
kus@free.net
- Общее описание архитектуры S2MP
- Узлы Origin
- Обеспечение когерентности кэша
- Межсоединение
- Подсистема ввода-вывода
- Заключение
- Литература
Вопросы масштабирования вычислительных систем уже давно находятся в поле зрения потребителей, равно как и компаний, производящих компьютеры. Какую мало-мальски серьезную многопроцессорную систему ни возьми - всегда можно прочесть в каком-нибудь рекламном проспекте, что она обеспечивает высокое качество масштабирования. А между тем, по большому счету, это почти всегда не так. Например, все SMP-серверы "по определению" имеют ограничения на масштабируемость, вызванные ограниченной пропускной способностью системной шины и предельным числом ее слотов. Стремительно набирающая сегодня популярность архитектура cc-NUMA является, в частности, одним из путей улучшения масштабируемости по сравнению с традиционным SMP-подходом. Но даже системы с массовым параллелизмом (МРР) - и те часто имеют серьезные ограничения масштабируемости. Проанализируем в этой статье особенности действительно свободной от многих ограничений масштабируемости архитектуры S2MP (Scalable Shared Memory MultiProcessing), предложенной компанией SGI.
Для того чтобы понять возможные ограничения масштабируемости, присущие той или иной архитектуре, прежде всего следует уточнить, что имеется в виду под этим понятием. Масштабируемость включает в себя возможности наращивания конфигурации и производительности компьютера по всем основным параметрам: числу процессоров, емкости оперативной памяти (ОП) и ее пропускной способности (ПС), конфигурации внешних устройств (от НЖМД до сетевых контроллеров) и ПС подсистемы ввода-вывода и т. д. Масштабируемость включает в себя, в частности, и увеличение ПС сетевого соединения при росте числа узлов в МРР-системах.
Построение кластерных конфигураций из SMP-компьютеров, как правило, не дает хороших показателей масштабирования; обычно ограничиваются небольшим числом компьютеров в кластере. Более масштабируемые кластероподобные системы можно строить с применением архитектуры Tandem ServerNet [1, 2].
Перспективное направление развития МРР-систем с архитектурой сс-NUMA было предложено Convex - ныне подразделением Hewlett Packard, выпустившем многопроцессорные компьютеры Exemplar SPP1000 [3], SPP1200 [4], SPP1600 и, наконец, серверы S и X-класса (SPP2000) [5,6]. Все эти системы имеют определенное ограничение масштабируемости из-за применения связывающих гиперузлы магистралей CTI с фиксированной пропускной способностью. Сегодня архитектура S2MP свободна от подобного ограничения масштабируемости. В нашем анализе мы ограничимся наиболее принципиальными и интересными особенностями S2MP. С тонкостями реализации архитектуры S2MP в компьютерах SGI Origin и Onyx2 и дополнительными техническими деталями можно ознакомиться в работах [7-9].
Общее описание архитектуры S2MP
Известно, что суперкомпьютеры традиционной векторно-конвейерной архитектуры действительно сильно опережают многопроцессорные системы на базе высокопроизводительных RISC-микропроцессоров главным образом по одному параметру - производительности подсистемы ОП [10]. При разработке S2MP компания SGI поставила в качестве основной цели создание высокомодульных масштабируемых систем, имеющих высокую ПС.
На рисунке1 представлена общая структура построения S2MP из узлов и маршрутизаторов. Применение маршрутизаторов, а фактически сети, для соединения процессорных узлов (в дальнейшем - просто узлов) роднит S2MP с архитектурой ServerNet [1,2]. Узлы включают в себя не только процессоры, но и ОП и интерфейсы к системе ввода-вывода.
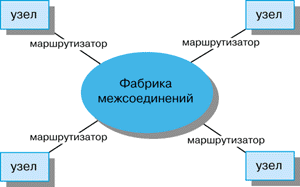
Рисунок 1.
Общая структура S2MP.
"Фабрика" межсоединений (Interconnect Fabric, IF), называемая также CrayLink Interconnect, связывает узлы друг с другом. Следует обратить внимание на некоторые особенности IF по сравнению с обычной шиной. Во-первых, IF позволяет многим процессорам одновременно "соединяться" с другими узлами, в то время как ресурсы шины SMP-компьютера в любой момент может использовать только один процессор (ЦП). Во-вторых, системная шина работает обычно в полудуплексном режиме, в то время как все "пути" в IF являются дуплексными. Вместе с тем, как и в базирующихся на шине SMP-системах, ОП и порты ввода-вывода в S2MP являются глобально адресуемыми, общими для всех узлов.
Узлы Origin
Основным строительным блоком в архитектуре S2MP является узел. Для конкретности возьмем компьютеры Origin 2000 - в них узлы реализованы в виде отдельных плат (рисунок 2), каждая из которых содержит 1 или 2 64-разрядных ЦП R10000 [11-13]. Сегодня возможны конфигурации Origin 2000 на базе 180 МГц чипов R10000 со вторичным кэшем емкостью 1 Мбайт или 195 МГц чипов R10000 со вторичным кэшем емкостью 4 Мбайт.
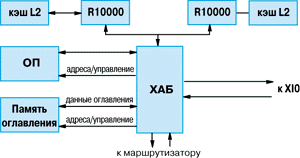
Рисунок 2.
Строение узла S2MP.
Центральная часть каждого узла - это хаб. Он представляет собой полузаказную микросхему-коммутатор (crossbar switch) c 4 двунаправленными портами, имеющими пиковую ПС 780 Мбайт/с для 195 МГц - версии R10000 (или 720 Мбайт/с - для 180 МГц чипа R10000) в каждом направлении, или 1,56 Гбайт/с на порт (Таблица 1). Эти 4 порта связывают хаб с процессорами, ОП, подсистемой ввода-вывода и маршрутизатором. Таким образом, хаб не только объединяет воедино все блоки узла - через него осуществляется также взаимодействие с другими узлами (через маршрутизатор и IF). Хаб преобразует внутренние сообщения, использующие формат "запрос/ответ", в формат внешних сообщений, который используется для портов XIO и CrayLink Interconnect (к маршрутизатору); инициатором внутренних сообщений выступают ЦП и внешние устройства (ВУ). Внутри самого хаба используется собственный формат сообщений.
Таблица 1.
Пропускная способность портов хаба (за 1 сек).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ОП в узлах использует SDRAM-технологию и модули DIMM. Каждая плата узла имеет 8 банков ОП, а каждый банк имеет 2 позиции для модулей DIMM для ОП и 1 позицию - для модулей оглавления, используемого для поддержания когерентности кэша. На плате можно смешивать DIMM разного размера, но не в пределах одного банка. Сейчас применяется 16 Мбит-технология, при этом емкость DIMM может быть 32 или 64 Мбайт, а максимальная емкость ОП узла - соответственно 512 или 1024 Мбайт. Переход в будущем к 64 Мбит-технологии позволит применять модули DIMM емкостью 256 Мбайт, и максимальный размер ОП узла увеличится до 4 Гбайт. Каждый банк ОП имеет 4-кратное расслоение, и добавление нового банка увеличивает степень расслоения на 4. Однако высокопроизводительная технология SDRAM обеспечивает достижение полной ПС для ОП узла уже одним банком.
Обеспечение когерентности кэша
Пересылка данных в кэш, уменьшающая задержку при обращении к ОП, одновременно осложняет поддержку когерентности кэша разных процессоров: соответствующая копия в кэше может рассогласоваться с данными, расположенными в другом месте. Рассмотрим подробнее ситуацию на примере [7] (рисунок 3а).
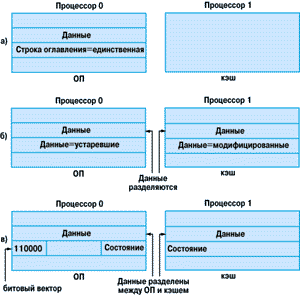
Рисунок 3.
Когерентность кэша.
Пусть в кэш ЦП 0 загружен блок данных. Поскольку имеется только один экземпляр этих данных на всю систему, то состояние когерентности этих данных называют "единственное" (exclusive) (рисунок 3а). В соответствующей строке оглавления, описывающей этот блок данных, вводится бит "единственные". Когда эти данные потребуются ЦП 1, он создаст их копию, которую загрузит в свой кэш. Тогда в системе будет два экземпляра этих данных - информация в ЦП 0 более не является единственной. Поэтому, когда делается копия, в соответствующей строке оглавления будет установлен бит "разделяемые", говорящий о том, что где-то в системе имеется копия данного блока. Где именно находится копия, отмечается битовым вектором, расположенным в той же строке оглавления. Этот вектор указывает, в каких узлах расположена разделяемая копия (рисунок 3б).
Процессор 1 может изменить эти данные; тогда они помечаются как "модифицированные" (SGI использует термин "dirty" - грязные) и готовятся к записи в кэш. Но выполнить эту запись так просто нельзя: тогда в системе образуются две разные версии данных - одна новая (в кэше ЦП 1) и одна немодифицированная, "устаревшая" (stale) - в ОП и в кэше ЦП 0. Следовательно, "устаревшие" данные должны быть согласованы с новой версией в кэше ЦП 1.
Для достижения согласованности между версиями данных используется два протокола поддержания когерентности: основанный на отслеживании (snoopy) и основанный на применении оглавления. Первый обычно встречается в SMP-системах, например в SGI Power Challenge [13]. При этом часто используется стандартный протокол MESI [14]. В S2MP-архитектуре, напротив, применяется протокол, основанный на оглавлении [7], в котором каждому блоку памяти ставится в соответствие строка в оглавлении. Она указывает на состояние блока памяти в системе, и содержит битовый вектор, содержащий информацию о том, в каких кэшах системы находятся копии этого блока (рисунок 3в). В протоколе, основанном на отслеживании, ЦП оповещают всех (broadcast) при обращении к памяти, что приводит к заметному трафику, например, на системной шине SMP-серверов. Использование протокола, основанного на оглавлении, имеет то преимущество, что о доступе к памяти извещаются только те кэши, которые содержат ту же копию блока памяти. Это позволяет уменьшить трафик протокола обеспечения когерентности кэша и тем самым улучшить масштабируемость ПС IF.
В реализованной для S2MP версии протокола поддержания когерентности, основанного на оглавлении, используется метод установки "недостоверности" (invalidate). Установка "недостоверности" приводит к стиранию всех копий модифицированной строки кэша во всех других кэшах, содержащих эту строку. Для установки "недостоверности" в тэге строки кэша вводится бит "недостоверно". Когда выполняется установка недостоверности, записавший в кэш ЦП становится единственным владельцем блока памяти, что позволяет ему производить повторную запись в эту строку кэша, не извещая об этом другие кэши. Это также уменьшает трафик.
Описание состояний оглавления, позволяющих реализовать вышеописанный механизм, дано в [7]. Стоит отметить только, что архитектура S2MP поддерживает возможность перераспределения данных (страниц) в ОП путем их пересылки из удаленной в локальную ОП данного узла. Для такой страницы, мигрирующей к другому узлу, в оглавление вводится специальный бит состояния. Этот механизм является альтернативным используемому в Convex Exemplar SPP кэшу CTI для гиперузлов [3-6] и также направлен на повышение локализуемости обращений к ОП. Миграцию страниц в серверах Origin поддерживает 64-разрядная операционная система Irix 6.4.
Межсоединение
Транспортной артерией, соединяющей все узлы между собой, является межсоединение - IF. Использование программируемых маршрутизаторов позволяет строить системы с различной топологией, но стандартной является топология гиперкуба. Системы Origin 2000 могут масштабироваться до 512 узлов. IF обеспечивает много одновременных соединений типа точка-точка, каждое из которых имеет поддерживаемую ПС на уровне системной шины PowerPath-2 SMP-серверов Power Challenge [13,15]. IF не требует арбитража, необходимого при использовании системной шины, а ПС IF возрастает с увеличением числа узлов. Половинная (bisection) ПС, как пиковая, так и поддерживаемая, также линейно растет с числом узлов. Для восьми ЦП эти величины составляют 1,25 и 1,56 Гбайт соответственно, а при 128 ЦП - 20 и 25 Гбайт/с. При использовании экспресс-соединений (или звездных маршрутизаторов) соответствующая ПС возрастает вдвое.
Специальные меры приняты для обеспечения надежности работы IF: она поддерживает не менее двух путей к любой паре узлов; в каждом соединении используются коды CRC, а протокол канального уровня обеспечивает надежную передачу, в частности, путем повтора при сбоях передачи.
Хаб, расположенный на плате узла, связывается с IF через платы маршрутизаторов М (рисунок 4), которые монтируются в слоты midplane - платы, расположенной в середине модуля Origin 2000 (модуль может содержать до 4 узлов). Основной элемент плат М - это 6-портовая полузаказная микросхема маршрутизатора, представляющая собой неблокирующийся коммутатор (crossbar switch). Каждый порт М представляет собой пару 16-разрядных однонаправленных каналов (links), имеющих пиковую ПС 780 Мбайт/с в одном направлении. Соответственно общая ПС маршрутизатора составляет 9,36 Гбайт/с. В маршрутизаторах используются статические таблицы маршрутизации.
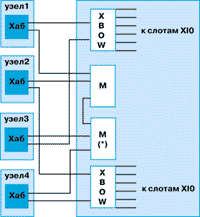
Рисунок 4.
Соединение узлов в модуле Origin 2000. Звездочкой помечен звездный маршрутизатор.
Три внутренних порта М предназначены для быстрой передачи данных между полузаказными микросхемами внутри модуля и используют однопроводную (single-ended) технологию STL (SGI Transistor Logic) со временем цикла всего 2,5 нс. Три внешних порта М используют более устойчивую по отношению к шумам дифференциальную технологию PECL; к этим портам подсоединяются кабели для связи модулей между собой.
Имеется четыре типа плат М. Нулевой маршрутизатор связывает 2 узла (2 хаба) напрямую через порты CrayLink и может применяться в системах, содержащих до 4 ЦП. Также имеющий низкие задержки звездный маршрутизатор связывает до 4 плат узлов; системы, имеющие 3 или 4 узла, используют один звездный маршрутизатор и один стандартный маршрутизатор (рисунок 4). Через стандартные (стоечные) маршрутизаторы связываются кабелями системы, имеющие до 32 узлов. Метамаршрутизаторы применяются в системах из 33 и более узлов.
В таблице 2 приведены величины задержек при обращении ЦП (200 МГц R10000) к удаленной ОП для разных конфигураций. Эти данные предоставлены Дж. Мэшеем (J.R. Mashey) из компании SGI. Вторая строка в таблице соответствует применению нулевого маршрутизатора, третья - звездного. По данным автора тестов STREAM Дж. Мак-Калпина (SGI), c точки зрения величины задержек системы Origin пока опережают другие компьютеры с архитектурой cc-NUMA; при числе процессоров до 16 Origin в 1,3-2 раза уступают лучшим реализациям SMP-архитектуры, но при большем числе процессоров задержки оказываются в 3 раза ниже, чем у альтернативных архитектур. Более того, системы даже из 128 ЦП имеют более низкую среднюю величину задержки, чем в серверах SGI Power Challenge.
Таблица 2.
Задержки при обращении к ОП (нс).
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Итак, с точки зрения задержек архитектура S2MP оказывается лучшей при больших конфигурациях систем, хотя эта характеристика теоретически является самым слабым местом. Что же касается ПС ОП, то, по данным тестов STREAM, компьютер Origin опережает другие системы, хотя и уступает векторно-конвейерным суперкомпьютерам (таблица 3). Для путей к удаленной ОП, содержащих 3 маршрутизатора, ПС составляет 75% от локальной, а при использовании команды предварительной выборки в кэш - даже 88% от ПС локальной ОП.
Таблица 3.
Пропускная способность ОП (Мбайт/с) на тестах STREAM.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Производительность Origin 2000 на тестах Linpack при N=1000 приведена в таблице 4.
Таблица 4.
Производительность на тестах Linpack при N=1000 (в MFLOPS).
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- Примечания.
-
(*) Через слэш в обозначениях микропроцессоров дан размер внешнего кэша. Тактовая частота R10000 равна 195 МГц, R8000 - 90 МГц.
(**) После слэша приведена производительность с 440 МГц Alpha 21164.
Подсистема ввода-вывода
Как видно из рисунка 2, каждый узел имеет один порт интерфейса XIO, используемого для соединения с ВУ. Полузаказная микросхема коммутатора (crossbar switch), называемая crossbow (сокращенно-XBOW), используется для расширения одного XIO-порта до 8, из которых шесть применяются для связи с ВУ, а два - подсоединяются к узлам (рисунок 4). Midplane в модуле Origin2000 имеет 2 микросхемы XBOW. Отметим, что с точки зрения электрических сигналов XIO-интерфейс подобен CrayLink Interconnect, хотя в XIO-интерфейсе используется другой протокол, более подходящий для организации ввода-вывода. Все порты XBOW являются 16-разрядными, но могут быть запрограммированы на работу как в 16-разрядном, так и в 8-разрядном режиме.
Шести портам XBOW, отвечающим за связь с ВУ, соответствуют 6 XIO-слотов на midplane. В эти слоты вставляются XIO-платы различного типа, которые отвечают за интерфейс с другими протоколами и шинами ввода-вывода: PCI-64 (с пиковой ПС 266 Мбайт/с), Ultra SCSI, Fibre Channel - Arbitrated Loop, ATM (OC3, 155 Мбит/с), Ethernet 10/100 BaseTX, HiPPI и др. Всегда присутствующая базовая XIO-плата содержит, в частности, два последовательных порта, Ethernet 10/100 BaseTX, один внутренний 16-разрядный интерфейс UltraSCSI и один такой же внешний интерфейс, флэш-PROM, NVRAM и часы. Другие XIO-платы являются специализированными: UltraSCSI (дает 4 дифференциальных 16-разрядных канала с ПС, равной 40 Мбайт/с у каждого), Fibre Channel (поддерживает 2 канала с ПС, равной 100 Мбайт/с у каждого), PCI (предоставляющая 3 слота шины PCI-64) и т. д. Дополнительную информацию о XIO-платах и возможных конфигурациях ВУ в серверах Origin можно найти в [7,8].
Заключение
В статье были рассмотрены особенности архитектуры S2MP, реализованной в компьютерах SGI Origin и Onyx2. Целый ряд характерных черт этой архитектуры отражает некоторые складывающиеся на сегодня общие тенденции развития архитектур суперкомпьютеров, в частности:
1) Закат векторно-конвейерной архитектуры суперкомпьютеров [10]. Крупнейшие производители таких систем в США уже свернули их производство (например Convex Corp.) или неявно планируют это сделать (Cray Research, вошедшая в состав SGI, намерена перейти в будущем к единой общей с SGI аппаратно-программной платформе, что, вероятно, означает появление MPP-системы на базе КМОП-микропроцессоров MIPS Rxxxxx).
2) Выход на первые позиции, в том числе по производительности, МРР-систем на базе стандартных высокопроизводительных КМОП-микропроцессоров RISC-архитектуры - тех же, что используются в рабочих станциях и серверах.
3) Применение систем с физически распределенной, но логически разделяемой ОП (в частности, архитектуры сс-NUMA) - это часть общей тенденции использовать логически общую ОП. Другой путь от SMP к МРР - кластеризация SMP-систем (примеры - кластеры из DEC AlphaServer 8400 и будущие кластеры IBM SP2 на базе SMP-узлов) - менее эффективен.
4) Отказ в "SMP-частях" современных МРР-систем, равно как и в самих SMP-компьютерах, от применения системной шины в пользу коммутатора. Примеры: серверы SUN Ultra Enterprise; серверы S-класса от HP; ориентация на коммутатор будущей микросхемы DEC Alpha 21264 и т. д.
5) Ориентация на стандарт шины ввода-вывода PCI. Примеры: SGI Origin2000, DEC AlphaServer 8400, серверы S- и Х-классов от HP.
6) Ориентация на применение обычных ВУ современных индустриальных стандартов UltraSCSI, Fibre Channel и отказ от специальных ВУ собственной разработки, что было характерно ранее для суперкомпьютеров Cray Research, а также мэйнфреймов.
7) Переход на использование в ОП-технологии SDRAM. Примеры: SGI Origin, серверы S- и X-класса от HP.
В архитектуре S2MP отражены все эти общие тенденции. Основной задачей компании SGI становится, вероятно, скорейший выпуск новой, более высокопроизводительной версии микропроцессора R10000, поскольку на сегодня он отстает по ряду тестов от HP PA-8000 и DEC Alpha 21164. Здесь важным является также решение проблемы модернизации существующих серверов Origin при переходе к будущим версиям R10000. Дело в том, что в SMP-серверах SGI Challenge/Power Challenge можно было использовать в одной системе микропроцессоры с разной тактовой частотой, что создает прекрасные возможности модернизации компьютера. В системах DEC AlphaServer такой возможности нет; там для модернизации нужно производить замену микропроцессорных плат с тем, чтобы все процессоры были одинаковыми и работали на одной тактовой частоте. В основанных на коммутаторе системах Exemplar SPP фирмы HP, как и в серверах S-класса, такую замену просто нельзя произвести - нужно менять и сам коммутатор. Сходные проблемы имеют также использующие коммутаторы Origin 2000 или Onyx2. Здесь проблема связана с CrayLink-соединениями, рабочая частота которых должна быть строго кратна частоте микропроцессоров R10000.
В заключение следует сказать, что S2MP можно, вероятно, рассматривать как наиболее продвинутую на сегодня архитектуру МРР-систем. Не случайно с развитием этой архитектуры связаны планы создания наиболее мощного в мире суперкомпьютера для Лос-Аламосской лаборатории в США. Эта система с 3072 ЦП должна, как известно, превзойти уровень производительности 3 TFLOPS. Рыночный успех суперкомпьютерных систем с архитектурой S2MP в ближайшее время будет во многом определяться успехами SGI в выпуске новых, еще более высокопроизводительных микропроцессоров R10000.
Литература
[1] М. Кузьминский, Computerworld/Россия, # 10, 1995.
[2] В.Шнитман, Открытые системы, # 3, 1996, c. 15 http://www.osp.ru/os/1996/03/5.htm
[3] М. Кузьминский, Открытые системы сегодня, # 7, 1995.
[4] В. Шнитман, Открытые системы, # 6, 1995, c. 42.
[5] В.Коваленко, Открытые системы, # 1, 1997, c. 5. http://www.osp.ru/os/1997/01/5.htm
[6] М. Кузьминский, Computerworld/Россия, # 2, 1997. http://www.osp.ru/cw/1997/02/34.htm
[7] Origin200 and Origin2000. Technical Report, SGI, 1996.
[8] М. Кузьминский, Computerworld/Россия, # 4, 1997. http://www.osp.ru/cw/1997/04/31.htm
[9] В. Коваленко, Открытые системы, # 1, 1997, c. 73. http://www.osp.ru/os/1997/01/73.htm
[10] М. Кузьминский, Д.Волков, Открытые системы, # 6, 1995, c. 33.
[11] В. Аваков, Открытые системы, # 6, 1995, с. 62.
[12] М. Кузьминский, Открытые системы сегодня, # 8, 1995.
[13] Power Challenge. Technical Report, SGI, 1996.
[14] В. Шнитман, Открытые системы, # 4, 1996, c. 11. http://www.osp.ru/os/1996/04/11.htm
[15] М. Кузьминский, Computerworld/Россия, # 12, 1995.
