
 Область business intelligence можно определить как множество математических моделей и методологий анализа, позволяющих систематически использовать доступные данные для поиска и извлечения информации и знаний, необходимых для поддержки принятия решений, совсем не очевидных в случае применения традиционных подходов. Значительную часть таких моделей и методов предоставляет интеллектуальный анализ данных, разработка или добыча данных (data mining). Несмотря на то что история возникновения дисциплины анализа данных восходит к задачам математической статистики, сегодня арсенал методов анализа данных существенно обогатился благодаря достижениям прикладной алгебры и дискретной математики. Двумя основными действующими силами, повлиявшими на становление дисциплины, стало развитие технологий СУБД в 60-е – 80-е годы и появление Сети. Для обработки размещаемых, в частности, в Web данных потребовались специальные методы выявления полезных знаний из уже собранных, добытых данных, поэтому не вполне точен перевод термина data mining как «добыча данных» – речь идет именно об их «разработке», раскопках с целью выявления скрытой информации.
Область business intelligence можно определить как множество математических моделей и методологий анализа, позволяющих систематически использовать доступные данные для поиска и извлечения информации и знаний, необходимых для поддержки принятия решений, совсем не очевидных в случае применения традиционных подходов. Значительную часть таких моделей и методов предоставляет интеллектуальный анализ данных, разработка или добыча данных (data mining). Несмотря на то что история возникновения дисциплины анализа данных восходит к задачам математической статистики, сегодня арсенал методов анализа данных существенно обогатился благодаря достижениям прикладной алгебры и дискретной математики. Двумя основными действующими силами, повлиявшими на становление дисциплины, стало развитие технологий СУБД в 60-е – 80-е годы и появление Сети. Для обработки размещаемых, в частности, в Web данных потребовались специальные методы выявления полезных знаний из уже собранных, добытых данных, поэтому не вполне точен перевод термина data mining как «добыча данных» – речь идет именно об их «разработке», раскопках с целью выявления скрытой информации.
Ввиду многообразия методов и областей применения data mining удобно пользоваться классификацией по характеру задачи, например:
-
задачи описания понятия/класса (установление характерных и различающих черт);
-
поиск частых признаков, ассоциаций и корреляций;
-
классификация и прогнозирование;
-
кластерный анализ;
-
анализ выбросов (аномальное поведение);
-
анализ изменений.
Такая классификация недостаточно детализирована, но охватывает все многообразие методов. По характеру и источникам исходных данных можно выделить методы анализа баз данных (целый спектр технологий, например, анализ OLAP-кубов), мультимедийных данных, текстовых и Web-данных. Безусловно, системы промышленного анализа данных содержат встроенную СУБД или же интегрированы с хранилищами данных, и позволяют хранить данные последних трех перечисленных типов. Но мультимедиаданные, тексты и Web-ресурсы требуют особой предварительной обработки, прежде чем стать объектом анализа, доступным из базы данных; не случайно исследователи отдельно рассматривают Text Mining и Web Mining.
Для задачи описания понятия или класса требуются методы установления характерных и различающих черт, позволяющие представить данные в обобщенном виде. Такие методы используются при первичном анализе для знакомства с данными, когда еще мало информации о предмете исследований, но достаточно для выдвижения каких-либо гипотез.
Одним из ключевых методов data mining является поиск частых множеств признаков (frequent itemset mining), ставший популярным благодаря успешному применению в задаче анализа потребительской корзины, при решении которой ищутся наборы товаров, часто приобретаемых вместе. Величина, равная частоте, с которой встречается тот или иной набор товаров, называется поддержкой (support). Регулируя величину поддержки, можно получить приемлемое для дальнейшего анализа менеджером множества часто покупаемых вместе товаров. На основе частых множеств признаков строятся ассоциативные правила, позволяющие делать выводы о том, что, скорее всего, приобретет потребитель, если он уже купил некоторый товар. Однако реально толк в этих технологиях сегодня знают крупные Internet-магазины, такие как Amazon, но задачу «холодного старта», когда о посетителе, впервые пришедшем на сайт, еще ничего не известно, и они решают плохо. Можно, конечно, анализировать информацию о его предыдущих посещениях аналогичных сайтов, но если человек ничего не покупал, а только посмотрел на какой-то товар, то предложить ему адекватный выбор сложно, и обычно здесь ему приходится показывать хоть что-нибудь.
Ассоциативные правила записываются в виде зависимости A->B, а их качество определяется двумя величинами: поддержкой и достоверностью (confidence). Достоверность соответствует вероятности того, что при покупке всех товаров группы A будут куплены товары из группы B, а поддержка – доля (колличество) таких правил в общем потоке всех покупок.
Методы классификации позволяют по имеющемуся описанию некоторого объекта отнести его к одному из заранее известных классов. Например, в задачах кредитного скоринга эти методы применяются для предсказания возврата или невозврата кредита. Изначально алгоритм проходит обучение на данных о благонадежных заемщиках и неплательщиках (обучающая выборка), а затем тестируется на выборке с известными ответами о принадлежности к классам «возврат» и «невозврат» (тестовая выборка). По количеству и характеру ошибок судят о качестве предсказательной модели. Примером такого метода является построение дерева решений, которое представляет собой обобщение правил типа «если…, то...». Последовательно применяя порожденные правила к признакам экземпляра данных (проходя по узлам дерева), можно получить класс, к которому его отнес данный метод. Например, если заемщик – мужчина со средним доходом выше 50 тыс. руб. и высшим образованием, то можно выдать кредит. В банках часто используют скоринговые карты, представляющие собой табличный вид деревьев решений, и, конечно, там тоже используется некая всероссийская база по невозвратам, хотя банки и не афишируют свои методики. В условиях нестабильной экономики происходит сопряжение исходных данных для метода со стратегией банка – ужесточение правил без изменения сути метода. Методы прогнозирования позволяют предсказать значения некоторой числовой величины, например сумму ожидаемого дохода или курс акций, оптимальную цену продажи недвижимости в зависимости от расположения, площади и других факторов. Примером служат методы регрессионного анализа.
Кластерный анализ позволяет разбить исходные данные на группы по сходству образующих их объектов. Скажем, крупная компания может проанализировать продажи, исходя из стоимости покупок, их частоты, места продажи и других характеристик, разбить данные о продажах на группы, тем самым сегментировать рынок и получить о нем наглядное представление, увидеть портрет клиента из целевой группы. Типичные методы этой группы – иерархическая кластеризация и метод K-средних.
Методы анализа выбросов призваны выявить аномальное поведение объекта и часто применяются для выявления мошенничества с кредитными картами и оплатой телекоммуникационных услуг, а также для мониторинга технических неисправностей. Как правило, они основаны на выявлении единичных, не частотных событий или событий с «необычными» параметрами, не похожими на регулярно происходящие.
Анализ изменений или динамики предназначен для описания зависимостей и прогнозирования в данных, содержащих параметр время. Примеры метода – временные ряды и анализ последовательностей. Первые могут предсказать изменения биржевых котировок на основе предыдущей динамики, а анализ последовательностей способен по известному поведению покупателя предсказать его дальнейшие покупки. Например, покупка внутренних отделочных материалов может предшествовать покупке мебели.
Говоря об анализе данных из Internet, стоит заметить, что, как правило, аналитик имеет дело с огромной сетью связанных между собой сайтов и документов, а также с пользователями, посещающими эти ресурсы и генерирующими разнообразную информацию. Исходя из этого выделяют три типа подзадач: анализ использования Web-ресурсов (Web usage mining), анализ содержания или контент-анализ (Web content mining) и анализ структуры Паутины (Web structure mining). Примерами задач первого типа являются исследование целевой аудитории сайта и выдача рекомендаций пользователям электронного магазина. Задачи контент-анализа используются для исследования блогосферы, например, для выявления тем политических блогов, определения состава и предпочтений пользователей таких сайтов. Анализ структуры Web применяется для расчета ссылочной популярности сайтов, например, алгоритм Page Rank использует информацию о числе входящих и выходящих ссылок на ресурс, позволяя выдать пользователю в ответ на его запрос релевантную информацию не только благодаря тематическому сходству, но и согласно рейтингу популярности и надежности ресурса, определяемому ссылочной структурой Сети. Как видно, решение этих задач призвано улучшить качество Web-сервисов, помочь владельцам сайтов лучше узнать свою аудиторию, найти товар согласно предпочтениям клиента, снабдить пользователя релевантной информацией, узнать мнение электората.
Поиск дубликатов
По мнению экспертов, около 30% всех документов в Сети по разным причинам имеют дубликаты. Для борьбы с этой проблемой предложено несколько методов, например «шинглирование» (от англ. shingle – чешуйка). Исходный документ разбивается на цепочки символов, или шинглы, которые хешируются, а результирующий образ документа представляет собой множество или мультимножество таких чисел. Два документа считаются «почти дубликатами» (near-duplicate), если количество их общих шинглов превышает некоторый порог, например, 85%. После того как такие дубликаты выявлены, необходимо разбить их на группы или кластеры, каждый из которых будет представлять собой множество сходных копий одного и того же документа.
Если традиционным путем искать кластеры документов-дубликатов с помощью отношения сходства, то можно прийти к абсурдным результатам. Например, можно подобрать цепочку слов, «превращающих» муху в слона: МУХА – муpа – туpа – таpа – каpа – каpе – кафе – кафp – каюp – каюк – кpюк – уpюк – уpок – сpок – сток – стон – СЛОН. Каждый шаг такого преобразования – значащее слово, аналог документа в нашем примере, а пары соседних слов отличаются только одним символом, т.е. принадлежат отношению сходства, определяемому через 75-процентное совпадение множеств символов слов. В результате применения транзитивного замыкания к отношению сходства все эти слова окажутся в одном кластере.
Описанный ранее поиск частых множеств признаков не только поможет отделить «мух» от «слонов», но и позволит не производить ресурсоемкое попарное сходство. В случае документов-дубликатов мы отбираем те из них, у которых число общих шинглов больше заданного порога – поддержки, например 85, при размере образа документа в 100 шинглов. Природа данных методов такова, что они способны работать с большими размерами входных данных и не порождают кластеров ложных дубликатов, оставаясь при этом особенно эффективным для разреженных массивов и чувствительными к порогу.
Построение таксономий посетителей сайтов
Любой владелец Internet-магазина хочет иметь представление об интересах посетителей его ресурсов – чем точнее получается портрет клиента, тем лучше может быть выстроена стратегия торговли. Частично это решается путем опросов и голосований по наиболее важным проблемам, но обычно отвечающих слишком мало, чтобы сформировать репрезентативную выборку. Компании, предоставляющие счетчики, обладают большей полнотой информации. И чем больше счетчиков у такой компании на других сайтах, тем больше возможностей у нее отслеживать поведение конкретных посетителей. Составление тематических каталогов, дополняющих счетчики ресурсов, помогает лучше понять интересы аудитории целевого сайта. Например, для бизнес-стратегии крупного банка важно понимать распределение интересов посетителей корпоративного сайта – потенциальных клиентов – по ресурсам финансовой тематики, представленным в тематическом каталоге. Крупному автодилеру не помешает знание интересов посетителей своего сайта, опять же в терминах профильной тематики, это позволит ответить на вопросы «Какими марками автомобилей сейчас интересуются потенциальные клиенты?», «Какого класса эти автомобили?», «Какие сайты конкурентов в этом секторе они еще посещают?» и т.п. Без тематических каталогов построение диаграмм решеток в терминах целевого сайта невозможно, но с помощью диаграмм решеток замкнутых множеств можно визуализировать данные о посещаемости целевого сайта в терминах распределения его аудитории по внешним ресурсам. На рис. 1 приведен пример такой визуализации, таксономии для данных о посещаемости сайта ГУ–ВШЭ в терминах новостных ресурсов.
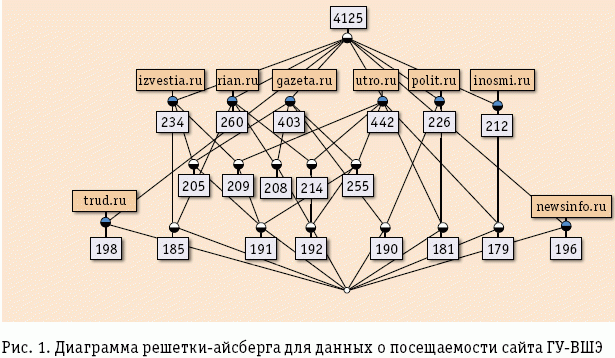
Данные для рис. 1 предоставлены компанией Spylog и представляют собой сведения о пользователях сайта www.hse.ru и посещениях ими других сайтов за один месяц. Отобраны наиболее активные пользователи, совершившие более двадцати посещений за месяц. Каждый узел диаграммы решетки представляет собой группу посетителей, белые метки указывают их число, а серые – сайт, посещенный ими и всеми пользователями других узлов, в которые ведут нисходящие ребра. «Айсбергом» это упорядоченное множество групп пользователей называется потому, что использована популярная в data mining идея отбора наиболее часто встречающихся множеств признаков (в данном случае только сайтов). Таким образом, на диаграмме показана лишь верхняя часть решетки, вершина айсберга, в данном случае содержащая 20 узлов. По результатам такой визуализации можно прийти к выводу, что аудитория ГУ-ВШЭ придерживается чтения новостных ресурсов середины политического спектра. Конечно, это довольно очевидные выводы, которые можно получить, например просто анализируя частоту посещений сайта, однако картина несколько изменится, если рассмотреть диаграмму для 20 самых устойчивых (в смысле специального индекса устойчивости) категорий посетителей (рис. 2).
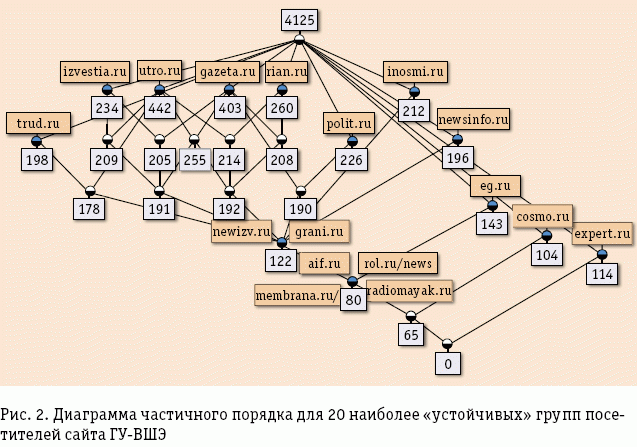
Очевидно, что устойчивые группы посетителей не всегда крупны, но их наличие говорит о сильно выраженных интересах аудитории к конкретным сайтам. Судя по диаграмме, устойчивой является аудитория сайта expert.ru, состоящая из 114 активных пользователей. То, что такая аудитория этого сайта оказалась среди устойчивых, означает, что даже при уходе нескольких постоянных посетителей ресурсов ГУ-ВШЭ она не прекратит существования. Зная характер новостного ресурса expert.ru, можно выдвинуть гипотезу о том, что определенная доля посетителей сайта ГУ-ВШЭ интересуется альтернативными экспертными мнениями из заслуживших доверие источников. В то же время особняком стоят группы посетителей ресурсов eg.ru и cosmo.ru (отсутствуют пересечения этих аудиторий на диаграмме), что говорит об отличии их интересов от интересов группы посетителей сайта expert.ru. Характер ресурсов eg.ru и cosmo.ru был оценен некоторыми исследователями как относительно неглубокий, поэтому такие устойчивые группы вносят дополнительные штрихи к портретам посетителей сайта ГУ-ВШЭ. Наличие средств визуализации является краеугольным камнем успеха тех или иных методов data minig, так как не всегда существует возможность представить извлеченные знания в наглядном виде, понятном не только эксперту.
Рекомендательные системы
Для покупателей товаров в Internet-магазинах не новость, что их покупки фиксируются, а исходя из их истории и поведения пользователей с похожими интересами предлагаются рекомендации. Такие рекомендации, как правило, не лишние, потому что трудно уследить за всеми новинками, да и просто во всем многообразии товаров и услуг подобрать подходящие. За таким интеллектуальным поведением рекомендательных систем стоят вполне традиционные алгоритмы анализа данных, например кластеризация и метод поиска ближайшего соседа, применение которых необходимо для выявления сходства товаров на основе их совместной покупки, а также для определения сходства пользователей и корреляции их поведения.
Два метода, ставшие классическими в этой области, – это рекомендации, основанные на сходстве пользователей (user-based) и на сходстве признаков (item-based). Первый хорошо работает на данных с небольшим числом пользователей и ищет их попарное сходство, выдавая в качестве рекомендаций товары, покупаемые наиболее похожими посетителями. Подход на основе сходства по признакам работает быстрее и особенно эффективен на разреженных данных, не требует вычисления сходства со всеми остальными товарами. В этом случае ищутся товары, схожие с теми, что наиболее часто покупаются данным посетителем.
Кроме этого, успешно применяются и рекомендательные алгоритмы на основе ассоциативных правил, которые способны предложить рекомендации в виде импликаций A->B. Такие правила интуитивно понятны: если посетитель купил товары группы A, то рекомендуем ему товары группы B. Сгенерированные правила ранжируются по достоверности и выдаются пользователю под видом TOP-N-товаров из правой части правила в порядке убывания. На практике по точности и полноте поиска рекомендаций метод ассоциативных правил оказывается лучше рекомендаций на основе сходства пользователей или признаков, но хуже масштабируется.
Покажем, каким образом можно формировать рекомендации в виде правил, на примере задачи о подборе словосочетаний покупателями контекстной рекламы, опираясь лишь на знание названий признаков. Поисковые системы давно освоили этот вид рекламы, как правило, их клиенты самостоятельно выбирают, а затем покупают ключевые слова для наиболее точного описания своих услуг. При вводе поискового запроса, который содержит такие слова, будет показано объявление со ссылкой на сайт рекламодателя. Это один из самых прибыльных видов рекламы в Сети, опережающий по динамике и продажам баннерную. К услугам такой поисковой рекламы в России прибегают в основном представители малого и среднего бизнеса. Относительно недавно у компаний, продающих контекстную рекламу, появились «интеллектуальные помощники», советующие их клиентам приобрести наиболее точно описывающие их бизнес рекламные словосочетания, исходя из частоты их продаж.
Предположим, у нас есть выборка данных о 2 тыс. компаний, которые покупали какие-либо из 3 тыс. рекламных словосочетаний для показа контекстной рекламы в одной из поисковых систем. Надо выработать рекомендации для фирмы f на основе тех рекламных словосочетаний, которые купила она и конкуренты. Примером сервиса, решающего подобную задачу, является служба Google AdWords, помогающая подобрать рекламные словосочетания для сайтов компаний-рекламодателей. Анализируя покупки, можно использовать напрямую поиск ассоциативных правил, получая рекомендации в виде «подарок на выпускной» ® «подарок на юбилей» (support=41; confidence=0,82). Но часто посылка и заключение таких правил содержат однокоренные слова, поэтому предлагается не только анализировать поведение фирм, отраженное в покупках, но также использовать морфологию и слова-синонимы для поиска близких словосочетаний, тем самым выявляя целые рынки. Приведем пример правила для покупки ключевых слов об услугах провайдера, предлагающего недорогой доступ в Internet:
{дешевый интернет} ® { дешевый интернет-провайдер, дешевая интернет-связь, …, дешевый спутниковый интернет, дешевый 3g-интернет, дешевый мобильный интернет, самый дешевый безлимитный интернет} support=37, confidence=0,88
Это правило довольно достоверное, а возникло оно в результате вынесения в заключение всех словосочетаний, содержащих однокоренные слова хотя бы для одного из слов в посылке. Предложенный здесь метод формирования ассоциаций использует алгоритм стемминга (выделение основы или корня слова) для всех признаков, то есть 3 тыс. словосочетаний. Такая техника позволяет провести вычисления заранее и работает эффективнее, чем поиск ассоциативных правил, хотя при этом сложно достичь такой же полноты поиска. Таким образом, компания, собирающаяся купить словосочетание «дешевый интернет», получит рекомендации в виде словосочетаний, включающих однокоренные слова. Высокая достоверность правила, вычисленная по данным реальных покупок рекламы, гарантирует то, что это будут действительно популярные запросы. Такие алгоритмы полезны для сервисов контекстной рекламы, примерами которых являются «Яндекс.Директ», Google AdWords и др. Улучшить этот метод способны релевантно составленные словари синонимов или онтологии предметной области, но их автоматическое построение – отдельная и весьма непростая задача.
***
Выбор того или иного метода анализа данных определяется характером задачи и мастерством аналитика, поэтому часто грамотное комбинирование идей на стыке разных областей информатики, математики и других наук помогает достичь впечатляющих результатов. Сегодня наиболее активное применение эти методы находят в задачах, связанных с анализом Web-данных.
Дмитрий Игнатов (dignatov@hse.ru) – преподаватель факультета бизнес-информатики ГУ–ВШЭ (Москва).
