения оказали колоссальное влияние на развитие многих дисциплин?— на газовую динамику и динамику движения жидкостей, на исследования в биологии, на расчеты механических конструкций, на сейсмический анализ, даже на финансовую аналитику. Но, признавая все их достоинства, следует признать и то, что они были и остаются подчиненными одной цели?— собрать множество машин вместе и заставить сеть работать, используя соответствующие библиотеки. На первых порах существовала иллюзия, что цель эта вполне достижима. Между тем с системной точки зрения очевидно?— простая сборка однородных компонентов не обеспечивает системе нужных качеств. Любая система сильна не только своими исполнительными органами, но прежде всего управлением, это можно наблюдать в технике и в общественной жизни, кластеры не исключение. Можно выделить несколько направлений для усовершенствования кластеров первого поколения (см. Bob Monkman, Next-Generation Linux Clusters, Enterprise OpenSource Magazine):
-
стабильность, надежность и прозрачность системы первоначальной загрузки;
-
механизмы для начального развертывания и модернизации всех элементов системы;
-
модель установки приложений, предполагающая отсутствие системного состояния и позволяющая загружать приложение непосредственно в оперативную память;
-
возможность динамического обновления системы;
-
средства для динамического управления ресурсами и отключение тех частей, которые не нужны для исполняемого приложения;
-
единая точка управления системными ресурсами и выполняемыми заданиями;
-
специализированная файловая система, адаптированная к требованиям приложений.
Удовлетворение всем перечисленным условиям?— дело будущего. Пока же в кластерах доминирует пакетный режим работы, который неэффективен, поскольку независимо от потребностей задачи ей отдаются все ресурсы кластера, а все действия, связанные с управлением данными и заданиями, выполняются вручную.
Полноценным выходом из сложившегося положения могут быть технологии виртуализации. Одним из первых эту мысль высказал Беккер в интервью в 2005 году (Beowulf founder: Virtualization hot on Linux clusters). Он утверждал, что виртуализация решает проблемы, но стоит заметить, что он понимал сущность виртуализации иначе, чем большинство специалистов в то время. Тогда лидеры, VMware и Xen, сосредоточили свое внимание только на одной стороне виртуализации, а именно на возможности предоставления одного физического ресурса в виде множества независимых логических. Виртуализация кластеров?— обратная задача: в кластерах требуется представить множество ресурсов в виде одного. Странно, что, рассуждая на эту тему, Беккер почему-то упустил из виду многочисленные работы, связанные с системами хранения данных, где решается именно эта задача. По своей логике к кластерам ближе именно виртуализация систем хранения, чем виртуализация серверов. В 2006 году компанией Penguin Computing под руководством того же Беккера было выпущено программное обеспечение Scyld ClusterWare HPC, обеспечивающее виртуализацию кластерной среды и позволяющее представить весь пул Linux-серверов в форме единой виртуальной системы. В Scyld ClusterWare имеется одна точка управления?— мастер-узел, с помощью которого можно за считанные секунды собрать из имеющихся ресурсов требуемую конфигурацию. Комментируя появление нового продукта, Беккер сказал: «За годы эксплуатации серверов мы пришли к осознанию простой истины. Когда вы собираете машину в первый раз и запускаете на ней приложение, все замечательно. Но потом из-за появления новых версий начинается расползание. Если у вас нет четко прописанного механизма для управлениями версиями приложений и конфигурационных файлов, то рано или поздно вы попадете в сложную ситуацию».
При создании своих кластеров Беккер руководствовался тремя основными принципами.
Вычислительные узлы кластера должны быть бездисковыми, не иметь и не сохранять свое собственное состояние. Это позволяет реализовать простую процедуру развертывания приложений. Возможность создания бездисковых узлов обеспечивается несколькими факторами: наличием высокоскоростных сетей, большими объемами оперативной памяти и созданием компактных версий операционных систем. Для сравнения, обычная установка ОС на диск занимает от четверти часа до получаса и еще требует дополнительной ручной настройки, а с использованием подхода, реализованного в Scyld ClusterWare и предусматривающего загрузку ОС на узел без собственного состояния, это время сокращается до 20 секунд. В той же пропорции сокращается время на замену узла и модернизацию его программного обеспечения. Централизованное хранение версий полностью исключает вероятность «расползания версий».
На узлах кластера развертывается облегченная операционная среда. В Scyld ClusterWare реализована версия Linux существенно меньшего размера, чем используемая обычно в проектах Beowulf, ее размер всего 8 Мбайт (сравните с обычными 800 Мбайт). Ее можно полностью загрузить в оперативную память, поскольку она занимает менее 1% привычного размера памяти в 1 Гбайт. Очевидно, что резидентная в памяти операционная система работает быстрее.
Виртуализация распространяется на весь кластер. Поэтому администратор «видит», скажем, не 100 четырехпроцессорных узлов, и один 400-процессорный SMP-сервер, а вся работа с пользователями, паролями и другие служебные операции полностью сосредоточены на «мастере».
Даже при самом поверхностном анализе предлагаемой кластерной идеологии невольно напрашивается сравнение с архитектурой тонкого клиента. Аргументы в пользу «утоньшения» почти совпадают, впрочем, в этом нет ничего удивительного: в кластере вычислительный узел выступает в роли клиента по отношению к мастер-узлу, а чем проще клиенты, тем легче ими управлять. В основе Beowulf второго поколения лежит технология Beowulf Distributed Process (Bproc), особенность которой в том, что он обеспечивает возможность миграции процессов по узлам кластера (рис. 2). Все процессы представлены в специальной таблице, поддерживаемой мастер-узлом. Сочетание BProc с ультратонким узлом Scyld ClusterWare создают новую парадигму кластерных вычислений, отличающуюся логической простотой и элегантностью.

Кластерное программное обеспечение
Отмеченное несовершенство первого поколения кластеров вызвало к жизни, многочисленные попытки усовершенствовать его программный инструментарий. Принципы Open Source никак не ограничивали свободу творчества, а потому в начале 2000-х во множестве университетов и исследовательских лабораторий стали запускать собственные проекты высокопроизводительных кластеров. Они строились примерно на той же аппаратной платформе, что и Beowulf, но отличались оригинальным программным обеспечением. Во многих случаях название Beowulf оставалось за аппаратной архитектурой, на которой могло работать самое разное программное обеспечение. Уже к 2002 году насчитывалось не менее 30 известных независимых проектов, авторы которых ставили своей целью повысить адаптивность и функциональность кластеров. Часть из них завершилась, так не оставив заметных результатов, некоторые разработки были приобретены крупными компаниями (к примеру, проект Cluster Systems Management стал основой для кластеров корпорации IBM). Есть совсем мало примеров появления независимых компаний, специализирующихся на кластерах; среди них ClusterIt, теперь появились Mach1 Computing, есть еще канадская компания Platform Computing. Некоторые продолжают свое существование в недрах крупных лабораторий, Clustermatic?— в Лос-Аламосской национальной лаборатории, а Cplant (Computational Plant?— «вычислительный завод») при национальной лаборатории в Сандии. Их целью является обеспечение широкомасштабных решений на основе имеющихся на рынке компьютерных ресурсов для критически важных приложений; так, в феврале текущего года было объявлено, что Сандия получила финансирование на строительство компьютера, который должен преодолеть экзафлопный барьер 1018 операций.
Итогом описанного эволюционного процесса стала новая категория программного обеспечения, получившая название cluster middleware. Речь идет о наборе средств, осуществляющем представление совокупности кластерных ресурсов в образе единой машины. Перечислим его типовые компоненты.
-
Система управления потоком работ (Job Management System, JMS). Отвечает за расписание и диспетчеризацию работ, предоставляет средства для описания работ, мониторинга их прохождения и для получения результатов. Администратор использует эту систему для определения правил, которыми руководствуются пользователи, в части распределения, ограничения и резервирования ресурсов. Ее средствами можно собирать статистику нагрузки, с тем чтобы оценивать загруженность кластера.
-
Система мониторинга кластера (Cluster Monitoring System, CMS). Служит для сбора технических данных, таких как загруженность процессоров, объем занятой памяти, наличие свободного дискового пространства. Эти сведения администратор кластера использует для обнаружения потенциальных проблем и оптимизации его работы, а обычные пользователи?— для отладки своих заданий. Кроме того, они передаются в JMS для поддержки расписания работ.
-
Библиотеки для параллельной работы. Предоставляют разработчикам приложений средства распараллеливания заданий и синхронизации в процессе их исполнения (чаще всего это те или иные варианты MPI или PVM). Также могут быть использованы различные языки параллельного программирования.
-
Средства для управления кластером. Область действия системы управления распространяется на весь кластер; ее основная функция?— поддержка процессов установки программного обеспечения в узлах кластера, она же служит для обнаружения ошибок в его работе и для изменения его конфигурации.
-
Глобальное пространство процесса. Связывает воедино все узлы кластера.
Набор перечисленных компонентов по аналогии с операционными системами называют «кластерными дистрибутивами» (cluster distribution). В число наиболее распространенных дистрибутивов входят Rocks, OSCAR, OpenSCE, Scyld Beowulf, Clustermatic, Warewulf, xCAT и Score. Все они построены на основе ОС Linux.
Rocks
Разработавшее Rocks партнерство National Partnership for Advanced Computational Infrastructure уже не существует, сейчас его поддерживает Rocks Group. Дистрибутив Rocks, основанный на Red Hat Linux, использует механизмы этой операционной системы для распространения программного обеспечения по вычислительным узлам кластера. Поддерживается несколько вариантов JMS (SGE, OpenPBS и Condor). Дистрибутив известен своей высокой степенью автоматизации процессов первичной установки, но при этом почти не приспособлен к модернизации. Поэтому в случаях, когда требуется обновление, его приходится устанавливать заново.
OSCAR
Проект OSCAR (Open Source Cluster Application Resources) разрабатывается общественной организацией Open Cluster Group. Его первоначальный замысел принадлежит Тимоти Мэттсону из лаборатории Аргоннской национальной лаборатории и Стивену Скотту из лаборатории в Окридже,?— они стремились создать дистрибутив, который был бы проще во внедрении, чем Beowulf, не требуя серьезных знаний в программировании. Поэтому OSCAR не привязан ни к одной определенной операционной системе, а содержит в себе только необходимые компоненты кластерного программного обеспечения.
OpenSCE
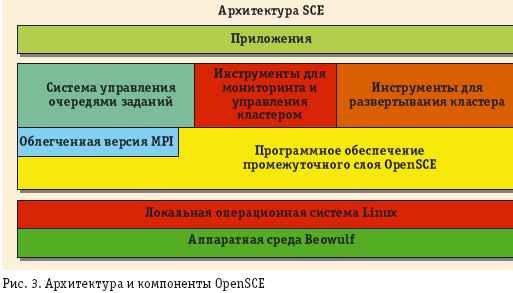
Проект OpenSCE (Open Scalable Cluster Environment) поддерживается таиландским Центром высокопроизводительных вычислений и сетей. В отличие от других кластерных дистрибутивов, не интегрирует известные компоненты, а целиком построен на своих собственных; его архитектура и основные составляющие показаны на рис. 3.
Scyld
Проект Scyld Beowulf отличается от большинства аналогичных проектов своим коммерческим статусом.
Clustermatic
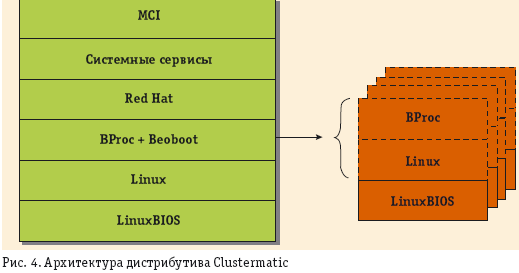
Дистрибутив Clustermatic разработан в лаборатории кластерных исследований в составе знаменитой Лос-Аламоской национальной лаборатории. По своей логике он ближе всего ко второй версии Beowulf. Все основные компоненты кластерного программного обеспечения устанавливаются на мастер-узлах, на вычислительных узлах есть только загрузочный модуль, операционная система, и Bproc на них подгружаются (рис. 4).
Warewulf
Проект Warewulf Cluster Project недавно переименован в Perceus. В нем, как в Clustermatic и Scyld Beowulf, использованы технологии виртуализации, минимизирующие объем программного обеспечения, устанавливаемого на вычислительных узлах. Его спонсирует консорциум, в который входят корпорации Intel, IBM, национальная лаборатория Лоуренса в Беркли и ряд других организаций.
xCAT
Проект xCAT (Extreme Linux Cluster Administration Toolkit) Университета штата Индиана ориентирован в первую очередь на кластеры IBM и инструментарий IBM Management Processor Network для управления и мониторинга узлов.
SCore
Проект Score, объединяющий в основном японские организации, а также отделения международных компаний, работающих в Японии, поддерживается специально созданной группой PC Cluster Consortium.
Microsoft и HPC
Выпустив Windows Compute Cluster Server 2003, в 2005 году на путь создания программного обеспечения для кластеров вступила корпорация Microsoft. Разработкой непосредственно руководил Кирилл Фаенов, несколько раз бывший гостем нашего журнала, в прошлом году в своем интервью (см. «Суперкомпьютеры для всех», Открытые системы, № 8, 2007), он рассказал об общих подходах корпорации к HPC и особенностях этого программного продукта.
Нынешней весной была выпущена бета-версия его преемника, Microsoft Windows HPC Server 2008. Имеющиеся в нем средства централизованного управления существенно упрощают управление и повышают производительность труда операторов (рис. 5). Планировщик заданий, входящий в состав Microsoft HPC Pack, в сочетании с High Performance Computing for Windows Communication Foundation (HPC for WCF) и Microsoft Message Passing Interface (MS-MPI) обеспечивают эффективное распараллеливание работ. Интеграция с операционной системой Windows является гарантией безопасности при обращении к системам хранения данных и доступе к ресурсам кластера с рабочих мест. Наличие средств параллельной отладки приложений в Visual Studio 2005 позволяет интегрировать Windows HPC Server 2008 и MS-MPI с Event Tracing for Windows, открывая возможности для консолидации приложений с передаваемыми из вычислительных узлов сообщениями о событиях, происходящих в сети и в операционных системах.
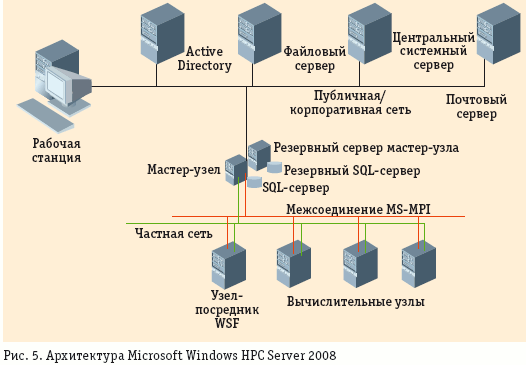
Кластер состоит из одного мастер-узла и множества вычислительных узлов. Мастер-узел контролирует все ресурсы кластера и осуществляет управление потоком работ, он может использовать Active Directory для обеспечения безопасности учета всех выполняемых операций с привлечением такого инструмента, как Microsoft System Center Operations Manager 2007.
Установка Windows HPC Server 2008 на кластер начинается с установки операционной системы на мастер-узел, затем подключается домен Active Directory, далее запускается пакет Compute Cluster Pack. Последний создает список действий To Do List, определяющий последовательность шагов, необходимых для выбора топологии и последующих процедур развертывания и подключения вычислительных узлов в кластер. Упрощение процедур достигается за счет того, что Windows HPC Server 2008 включает готовые «заготовки узлов» (Node Templates), обеспечивающие простой способ задания желаемой конфигурации вычислительных узлов и предоставляющие простой интерфейс к Windows Deployment Services?— средству развертывания кластера в целом или группы его узлов. Работа по развертыванию кластера облегчается тем, что имеется набор диагностических тестов, позволяющих проверить межсоединение узлов, их загрузку, состояние работ, распределенных по всему кластеру.
Для объединения разрозненных узлов в кластер Windows HPC Server 2008 поддерживает пять вариантов топологии (это оказывается возможным благодаря тому, что каждый из узлов может содержать до трех сетевых карт, а процесс создания требуемого варианта поддерживается специальным помощником Network Wizard).
-
Вычислительные узлы изолированы в частную сеть, в таком случае мастер-узел, имеющий две сетевые карты, обеспечивает трансляцию адресов (network address translation, NAT) между вычислительными узлами, каждый из которых по единственной сетевой карте подключен к частной сети.
-
Все узлы подключены и к публичной, и к частной сети, для этого используются по две сетевые карты.
-
Вычислительные узлы изолированы в частной сети и сети передачи по MPI. В таком случае мастер-узел использует три сетевые карты: для подключения к публичной, к частной сети и к сети MPI. Мастер-узел осуществляет NAT между публичной сетью и вычислительными узлами, каждый из которых подключен к частной сети и высокоскоростной сети MPI.
-
Все узлы подключены к публичной и к частной сети, а также к сети MPI. В таком случае в каждом из них используются все три сетевые карты.
-
Все узлы подключены только к публичной сети. Такая ограниченная версия не поддерживается сервисами Windows Deployment Services, при ее выборе операции придется выполнять вручную.
Слово практикам
Недавно корпорация Dell провела семинар, где представила тенденции рынка HPC и свою стратегию в этой области. Выбор в качестве площадки для его проведения НИВЦ МГУ,?— места с глубокими профессиональными традициями, где когда-то стоял один из первых экземпляров легендарной «Стрелы», а теперь работает самый мощный в России кластер,?— обязывает. Наряду с обязательными маркетинговыми выступлениями здесь можно было услышать доклад Пола Каллея, директора вычислительного центра Университета Оксфорда. Он поделился своими наблюдениями о практических аспектах строительства и последующей 18-месячной эксплуатации 566-узлового кластера, собранного на лезвиях Dell с четырехъядерными процессорами Intel Woodcrest.
Чтобы оценить подобный масштаб, приведем некоторые данные о кластере с пиковой производительностью 27 TFLOPS: 150 Тбайт дисковой памяти, 23 стойки, общий вес?— 19 тонн, 2600 кабельных соединений, потребление энергии?— 0,4 МВт.
Вычислительные узлы размещены в 18 стойках, собранных в три группы. Внутри групп эти стойки объединены магистралью, обеспечивающей скорость передачи, равную 40 Гбит/с. Между собой эти группы взаимодействуют через центральный коммутатор по четырем 10-гигабитным магистралям InfiniBandQLogic, узел управления подключен на каналу со скоростью передачи 1 Гбит/с, используются библиотеки InfiniPath MPI, считающиеся лучшими в своем классе. Распределение невычислительных узлов таково: два основных мастер-узла с зеркалированием, девять вспомогательных мастер-узлов, по одному на стойку, четыре узла ввода/вывода, четыре узла для контроля подключений и один?— для мониторинга.
Для сборки кластера пришлось использовать оборудование восьми основных производителей, на сборку ушел один месяц (или 1100 человеко-часов), еще один месяц потребовался на отладку. Бета-тестирование продолжалось четыре месяца.
В течение первого года эксплуатации простой составил 13% (7%?— запланированные и еще 6%?— нет), в первом полугодии второго года?— 5% (соответственно 2 и 3%). Таким образом удалось добиться готовности 95%. Самое важное, как отметил Каллей,?— это планирование и диспетчеризация нагрузки, именно от них зависит коэффициент полезного использования оборудования; при должной квалификации администраторов использование также можно довести до 95%. Интерес представляет распределение задач по требуемым мощностям. Выделяется три пика: 15% задачам нужно от 28 до 36 ядер, 20%?— от 52 до 68, 37%?— от 126 до 140. Задач, которые собой загрузили бы весь кластер, практически нет. Из приведенной статистики нетрудно сделать вывод, что число терафлопов не самоцель и, прежде чем строить системы с рекордными показателями, необходимо оценить их потенциальную загрузку в процессе будущей эксплуатации.
Но достаточно о кластерах. Возвратимся к вопросу, поставленному в статье Дмитрия Арапова,?— «Можно ли превратить сеть в суперкомпьютер?» Сегодня этот вопрос стоит перефразировать так: «Какие сети можно превратить в суперкомпьютер?» Действительно, в настоящий момент есть альтернативы. При построении суперкомпьютера можно переходить на микроуровень или, напротив, на макроуровень, и строить вычислительные сети на кристалле, а также использовать коммуникационные возможности Internet.
RAMP из Беркли
Головной в программе RAMP (Research Accelerator for Multiple Processors) является команда из Университета Беркли, образованная в свое время для строительства сетей рабочих станций NOW. Ее по-прежнему возглавляет Дэвид Паттерсон, один из самых знаменитых профессоров Кремниевой долины. Программа стартовала в 2004 году, а заговорили о ней в феврале 2006 года, когда благодаря Internet была широко растиражирована статья «1000-процессорный компьютер за 100 тыс. долл.?» (Такой компьютер действительно можно построить, более того, он уже построен, правда, с поправкой на то, что число 1000 относится не к числу процессоров, а к количеству процессорных ядер.) Ключевая идея RAMP заключается в переходе от процессоров с количеством ядер, исчисляемых десятками (multicore), к процессорам, где ядра считают сотнями и тысячами (manycore)*. Для создания подобных процессоров сейчас предлагается технология программируемых логических матриц (FPGA).
Но как бы ни называли исследователи свою программу, по сути, это?— Beowulf на кристалле, ярко демонстрирующий тот количественный сдвиг, за которым последовали качественные изменения. Далеко не случайно, что в RAMP соучаствуют крупнейшие американские университеты, его поддерживают все крупные производители процессоров, серверов и, естественно, программируемых массивов. Для них он представляет особый интерес, поскольку, как следует из названия, является исследовательским проектом, в дальнейшем на его основе будут построены коммерческие версии. И опять история повторяется. Так было и с процессорами RISC-архитектуры, разработанными в университетах (Паттерсон был одним из авторов идеи), а внедренными Sun, IBM, HP и другими компаниями.
В проекте RAMP для разработки используются средства программирования Xilinx FPGA и собственный язык разработки RDL (RAMP Description Language). Компьютеры, создаваемые в рамках этого проекта, строятся по иерархическому принципу. Самый нижний уровень представлен ядром MicroBlaze с оптимизированной для использования в FPGA архитектурой, обеспечивающей работу на частоте до 210 МГц. Процессоры располагаются на программируемом массиве Virtex. В зависимости от функциональности, на одном кристалле Virtex-II располагается от одного до 12 ядер MicroBlaze. Следующий уровень иерархии?— устанавливаемые в стойку модули Berkeley Emulation Engine (BEE); в одном модуле может быть от одной до четырех микросхем Virtex-II. В стойку монтируется от одного до 21 BEE. То, как ядра объединяются в массиве, зависит от типа создаваемой машины; это может быть «каждый с каждым» или топология трехмерной сети, общим является то, что канал между ядрами последовательный, а его скорость передачи?— 10 Гбит/с. Приложения пишутся на языке Unified Parallel C (UPC).
 Параллельно разрабатывается три типа компьютеров?— RAMP Red, RAMP Blue (рис. 6) и RAMP White. Каждый из них является экспериментальным, нацеленным на определенную задачу. В частности, на RAMP Red отрабатывается технология транзакционной памяти, на RAMP Blue?— сочетание стандарта MPI с языком UPC, а на RAMP White исследуются проблемы распределенного доступа к памяти.
Параллельно разрабатывается три типа компьютеров?— RAMP Red, RAMP Blue (рис. 6) и RAMP White. Каждый из них является экспериментальным, нацеленным на определенную задачу. В частности, на RAMP Red отрабатывается технология транзакционной памяти, на RAMP Blue?— сочетание стандарта MPI с языком UPC, а на RAMP White исследуются проблемы распределенного доступа к памяти.
Облака плывут, облака
Развитием идей Beowulf стали серверы для поисковых машин. Успех Google объясняется не только эффективностью поисковых алгоритмов, предложенных Сергеем Брином и Ларри Пейджем, но и тем, что для их реализации были выбраны не дорогие серверы, как это было на первых порах, а упрощенные серверы, собранные из стандартных компонентов и ставшие в последующем прототипом поисковых специализированных устройств. Несмотря на идейную близость, вплоть до самого последнего времени суперкомпьютерные кластеры и кластеры, предназначенные для поиска и других Web-сервисов, существовали совершенно независимо друг от друга, это были два непересекающихся мира. В известной статье Джима Грея «Экономика распределенных вычислений» (Distributed Computing Economics) можно найти следующие слова: «Кластеры Beowulf подчиняются собственным закономерностям сетевой экономики… Не следует путать кластеры Beowulf с grid-вычислениями в масштабе Internet».
Но времена меняются. Сказанное в 2003 году перестало быть истиной в 2007-м, когда другой гуру, Эрик Шмидт, генеральный директор Google, ввел в лексикон ИТ-отрасли термин cloud computing («вычисления в облаке» или «облачный компьютинг»). Им он выразил изменения, произошедшие за четыре-пять лет, и точно дополнил девиз «Сеть?— это компьютер», придуманный им же для компании Sun Microsystems на 25 лет раньше. Удачная метафора настолько быстро разошлась, что «вычисления в облаке» стали темой последнего в 2007 году номера совсем уж не профильного журнала BusinessWeek, невольно напомнив 1984-й год, когда «человеком года» The Times назвал персональный компьютер. И определенно в этой связке что-то есть. В том номере центральной была статья Google and the Wisdom of Clouds («Google и мудрость облаков»), а на обложку вынесен портрет одного из программистов компании с подписью Google’s Next Big Thing («Следующая большая вещь Google»).
Возможность сетевых вычислительных сервисов предположил еще в 60-е годы один из пионеров компьютерной отрасли, Джон Маккарти, который писал: «Не исключено, что когда-нибудь вычисления будут организованы как коммунальные услуги (public utility)». Самое же точное предсказание принадлежит Ларри Смарру, физику, который со временем переориентировался на компьютеры и философию и сейчас возглавляет Калифорнийский институт коммуникационных и информационных технологий. Один из его проектов, OptIPuter LambdaGrid, предполагает создание оптической магистрали планетарного масштаба. В 1999 году в журнале Nature была опубликована его статья Computing 2010: from black holes to biology, посвященная приложению компьютеров в исследования от астрофизики до биологии. В ней с большой степенью достоверности описывается то будущее, которое действительно может наступить через несколько лет. Не стоит упускать из виду то, что особое внимание к новой парадигме вычислений объясняется и теми изменениями в умонастроениях, которые выражены и вызываются очередной книгой эпатажного Николаса Карра The Big Switch: Rewiring the World from Edison to Google («Великий перелом: от Эдисона до Google»).
Показательна реакция на появление «облаков» со стороны Яна Фостера, одного из авторов идеи вычислительных grid-сред. Он задается вопросом «а не являются ‘вычисления в облаке’ еще одним названием grid?», и сам же на него отвечает: основное отличие в том, что ‘в облаках’ речь идет не об объединении ресурсов силами самих пользователей, а о приобретении этих ресурсов у профессиональных поставщиков. Этот переход, по мнению Фостера, совершенно закономерен: снижение стоимости вычислений, обеспеченное кластерами из доступных компьютеров, успехи виртуализации и инвестиции Amazon, Google, Microsoft и ряда других компаний привели к тому, что создана новая реальность. Проще купить нужные ресурсы, чем создавать их заново. К недостаткам «облачного» подхода Фостер относит то, что методы, которые используются при его реализации, не являются открытыми: пока все строящиеся облака являются проприетарными.
Заметим, что переход на сервисную модель потребует от поставщиков услуг существенного повышения качества обслуживания. Так, имевшие место перебои в работе сервисов Amazon S3 и Amazon EC2, пока пребывающего в режиме бета-тестирования, вызывали панику. Вопросы обеспечения надежности и готовности необходимо рассматривать по-новому.
Голубое облако
Одним из критериев, по которым можно судить о перспективности новой технологии, является реакция на нее со стороны корпорации IBM. Реакция на «вычисления в облаке» оказалась почти мгновенной: уже в ноябре 2007 была анонсирована программа Blue Cloud. Ее цель состоит в создании среды, в которую объединяются корпоративные центры обработки данных и обеспечивается распределенный доступ к общим ресурсам. Эта среда будет строиться на принципах Open Source и по открытым стандартам.
Примерно 200 специалистов, участвующих в проекте Blue Cloud, собираются использовать технические возможности исследовательского центра IBM Almaden Research Center. Для нужд проекта выбрана операционная система Linux, технологии виртуализации Xen и PowerVM, инструментарий Hadoop для управления параллельным выполнением заданий, а также IBM Tivoli для оптимизации распределения нагрузки на серверы. При создании Blue Cloud используется опыт нескольких предшествующих проектов:
-
Parallel Sysplex?— объединение нескольких мэйнфреймов IBM System z для создания единого образа одной машины;
-
Deep Blue SP Cluster?— предшественник нынешних кластерных решений, наиболее известен по участию в шахматных матчах с Гарри Каспаровым;
-
Blue Gene?— семейство суперкомпьютеров; проектируемая система Blue Gene/Q должна показать производительность в диапазоне 10-30 PFLOPS.
Интенсивная работа с данными и будущее супервычислений
Группа компаний во главе с Google, Yahoo, Amazon и Microsoft развивает новое суперкомпьютерное направление, получившее название Data-Intensive Supercomputing (DISC), то есть «супервычисления, ориентированные на интенсивную работу с данными». В значительной мере оно отождествляется с технологией Google MapReduce, файловой системой Google File System и открытой версией инструментария Hadoop. Появление DISC предсказывалось многими специалистами. Александр Шалай и Джим Грай в статье «Наука в экспоненциальном мире» (Science in an exponential world, Nature, 440, 2006) писали: «В будущем работа с большими объемами данных будет связана с пересылкой вычислений к данным, а не с копированием данных на вашу рабочую станцию».
Новая модель вычислений вызовет к жизни принципиально новые принципы построения суперкомпьютеров. Действительно, современные компьютеры ориентированы на внутренние данные, а их наследники будут работать с внешними данными. Подготовка данных и их поддержание станет функцией системы, а не пользователя, примерно так, как это сейчас делает Google MapReduce.
* Скорее всего, нам придется каким-то образом освоить терминологическое различие между multi и many.?— Прим. автора.
