
Двадцать лет назад компьютерное сообщество живо обсуждало альтернативу двух режимов эксплуатации вычислительных систем - интерактивного доступа и пакетной обработки заданий. Появление ПК склонило мнение в сторону первого варианта и графический интерфейс пользователя стал непременным компонентом всех современных вычислительных систем. Однако и пакетная обработка сохранилась в своей естественной нише - области интенсивных вычислений с характерными временами счета, измеряемыми в часах и сутках.
Эта область ассоциируется, в первую очередь, с суперкомпьютерами и Unix-системами, однако их базовые средства работают в рамках отдельной машины . С другой стороны, высокопроизводительные вычислительные системы могут быть построены из серийно выпускаемых компонентов путем их объединения сетевыми технологиями. Организация вычислений в такой распределенной среде компьютеров - это задача систем управления пакетной обработки (СУПО), расширяющих возможности локальных ОС. Данная работа посвящена анализу альтернативных подходов построения систем распределенной пакетной обработки.
В литературе для рассматриваемого класса систем применяются различные термины: Cluster Management Software (CMS), Batch System (BS), Resource Management System (RMS). Мы будем использовать название Система Управления Пакетной Обработкой, как наиболее близкое стандарту POSIX 1003.2d. На сегодняшний день известно более 20 различных коммерческих и свободно распространяемых систем из класса СУПО. Имеется ряд обзоров [1-3] и аналитических материалов [4-6], в которых сформулированы критерии их сравнения. Существует также стандарт POSIX 1003.2d - расширение для систем пакетной обработки (Batch Environment Standard). Однако в стандарте только специфицируется, а в обзорах лишь оценивается наличие/отсутствие тех или иных характеристик. Опыт работы с системами PBS [7], DQS [8], а также анализ систем NQS [9] и Condor [10] показали, что в рамках одних и тех же спецификаций принципы реализации аналогичных механизмов различны, и это существенно сказывается на функциональных возможностях.
Современные СУПО способны управлять различными комплексами: многопроцессорными системами SMP и MPP, кластерами на специализированных коммутаторах, конгломератом рабочих станций и серверов, соединенных стандартными сетевыми протоколами, и любой смесью указанных конфигураций. До сих пор гетерогенность всех систем была ограничена различными диалектами Unix, включая Linux для платформы Intel, но недавно произошло знаковое событие - появилась первая версия СУПО, которая поддерживает платформу NT - это версия 6.1 системы Condor. Это важно, по крайней мере, по двум причинам. Во-первых, пользователи NT получили средство для пакетного счета задач давно известное в ОС Unix. Во-вторых, в России относительно мало действительно мощных вычислителей - даже рабочих RISC-станций, не говоря уже о суперкомпьютерах, а ПК - много. Condor позволяет построить из них интегрированный вычислительный комплекс, ориентированный на специальный режим - высокой пропускной способности (High Throughput Computing - HTC).
С другой стороны, в условиях локальной сети пользователь и без СУПО может работать на всех Unix-компьютерах- для этого имеются, например, протоколы удаленного входа Telnet, удаленного запуска (Rexec), пересылки файлов (FTP, Rcopy) и т.д. Подход СУПО - это шаг к представлению отдельных компьютерных установок в виде единой вычислительной среды. Представим себе, как происходит работа в локальной сети с большим числом «общедоступных» компьютеров. Если пользоваться только штатными средствами ОС, то нужно будет найти в сети свободные машины, переслать на них исполняемые файлы, файлы данных, произвести запуск и сделать то же самое с файлами результатов в обратном направлении. Проблема даже не в том, что это скучная и рутинная работа, а в том, что организовать этот процесс административными способами даже при небольшом числе пользователей и вычислительных узлов практически невозможно.
Основные понятия СУПО
Базовый объект СУПО - пакетное задание (batch job), которое может выполняться без вмешательства пользователя и, следовательно, не требовать интерактивного входа в систему. Форма представления пакетного задания - скрипт командной оболочки Shell, который может включать команды для создания рабочей среды, компиляции, сборки программы и запуска ее на выполнение.
Система пакетной обработки принимает задания, вводимые пользователями с распределенных рабочих мест и буферизует их в общем спуле ожидания (рис. 1). Отдельный процесс - диспетчеризация, выбирает из спула задания, находит для каждого подходящие исполнительные узлы, пересылает на них задание и запускает его. Диспетчеризация происходит периодически, и за один цикл не обязательно все задания из спула будут запущены - для некоторых может не найтись подходящих узлов.
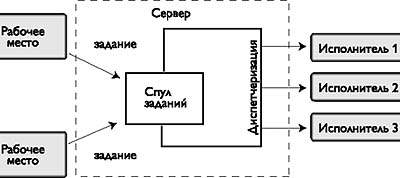 |
| Рис. 1. Схема функционирования СУПО |
Наиболее существенные различия между СУПО заключены в механизмах диспетчеризации - управлении потоком заданий. Что же касается уровня обслуживания отдельных заданий, то здесь наблюдается более однородная картина. Задача СУПО - обеспечить надежную, контролируемую обработку задания в распределенной среде, включающей: машину (рабочее место) пользователя, с которой вводится задание; один или несколько исполнительных узлов, на котором задание обрабатывается; узел, содержащий файлы данных для задания; буферизующие и управляющие узлы самой СУПО.
В общем случае обработка заданий в распределенной среде предусматривает выполнение следующих функций:
- централизованное управление заданиями;
- пост/пре доставка файлов на исполнительный узел;
- пересылка стандартных файлов на машину, с которой произведен запуск задания;
- мониторинг задания;
- установка зависимостей между заданиями;
- автоматическое восстановление задания после сбоя СУПО или исполнительного узла (рестарт, контрольные точки);
- гарантированное выделение ресурсов, требующихся заданию при исполнении, и контроль за лимитами ресурсов;
Централизованное управление заданиями
Обычно, работая в локальной сети пользователь должен иметь информацию об адресах компьютеров, именах и паролях для регистрации на них. При работе в среде СУПО нужно думать о ресурсах, необходимых заданию: число процессоров, их быстродействие, объем памяти и пр.
Взаимодействие с системой обработки происходит через один из распределенных компонентов СУПО - пользовательский интерфейс рабочих мест, в состав которого обычно входят команды ввода заданий (Qsub) и управления заданиями: снятие (Qdel), задержка/освобождение (Qhold/Qrls), модификация (Qalter), получение информации о текущем состоянии (Qstat). Нетрудно заметить, что большинству команд найдутся аналоги среди инструкций ОС, а команды Qhold/Qrls дают возможность пользователю вручную вмешиваться в ход обработки своих заданий. Более всего отличается от привычного команда Qsub - именно она в полной мере представляет функциональность СУПО. Команда имеет множество опций:
qsub <скрипт>
[<управление>
<заказ ресурсов>
<зависимость заданий>
<уведомления>
<доставка файлов>] (1)
Семантика qsub заключается в том, что СУПО выбирает подходящий исполнительный узел, пересылает на него файл <скрипт> из локальной файловой системы, в которой выдается Qsub и осуществляет запуск скрипта.
От момента ввода командой Qsub до начала выполнения задание проходит ряд этапов обработки (о них, в частности, информирует команда Qstat). Обрабатывая опции, СУПО строит паспорт задания, упаковывая в него скрипт и различные атрибуты (например, адрес узла, с которого запущено задание). На всех последующих этапах паспорт служит полноценным описателем задания и передается всем распределенным компонентам СУПО. Далее задание помещается в централизованный спул и ждет диспетчеризации. Следует подчеркнуть, что спул - это постоянная память и как только задание попало в него, гарантируется, что задание никуда не исчезнет даже при сбое или выключении сервера и когда-нибудь будет запущено на выполнение.
В основном режиме Qsub не ждет запуска задания - пользователю сообщается идентификатор и тут же происходит возврат управления. Остальные команды репертуара ссылаются на этот идентификатор и позволяют управлять заданием независимо от его состояния (ожидание в очереди/выполнение) и исполнительного узла, где оно запущено. В дополнение к основному поддерживается интерактивный режим выполнения заданий, когда Qsub завершается не сразу, а блокирует терминал запуска до тех пор, пока задание не начнет выполняться и не будет выполнен скрипт. После этого терминал пользователя оказывается связанным с командной оболочкой, выполняющейся на исполнительном узле, и со стандартными потоками stdin, stdout, stderr, так что можно выполнить любую последовательность команд интерактивно. Этот режим унаследован от самых ранних СУПО, которые ограничивались поиском свободных исполнительных узлов, однако он может быть полезен, например, при отладке.
Порядок выполнения заданий в СУПО определяется автоматически и вовсе не всегда совпадает с порядком их ввода. Если запускается несколько заданий и они зависимы, порядок между ними можно задать принудительно:
depend = <список зависимостей> <список зависимостей> = <тип зависимости> : <идентификатор задания> [: <идентификатор задания>...]
Эта конструкция означает, что запускаемое задание зависит от заданий с указанными номерами, а <типы зависимости> могут быть, например, следующими:
syncswitch - одновременный запуск нескольких заданий;
after - задание запускается после зависимых;
afterok (afternotok, afterany) - задание запускается после успешного окончания;
before - задание запускается после зависимого.
После отработки команды Qsub терминал пользователя немедленно освобождается, а что будет со стандартными файлами, куда выводят информацию утилиты ОС и компиляторы, которые могут использоваться в задании? Во всех вариантах запуска потоки stdout, stderr буферизуются на исполнительном узле. Если в команде нет опции <доставка файлов>, то по завершении задания стандартные файлы пересылаются на машину пользователя, с которой была выдана команда Qsub, в текущий на момент ввода задания каталог. С помощью опций -o, -e можно указать полную квалификацию доставки файла, включающую хост и каталог, - это второй вариант. И, наконец, третий вариант - файлы можно оставить на исполнительном хосте. В первых двух вариантах доставка файлов производится штатными средствами удаленного копирования ОС - утилитой RCP. Как известно, протокол RCP основан на доверительных отношениях между машинами и его использование в СУПО - один из пунктов, ограничивающих применимость СУПО локальными сетями.
Отметим также, что во время выполнения задания стандартные файлы недоступны для пользователя в рамках средств СУПО, хотя это и может быть полезно. Способы организации оперативного доступа к стандартным файлам известны, но в распространенных СУПО не реализованы.
Выполнение заданий в распределенной среде делает актуальным вопрос доступа не только к стандартным, но и к любым другим файлам пользователя, которые обрабатываются в задании, например, файлы могут лежать на пользовательской машине, а задание будет запущено совсем на другой. Собственный механизм СУПО - предварительная закачка/выкачка файлов на/с исполнительного узла. Для этого в Qsub есть два параметра: stagein <список файлов> и stageout <список файлов>, в которых задается копирование полностью квалифицированных (локальное имя, имя хоста) файлов до (stagein) начала выполнения задания и после (stageout) его окончания.
Несмотря на наличие в СУПО встроенных механизмов копирования более интересным представляется развертывание той или иной распределенной файловой системы (мы используем NFS). При надлежащем конфигурировании такое решение образует единое файловое пространство и обеспечивает прозрачный (не требующий изменений программ) доступ к файлам независимо от места выполнения задания.
Поддержка выполнения заданий
После того, как задание выбрано в результате диспетчеризации, оно переправляется на один или на несколько исполнительных узлов и запускается на выполнение.
В соответствии с заказом ресурсов в команде Qsub, устанавливаются лимиты (с помощью системной функции типа setrlimit) на потребление процессами задания системных ресурсов исполнительного узла. Далее контроль за превышением лимитов осуществляет уже сама ОС, выдавая сигналы, например, если задание считается дольше заказанного времени. Точный мониторинг потребления ресурсов, поддержанный на уровне ОС, не только уменьшает непроизводительные издержки на прогоны программ с ошибками, но и делает осмысленным планирование порядка обработки, приводя в согласие параметры планирования и реальный ход дел.
Механизм автоматического рестарта повышает надежность этапа счета задания. Паспорта заданий хранятся в спулах на дисках исполнительных узлов, поэтому при любых аппаратных или системных сбоях (или просто при перезагрузке ОС) имеется возможность перезапустить те задания, которые в момент сбоя считались в рамках СУПО. Например, в PBS после того как исполнительный узел перезагружен, его задания возвращаются в общий спул, проходят диспетчеризацию и запускаются на выполнение, но при этом могут оказаться на другом узле.
Применяются два вида рестарта. На некоторых вычислительных платформах (например, на SGI Origin) ОС поддерживает создание контрольных точек и рестарт производится с последней из них. Во втором варианте предполагается, что сами программы периодически выводят рассчитанные данные в файл (как правило, вычислительные задачи работают именно таким образом), и тогда автоматический рестарт заключается просто в повторном запуске задания.
Рестарт находит применение и в особом виде балансировки загрузки узлов - миграции заданий. Если создаются условия, когда продолжение задания на данном исполнительном узле нежелательно (превышен уровень оптимальной загрузки, узел занят интерактивным пользователем), то выполнение прерывается, задание возвращается в очередь, производится диспетчеризация и задание перезапускается на другом узле. Миграция - один из «коньков» системы Condor, поскольку она расчитана на применение в среде компьютеров, неотчуждаемых от их владельцев.
Архитектура СУПО
СУПО содержат программные компоненты четырех типов: пользовательский интерфейс; управляющий сервер; планировщик; исполнительный демон. В процессе развертывания системы все эти компоненты устанавливаются на разные узлы и в общем случае могут присутствовать во множестве экземпляров. В частности, на каком-либо узле могут быть установлены все четыре компонента или любая их комбинация. Пользовательский интерфейс ставится на те узлы, которые будут использоваться как рабочие места, т. е. будут служить для ввода заданий и управления ими. Управляющих серверов может быть несколько - в этом случае то, на какой из серверов направляется задание указывается в команде Qsub. Сервер принимает паспорт задания от пользовательского интерфейса, хранит спул паспортов и предоставляет его планировщику: процесс диспетчеризации происходит в виде взаимодействия этих двух компонентов. Исполнительные демоны устанавливаются на те узлы, на которых выполняются задания.
Гетерогенность - важное свойство СУПО, которые могут работать на комплексах, составленных из машин разных производителей с разными вариантами и версиями ОС Unix, а после появления Condor 6.1 и с NT. Свободно распространяемые системы (PBS и DQS) поставляются в исходных кодах и инсталлируются на каждый узел путем условной генерации в соответствии с платформой узла.
Весь информационный обмен между гетерогенными компонентами распределенной системы происходит по сети. Межпроцессное взаимодействие строится на программном интерфейсе сокетов и протоколе TCP/IP, хотя проявляются и недостатки этого протокола, например иногда PBS «зависает» при сбоях даже одного исполнительного узла. СУПО обладают чертами транзакционной системы - когда пакетное задание перемещается между хостами, важно, чтобы оно не было утеряно или реплицировано. Техника реализации сетевого обмена учитывает возможность разрыва сетевого соединения как на клиентской, так и на серверной стороне, с сохранением возможности отката к корректному состоянию.
Сложности с передачей собственно данных возникают из-за того, что в условиях гетерогенности формат обмена должен обеспечивать интероперабельность узлов с разной архитектурой, различающихся, например, размером слов и порядком байтов. В такой ситуации применяются стандартные, например ISO ASN.1, или собственные библиотеки кодирования.
Администрирование СУПО
СУПО способны функционировать в автоматическом режиме (как и ОС), однако надежность и эффективность их работы в большой степени зависит от начальной установки, которая включает проектирование состава узлов, определение их ролей, инсталляцию соответствующих компонентов СУПО и их конфигурирование. Наиболее трудные моменты - выбор политики диспетчеризации, разработка схемы очередей и спецификация ресурсов.
В ходе функционирования СУПО администратор может модифицировать конфигурацию, причем без остановки процесса обработки. Основное средство - утилита Qmgr с собственным командным языком для создания очередей и изменения их атрибутов, включая определение ресурсов. Поддерживается также оперативное управление обработкой: например с помощью команды Qmgr можно управлять отдельными заданиями (снимать, задерживать, удалять), очередями (исключать их из диспетчеризации), узлами (перевод в состояния off-line и down) и всем процессом обработки (прекращать диспетчеризацию).
Безопасность в СУПО
Во всех реализациях СУПО используется довольно примитивный способ обеспечения безопасности. Регистрация пользователя в СУПО происходит на интерфейсном узле и контролируется средствами ОС, но задания могут выполняться на любом исполнительном узле. Их запуск происходит от имени пользователя с тем же входным именем (login name), что и на интерфейсном узле. Таким образом предполагается, что пользователь СУПО зарегистрирован на всех исполнительных узлах под одним именем. Кроме того, применяются файлы отображений (map-file), в которых задаются соответствия входных имен на интерфейсном и исполнительном узле.
Диспетчеризация заданий
Процесс диспетчеризации в СУПО производит распределение заданий по исполнительным узлам в соответствии с некоторой политикой, которая зависит от конкретной установки и реализуется средствами конфигурирования. Аналогичную функцию в ОС выполняет диспетчер процессов (dispatcher), однако в пакетной обработке роль диспетчеризации (scheduling) значительно выше, так как СУПО работают в более крупном временном масштабе и цена ошибок планирования возрастает.
Диспетчеризация решает две задачи - временную и пространственную. Первая - это порядок, в котором задания будут запускаться на счет. ОС работают в режиме разделения времени, и все введенные команды сразу запускаются. Такой режим годится для коротких интерактивных задач с характерными временами ответа порядка секунды. Временная диспетчеризация пакетных заданий учитывает, что параллельный счет нескольких задач вычислительного характера ведет к удлинению времени завершения каждой из них, накладным расходам на свопинг и переключение процессов. Поэтому в СУПО ввод задания пользователем и запуск его на счет могут быть разделены значительным временным интервалом. В период ожидания задание находится в спуле.
Пространственная диспетчеризация заданий - это размещение их по исполнительным узлам вычислительного комплекса. Здесь есть два мотива. Первый учитывался в самых первых СУПО типа NQS - это равномерная загрузка узлов: плохо, если на одном узле будет запущено 10 заданий, в то время как другой будет простаивать. Второй мотив проявляется в современных СУПО и связан с ростом количества включаемых в комплексы узлов и увеличением степени гетерогенности. Задание должно быть запущено на таком узле, который для него подходит по платформе, конфигурации вычислительных ресурсов и предполагаемого времени счета.
Периодическое размещение заданий на вычислительных узлах выглядит как типичная задача планирования, которую можно формализовать следующим образом.
1. Вводится понятие ресурса, каждое задание оформляет свои потребности в виде <заказа ресурсов>, и для исполнения задания выбираются только те узлы, которые располагают всеми необходимыми ресурсами.
2. С заданием ассоциируется приоритет, определяющий частичный порядок в спуле. В соответствии с этим порядком производится выборка заданий и их запуск.
3. Определяются правила выбора узлов из числа тех, которые удовлетворяют заказу ресурсов задания.
Каждая из современных СУПО содержит несколько способов интерпретации приоритетов и выбора узлов, относя применение того или иного способа к компетенции администрации и предоставляя конфигурационные средства для настройки (без остановки функционирования) на конкретный поток заданий. Так, например, два основных алгоритма распределения узлов - балансировка загрузки и монопольное выделение. В первом случае задания направляются на узел до тех пор, пока не будет превышен заданный предельно допустимый уровень загрузки узла, и они считаются, вообще говоря, в режиме разделения времени. При монопольном выделении на узел распределяется только одно задание.
В общем случае задача планирования одного цикла диспетчеризации, по-видимому, может быть решена точно, хотя она комбинаторная и способ ее решения - перебор вариантов. Результатом точного планирования было бы: расписание запуска заданий и места их запуска. Однако реально применяются более простые методы. Выделяются две независимые фазы: определение порядка выполнения заданий (их упорядочение) и выбор подходящего исполнительного узла для каждого задания. Ясно, что при таком варианте возможно блокирование запуска задания даже при наличии свободных ресурсов. Например, имеется два задания J1 и J2 с требованиями к памяти по 100 и 200 Мбайт соответственно, которые запускаются на комплексе с двумя узлами: 200 и 100 Мбайт. Если задание J1 будет запущено первым на 200-мегабайтном узле, то второе будет вынуждено ждать его окончания, между тем как можно запустить и оба.
Диспетчеризация на основе очередей
Очереди - самый ранний механизм планирования вычислений, ведущий начало от пакетных ОС и перенесенный затем в первые СУПО. Очереди задают разбиение спула ожидающих выполнения заданий на группы с общими «пунктами назначения». Со временем были осознаны серьезные недостатки этого механизма и само понятие очереди претерпело серьезную трансформацию, так что трактовка очередей в NQS, PBS, DQS и Condor существенно различна.
Система очередей реализуется администратором как один из этапов установки СУПО и может корректироваться в ходе функционирования. Интерфейс администратора (утилита Qmgr) содержит команду для создания очередей (Create Queue) и команды для установки/изменения их атрибутов. Прежде всего, о тех атрибутах, которые управляют попаданием (маршрутизацией) заданий в ту или иную очередь. Это атрибуты-ограничения и их можно разбить на три группы.
1. Ограничения доступа разрешают доступ к очереди только заданиям, введенным с определенных машин (acl_hosts), определенными пользователями (acl_users), входящими в группы (acl_groups).
2. Ограничения на количество заданий специфицируют емкость очереди (max_queuable) и максимальное число заданий, которые могут быть из нее запущены (max_running), причем ограничения могут быть наложены на задания одного пользователя (max_ user_run). С помощью этих атрибутов можно регулировать нагрузку на исполнительные узлы, перераспределять задания в другие очереди и исключить монополизацию очереди одним пользователем.
3. Ограничения на ресурсы сортируют задания по величине ресурсного запроса: маленькие задания можно направить в одну очередь, средние - в другую, а большие - в третью. Для этого определяются значения атрибутов resources_max.<имя ресурса>, resources_min.<имя ресурса>. Задание может попасть в очередь, если в нем запрос ресурса находится в пределах [resources_max, resources_min].
При попадании задания в очередь происходит следующее. Во-первых, паспорт пополняется значениями атрибутов очереди, если они не указаны явно в команде Qsub. Таким способом удобно, например, определять стандартную рассылку уведомлений, присваивать приоритеты, восполнять опущенные позиции заказа ресурсов. Во-вторых, очереди определяют «пункты назначения» заданий. Есть два типа очередей: исполнительные и маршрутизирующие (pipe queue). Они отличаются тем, что у исполнительных очередей пункты назначения - только исполнительные узлы, а у маршрутизирующих - другие очереди.
Далее на каждом цикле диспетчеризации делается попытка переправить задания в один из пунктов назначения, причем обработка заданий ведется в порядке приоритетов соответствующих очередей (это еще один из атрибутов). Таким образом, очереди определяют порядок выборки заданий на каждом шаге маршрутизации и при запуске заданий. Для выбранного задания селекция пунктов назначения при наличии нескольких возможных происходит либо по кругу, либо по загрузке пункта назначения. Маршрутизация осуществляется, если пункт назначения готов к приему. Для очередей это означает, что задание удовлетворяет ее ограничениям, а для исполнительных узлов - что не превышены пределы загрузки.
Аппарат очередей позволяет реализовать различные стратегии управления заданиями в конкретных производственных условиях, но для этого должны быть задействованы маршрутизирующие очереди. Можно указать ряд приемов построения схемы очередей.
1. Неявное определение значений атрибутов. Например приоритет задания - существенный атрибут, определяющий порядок выборки заданий и следовательно время ожидания в очереди. Возложить расстановку приоритетов на самих пользователей было бы наивно, но можно устроить «вычисление» приоритетов по именам пользователей.
2. Удовлетворение ресурсных запросов. Правильное конфигурирование очередей должно обеспечить попадание заданий на исполнительные узлы, располагающие необходимыми ресурсами. Из этого следует, что у одной очереди пунктами назначения могут быть только узлы с тождественными ресурсами, и эти ресурсы должны быть описаны в виде атрибутов-ограничений очереди.
У аппарата очередей просматриваются весьма существенные недостатки, которые вытекают из формальности и жесткости схемы. Несложно установить критерии маршрутизации на одном шаге (в одной очереди), однако, спроектировать несколько связанных шагов значительно сложнее. Типичная словесная формулировка такого условия: «Принимать задания с временем счета до 10 минут в первую очередь, а если их нет, то можно и более длинные». Если же пренебречь такими «сложностями», то будут весьма вероятны ситуации, в которых одна очередь (и прикрепленные к ней узлы) может быть перегружена, в то время как другие будут пустыми.
Другой недостаток. Маршрутизация задания по очередям может быть длительным процессом. Траектория движения задания по системе очередей детерминируется атрибутами-ограничениями, но проверки происходят в разные моменты времени. В результате, когда задание направляется на выполнение, решения, принятые на предыдущих этапах маршрутизации могут оказаться не адекватными текущей ситуации в СУПО.
Диспетчеризация в DQS
Подход DQS весьма радикален - здесь устранен основной аппарат диспетчеризации, принятый в системе NQS - маршрутизирующие очереди. Правда исполнительные остались, и вначале о том, в чем они похожи: в DQS исполнительная очередь имеет атрибуты-ограничения на доступ, на число заданий в очереди и на ресурсы - все как в NQS. Различия же в следующем.
1. Исполнительная очередь DQS имеет ровно один пункт назначения - исполнительный узел, причем один узел может быть связан с несколькими очередями.
2. Распределение задания в какую-то очередь фактически означает его запуск, т. е. задание передается в пункт назначения и попадает в руки исполнительного демона.
3. Каждый цикл диспетчеризации в DQS - это попытка запустить все задания, содержащиеся в спуле. Для каждого задания спула делается попытка разместить его в какую-либо очередь: сравнивается паспорт задания и ограничения очереди. Если ни одна очередь не способна принять задание, оно остается в спуле, ожидая следующего цикла, и начинается диспетчеризация следующего.
Здесь нужно уточнить порядок перебора заданий и очередей. В спуле ожидания задания упорядочены, во-первых, по приоритетам, и, во-вторых, по времени ввода. Очереди перебираются в соответствии с конфигурационным параметром SORT_SEQ_NO. Если его значение TRUE, - то в соответствии с порядковыми номерами, установленными администратором при конфигурировании очереди. Если SORT_SEQ_NO = FALSE, то очереди просматриваются в порядке возрастания средней загрузки пункта назначения и с учетом параметров конфигураций очередей, устанавливающих лимиты на загрузку.
Схема диспетчеризации DQS устраняет один из недостатков NQS - распределение заданий по очередям совмещено по времени с передачей их на исполнение и, следовательно, происходит по актуальной информации о состоянии СУПО. Главными селекторами отбора очереди становятся ограничения доступа и ресурсные ограничения. То обстоятельство, что на один исполнительный узел могут быть настроены несколько очередей, можно использовать для направления на него нескольких потоков заданий, но с разными приоритетами (например, большие задачи, которые считаются в первую очередь, и маленькие задачи, запускающиеся при отсутствии больших).
Однако отказ от маршрутизирующих очередей приводит к новому недостатку: фактически приоритеты заданий могут быть заданы только явным образом (либо через явную спецификацию очереди, чего, по-видимому, не следует допускать).
Комбинированная диспетчеризация в PBS
Разработчики системы PBS, критически переосмысливая опыт СУПО первого поколения, в основу своего проекта положили несколько принципов:
- максимальная приближенность к стандарту POSIX 1003.2d;
- модульность архитектуры и стандартизация компонентов (планировщика, управления задачами (API TM), сетевых протоколов);
- избыточность, конфигурируемость и адаптируемость средств управления заданиями.
В результате PBS, сохраняя многие черты NQS , в некоторых отношениях оказалась похожа на DQS. Последние, начиная с v. 2.0, версии PBS характеризуются следующими особенностями.
1. В PBS тот же механизм очередей, что и в NQS, включая маршрутизирующие очереди.
2. Разделяются фазы маршрутизации заданий, которая происходит на сервере, и распределения по исполнительным узлам. Последняя выполняется отдельной компонентой - Планировщиком, выделенным в отдельный сервис. Планировщик может располагаться на машине, отличной от серверной, и более того, его интерфейсы позволяют обслуживать несколько серверов.
3. Исполнительные очереди не имеют пунктов назначения, и задания из любой очереди распределяются по всему множеству исполнительных узлов - как в DQS. Пунктами назначения маршрутизирующих очередей могут быть только очереди.
Остановимся подробнее на одном из нескольких поставляемых в дистрибутиве PBS - планировщике FIFO. На каждом своем цикле планировщик, получая от сервера список прошедших маршрутизацию и готовых к выполнению заданий, делает попытку распределить их по исполнительным узлам. Cам планировщик наделен конфигурационными параметрами, позволяющими упорядочивать как задания, так и очереди:
sort_by - сортировка заданий по одному или нескольким ключам: длительности задания, объему памяти, приоритету;
by_queue - cканирование спула заданий с учетом/без учета очередей;
round_robin - порядок сканирования заданий из очередей («true»- по одному из каждой, «false» - сначала все из одной);
sort_queues - сортировка очередей по приоритету;
strict_fifo - выбор задания, строго придерживаясь правила первый пришел-первый ушел (fifo).
Таким образом, упорядочение заданий в PBS может производиться в двух пунктах обработки - на сервере (маршрутизация) и в планировщике, и следовательно система может работать как с очередями, так и без них . Сами разработчики PBS выражают мнение, что диспетчеризацию лучше всего проводить по всему множеству ждущих заданий, сопоставляя их с множеством узлов и текущим состоянием ресурсов, и рекомендуют создавать всего одну очередь. В таком варианте на долю маршрутизации остается установка атрибутов по умолчанию и ограничение доступа.
Если процесс выборки заданий происходит путем взаимодействия планировщика с сервером, то при распределении их по узлам планировщик получает информацию от работающих на узлах исполнительных демонов. Как и в других СУПО планировщик PBS умеет выравнивать загрузку узлов (Loadleveling), опираясь на текущие полученные от ОС значения. Однако кроме того, в PBS сделано важное движение в сторону распределения по текущему состоянию ресурсов.
Диспетчеризация по ресурсам
Ресурс, как и любое базовое понятие, определить трудно. Не слишком формально будем называть типом ресурса (или ресурсом там, где это не вызывает двусмысленности) любую характеристику исполнительного узла компьютерной системы (СУПО), которая отличает ее от других компонентов. Это определение позволяет понимать под характеристикой сущности разной природы: оперативную и файловую память, процессоры, конкретные файлы (программы, библиотеки), внешние устройства и т.д. У ресурсов в СУПО два лица: во-первых, вычислительные узлы ими располагают и их выделяют, а во-вторых, они заказываются в задании. Примеры типов ресурсов: архитектура узла (arch=HP-UX10.20), максимальный объем памяти задания (mem=10mb), число доступных ЦПУ (ncpus=2), время счета задания (walltime=30:00), необходимые программные средства (Prog= MPI).
Можно выделить два класса ресурсов: статические и динамические. Первые не меняются в течение достаточно больших временных интервалов: архитектура узлов, тип ЦПУ и т.п. Вторые меняются в процессе работы СУПО, например: количество свободной виртуальной памяти или доступный для задания размер файлового пространства. Важной характеристикой СУПО является возможность расширения набора типов ресурсов. Она есть и в DQS, и в PBS, хотя реализуется по разному.
В пользовательском интерфейсе PBS заказ ресурсов производится в опции командой QSUB, список ресурсов в которой задается в следующей форме:
< имя ресурса>[=<значение ресурса >][,< имя ресурса >[=<значение ресурса >],...]
Например,
host=kserv,cput=02:30:00,mem=10mb, file=20mb script.
Конфигурирование PBS выполняется с помощью команды администратора Qmgr, в которой можно определить ресурсные ограничения для системы в целом (для Сервера) и для отдельных очередей. Для этого задаются значения атрибутов: resources_max, resources_min, resources_default, resources_available - максимальное, минимальное значение, значение по умолчанию для одного задания и общее количество ресурса на Сервере или в очереди. С помощью resources_ available моделируется резервирование ресурсов. При запуске заданий занимаемое ими количество ресурсов суммируется во внутреннем атрибуте resources_assigned. Как только значение последнего атрибута превышает значение resources_available, запуск заданий приостанавливается до освобождения ресурса.
Система DQS в значительно большей степени, чем PBS, ориентирована на работу с ресурсами. Характерная черта подхода - наличие средств расширения. Любая строка символов может быть обозначением ресурса. Типы ресурсов определяются административными средствами при конфигурировании очередей: ресурсы именуются и получают значения. Поскольку в отличие от PBS очередь DQS однозначно определяет исполнительный узел, указывая тот или иной ресурс в запросе, пользователь может точно (в том числе и однозначно, если введен ресурс «имя узла») определить множество узлов, на которые следует направлять задание.
В DQS существуют два класса ресурсов: фиксированные и расходуемые. Приписывание фиксированных ресурсов к очереди производится не по одиночке, а в виде так называемых ресурсных комплексов (complex). Описание заключается в том, что для комплекса выбирается уникальное имя и в специальном редакторе создается набор определений ресурсов. Для определения ресурса используется три вида описаний: «строка», «строка=строка», «строка=число».
Описание первого типа просто именует ресурс и обозначает его наличие. Если это имя указано в ресурсном запросе, то задание будет распределяться только в очереди с точно таким же определением. В таком виде удобно оформлять наличие/отсутствие какого-либо компонента, например, библиотеки PVM. Описание второго типа, кроме имени, вводит значение ресурса. Предполагается, что в других комплексах этому же ресурсу могут быть присвоены иные значения - это перечислимый тип ресурса, например обозначение архитектуры. Ресурсный запрос оформляется в таком же виде - как имя и значение. Последнее описание соответствует ресурсам численного типа, и обработка ресурсного запроса для них производится с помощью операций сравнения > < =. Например, комплекс с именем «НР» содержит описание трех ресурсов: arch=hpux, memory=256, pvm.
Ресурсный запрос задается командой Qsub и состоит из списка, описанных в конфигурации ресурсов, с требуемыми значениями, соединенных логическими операциями, например: arch=hpux && memory>=128, что означает: для выполнения данного задания необходим исполнительный компьютер с операционной системой HPUX и с памятью не менее 128 Mбайт - следовательно для него подойдет очередь, в которой добавлен ранее описанный комплекс с именем «HP».
Для расходуемых ресурсов используются другие структуры - consumables, значения которых изменяются в результате запуска заданий на выполнение. Простейшим примером расходуемого ресурса может быть программное обеспечение (компиляторы, базы данных) с ограниченной по числу одновременно работающих пользователей лицензией. Однако таким же образом может управляться разделяемая память и дисковое пространство. В определении расходуемого ресурса, в отличие от комплексов, кроме общего количества ресурса, имеющегося в системе, указывается количество ресурса, занимаемого заданием при удовлетворении ресурсного запроса. Если задание помещается в определенную исполнительную очередь, доступное количество этого ресурса уменьшается (до окончания задания или освобождения ресурса специальной утилитой DQS).
Рассмотрим пример с компилятором, доступ к которому контролируется «лицензионным сервером». Менеджер расходуемых ресурсов DQS не может заменить такой сервер, но он порождает параллельный механизм, который отслеживает то, как много лицензий используется в данный момент пользователями СУПО и соответственно разрешает/запрещает запуск новых заданий, использующих компилятор. Для этого примера расходуемые ресурсы можно определить командой конфигурирования расходуемых ресурсов:
Qconf -acons FORTRAN
Окно редактора ресурсов при этом будет содержать следующий шаблон:
Consumable xlf
Available=5
/*доступное количество ресурса*/
Consume_by 1 /*квант уменьшения
ресурса при запросе*/
Current=5
/*текущее доступное количество
ресурса */Расходуемые ресурсы DQS - аналог используемого в PBS механизма, основанного на атрибуте resources. available: оба средства направлены на «резервирование» ресурсов для запускаемых заданий.
Диспетчеризация заданий по ресурсам предполагает учет ряда обстоятельств.
1. При распределении задания на исполнительный узел должно проверяться не только наличие ресурсов, но и то, не заняты ли они в текущий момент другими заданиями или процессами. Такая проверка позволяет избежать непроизводительных расходов: в противном случае задание может сняться либо во время запуска, либо после длительного счета по причине нехватки ресурсов. Только в архитектуре PBS проверка ресурсного запроса по текущему состоянию узлов представлена в явном виде - актуальную информацию планировщику сообщает Монитор Ресурсов (МР), работающий на каждом исполнительном узле. В DQS аналогичная функция моделируется «расходуемыми» типами ресурсами (см. ниже) и не использует информацию от узлов.
2. Вообще говоря, наличия свободных ресурсов при запуске задания недостаточно - они должны быть выделены на весь период выполнения. Механизм управления заданиями PBS имеет в виду резервирование ресурсов, но он опирается на наличие средств резервирования в операционной системе. Такие средства есть, например, в Unicos, для которой разработано расширение SRFS - Session Reservable File System.
При наличии поддержки PBS пытается зарезервировать нужное количество ресурса в процессе диспетчеризации. Происходит это следующим образом. Задание может начать выполняться только при наличии всех ресурсов на исполнительном узле. Если отсутствуют нерезервируемые ресурсы, то оно остается в состоянии ожидания. В случае же отсутствия резервируемого ресурса задание будет переведено в особое состояние сопровождения (expedite) запуска. В этом состоянии все уже выделенные ресурсы не освобождаются, а PBS ожидает выделения недостающего ресурса в течении времени, заданного атрибутом очереди reserved_expedite. Если этого не удается сделать, все занятые заданием ресурсы освобождаются. Процессы сопровождения и диспетчеризация действуют параллельно: пока часть заданий ожидают выделения резервируемого ресурса, остальные могут запускаться.
Заключение
Вопрос: какая из СУПО лучше? - не имеет, по-видимому, однозначного ответа. Отдавая себе отчет в недостатках, мы остановились в конце концов на PBS, руководствуясь следующими соображениями.
Коммерческие системы весьма дороги, а свободно распространяемые разрабатываются в крупных исследовательских центрах на высоком профессиональном уровне, превращаясь потом в коммерческие, например DQS в Codine. Для пользователей PBS организована поддержка по электронной почте - можно оперативно получить любые консультации. В составе дистрибутива поставляется полный комплект актуальной документации. А самое главное - система динамично развивается.
СУПО - это конечно не ширпотреб, и в цели этой статьи вовсе не входит борьба за их повсеместное внедрение. Но можно взглянуть с другой стороны и рассмотреть эти системы как индикатор положения дел в области высоких технологий. Сейчас, наверное, если не все, то очень многие социально значимые технические прорывы опираются на компьютерное моделирование и, таким образом, на интенсивные вычисления. Как следствие, средства организации таких вычислений (СУПО) широко применяются сегодня в каждом более - менее крупном вычислительном центре. Сопоставляя это, выходит, что либо в России исследования ведутся какими-то оригинальными методами, для которых не нужны мощные вычислительные ресурсы, либо, наоборот, попросту нет реальных масштабных исследований, несмотря на все оптимистические оценки и заявления.
Работа выполнена при финансовой поддержке Российского фонда фундаментальных исследований (проект N 99-01-00389) и Министерства промышленности, науки и технологий РФ (гос. контракт № 203-3(00)-П).
Об авторах
Виктор Коваленко, Евгения Коваленко - сотрудники ИПМ им. М.В.Келдыша РАН. С ними можно связаться по электронной почте по адресу: kvn/kei@keldysh.ru
Литература
[1] M. Baker, T. Hey and L. Robertson. Cluster Computing Report, A Report for the JISC NTSC, The University of Southampton, January 1995. http://www.npac.syr.edu/techreports/html/0700/abs-0748.html
[2] M.A. Baker, G. C. Fox and H.W. Yau. Review of Cluster Management Software, NHSE Review, v.1, N 1, 1996. ttp://www.nhse.org/NHSEreview/CMS
[3] М. Кузьминский. NQS и пакетная обработка в Unix. «ОТКРЫТЫЕ СИСТЕМЫ» 1997, №1. http://www.osp.ru/os/1997/01/18.htm
[4] J.P. Jones, C. Brickell. Second Evaluation of Job Queuing/Scheduling Software: Phase 1 Report, NAS Technical Report NAS-97-013, NAS Facility, NASA Ames Research Center, 1997 June. http://www.nas.nasa.gov/Pubs/TechReports/NASreports/NAS-97-013/
[5] J.P. Jones. NAS Requirements Checklist for Job Queuing/Scheduling Software, NAS Technical Report NAS-96-003, NAS Facility, NASA Ames Research Center, 1996 April. http://www.nas.nasa.gov/Pubs/TechReports/NASreports/NAS-96-003/
[6] J.P. Jones. Evaluation of Job Queuing/Scheduling Software: Phase 1 Report, NAS Technical Report NAS-96-009, NAS Facility, NASA Ames Research Center, 1996 July. http://www.nas.nasa.gov/Pubs/TechReports/NASreports/NAS-96-009/
[7] http://pbs.mrj.com
[8] http://www.scri.fsu.edu/~pasko/dqs.html
[9] ConvexNQS+ User?s Guide, Convex Press, 1995
[10] http://www.cs.wisc.edu/condor
