
По мере того, как механизмы обработки запросов становятся все масштабнее и приобретают федеративный характер, они должны удовлетворять требованиям непредсказуемых и быстро меняющихся сред. В проекте Telegraph мы попытались разработать и реализовать механизм непрерывно адаптирующейся обработки запросов, отвечающий требованиям глобальных систем, массивного параллелизма и нейронных сетей. Чтобы подготовить почву для нашего исследования, мы представляем обзор проделанной раннее работы, касающейся адаптивной обработки запросов, первоочередное внимание уделяя трем характеристикам адаптивности: частоте адаптивности, эффекту адаптивности и диапазону адаптивности. С учетом данных этого обзора мы наметили направления исследования в рамках проекта Telegraph*.
Введение
Последние три года адаптивность была неотъемлемым (хотя зачастую скрытым) аспектом исследований в области баз данных. Представление Кодда о независимости данных было основано на разработке систем, способных элегантно и незаметно изменять данные и структуры данных. Оптимизация запросов вместе с дополняющими ее технологиями оценки затрат, послужила основным признаком, отличающим систему управления базами данных от других компьютерных систем. Эта традиционная динамическая, основанная на статистической информации оптимизации до сих пор остается одним из самых блестящих достижений научного сообщества, работающего над вопросами баз данных.
В последние несколько лет проектированием систем, способных адаптироваться к условиям среды, в которых они работают, занимались специалисты самых разных областей информатики. По мере того, как компьютерные системы становились все масштабнее и приобретали четко выраженный федеративный характер, традиционные методики системного управления и настройки производительности вынуждены были становиться все более слабо структурированным и способными более активно адаптироваться. В контексте систем баз данных это расширение традиционных методик для поддержки адаптивной обработки запросов дошло до своего предела, поскольку очень крупномасштабные механизмы обработки запросов действуют в непредсказуемых и быстро меняющихся средах. Непредсказуемость - практически неотъемлемое свойство крупномасштабных систем, что обусловлено постоянным увеличением сложности в самых разных аспектах [AH00].
Сложность аппаратного обеспечения и рабочей нагрузки. В глобальных средах изменчивость обусловлена резкими изменениями производительности серверов и сетей [UFA98]. Эти системы, как правило, обслуживают сообщества пользователей, чье совокупное поведение предсказать порой очень сложно, а разное аппаратное обеспечение, используемое в глобальном масштабе, в достаточной степени неоднородно. Крупные кластеры «ничего не разделяющих» компьютеров могут быть подвержены столь же значительным колебаниям производительности из-за огромного разнообразия пользовательских запросов и применения разнородного аппаратного обеспечения. Даже в полностью однородных средах производительность аппаратного обеспечения может оказаться непредсказуемой: например, внешние треки диска могут предлагать в два раза большую пропускную способность, чем внутренние треки [Met97].
Сложность данных. Выборочная оценка статических наборов арифметических данных довольно понятна и первые работы в этом направлении касались оценки статистических свойств статичных наборов данных сложных типов [Aok99] и методов [BO99]. Но федеративные данные часто поступают без каких-либо статистических комментариев, а сложные неарифметические типы данных широко используются как в объектно-реляционных базах данных, так и в Web. В этих ситуациях (и даже в традиционных статических реляционных базах данных) выборочные оценки зачастую оказываются неточными.
Сложность пользовательского интерфейса. В крупномасштабных системах многие запросы обрабатываются очень долго. В силу чего, особым вниманием пользуются методы Online Aggregation и другие технологии, которые дают пользователям возможность «управлять» свойствами запросов во время их выполнения за счет улучшения аппроксимированных результатов [HAC+99].
Telegraph в контексте
Цель проекта Telegraph, осуществляемого в университете Беркли, состоит в том, чтобы спроектировать и создать глобальный механизм обработки запросов, который может выполнять сложные запросы ко всем данным, доступным в интерактивном режиме [1]. При проектировании Telegraph мы столкнулись с новыми трудностями, связанными с глобальными системами, в том числе с быстрыми изменениями производительности и готовности ресурсов в Internet. Мы также хотели, чтобы Telegraph служил в качестве ничего не разделяющего механизма параллельной обработки запросов, подключаемого по принципу plug-and-play и который должен элементарно управляться и поддерживать инкрементальное масштабирование. Наконец, мы хотели обеспечить поддержку сенсорных сетей (например, [EGH99, KKP99, KRB99]), которые превращаются во все более важный (и непредсказуемый аспект) «повсеместных» вычислительных систем.
Основным элементом Telegraph является механизм постоянно адаптирующейся обработки запросов, который способен накапливать информацию и действовать в соответствии с учетом обратной связи с очень высокой частотой. Эта высокочастотная адаптивность открывает новые возможности и ставит новые задачи в рамках нашего исследовательского проекта. В данной статье мы расскажем о предыдущих усовершенствованиях в адаптивной обработке запросов, подготовивших почву для решения тех вопросов, которые мы рассматриваем при создании Telegraph. В таблице 1 приводятся краткий список работ, которые мы анализируем.
Оболочка
К сожалению, выражение «адаптивная система» не является каноническим. Эти системы иногда называют «динамическими» или «самонастраивающимися системами», или системами, которые меняют свое поведение за счет «обучения», «самоанализа» и тому подобными. Аналогичные понятия используются в родственных областях, таких как теория управления [Son98] или машинное обучение [Mit97]. Чтобы избежать путаницы в терминологии, мы предлагаем свое собственное определение адаптивности в этом контексте. Мы будем называть систему обработки запросов адаптивной, если она имеет три признаки: (1) получает информацию из среды; (2) использует эту информацию для определения своего поведения; (3) этот процесс повторяется со временем, создавая цикл обратной связи между средой и поведением системы.
Мы хотим подчеркнуть различие между адаптивными системами и системами, которые выполняют статическую оптимизацию. Статическая оптимизация имеет первые два из этих признаков, но не третий. Обратная связь, включенная в адаптивную систему, - ключ к ее эффективности: она позволяет системе принимать многочисленные решения (и анализировать их результаты). Это дает системе возможность учитывать свое влияние на среду в совокупности с внешними факторами и анализировать эффект «использования» ранее полезного поведения, а также «искать» альтернативное поведение [Mit97].
Исходя из определения адаптивности мы можем выделить три основных характеристики адаптивной системы: (1) частота адаптивности (насколько часто система получает информацию и меняет свое поведение); (2) эффект адаптивности (какое поведение система способна менять); (3) диапазон адаптивности (как долго поддерживается цикл обратной связи).
Исследование адаптивной обработки запросов
Не придавая слишком большое значение историческому анализу, мы, тем не менее, признаем, что это исследование касается не только планов ведения нашего проекта, но и истории вопроса. Действительно, при написании данной статьи мы стремились рассказать о реализации проекта по адаптивной обработке запросов в контексте того, как нам представляются перспективы, а в чем состоят недостатки проведенных на сегодняшний день исследований.
Мы организовали наш обзор частично придерживаясь хронологического порядка, а частично с учетом роста частоты адаптивности в предложенных на сегодняшний день решениях. Как следует из таблицы 1, эти два принципа упорядочивания коррелируют за рядом нескольких интересных исключений. Увеличение уровня адаптивности с появлением каждого нового решения кажется естественным, учитывая, что системы создаются для все более сложных и быстро изменяющихся сред.
Первые реляционные системы
Начиная с самых первых прототипов, процессоры реляционных запросов поддерживали некоторые минимальные возможности адаптивности, как правило для получения информации о меняющемся распределении данных в базе, и использовали ее для моделирования размера результатов выполнения подзапросов и, как следствие, затрат на операторы запросов.
Оптимизатор запросов System R [SAC+79] (который послужил основой практически для всех серьезных реализаций коммерческий СУБД, существующих на сегодняшний день) хранит каталог статистики, в том числе характеристики таблиц и примерное распределение значений внутри столбцов. Согласно определению, System R не является в полной мере адаптивной, поскольку она не поддерживает четкую обратную связь с системой. С другой стороны, системный администратор может вручную указать System R на необходимость адаптировать свое поведение в соответствии с данными: по команде система сканирует всю базу данных и меняет свою статистику, по завершении чего эта информация влияет на все решения, касающиеся оптимизации запросов. Этот сложный подход периодической пакетной адаптивности сохранился практически во всех современных коммерческих СУБД, хотя, конечно же, собираемая статистика, как и используемые для этого инструментальные средства, со временем становятся все совершеннее. Хотя частота адаптивности в таких системах довольно низка (статистика обычно обновляется раз в день или раз в неделю), эффект достаточно широк, а диапазон адаптивности обширен: при получении новой статистики оптимизатор может выбрать абсолютно иные методы доступа, порядок соединений и алгоритмы соединений для всех последующих запросов.
Схема «декомпозиции запросов» [SWK76] в Ingres менее эффективна, но значительно более адаптивна, чем System R. Ingres чередует выбор подплана и выполнение. Для запроса на n таблицах она действует как ресурсоемкая, но адаптивная последовательность соединений вложенных циклов. Самая маленькая таблица** сканируется первой. Для каждого картежа самой маленькой таблицы в следующей по размеру таблице ведется поиск соответствий через «процессор запросов одной переменной» (т. е., модуль сканирования таблиц или модуль поиска в индексе) и результат этого поиска (без дублирующих элементов) будет материализован. Этот ресурсоемкий процесс затем рекурсивно применяется к оставшимся n-1 таблице, т. е. n-2 базовым таблицам и одному материализованному промежуточному результату. После окончания рекурсии процесс начинается снова со следующего кортежа самой маленькой таблицы. Отметим, что это не соответствует статическому «порядку соединения» в смысле System R: материализованный результат каждой «проверки кортежа» может меняться в размерах в зависимости от числа соответствий с каждым конкретным кортежем и, таким образом, порядок соединений в рекурсивном вызове может меняться от кортежа к кортежу в самой маленькой таблице. Хотя этот ресурсоемкий процесс оптимизации часто приводит к неэффективной обработке в традиционных средах, он отличается относительно высокой частотой адаптивности, поддерживая обратную связь после каждого обращения к процессору запросов одной переменной. Адаптивность в Ingres, таким образом, выполняется внутри каждого запроса или даже внутри оператора, в том смысле, что адаптация могла осуществляться от кортежа к кортежу таблицы, которая находится в центре последовательности соединений вложенных циклов. До недавнего времени в теории данная схема оставалась одной из самых высокочастотных. Обратная связь, выполнявшаяся после каждого сканирования таблицы или поиска в индексе влияла на адаптацию порядка соединений в последующих итерациях. Отметим, что эффект адаптивности в Ingres распространяется только на один запрос.
Схемы позднего связывания
Схемы, которые мы обсудим дальше, в каком-то смысле не более адаптивны, чем System R, и собирают столько же информации, сколько получает стандартный оптимизатор. Однако эти схемы обладают некоторым динамизмом и часто обсуждаются в контексте адаптивной обработки запросов, поэтому для полноты и ясности мы расскажем о них в данной статье.
Смысл этой работы состоит в том, чтобы усовершенствовать определенные возможности оптимизатора System R для часто выполняемых запросов. Помимо других своих функций System R предлагает возможность оптимизировать запросы, компилировать их в машинный код и хранить в системе для последующего использования. Эта методика, присутствующая в современных коммерческих РСУБД, позволяет распределить затраты на оптимизацию запроса между несколькими исполнениями одного и того же запроса, даже если константы запроса остаются неизвестны до момента его исполнения.
В конце 1980-х и в начале 1990-х годов были опубликованы несколько статей, посвященных анализу недостатков этой схемы: последующие выполнения запроса происходят при других легко проверяемых параметрах времени исполнения, в том числе изменения в определяемых пользователям константах, которые влияют выборочно, изменения в наличии памяти и тому подобного [HP88, GW89, INSS92, GC94, ACPS96, LP97]. Из-за таких изменений производительность при выполнении запроса может снижаться, но затраты на выполнение повторной оптимизации при каждом изменении среды могут оказаться слишком большими. Чтобы добиться оптимального выполнения эти системы осуществляют определенную оптимизацию заранее и затем необходимо только проанализировать некоторое подмножество всех возможных планов исполнения. План, который в конечном итоге выбирается для выполнения, будет таким, который мог бы быть создан при запуске полного оптимизатора System R во время исполнения. В типичном примере этой работы Граеф и Кол описывают динамические планы обработки запросов [GC94]. Учитывая ограничения на возможные изменения среды исполнения, их оптимизатор будет отбрасывать только те планы запросов, которые были оптимизированы во всех конфигурациях, удовлетворяющих этим ограничениям. В результате, их оптимизатор предлагает множество возможных планов запросов, среди которых ведется поиск на основе легко проверяемых параметров среды.
Эти схемы сосредоточены на проблеме отсрочки минимального решения до времени исполнения, эффективно выполняя «позднее связывание» неизвестных переменных для часто выполняемых повторно запросов. Но они не используют никаких особых преимуществ повторяющейся обратной связи и предлагают ту же самую частоту, эффект и диапазон адаптивности, которую предлагает оптимизатор System R, когда бы ни выполнялся запрос.
Позапросная адаптивность: увеличение адаптивности System R
Собирающая статистику схема системы System R была недостаточно детальной и работает лишь периодически, требует участия администратора и расходов значительных ресурсов. Чен и Роуссопоулос предложили схему Adaptive Selectivity Estimation (ASE) для совершенствования оптимизатора типа System R за счет промежуточного сбора статистики при обработке запроса [CR94]. Когда в данной схеме выполняется запрос, размер промежуточных результатов будет контролироваться системой и использоваться для улучшения статистических метаданных, на основе которых принимаются последующие решения по оптимизации. Этот подход предлагает органичный механизм обратной связи, анализирующий естественное течение обработки запроса для детального изучения и лучшего выполнения на последующих запросах. Адаптация ASE выполняется на уровне запросов (по прежнему охватывает несколько запросов, как и в системе System R, но более детальна и более естественно адаптивна). Эффект обратной связи в ASE потенциально столь же значителен, как и в системе System R, и влияет на выбор метода доступа, а также на порядок соединений и выбор метода соединения и может сохраняться между запросами. Отметим, однако, что в то время как ASE использует информацию, которую получает из запросов сразу, как только они инициированы, он не собирает информацию о таблицах, которые еще не были затронуты в запросах.
Mariposa выпускает СУБД, допускающие адаптивность на уровне запроса с федеративным администрированием [SAP+96]. Mariposa использовала экономическую модель, которая позволяет узлам в распределенной среде автономно моделировать изменение затрат на операции при выполнении запроса. Во время оптимизации запроса Mariposa запрашивает у каждого узла «предлагаемую цену» выполнение подпланов. Механизм предложения цен позволяет узлам анализировать изменение состояние своей среды от запроса к запросу и автономно переназначать стоимость операций для последующих запросов. В первых экспериментах Mariposa использовала эту гибкость для того, чтобы позволить узлам учитывать среднюю нагрузку и другие меняющиеся параметры при определении своих затрат на выполнение операций. В системе с помощью языка описания сценариев можно запрограммировать более совершенные «ценовые агенты» и в коммерческую версию системы (Cohera [HSC99]) входит API-интерфейс расширения, благодаря которому можно использовать ценовые агенты других производителей. Что касается частоты, то она, по сути, не отличается от частоты адаптивности, предлагаемой ASE: адаптивность осуществляется отдельно в пределах каждого запроса. Новым в Mariposa является тот факт, что экономическая модель допускает автономию и расширяемое управление правилами адаптации в узлах, входящих в федерацию. Mariposa использует «двухфазную» схему оптимизации, при которой порядок и методы соединений выбираются центральным оптимизатором, а «предложения цены» влияют только на выбор узлов, которые будут выполнять работу.
Конкуренция и анализ образцов
Одним из самых необычных на сегодняшний день оптимизаторов является оптимизатор СУБД RDB [AZ96], предложенный компанией Digital Equipment и передший впоследствии к Oracle. RDB стала первой системой, которая использовала конкуренцию для помощи при выборе планов выполнения запросов. Проектировщики RDB в первую очередь сосредоточились на вопросах выбора методов доступа для данного однотабличного предиката. Они отмечают, что относительную производительность двух методов доступа можно сравнивать только запустив оба метода одновременно. На основе анализа этой работы они могут выбирать среди нескольких одновременно выполняемых методов для данной таблицы и через короткий срок прервать работу всех, кроме самого перспективного метода доступа. RDB стала первой системой после Ingres, которая поддерживает адаптивность на уровне каждого оператора, хотя принимает только одно решение для каждой таблицы в запросе и влияет только на выбор метода доступа.
Схема RDB не похожа на схемы анализа образцов для выборочной оценки, которые также поддерживают частичное выполнение запроса для получения более детальной информации о производительности при полном выполнении запроса. За последние десять лет было опубликовано немало статей, в которых обсуждались вопросы анализа образцов для оценки избирательности предикатов (см. раздел 9 книги [BDF+97]). Анализ образцов, как правило, предлагается для использования во время оптимизации запроса и применяется только для указания начального выбора плана запроса (за исключение интерактивной обработки запросов, раздел 2.7.2). Также, как и в случае с ASE и Mariposa, эта схема поддерживает частоту на уровне каждого запроса - более детальную, чем System R, но не внутри одного запроса, как RDB. Эффект адаптивности здесь такой же как и у System R: изменение статистики может повлиять на все аспекты обработки запросов. Однако диапазон намного меньше, чем у System R - действует только при выполнении одного запроса.
Межоператорная повторная оптимизация и Query Scrambling
Как было сказано во введении, потребность в адаптивности растет с увеличением неопределенности, присущей среде обработки запросов. Среды с непредсказуемым поведением, такие как Internet, требуют адаптивности даже во время исполнения одного запроса. Несколько проектов, посвященных неопределенным средам, используют межзапросную адаптивность. Внутриоператорная адаптивность была естественным первым шагом в развитии этого направления. Один из подходов, использованных в распределенных системах, состоял в том, чтобы посылать запросы на удаленные узлы и затем на основе результатов подзапроса планировать оставшиеся части запроса [TTC+90, ONK+96]. Такие подходы учитывают неопределенность в затратах на выполнение удаленных подзапросов и, если результаты подзапроса материализованы, могут также до определенной степени компенсировать непредсказуемые задержки.
Query Scrambling [AFTU96] был разработан для компенсации непредсказуемых задержек, которые возникают, когда обработка распределенных запросов ведется в глобальной сети. При Query Scrambling запрос сначала выполняется в соответствии с планом, сгенерированным оптимизатором типа System R. Если, однако, во время исполнения производительность оказывается слишком низкой, план запроса модифицируется «на лету». Query Scrambling использует две базовые методики компенсации непредсказуемых задержек: 1) меняется порядок выполнения операций для того, чтобы избежать простоя; 2) синтезируются новые операции для выполнения в отсутствие другой работы. Как описано в [UFA98], процесс Query Scrambling может управляться с помощью простого оптимизатора запросов, учитывающего время ответа.
Кабра и Девитт предложили схему повторной оптимизации [KD98], связанную с неопределенностями в размерах результатов подзапросов. Как и в Query Scrambling, первоначальный план запроса выбирается традиционным оптимизатором типа System R. После каждого оператора блокировки в этом плане остаток плана повторно оптимизируется с учетом размера промежуточных результатов, сгенерированных к этому моменту. Система Tukwila предлагает очень похожую методику с языком правил для описания логики, позволяющей решить, когда необходима повторная оптимизация, и сохраняющей состояние оптимизатора, что позволяет сократить затраты на повторную оптимизацию [IFF+99].
По существу, межоператорная адаптивность - это долго откладываемое соединение схем оптимизации Ingres и System R: как Ingres она использует преимущества информации о размере материализованных промежуточных результатах; как System R она использует оценки на базе затрат для неизвестной работы, которую предстоит выполнить. Эти схемы выполняют адаптивность внутри оператора, которая оказывает произвольный эффект на оставшиеся шаги после блока в плане запроса; диапазон ограничен рамками оставшейся части запроса.
Еще раз о внутриоператорной адаптивности: WHIRL
WHIRL - это логика интеграции данных, разработанная в лабораториях AT&T, которая основана на текстуальном совпадении предикатов и отсортированная в соответствии с типом извлекаемой информации. Реализация WHIRL в AT&T ориентирована на то, чтобы как можно быстрее получить ответы с высокими приоритетами. Базовые операторы обработки запросов в реализации WHIRL по сути выполняют поиск в индексе с приоритетами из индексов инвертированных файлов. В конце каждого сканирования таблицы и поиска в индексе реализация может выбирать среди всех возможных вариантов последующего сканирования таблиц или поиска в индексах. Реализация AT&T WHIRL во многом похожа на INGRES, в том, что касается адаптивности внутри оператора: она поддерживает только соединения вложенных циклов и адаптирует порядок соединений в пределах конвейера этих соединений - потенциально меняя порядок после выполнения каждого обращения к методу доступа.
Адаптивные операторы запросов
До этого момента эффекты адаптивности, которые мы обсуждали, выполнялись на уровне оптимизации запросов: выбор методов доступа, методов соединений и порядок соединений (и а случае распределенных запросов - выбор узлов). Адаптивность может возникать на уровне отдельных операторов, которые способны адаптироваться на внутриоператорной частоте даже внутри контекста фиксированного плана запроса.
Адаптированные к памяти сортировка и хеширование
Затраты двух из базовых операций обработки запросов - сортировки и хеширования, представляют собой функцию объема доступной оперативной памяти. Оптимизаторы запросов оценивают эти затраты в предположении о наличии памяти. В некоторых системах адекватная память резервируется до выполнения, чтобы априори гарантировать эти затраты; в других системах память резервируется безотносительно к глобальному потреблению. Первая методика консервативна и может привести к недостаточному использованию ресурсов и увеличению задержки запросов. Последняя методика агрессивна, потенциально может привести к подкачке страниц, а также сокращает производительность при обработке запросов и увеличивает задержку.
Третий подход предусматривает модификацию алгоритмов сортировки и хеширования для адаптации к меняющемуся объему доступной памяти. Такие схемы обычно касаются как внезапного увеличения, так и внезапного сокращения объема доступной памяти. При сокращение объема доступной памяти, как правило, выполняется расщепление хеш-разделов или отсрочка слияния отсортированных запусков; при увеличении объема доступной памяти выполняется чтение из ранее расщепленных хеш-разделов или осуществляется слияние отсортированных запусков. Образцовая работа в этой области была выполнена Пенгом, Кареем и Ливни, которые изучили варианты хеш-соединений адаптивных к памяти [PCL93b] (на основе более ранней работы, в том числе [NKT88, ZG90]) и варианты, адаптивной к памяти сортировки, выполняемой вне ядра (out-of-core) [PCL93a] (с последующей работой в [ZL97]).
Конвейерные и сквозные алгоритмы соединений
Свойства конвейерной обработки алгоритмов соединений используются для реализации параллелизма; в своей параллельной СУБД, размещаемой в оперативной памяти, Уилшат и Эйперс предложили симметрическое хеш-соединение для максимального выявления конвейерного параллелизма,. [WA91]. Совсем недавно группы, работающие над Tukwila и Query Scrambling, естественным образом расширили конвейерное хеш-соединение, которое может выполняться вне ядра. Алгоритм XJoin [UF99], предложенный группой Query Scrambling еще больше развил идею out-of-core. Так, чтобы использовать задерживаемые данные: при задержке результатов конкретного сканирование таблицы XJoin использует время простоя для считывания с диска ранее расщепленных разделов и их соединения. Ни одно из этих расширений не является адаптивным в смысле данного ранее определения, но оба были использованы в контексте адаптивных систем.
Последняя работа по интерактивной обработке запросов в проекте Control подчеркивает способность конвейерных операторов обеспечить постоянную обратную связь и, как следствие, поддерживать адаптивность [HAC+99]. В первой работе по Online Aggregation [HHW97], алгоритмы конвейерной обработки запросов называются необходимым условием поддержки пользовательской обратной связи во время обработки запросов. В последующей работе системная обратная связь использовалась внутри алгоритмов сквозного соединения (ripple join) для того чтобы автоматически адаптироваться к относительным скоростям, с которыми они извлекают данные из различных таблиц с учетом статистической производительности [HH99]. Методы доступа в интерактивной обработке запросов, как правило, предполагают выполнение прогрессивного испытания образцов без замены, в силу чего эту работу можно отнести к традиционным схемам испытания образцов для оценки затрат.
Хаас и Хеллерштейн [HH99] предлагают более широкое определение сквозного соединения как семейства алгоритмов конвейерного соединения.
Они включают в свое определение более ранние конвейерные хеш-соединения и индексные соединения вложенных циклов параллельно с новыми итеративными и «блокирующими» сквозными соединениями***.
Подобная адаптивность использовалась только для управления относительными скоростями ввода-вывода из различных таблиц во время выполнения одного запроса.
River: адаптивное разбиение
В ничего не разделяющих параллельных СУБД внутриоператорный параллелизм достигается за счет распределения предназначенных для обработки данных между узлами системы. Традиционно такое распределение выполняется статически с помощью хеширования или циклических схем. River [AAT+99] - это инфраструктура параллельных потоков данных, цель которой - сделать это распределение более адаптивным. При создании рекордной реализации NOW-Sort [AAC+97] разработчики River отметили, что крупномасштабные кластеры значительно отличаются по производительности, причем даже физически идентичные вычислительные узлы. В итоге, они создали в River два базовых механизма, позволяющие адаптировать распределение данных между узлами в соответствии с меняющимися скоростями различных узлов. Механизм Distributed Queue пропорционально распределяет работу между многими потребителями, работающими на различных (и потенциально изменяющихся) скоростях; схема Graduated Declustering динамически выравнивает нагрузку, сгенерированную многочисленными избыточными источниками данных. Оба эти механизма выполняют адаптацию отдельно для каждого картежа, влияя на назначение работы узлам, а эффект адаптивности сказывается в течение всего времени выполнения оператора.
Eddy: постоянная адаптивность
В плане запроса (или подплане), состоящем из конвейерных операторов, таких как сквозное соединение, обратная связь поддерживается на покортежной основе. В силу чего необходимо, чтобы план (подплан) конвейерного запроса был способен адаптироваться с такой же частотой. Сквозные соединения, River и другие схемы используют обратную связь в пределах оператора для того чтобы изменить поведение операторов; Eddy - это механизм для получения межоператорных эффектов с внутриоператорной частотой адаптивности [AH00].
Eddy - это инкапсулированный оператор потоков данных, аналогичный соединению, сортировке или методу доступа с интерфейсом повторителя (iterator). Таким же образом как оператор обмена в Volcano инкапсулирует параллелизм, Eddy используется для инкапсулированной адаптивности. Eddy выполняет роль посредника между сканированиями таблиц в плане (который поставляет входные кортежи для Eddy) и другими «противотоковыми» операторами в плане (которые и используют выходные кортежи Eddy, и порождают дополнительные входные данные).
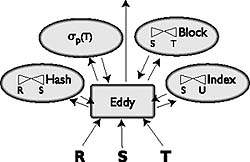 |
| Рисунок. Eddy в конвейере. Данные попадают в Eddy из входных отношений R; S и T. Eddy направляет кортежи операторам в конвейере, операторы работают как независимые потоки, передающие кортежи в Eddy. Eddy посылает кортеж на вывод только тогда, когда тот обработоан всеми операторами. Eddy адаптивно выбирает порядок передачи обработки каждого кортежа операторами. |
Как предполагалось изначально, Eddy - в сочетании с конвейерными операторами, такими как сквозные соединения, - служат для адаптации порядка соединения на покортежной основе. Каждый «противотоковый» оператор Eddy возвращает свои результаты в Eddy, который передает их вместе с другими операторами для дальнейшей обработки. В итоге Eddy инкапсулирует упорядочивание операторов, динамически пропуская через них кортежи (рисунок 1). Поскольку Eddy контролирует кортежи, входящие и исходящие из конвейерных операторов, он может адаптивно менять их маршруты с тем, чтобы обеспечить другой порядок операторов. Он делает это с помощью лотерейной схемы планирования [WW94]. Он может также управлять скоростью ввода из сканирования таблиц (если это управляется системой, как в оригинальном сценарии интерактивного слияния). В их исходном виде диапазон адаптивности в Eddy ограничен одним запросом. В следующем разделе мы опишем наш план расширения эффекта и диапазона Eddy.
Трудности в адаптивной обработке запросов
Хотя адаптивность долгое время была одним из аспектов исследований, связанных с базами данных, мы уверены, что частота адаптивности в более ранних системах была недостаточной для многий из возникающих крупномасштабных сред. Работа над постоянной адаптивностью только началась и мы осознаем, каковы трудности и перспективы в этой области.
При проектировании Telegraph мы использовали новые идеи постоянной адаптивности обработки запросов. Механизм обработки запросов в Telegraph представляет собой архитектуру потоков работ на базе River, Eddy и конвейерных операторов обработки запросов, таких как сквозные соединения и XJoins. Таким образом, проект рассчитан на реализацию детальной адаптивности и интерактивного пользовательского управления. River и Eddy - достаточно общие концепции и мы трактуем их шире, чем предполагается в оригинальных статьях, где вводятся эти понятия. Расширение их диапазона - дело относительно простое: хранилище метаданных может быть использовано для сохранения информации в конце каждого запроса и эта информация используется для определения начальных условий последующих запросов (распределение данных, относительное число лотерейных билетов и т.д.) Улучшение эффектов River и Eddy - намного сложнее и мы видим на этом пути целый ряд препятствий.
Охват деревьев. Как было предложено изначально, Eddy не влияет на дерево охвата для запроса, т. е. набор бинарных соединений, которые связывают отношения в запросе. В случае циклических графов соединений он используется для адаптации выбора дерева охвата «на лету» за счет связи Eddy с соединениями (или между продуктами) между большим числом пар в таблицах, чем это необходимо. По сути это вид конкуренции между деревьями охвата и, тем самым, он может потребовать значительных ресурсов и породить дублирующиеся результаты. Именно эти два вопроса мы сейчас изучаем.
Источники данных. River обрабатывает множество потенциальных источников данных с помощью калибровочной декластеризации, но требует конкретной структуры этих источников данных. Мы были бы рады расширить эту идею до федеративной среды, такой как Internet, где структура данных (и даже содержимое данных) никак не управляется. Это может породить дублированные или даже противоречивые результаты, которые необходимо урегулировать.
Соединение и методы доступа. Выбор методов доступа и соединений может быть выполнен Eddy только «на лету», если они работают на конкурентной основе, позволяющей Eddy изучать их поведение. При анализе этой идеи нам пришлось заниматься вопросами контроля разногласий между ресурсами и порождения дубликатов.
Меняющееся состояние в River. В исходной статье, посвященной River, точно не говорится, как состояние каждого узла (например, хеш-разделы в хеш-соединении) могут меняться по мере адаптации системы. Мы исследовали вопрос об использовании идеи адаптивных к памяти хеш-соединений в данном контексте.
Помимо расширения River и Eddy для того чтобы добиться более общего эффекта в большем диапазоне, мы рассматриваем несколько дополнительных вопросов адаптивности.
Двумерная интерактивность. Предыдущая работа по интерактивной обработке запросов допускала «горизонтальную» пользовательскую обратную связь на выбранных для обработки строках. В Telegraph мы также рассматриваем и «вертикальный» случай: частично соединенные кортежи должны быть доступны на выходе и пользователи должны иметь возможность выразить свои относительные требования к различным столбцам или даже комбинациям строк и столбцов. Частично соединенные кортежи не обязательно должны иметь соответствия во все таблицах в запросе. Другими словами, даже несмотря на то, что они попали в выходные данные, они могут не содержаться в окончательном ответе. Это имеет смысл для пользовательских интерфейсов, клиентских API и, конечно же, для правил, используемых в Eddy.
Начальные задержки. Первые работы по Query Scrambling затрагивают проблему начальных задержек, но не ясно, как эта работа может быть увязана с River и Eddy. Трудности возникают из-за полного отсутствия обратной связи, предусмотренной в сценариях начальной задержки.
Кеширование и предварительная выборка. Кеширование - это вероятно наиболее хорошо изученная проблема адаптивности в компьютерных системах, и особенно она актуальна для среды Internet, отличающейся большой степенью неопределенности. Предварительная выборка, которая тоже достаточно часто затрагивается при обсуждении проблемы адаптивности, динамически предсказывает выборку данных в свете изменения рабочей нагрузки. Мы активно используем обе методики в контексте Telegraph.
В дополнение к конструктивным целям Telegraph, остаются и многие аналитические вопросы. Первый из них состоит в том, как более точно охарактеризовать непредсказуемость всех прикладных сред, которые мы рассматриваем, в том числе глобальных сред, кластеров и сенсорных сетей. Мы понимаем, что каждая из этих сред заслуживает более детальной частоты адаптивности и верим, что широкий эффект и диапазон адаптивности также окажутся приемлемыми. Однако, чем больше мы узнаем об этих средах, тем более качественно должны работать наши адаптивные системы. Во-вторых, мы активно привлекаем наших коллег, занимающихся теоретическими аспектами информатики и машинного обучения, к разработке формальной оболочки для Eddy, решению вопросов конвергенции и стабильности, а также настройки правила, используемые для выполнения адаптивности.
Благодарности
Данная работа велась в рамках двух грантов от корпорации IBM, гранта компании Siemens AG, гранта компании ISX, гранта Национального научного фонда США IIS-9802051 и DARPA контракта N66001-99-2-8913. Хеллерштейна поддержала Sloan Foundation Fellowship, а Рамана - Microsoft Graduate Fellowship. Вычислительные и сетевые ресурсы были предоставлены в рамках гранта Национального научного фонда CDA-9401156.
Литература
[AAC+97] Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau, David E. Culler, Joseph M. Hellerstein, and David A. Patterson. High-Performance Sorting on Networks of Workstations. In Proc. ACM-SIGMOD International Conference on Management of Data, Tucson, May 1997.
[AAT+99] Remzi H. Arpaci-Dusseau, Eric Anderson, Noah Treuhaft, David E. Culler, Joseph M. Hellerstein, David A. Patterson, and Katherine Yelick. Cluster I/O with River: Making the Fast Case Common. In Sixth Workshop on I/O in Parallel and Distributed Systems (IOPADS ?99), pages 10-22, Atlanta, May 1999.
[ACPS96] S. Adali, K. Candan, Y. Papakonstantinou, and V. Subrahmanian. Query caching and optimization in distributed mediator systems. In Proc. of the ACM SIGMOD Int. Conf., Montreal, Canada, 1996.
[AFTU96] Laurent Amsaleg, Michael J. Franklin, Anthony Tomasic, and Tolga Urhan. Scrambling Query Plans to Cope With Unexpected Delays. In 4th International Conference on Parallel and Distributed Information Systems (PDIS), Miami Beach, December 1996.
[AH00] Ron Avnur and Joseph M. Hellerstein. Eddies: Continuously adaptive query processing. In Proc. ACM-SIGMOD International Conference on Management of Data, Dallas, 2000.
[Aok99] Paul M. Aoki. How to Avoid Building DataBlades(r) That Know the Value of Everything and the Cost of Nothing. In 11th International Conference on Scientific and Statistical Database Management, Cleveland, July 1999.
[AZ96] Gennady Antoshenkov and Mohamed Ziauddin. Query Processing and Optimization in Oracle Rdb. VLDB Journal, 5(4):229-237, 1996.
[BDF+97] Daniel Barbara, William DuMouchel, Christos Faloutsos, Peter J. Haas, Joseph M. Hellerstein, Yannis E. Ioannidis, H. V. Jagadish, Theodore Johnson, Raymond T. Ng, Viswanath Poosala, Kenneth A. Ross, and Kenneth C. Sevcik. The New Jersey Data Reduction Report. IEEE Data Engineering Bulletin, 20(4), December 1997.
[BO99] J. Boulos and K. Ono. Cost Estimation of User-Defined Methods in Object-Relational Database Systems. SIGMOD Record, 28(3):22-28, September 1999.
[Coh98] William W. Cohen Integration of heterogeneous databases without common domains using queries based on textual similarity. In Proceedings of the 1998 ACM SIGMOD International Conference on Management of Data, Seattle, 1998, pages 201-212.
[CR94] Chung-Min Chen and Nick Roussopoulos. Adaptive selectivity estimation using query feedback. In Richard T. Snodgrass and Marianne Winslett, editors, Proceedings of the 1994 ACM SIGMOD International Conference on Management of Data, Minneapolis, Minnesota, May 24-27, 1994, pages 161-172. ACM Press, 1994.
[DH00] Amol Deshpande and Joseph M. Hellerstein. Decoupled query optimization in federated databases. Technical report, University of California, Berkeley, 2000.
[EGH99] Deborah Estrin, Ramesh Govindan, and John Heidemann. Scalable coordination in sensor networks. In Proc. of ACM/IEEE Intl. Conf. on Mobile Computing and Networking (MobiCom 99), Seattle, August 1999.
[GC94] G. Graefe and R. Cole. Optimization of Dynamic Query Evaluation Plans. In Proc. ACM-SIGMOD International Conference on Management of Data, Minneapolis, 1994.
[GW89] Goetz Graefe and Karen Ward. Dynamic query evaluation plans. In James Clifford, Bruce G. Lindsay, and David Maier, editors, Proceedings of the 1989 ACM SIGMOD International Conference on Management of Data, Portland, Oregon, May 31 - June 2, 1989, pages 358-366. ACM Press, 1989.
16.[HAC+99] Joseph M. Hellerstein, Ron Avnur, Andy Chou, Christian Hidber, Chris Olston, Vijayshankar Raman, and Peter J. Haas Tali Roth. Interactive Data Analysis: The Control Project. IEEE Computer, 32(8):51-59, August 1999.
[HH99] Peter J. Haas and Joseph M. Hellerstein. Ripple Joins for Online Aggregation. In Proc. ACM-SIGMOD International Conference on Management of Data, pages 287-298, Philadelphia, 1999.
[HHW97] Joseph M. Hellerstein, Peter J. Haas, and Helen J. Wang. Online Aggregation. In Proc. ACM-SIGMOD International Conference on Management of Data, Tucson, 1997.
[HP88] Waqar Hasan and Hamid Pirahesh. Query Rewrite Optimization in Starburst. Research Report RJ 6367 , IBM Almaden Research Center, August 1988.
[HSC99] Joseph M. Hellerstein, Michael Stonebraker, and Rick Caccia. Open, independent enterprise data integration. IEEE Data Engineering Bulletin, 22(1), March 1999.
[IFF+99] Zachary G. Ives, Daniela Florescu, Marc Fiedman, Alon Levy, and Daniel S. Weld. An adaptive query execution system for data integration. In Proc. ACM-SIGMOD International Conference on Management of Data, Philadelphia, 1999.
[INSS92] Yannis E. Ioannidis, Raymond T. Ng, Kyuseok Shim, and Timos K. Sellis. Parametric query optimization. In Li-Yan Yuan, editor, 18th International Conference on Very Large Data Bases, August 23-27, 1992, Vancou-ver, Canada, Proceedings, pages 103-114. Morgan Kaufmann, 1992.
[KD98] Navin Kabra and David J. DeWitt. Efficient Mid-Query Reoptimization of Sub-Optimal Query Execution Plans. In Proc. ACM-SIGMOD International Conference on Management of Data, pages 106-117, Seattle, 1998.
[KKP99] J. M. Kahn, R. H. Katz, and K. S. J. Pister. Mobile networking for smart dust. In Proc. of ACM/IEEE Intl. Conf. on Mobile Computing and Networking (MobiCom 99), Seattle, August 1999.
[KRB99] Joanna Kulik, Wendi Rabiner, and Hari Balakrishnan. Adaptive protocols for information dissemination in wireless sensor networks. In Proc. of ACM/IEEE Intl. Conf. on Mobile Computing and Networking (MobiCom 99), Seattle, August 1999.
[LP97] L. Liu and C. Pu. A dynamic query scheduling framework for distributed and evolving information systems. In The IEEE Int. Conf. on Distributed Computing Systems (ICDCS-17), Baltimore, 1997.
[Met97] Rodney Van Meter. Observing the Effects of Multi-Zone Disks. In Proceedings of the Usenix 1997 Technical Conference, Anaheim, January 1997.
[Mit97] Tom Mitchell. Machine Learning. McGraw Hill, 1997.
[NKT88] Masaya Nakayama, Masaru Kitsuregawa, and Mikio Takagi. Hash-partitioned join method using dynamic destaging strategy. In Franc?ois Bancilhon and David J. DeWitt, editors, Fourteenth International Conference on Very Large Data Bases, August 29 - September 1, 1988, Los Angeles, California, USA, Proceedings, pages 468-478. Morgan Kaufmann, 1988.
[ONK+96] F. Ozcan, S. Nural, P. Koksal, C. Evrendilek, and A. Dogac. Dynamic query optimization on a distributed object management platform. In Conference on Information and Knowledge Management, Baltimore, Maryland, November 1996.
[PCL93a] HweeHwa Pang, Michael J. Carey, and Miron Livny. Memory-adaptive external sorting. In Rakesh Agrawal, Sean Baker, and David A. Bell, editors, 19th International Conference on Very Large Data Bases, August 24-27, 1993, Dublin, Ireland, Proceedings, pages 618-629. Morgan Kaufmann, 1993.
[PCL93b] HweeHwa Pang, Michael J. Carey, and Miron Livny. Partially preemptive hash joins. In Peter Buneman and Sushil Jajodia, editors, Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, D.C., May 26-28, 1993, pages 59-68. ACM Press, 1993.
17.[SAC+79] Patricia G. Selinger, Morton M. Astrahan, Donald D. Chamberlin, Raymond A. Lorie, and Thomas G. Price. Access path selection in a relational database management system. In Philip A. Bernstein, editor, Proceedings of the 1979 ACM SIGMOD International Conference on Management of Data, Boston, Massachusetts, May 30 - June 1, pages 23-34. ACM, 1979.
[SAP96] Michael Stonebraker, Paul M. Aoki, Avi Pfeffer, Adam Sah, Jeff Sidell, Carl Staelin, and Andrew Yu. Mariposa: A Wide-Area Distributed Database System. VLDB Journal, 5(1):48-63, January 1996.
[Son98] Eduardo D. Sontag. Mathematical Control Theory: Deterministic Finite-Dimensional Systems, Second Edition. Number 6 in Texts in Applied Mathematics. Springer-Verlag, New York, 1998.
[SWK76] M.R. Stonebraker, E. Wong, and P. Kreps. The design and implementation of INGRES. ACM Transactions on Database Systems, 1(3):189-222, September 1976.
[TTC90] G. Thomas, G. Thompson, C. Chung, E. Barkmeyer, F. Carter, M. Templeton, S. Fox, and B. Hartman. Het-erogeneous distributed database systems for product use. ACM Computing Surveys, 22(3), 1990.
[UF00] Tolga Urhan and Michael Franklin. XJoin: A Reactively-Scheduled Pipelined Join Operator. IEEE Data Engineering Bulletin, 2000. In this issue.
[UFA98] Tolga Urhan, Michael Franklin, and Laurent Amsaleg. Cost-Based Query Scrambling for Initial Delays. In Proc. ACM-SIGMOD International Conference on Management of Data, Seattle, June 1998.
[WA91] A. N. Wilschut and P. M. G. Apers. Dataflow Query Execution in a Parallel Main-Memory Environment. In Proc. First International Conference on Parallel and Distributed Info. Sys. (PDIS), pages 68-77, 1991.
[WW94] Carl A. Waldspurger and William E. Weihl. Lottery scheduling: Flexible proportional-share resource management. In Proc. of the First Symposium on Operating Systems Design and Implementation (OSDI ?94), pages 1-11, Monterey, CA, November 1994. USENIX Assoc.
[ZG90] Hansj ? org Zeller and Jim Gray. An adaptive hash join algorithm for multiuser environments. In Dennis McLeod, Ron Sacks-Davis, and Hans-J? org Schek, editors, 16th International Conference on Very Large Data Bases, August 13-16, 1990, Brisbane, Queensland, Australia, Proceedings, pages 186-197. Morgan Kaufmann, 1990.
[ZL97] Weiye Zhang and Per- ? Ake Larson. Dynamic memory adjustment for external mergesort. In Matthias Jarke, Michael J. Carey, Klaus R. Dittrich, Frederick H. Lochovsky, Pericles Loucopoulos, and Manfred A. Jeusfeld, editors, VLDB?97, Proceedings of 23rd International Conference on Very Large Data Bases, August 25-29, 1997, Athens, Greece, pages 376-385. Morgan Kaufmann, 1997.
Copyright 2000 IEEE. Bulletin of the Technical Committee on Data Engineering, June 2000, Vol. 23, No. 2, IEEE Computer Society. Joseph M. Hellerstein, Michael J. Franklin, Sirish Chandrasekaran, Amol Deshpande, Kris Hildrum, Sam Madden, Vijayshankar Raman, Mehul A. Shah, Adaptive Query Processing: Technology in Evolution
* Название проект получил в честь Telegraph Avenue - веселой и эклектичной главной улицы в Беркли.
** Действительно, самая маленькая таблица после того, как применены однотабличные предикаты и результаты материализованы («разъединение одной переменной»).
*** Формат индекса соединения вложенных циклов на самом деле не является объектом изменений: индексированное отношение полностью «просеивается» при каждом поиске в индексе. Однако, мы рассматриваем этот механизм, поскольку он позволяет увеличить производительность по сравнению с итеративными сквозными соединениями, в тех случаях, когда есть индекс.
Таблица 1. Ранние работы, связанные с адаптивной обработкой запросов и упорядоченные по частоте адаптации. Мы сознательно пропустили в таблице некоторые конкретные адаптивные операторы, в том числе сортировку и объединение, поскольку они по своей природе являются межоператорными по частоте. Мы обсудим их позже, в разделе 2.7.
| Пакетный | Для каждого запроса | Внутри оператора | Между операторами | Для каждого кортежа |
| System R [SAC+79], | ASE [CR94], | Query Scrambling | Ingres [SWK76] | River [AAT+99] |
| позднее связывание | ASE [CR94], | [AFTU96, UFA98] | RDB [AZ96] | Eddy [AH00] |
| [HP88, GW89] | ASE [CR94], | повторная | WHIRL [Coh98] | |
| [INSS92, GC94] | Mariposa [SAP+96] | оптимизация | ||
| [ACPS96, LP97] | [KD98], Tukwila [IFF+99] |
